grep命令及基本正则表达式
grep命令是Linux系统中一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。
grep可用于shell脚本,因为grep通过返回一个状态值来说明搜索的状态,如果模板搜索成功,则返回0,如果搜索不成功,则返回1,如果搜索的文件不存在,则返回2。我们利用这些返回值就可进行一些自动化的文本处理工作。
1.命令格式:
grep [OPTION] ...‘PATTERN’ FILE...
说明:[]:代表可省略的;...:可以是多个;
grep [选项]... ”关键词“ 文件...
2.命令功能:
文本搜索工具,根据用户指定的“模式(pattern)”对目标文本进行过滤,显示被模式匹配到的行。
3.命令选项:
-v: 反向选取
-o: 仅显示匹配到内容
-i: 忽略字符大小写
-E: 使用扩展正则表达式
-A #: 显示查找的到文件并显示下面#行
-B #:显示查找的到文件并显示上面#行
-C #:显示查找的到文件并显示上下#行
--color:长选项,可将匹配到的内容自动加颜色高亮显示。为了方便可设置别名输入:alias grep='grep --color=auto'
4.正则表达式:
正则表达式是由一类字符书写的模式,其中有些字符不表示字符的字面意义,而是表示控制或通配的功能。
说明:在windows中*代表任意长度,任意的字符。
元字符:字符不表示字符的字面意义,而是表示控制或通配的功能就叫做元字符。
说明:例:*就是一个元字符
正则表达式分两类:基本正则表达式和扩展正则表达式。
基本正则表达式:
字符匹配:
. #匹配单个非换行符的字符 如:'gr.p'匹配gr后接一个任意字符,然后是p。
[] #匹配一个指定范围内的字符,如'[Gg]rep'匹配Grep和grep。
[^] #匹配一个不在指定范围内的字符,如:'[^A-FH-Z]rep'匹配不包含A-R和T-Z的一个字母开头,紧跟rep的行。
\w #匹配文字和数字字符,也就是[A-Za-z0-9],如:'G\w*p'匹配以G后跟零个或多个文字或数字字符,然后是p。
\W #\w的反置形式,匹配一个或多个非单词字符,如点号句号等。
次数匹配:
* #匹配零个或多个先前字符。如:'*grep'匹配所有一个或多个空格后紧跟grep的行。
\? #匹配其前面出现的字符0次或1次。如:'x\?y'匹配x出现一次或者不出现的行。
\+ #匹配其前面的字符出现至少一次。如:'x\+y'匹配x出现最少一次的行。
\{m\} #匹配其前面的字符至少m次;如:'0\{5\}'匹配包含5个o的行。
\{m,\} #重复字符x,至少m次,如:'o\{5,\}'匹配至少有5个o的行。
\{m,n\}:匹配其前面的字符至少m次,至多n次;o\{5,10\}'匹配至少有5-10个o的行。
.* :匹配任意长度的任意字符
位置锚定:也就是位置锁定,指定其出现在什么位置上面
$ #行尾锚定 如:'grep$'匹配所有以grep结尾的行。
^ #行首锚定 如:'^grep'匹配所有以grep开头的行。
^$ #空白行:行首与到行尾 特殊环境能用到
\< #单词词首锚定,也可以用\b。如: '\<grep''\bgrep'只匹配grep单词开头的行。
\> #词尾锚定,也可以用\b。如:'grep/>''grep/b'只匹配grep单词结尾的行。
/<pattern/> #单词锚定,只匹配出现pattern单词的行和'/bpattern/b'是一样的效果。
\b #单词锁定符,如: '\bgrep\b'只匹配grep。 同/<pattern/>
分组
\(\) #在bash中{}(花括号),()小括号也有特殊意思,所以在这里需要用\做转意
后向引用:模式中,如果使用\(\)实现了分组,在某行文本的检查中,如果括号中的模式匹配到了某内容,次内容后面的模式中可以被引用;\1,\2,\3 第一个括号,第二个括号,第三个括号模式自左而右,引用第#个左括号以及与其匹配右括号之间的模式匹配到的内容。
POSIX字符:
为了在不同国家的字符编码中保持一至,POSIX(The Portable Operating System Interface)增加了特殊的字符类,如[:alnum:]是[A-Za-z0-9]的另一个写法。要把它们放到[]号内才能成为正则表达式,如[A- Za-z0-9]或[[:alnum:]]。在linux下的grep除fgrep外,都支持POSIX的字符类。
[[:alnum:]] = [0-9a-zA-Z] #文字数字字符
[[:alpha:]] = [a-zA-Z] #文字字符
[[:digit:]] = [0-9] #数字字符
[[:graph:]] #非空字符(非空格、控制字符)
[[:lower:]] = [a-z] #小写字符
[[:cntrl:]] #控制字符
[[:print:]] #非空字符(包括空格)
[[:punct:]] #标点符号
[[:space:]] #所有空白字符(新行,空格,制表符)
[[:upper:]] = [A-Z] #大写字符
[[:xdigit:]] = [0-9a-fA-F] #十六进制数字(0-9,a-f,A-F)
5.使用实例:
实例1:将匹配到的内容加颜色高亮显示
命令:
alias grep='grep --color=auto'
grep 'user' /etc/passwd
输出:
1 [root@localhost yum.repos.d]# alias grep='grep --color=auto'
2 [root@localhost yum.repos.d]# grep 'user'/etc/passwd
3 usbmuxd:x:113:113:usbmuxd user:/:/sbin/nologin
4 saslauth:x:498:76:Saslauthduser:/var/empty/saslauth:/sbin/nologin
5 rpcuser:x:29:29:RPC ServiceUser:/var/lib/nfs:/sbin/nologin
说明:
第一条是设置grep命令的别名;第二条是显示'user'所在的行。
实例2: . 匹配任意单个字符
命令:
grep 'r..t' /etc/passwd
输出:
[root@localhost yum.repos.d]# grep 'r..t'/etc/passwdroot:x:0:0:root:/root:/bin/bashoperator:x:11:0:operator:/root:/sbin/nologinftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
说明:
显示所有以r开头中间2个字符以t结尾的所有行。
实例3:[] 匹配指定集合中的任意单个字符。
命令:
grep 'r[a-z][a-z]t' /etc/passwd
输出:
1 [root@localhost yum.repos.d]# grep 'r[a-z][a-z]t'/etc/passwd
2 root:x:0:0:root:/root:/bin/bash
3 operator:x:11:0:operator:/root:/sbin/nologin
说明:
输出所有以r开头中间2个小写字母以t结尾的所有行。实例2中r/ft有非字母的字符,所以不予输出。
实例4:[^] 匹配一个不在指定范围内的字符
命令:
grep 'r^[a-z]^[a-z]t' /etc/passwd
输出:
1 [root@localhost yum.repos.d]# grep '^[^[:alpha:]].*'/etc/passwd
2 123:x:500:500::/home/123:/bin/bash
说明:
输出行首不包含大小写字母的行。[[:alpha:]] = [a-zA-Z]
实例5:/?与/+的区别
命令:
grep 'x\?y' a.txt
grep 'x\+y' a.txt
输出:
1 [root@localhost ~]# cat a.txt
2 xy
3 sy
4 aby
5 yyy
6 xxxy
7 xxy
8 [root@localhost ~]# grep 'x\?y' a.txt
9 xy
10 sy
11 aby
12 yyy
13 xxxy
14 xxy
15 [root@localhost ~]# grep 'x\+y' a.txt
16 xy
17 xxxy
18 xxy
说明:
从高亮显示可以看出来\?前面的x出现一次或者不出现都高亮后面的字符,就算有多个x也只会高亮一个,\+至少要x出现 一次。
实例6:\{m\} :匹配其前面的字符至少m次;
命令:
grep 'x\{3\}y' a.txt
输出:
1 [root@localhost ~]# grep 'x\{3\}y' a.txt
2 xxxy
说明:
匹配y前面的字符x至少3次。
实例7:\{m,n\}:匹配其前面的字符至少m次,至多n次;
命令:
grep 'x\{2,5\}y' a.txt
输出
1 [root@localhost ~]# grep 'x\{2,5\}y' a.txt
2 xxxy
3 xxy
实例8:.* :匹配任意长度的任意字符
命令:
grep 'r.*t' /etc/passwd
输出:

实例9: ^ :行首锚定,必须出现在最左侧
命令:
grep '^r[[:alpha:]][[:alpha:]]t' /etc/passwd
输出:
[root@localhost ~]# grep '^r[[:alpha:]][[:alpha:]]t'/etc/passwd
root:x:0:0:root:/root:/bin/bash
实例10:行尾锚定,必须出现在最右侧
命令:

实例11:\<:词首锚定,也可以用\b 注意是单词的词首不是行的行首
命令:
grep '\<r..t' /etc/passwd
grep '\br..t' /etc/passwd
输出:

实例12:\>:词尾锚定,也可以用\b
命令:
grep 'mes\>' /etc/passwd
grep 'mes\b' /etc/passwd
输出:

实例13:\<pattern\>和\bpattern\b:匹配单词
命令:
grep '\buser\b' /etc/passwd
grep '\buser\b' /etc/passwd
输出:

说明:只匹配关键字是单词的,不会出现在别的单词里面。
实例14:分组:\(\)
命令:
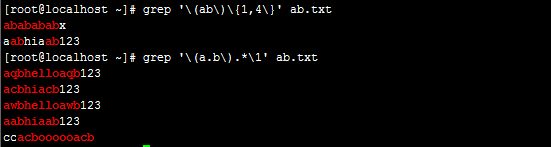
grep '\(ab\)\{1,4\}' ab.txt
grep '\(a.b\).*\1' ab.txt
输出:
1 文档ab.txt有以下内容
2 [root@localhost ~]# cat ab.txt
3 ababababx
4 aqbhelloaqb123
5 acbhiacb123
6 awbhelloawb123
7 aabhiaab123
8 ccacboooooacb
实例15:-v:反向选取,注意加参数后是后面所有行的反向选取。^只是代表的是后面紧跟着的元字符的反向选取。
命令:
grep -v 'ab' ab.txt
输出
1 [root@localhost ~]# grep -v 'ab' ab.txt
2 aqbhelloaqb123
3 acbhiacb123
4 awbhelloawb123
5 ccacboooooacb
实例16:-A #:显示查找的到文件并显示下面#行
命令:
grep -A 2 'root' /etc/passwd
输出

说明:
显示匹配到的行后并匹配其下面的2行。-B是显示上面的2行,-C是上下2行。
正则表达式后面还有扩展正则表达式,将在egrep命令及扩展正则表达式中提到。
本博文由于编辑器的问题,插入的代码有些无法着色,所以就用图片代替。
grep命令及基本正则表达式的更多相关文章
- Linux grep 命令中的正则表达式详解
在 Linux .类 Unix 系统中我该如何使用 Grep 命令的正则表达式呢? Linux 附带有 GNU grep 命令工具,它支持扩展正则表达式(extended regular expres ...
- Linux学习笔记之grep命令和使用正则表达式
0x00 正则表达式概述 正则表达式是描述一些字符串的模式,是由一些元字符和字符组成的字符串,而这些元字符是一些表示特殊意义的字符,即被正则表达式引擎表达的字符表示与其本意不同的一些字符. 0x01 ...
- grep命令的常用选项
Linux的grep命令是使用正则表达式进行文本搜索的,一些对程序员很有用的选项如下: -i 忽略大小写 -w 进行普通文件匹配,而不是正则表达式匹配 -c 只统计每个文件中匹配行数(默认是输 ...
- 快速掌握grep命令及正则表达式
Linux系统自带了支持拓展正则表达式的 GNU 版本 grep 工具,所有的Linux发行版中均默认安装grep ,grep 命令被用来检索一台服务器或工作站上任何位置的文本信息,如何在 Linux ...
- 正则表达式2——grep命令
grep是Global search Regular Expression and Print out the line的简称. 1. grep命令基本用法 命令格式: grep [选项][模式][文 ...
- Linux - 结合正则表达式使用grep命令
Grep with Regular Expression grep命令基本用法 grep [-acinv] [--color=auto] [-A n] [-B n] '搜寻字符串' 文件名参数说明: ...
- 07 grep命令与正则表达式
grep命令 首先我们知道grep命令是用来做文件内容过滤的!如果你要在文件中查找一些对应的内容,我们如何来过滤找到其中我们需要符合条件的内容呢?grep命令结合正则表达式就可以实现: grep.eg ...
- linux:正则表达式grep命令
基本语法一个正则表达式通常被称为一个模式(pattern),为用来描述或者匹配一系列符合某个句法规则的字符串. 一.选择:| | 竖直分隔符表示选择,例如"boy|girl"可 ...
- 正则表达式grep命令
grep命令 作用:文本搜索工具,根据用户指定的“模式”对目标文本逐行进行匹配检查:打印匹配到的行. 模式::由正则表达式字符及文本字符所编写的过滤条件 语法:grep [OPTIONS] PATTE ...
随机推荐
- 伸缩的菜单,用toggle()重写
<!DOCTYPE ><html><head><meta charset="UTF-8"/><title>伸缩的菜单,用 ...
- Codeforces 869E The Untended Antiquity
题意:给定一个网格图,三种操作:1.在(r1,c1,r2,c2)处建围墙.2.删除(r1,c1,r2,c2)处的围墙.3.询问两点是否可达 思路比较巧妙,将围墙内的点赋加一个权值,询问的时候判断两个点 ...
- TCP程序中发送和接收数据
这里我们来探讨一下在网络编程过程中,有关read/write 或者send/recv的使用细节.这里有关常用的阻塞/非阻塞的解释在网上有很多很好的例子,这里就不说了,还有errno ==EAGAIN ...
- Linux中如何恢复rm命令误删除的文件之extundelete编译安装及使用
1.下载extundelete包,安装依赖 我用的是Centos系统,在安装extundelete之前需要安装e2fsprogs,e2fsprogs-libs,e2fsprogs-devel. yum ...
- NHibernate之旅(13):初探马上载入机制
本节内容 引入 马上载入 实例分析 1.一对多关系实例 2.多对多关系实例 结语 引入 通过上一篇的介绍,我们知道了NHibernate中默认的载入机制--延迟载入.其本质就是使用GoF23中代理模式 ...
- JS 循环遍历JSON数据 分类: JS技术 JS JQuery 2010-12-01 13:56 43646人阅读 评论(5) 收藏 举报 jsonc JSON数据如:{"options":"[{
JS 循环遍历JSON数据 分类: JS技术 JS JQuery2010-12-01 13:56 43646人阅读 评论(5) 收藏 举报 jsonc JSON数据如:{"options&q ...
- 几条jQuery代码片段助力Web开发效率提升
平滑滚动至页面顶部 以下是jQuery最为常见的一种实现效果:点击一条链接以平滑滚动至页面顶部.虽然没什么新鲜感可言,但每位开发者几乎都用得上. $("a[href='#top']" ...
- 将CSS放头部,JS放底部,可以提高页面的性能的原因
css不阻止dom的解析 js阻止dom的解析 css js都会阻止dom的渲染 原因: js有可能影响dom的解析,比如在js里面新增dom等这些操作 css不能影响dom的解析 而 dom的渲染 ...
- 【SqlServer系列】JSON数据
1 概述 本文将结合MSDN简要概述JSON数据. 2 具体内容 JSON 是一种流行的数据格式,用于在现代 Web 和移动应用程序中交换数据. JSON 还可用于在 Microsoft Az ...
- CS:APP3e 深入理解计算机系统_3e Datalab实验
由于http://csapp.cs.cmu.edu/并未完全开放实验,很多附加实验做不了,一些环境也没办法搭建,更没有标准答案.做了这个实验的朋友可以和我对对答案:) 实验内容和要求可在http:// ...