zookeeper的安装与配置
单机模式:
1、首先去官网下载zookeeper的包 zookeeper-3.4.10.tar.gz
2、用FTP上传到服务器或者Linux虚拟机的/usr/local目录下
3、解压文件tar -zxvf zookeeper-3.4.10.tar.gz
4、在conf文件夹下新建zoo.cfg文件,或者使用里面自带的zoo_sample.cfg,重新cp zoo_sample.cfg zoo.cfg
zoo.cfg文件内容:
tickTime=2000
dataDir=/Users/zookeeper/data
dataLogDir=/Users/zookeeper/logs
clientPort=4180
至此, zookeeper的单机模式已经配置好了. 启动server只需运行脚本:
5、运行server脚本
./zkServer.sh start
6、Server启动之后, 就可以启动client连接server了, 执行脚本:
./zkCli.sh -server localhost:4180
(本次操作还是在本server上操作,你看localhost了嘛)
伪集群模式:
所谓伪集群, 是指在单台机器中启动多个zookeeper进程, 并组成一个集群. 以启动3个zookeeper进程为例.
1、首先去官网下载zookeeper的包 zookeeper-3.4.10.tar.gz
2、用FTP文上传到/usr/local下
3、解压文件tar -zxvf zookeeper-3.4.10.tar.gz
4、复制3分zookeeper文件
cp -r zookeeper-3.4.10.tar.gz zookeeper0
cp -r zookeeper-3.4.10.tar.gz zookeeper1
cp -r zookeeper-3.4.10.tar.gz zookeeper2
5、在每个zookeeper/conf/新建zoo.cfg文件
① zookeeper0下的zoo.cfg文件
tickTime=2000
initLimit=5
syncLimit=2
dataDir=/Users/zookeeper0/data
dataLogDir=/Users/zookeeper0/logs
clientPort=4180
server.0=127.0.0.1:8880:7770
server.1=127.0.0.1:8881:7771
server.2=127.0.0.1:8882:7772
② zookeeper1下的zoo.cfg文件
tickTime=2000
initLimit=5
syncLimit=2
dataDir=/Users/zookeeper1/data
dataLogDir=/Users/zookeeper1/logs
clientPort=4181
server.0=127.0.0.1:8880:7770
server.1=127.0.0.1:8881:7771
server.2=127.0.0.1:8882:7772
③ zookeeper2下的zoo.cfg文件
tickTime=2000
initLimit=5
syncLimit=2
dataDir=/Users/zookeeper2/data
dataLogDir=/Users/zookeeper2/logs
clientPort=4182
server.0=127.0.0.1:8880:7770
server.1=127.0.0.1:8881:7771
server.2=127.0.0.1:8882:7772
发现只有dataDir和dataLogDir还有clientPort这三个参数不一致,其他参数完全一致。
6、在这三个datadir配置的路径下/Users/zookeeper0、1、2上增加myid文件,里面依次填上0、1、2。
数字0、1、2和每个conf/zoo.cfg中的server.0、server.1、server.2的数字一一对应,让zookeeper知道你是哪个server
7、分别给这3个zookeeper节点开启服务
./zkServer.sh start
开启后,最好每个zookeeper都查看状态看一下服务是否启动:(因为start的启动的信息不准确)
./zkServer.sh status
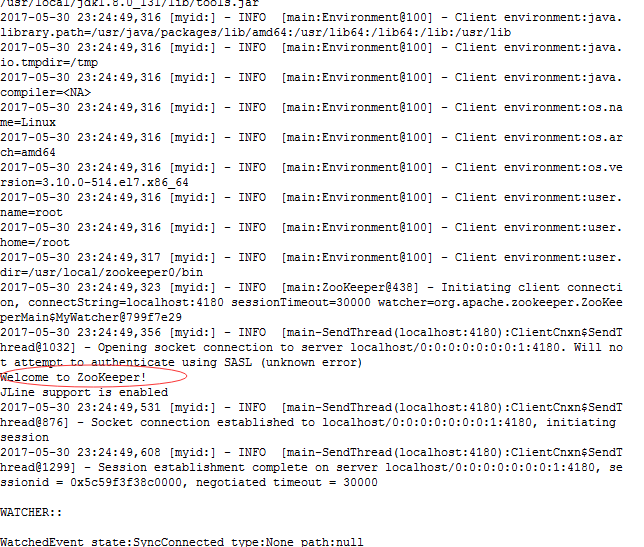
8、用客户端连接:
在任意一台server端,执行:
./zkCli.sh -server localhost:
看到以下信息,就恭喜你成功了。
集群模式:
集群模式, 各server部署在不同的机器上, 因此各server的conf/zoo.cfg文件可以完全一样(是所有都一样)
他们的zookeeper的conf下的zoo.cfg文件为:
tickTime=
initLimit=
syncLimit=
dataDir=/home/zookeeper/data
dataLogDir=/home/zookeeper/logs
clientPort=
server.=10.1.39.43::
server.=10.1.39.44::
server.=10.1.39.45::
部署了3台zookeeper server, 分别部署在10.1.39.43, 10.1.39.44, 10.1.39.45上。
各server的dataDir目录下的myid文件中的数字必须不同。
10.1.39.43 server的myid为1
10.1.39.44 server的myid为2
10.1.39.45 server的myid为3
至此,所有的安装与部署就都搞定了。
------------------------------------------------------------------------------
下面还有一些知识点:
ZooKeeper服务命令:
在准备好相应的配置之后,可以直接通过zkServer.sh 这个脚本进行服务的相关操作
- 1. 启动ZK服务: sh bin/zkServer.sh start
- 2. 查看ZK服务状态: sh bin/zkServer.sh status
- 3. 停止ZK服务: sh bin/zkServer.sh stop
- 4. 重启ZK服务: sh bin/zkServer.sh restart
zoo.cfg配置详解:
tickTime:Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,每个tickTime 时间就会发送一个心跳。
dataDir:Zookeeper 保存数据的目录,默认情况下,Zookeeper 将写数据的日志文件也保存在这个目录里。
clientPort:客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求。
initLimit:Leader和Follower初始化连接时最长能忍受多少个心跳时间间隔数。总的时间长度就是 5*2000=10 秒。
syncLimit:Leader 与 Follower之间发送消息,最长不能超过多少个 tickTime 的时间长度,总的时间长度就是 2*2000=4 秒。
server.A=B:C:D:其中 A 是一个数字,表示这个是第几号服务器;B 是这个服务器的 ip 地址;C 表示的是这个服务器与集群中的 Leader 服务器交换信息的端口;D 表示的是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的 Leader,而这个端口就是用来执行选举时服务器相互通信的端口。如果是伪集群的配置方式,由于 B 都是一样,所以不同的 Zookeeper 实例通信端口号不能一样,所以要给它们分配不同的端口号。
myid文件:
除了修改 zoo.cfg 配置文件,集群模式下还要配置一个文件 myid,这个文件在 dataDir 目录下,这个文件里面就有一个数据就是 A 的值,Zookeeper 启动时会读取这个文件,拿到里面的数据与 zoo.cfg 里面的配置信息比较从而判断到底是哪个server。
server.1=10.1.39.43:2888:3888,很多人不理解为啥后面有两个端口?解释一下:
2888:标识这个服务器与集群中的leader服务器交换信息的端口
3888:leader挂掉时专门用来进行选举leader所用的端口
zookeeper的安装与配置的更多相关文章
- ZooKeeper的安装、配置、启动和使用(一)——单机模式
ZooKeeper的安装.配置.启动和使用(一)——单机模式 ZooKeeper的安装非常简单,它的工作模式分为单机模式.集群模式和伪集群模式,本博客旨在总结ZooKeeper单机模式下如何安装.配置 ...
- ZooKeeper 的安装和配置---单机和集群
如题本文介绍的是ZooKeeper 的安装和配置过程,此过程非常简单,关键是如何应用(将放在下节及相关节中介绍). 单机安装.配置: 安装非常简单,只要获取到 Zookeeper 的压缩包并解压到某个 ...
- Zookeeper的安装的配置
详见:http://blog.yemou.net/article/query/info/tytfjhfascvhzxcyt192 安装和配置详解 本文介绍的 Zookeeper 是以 3.2.2 这个 ...
- 初识zookeeper(1)之zookeeper的安装及配置
初识zookeeper(一)之zookeeper的安装及配置 1.简要介绍 zookeeper是一个分布式的应用程序协调服务,是Hadoop和Hbase的重要组件,是一个树型的目录服务,支持变更推送. ...
- 浅谈 zookeeper 原理,安装和配置
当前云计算流行, 单一机器额的处理能力已经不能满足我们的需求,不得不采用大量的服务集群.服务集群对外提供服务的过程中,有很多的配置需要随时更新,服务间需要协调工作,那么这些信息如何推送到各个节点?并且 ...
- Zookeeper的安装与配置、使用
Dubbo的介绍 如果表现层和服务层是不同的工程,然而表现层又要调用服务层的服务,肯定不能像之前那样,表现层和服务层在一个项目时,只需把服务层的Java类注入到表现层所需要的类中即可,但现在,表现层和 ...
- zookeeper之一 安装和配置(单机+集群)
这里我以zookeeper3.4.10.tar.gz来演示安装,安装到/usr/local/soft目录下. 一.单机版配置 1.安装和配置 #.下载 wget http://apache.fayea ...
- 初识zookeeper(一)之zookeeper的安装及配置
1.简要介绍 zookeeper是一个分布式的应用程序协调服务,是Hadoop和Hbase的重要组件,是一个树型的目录服务,支持变更推送.除此还可以用作dubbo服务的注册中心. 2.安装 2.1 下 ...
- Linux系统下zookeeper的安装和配置
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件.它是一个为分布式应用提供一致性服务的软件,提供的功 ...
随机推荐
- .Net Core MVC 过滤器(一)
1.过滤器 过滤器运行在MVC Action Invocation Pipeline(MVC Action 请求管道),我们称它为Filter Pipleline(过滤器管道),Filter Pi ...
- 网站与域名知识扫盲-DNS
域名概述 域名的概念 IP地址不易记忆 早期使用Hosts解析域名 主机名称重复 主机维护困难 DNS(Domain Name System 域名系统) 分布式 层次性 域名空间结构 根域 组织域[. ...
- ios 视频/图片压缩
- (void)viewDidLoad { [super viewDidLoad]; // Do any additional setup after loading the view, typica ...
- 基于appium的移动端自动化测试,密码键盘无法识别问题
基于appium做自动化测试,APP密码键盘无法识别问题解决思路 这个问题的解决思路如下: 1.针对iOS无序键盘:首先,iOS的密码键盘是可识别的,但是,密码键盘一般是无序的.针对这个情况,思路是用 ...
- cocos2d-x - C++/Lua交互
使用tolua++将自定义的C++类嵌入,让lua脚本使用 一般过程: 自定义类 -> 使用tolua++工具编译到LuaCoco2d.cpp中 -> lua调用 步骤一:自定义一个C++ ...
- Vmware Vsphere WebService之vijava 开发(二)一性能信息的采集(实时监控)
最近一直没有更新这部分的内容,会利用五一时间完成vcenter这一个系列. 这里先给大家一本关于vijava开发的书,比较实用. 地址:http://pan.baidu.com/s/1gfkl9mj. ...
- sass学习入门篇(三)
这章我们讲“嵌套”,嵌套包括两种:一,选择器嵌套.二是属性的嵌套.一般用选择器嵌套居多 一,选择器嵌套:指的是在一个选择器中嵌套另一个选择器来实现继承.使用&表示父元素选择器 li{ floa ...
- 用Entity Framework往数据库插数据时,出现异常,怎么查看异常的详细信息呢?
做项目时,在用Entity Framework往数据库插数据时,程序报异常,但是通过报的异常死活没法查看异常的详细信息.这让人很是烦恼.本着自己动手丰衣足食的原则,通过查看资料终于找到了显示异常详细信 ...
- JTextArea自动换行以及设置滚动条
应将JTextArea置于JScrollPanel中若要使只有垂直滚动条而没有水平滚动条,使用JTextArea.setLineWrap(true),自动换行. 文本换行代码片段如下: JTextAr ...
- 七牛整合 ueditor (拦住那头牛,七牛又如何)
最近遇到个项目,要求所有图片都必须整合到七牛上,看了把你谈文档踩在前辈们的基础上终于把他完成了,恰巧本屌丝最近刚好有时间,本着天下屌丝是一家的原则,和小朋友们一同学习 闲话少说入正题. 第一 :下载编 ...