python爬虫xpath
又是一个大晴天,因为马上要召开十九大,北京地铁就额外的拥挤,人贴人到爆炸,还好我常年挤地铁早已练成了轻功水上漂,挤地铁早已经不在话下。
励志成为一名高级测试工程师的我,目前还只是个菜鸟,难得有机会,公司辞职的爬虫大佬教了我下爬虫,故借此机会分享给那些小白,
此篇只是简单爬取了小说的标题,没有涉及到框架,还望各位大佬海涵!!
环境准备:
pycharm(撩妹神器,人手一个) lxml(python的三方库)
如果电脑里没有安装lxml的伙伴,可以安装一下,在控制台输入pip intall https://pypi.douban.com/simple lxml,
利用国外的源下载比较慢,我一般用国内的这个源下载,如果有更好的,欢迎各位留个脚印,么么哒
如果你输入pip show lxml出现像我这样的界面,咦咦咦,厉害了,说明你离走向爬虫大师,差的不是一心半点了

导入文件:
好的,既然这样,说搞就搞,小白们,扑上来吧,要那种纯小白的,哈哈
在pycharm里边新建一个py文件
然后引入requests(请求库),以及lxml里边的etree,如下图

我们先打开豆瓣图书的一个网址,网址是“https://read.douban.com/kind/100”,如下图所示
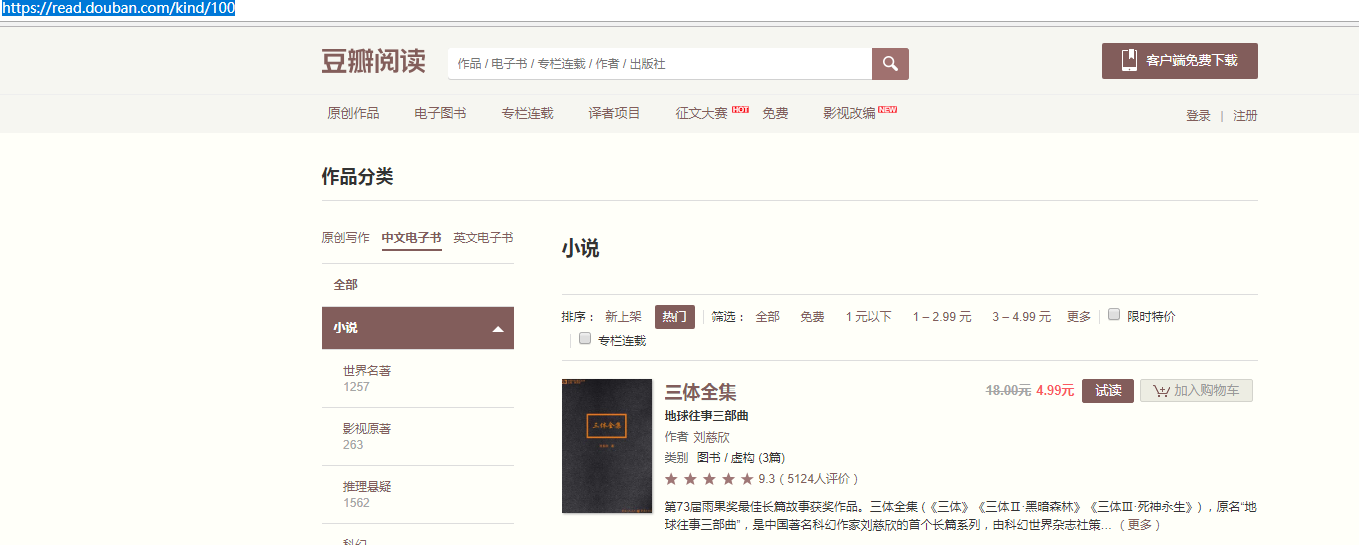
定位爬取:
现在要做的就是去爬取“三体全集”,“评分”以及“小说简介”这三个内容,可是怎么爬呢,那就要用到了xpath这个定位利器,用过的人都说好,他好我也好! //坏笑,坏笑
1.首先利用request进行get请求:

2.然后我们利用请求回来的r.content进行解析

3.下面重点来了,我们解析后的数据进行打印


我们可以知道这个html对象的位置,下面我们就要利用xpath去进行定位
在豆瓣网阅读的网页,我们点击F12,然后点击控制台的箭头,点击一下页面上的三体全集,我们就可以找到该元素的位置了
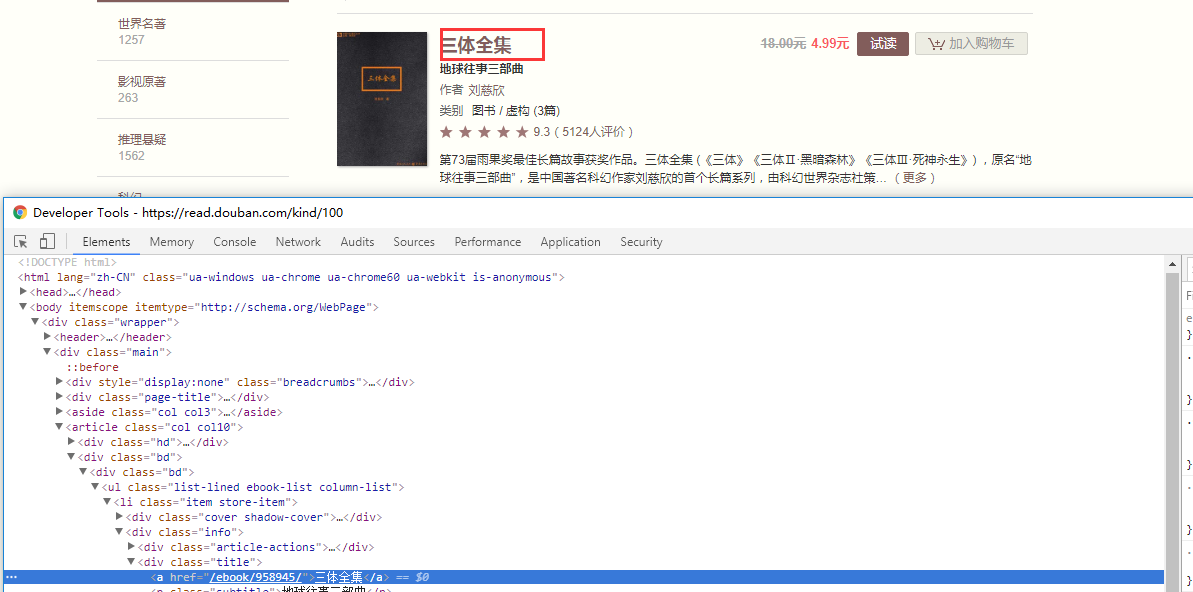
在锁定位置点击右键,找到Copy,点击Copy Xpath,然后在pycharm进行定位打印

其中利用content调用xpath方法,里边写上刚才copy好的位置,后边加一个text(),然后进行取[0],
然后运行一下,what fuck,出现了什么,三体全集被打印了,还TM的有这种操作,是在逗我吗!!
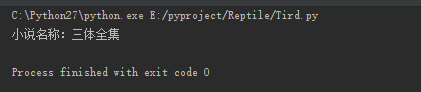
评分以及简介同样如此,如果我们想打印多个小说的这些属性,通过定位不难发现,他们是有规律的,我们可以进行循环赋值进行打印,这样就会出现如下所示

感谢各位的阅读,此篇过于简单,只是自己喜欢写写东西玩,如果能给您带来乐趣,那将是我的荣幸,祝各位前程似锦,工作顺利!!
源码如下:
- #coding=utf-8
import requests
from lxml import etree
def ReptileDouBan(url):
r = requests.get(url)
#print r.content
content = etree.HTML(r.content)
print content
for i in range(1,20):
print u"小说名称:" + content.xpath("/html/body/div/div/article/div[2]/div[1]/ul/li[%d]/div[2]/div[2]/a/text()" %i)[0]
#print u"小说备注:" + content.xpath("/html/body/div/div/article/div[2]/div[1]/ul/li[%d]/div[2]/div[2]/p/text()" %i)[0]
print u"评分:" + content.xpath("/html/body/div/div/article/div[2]/div[1]/ul/li[%d]/div[2]/div[3]/span[2]/text()" %i)[0]
print u"介绍:" + content.xpath("/html/body/div/div/article/div[2]/div[1]/ul/li[%d]/div[2]/div[4]/text()" %i)[0]
if __name__ == '__main__':
url = "https://read.douban.com/kind/100"
ReptileDouBan(url)
python爬虫xpath的更多相关文章
- python爬虫xpath的语法
有朋友问我正则,,okey,其实我的正则也不好,但是python下xpath是相对较简单的 简单了解一下xpath: XPath 是一门在 XML 文档中查找信息的语言.XPath 可用来在 XML ...
- Python爬虫 XPath语法和lxml模块
XPath语法和lxml模块 什么是XPath? xpath(XML Path Language)是一门在XML和HTML文档中查找信息的语言,可用来在XML和HTML文档中对元素和属性进行遍历. X ...
- python爬虫----XPath
1.知道本节点元素,如何定位到兄弟元素 详情见博客 XML代码见下 bt1在文档中只出现一次,所以很容易获取到bt1中内容,那怎么根据<td class='bt1'>来获取bt2中的内容 ...
- Python爬虫 | xpath的安装
错误信息:程序包无效.详细信息:“Cannot load extension with file or directory name . Filenames starting with "& ...
- python爬虫前提技术
1.BeautifulSoup 解析html如何使用 转自:http://blog.csdn.net/u013372487/article/details/51734047 #!/usr/bin/py ...
- Python爬虫与数据分析之爬虫技能:urlib库、xpath选择器、正则表达式
专栏目录: Python爬虫与数据分析之python教学视频.python源码分享,python Python爬虫与数据分析之基础教程:Python的语法.字典.元组.列表 Python爬虫与数据分析 ...
- python爬虫的页面数据解析和提取/xpath/bs4/jsonpath/正则(1)
一.数据类型及解析方式 一般来讲对我们而言,需要抓取的是某个网站或者某个应用的内容,提取有用的价值.内容一般分为两部分,非结构化的数据 和 结构化的数据. 非结构化数据:先有数据,再有结构, 结构化数 ...
- Python爬虫教程-22-lxml-etree和xpath配合使用
Python爬虫教程-22-lxml-etree和xpath配合使用 lxml:python 的HTML/XML的解析器 官网文档:https://lxml.de/ 使用前,需要安装安 lxml 包 ...
- 小白学 Python 爬虫(19):Xpath 基操
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
随机推荐
- Struts2第二篇【开发步骤、执行流程、struts.xml讲解、defalut-struts讲解】
前言 我们现在学习的是Struts2,其实Struts1和Struts2在技术上是没有很大的关联的.Struts2其实基于Web Work框架的,只不过它的推广没有Struts1好,因此就拿着Stru ...
- java基础知识5--集合类(Set,List,Map)和迭代器Iterator的使用
写的非常棒的一篇总结: http://blog.csdn.net/speedme/article/details/22398395#t1 下面主要看各个集合如何使用迭代器Iterator获取元素: 1 ...
- Windows和Linux查看和更改mysql连接池
Windows: 查看: 进入mysql 输入:show variables like '%max_connections%'; 更改: 进入MYSQL安装目录 打开MYSQL配置文件 my.ini ...
- SpringAop详解
近几天学习了一下SpringAop在网上找了一些资料,此链接为原文链接http://www.cnblogs.com/xrq730/p/4919025.html AOP AOP(Aspect Orien ...
- 认识:ThinkPHP的编译缓存文件~runtime.php
1.定义单入口文件(index.php) 在单入口index.php中不定义这两项时,会生成编译缓存文件~runtime.php define('RUNTIME_PATH','./App/Temp/' ...
- Object.defineProperty()方法的用法详解
Object.defineProperty()函数是给对象设置属性的. Object.defineProperty(object, propertyname, descriptor); 一共有三个参数 ...
- Running Spark on YARN
Running Spark on YARN 对 YARN (Hadoop NextGen) 的支持是从Spark-0.6.0开始的,后续的版本也一直持续在改进. Launching Spark on ...
- Operating system hdu 2835 OPT
Operating system Time Limit: 6000/3000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) ...
- .Neter玩转Linux系列之二:Linux下的文件目录及文件目录的权限
一.Linux下的文件目录 简介:linux的文件系统是采用级层式的树状目录结构,在此 结构中的最上层是根目录“/”,然后在此目录下再创建 其他的目录.深刻理解linux文件目录是非常重要的,如下图所 ...
- 手动打包MVC项目成Web Deploy包,发布至服务器
①确保服务器上安装了Web Deploy,可以使用微软Web Paltform Installer安装.https://www.microsoft.com/web/downloads/platform ...