GoogleNet:inceptionV3论文学习
Rethinking the Inception Architecture for Computer Vision
论文地址:https://arxiv.org/abs/1512.00567
Abstract
介绍了卷积网络在计算机视觉任务中state-of-the-art。分析现在现状,本文通过适当增加计算条件下,通过suitably factorized convolutions 和 aggressive regularization来扩大网络。并说明了取得的成果。
1. Introduction
介绍AlexNet后,推更深网络模型的提出。然后介绍GoogLeNet 考虑了内存和计算资源,五百万个参数,比六千万参数的 AlexNet 少12倍, VGGNet 则是AlexNet 的参数三倍多。提出了GoogLeNet 更适合于大数据的处理,尤其是内存或计算资源有限制的场合。原来Inception 架构的复杂性没有清晰的描述。本文主要提出了一些设计原理和优化思路。
2. General Design Principles
2.1避免特征表示瓶颈,尤其是在网络的前面。前馈网络可以通过一个无环图来表示,该图定义的是从输入层到分类器或回归器的信息流动。要避免严重压缩导致的瓶颈。特征表示尺寸应该温和的减少,从输入端到输出端。特征表示的维度只是一个粗浅的信息量表示,它丢掉了一些重要的因素如相关性结构。
2.2高纬信息更适合在网络的局部处理。在卷积网络中逐步增加非线性激活响应可以解耦合更多的特征,那么网络就会训练的更快。
2.3空间聚合可以通过低纬嵌入,不会导致网络表示能力的降低。例如在进行大尺寸的卷积(如3*3)之前,我们可以在空间聚合前先对输入信息进行降维处理,如果这些信号是容易压缩的,那么降维甚至可以加快学习速度。
2.4平衡好网络的深度和宽度。通过平衡网络每层滤波器的个数和网络的层数可以是网络达到最佳性能。增加网络的宽度和深度都会提升网络的性能,但是两者并行增加获得的性能提升是最大的。所以计算资源应该被合理的分配到网络的宽度和深度。
3. Factorizing Convolutions with Large Filter Size
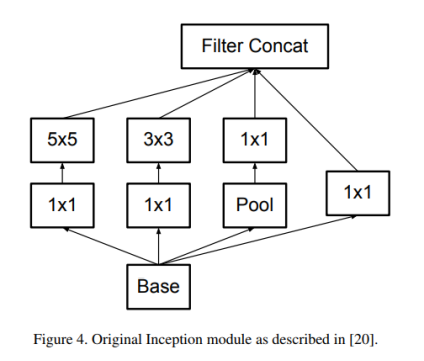
GoogLeNet 网络优异的性能主要源于大量使用降维处理。这种降维处理可以看做通过分解卷积来加快计算速度的手段。在一个计算机视觉网络中,相邻激活响应的输出是高度相关的,所以在聚合前降低这些激活影响数目不会降低局部表示能力。
3.1. Factorization into smaller convolutions
大尺寸滤波器的卷积(如5*5,7*7)引入的计算量很大。例如一个 5*5 的卷积比一个3*3卷积滤波器多25/9=2.78倍计算量。当然5*5滤波器可以学习到更多的信息。那么我们能不能使用一个多层感知器来代替这个 5*5 卷积滤波器。受到NIN的启发,用下面的方法,如图进行改进。
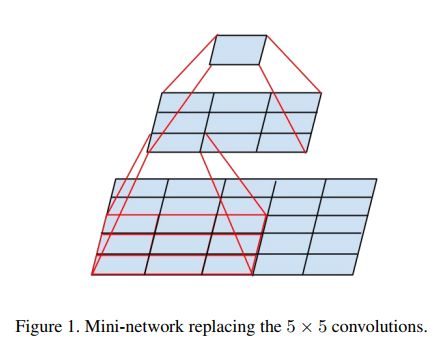
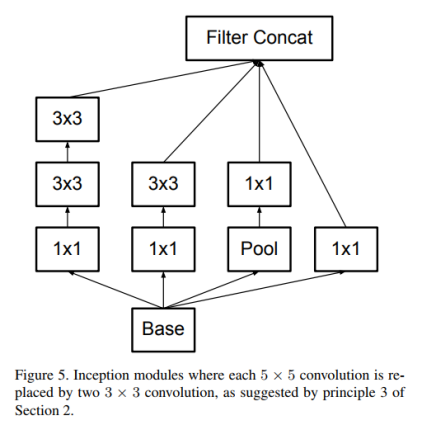
5*5卷积看做一个小的全链接网络在5*5区域滑动,我们可以先用一个3*3的卷积滤波器卷积,然后再用一个全链接层连接这个3*3卷积输出,这个全链接层我们也可以看做一个3*3卷积层。这样我们就可以用两个3*3卷积级联起来代替一个 5*5卷积。如图4,5所示。
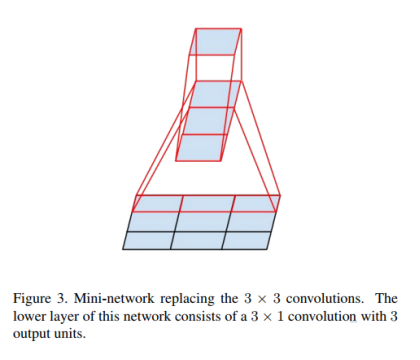
3.2. Spatial Factorization into Asymmetric Convolutions
空间上分解为非对称卷积,受之前启发,把3*3的卷积核分解为3*1+1*3来代替3*3的卷积。如图三所示,两层结构计算量减少33%。
4. Utility of Auxiliary Classifiers
引入了附加分类器,其目的是从而加快收敛。辅助分类器其实起着着regularizer的作用。当辅助分类器使用了batch-normalized或dropout时,主分类器效果会更好。
5. Efficient Grid Size Reduction
池化操作降低特征图大小,使用两个并行的步长为2的模块, P 和 C。P是一个池化层,然后将两个模型的响应组合到一起来更多的降低计算量。

6. Inception-v2
把7x7卷积替换为3个3x3卷积。包含3个Inception部分。第一部分是35x35x288,使用了2个3x3卷积代替了传统的5x5;第二部分减小了feature map,增多了filters,为17x17x768,使用了nx1->1xn结构;第三部分增多了filter,使用了卷积池化并行结构。网络有42层,但是计算量只有GoogLeNet的2.5倍。
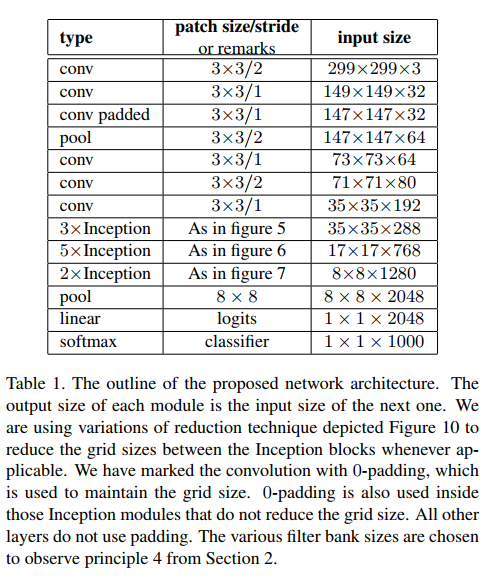
7. Model Regularization via Label Smoothing
输入x,模型计算得到类别为k的概率

假设真实分布为q(k),交叉熵损失函数
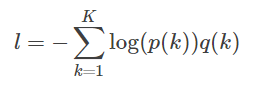
最小化交叉熵等价最大化似然函数。交叉熵函数对逻辑输出求导
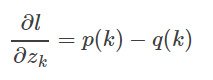
引入一个独立于样本分布的变量u(k)
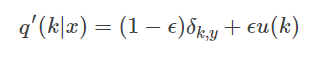
8. Training Methodology
TensorFlow 。
batch-size=32,epoch=100。SGD+momentum,momentum=0.9。
RMSProp,decay=0.9,ϵ=0.1。
lr=0.045,每2个epoch,衰减0.94。
梯度最大阈值=2.0。
9. Performance on Lower Resolution Input
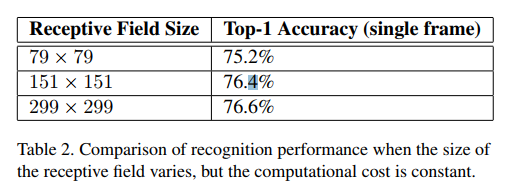
对于低分辨有图像,使用“高分辨率”receptive field。简单的办法是减小前2个卷积层的stride,去掉第一个pooling层。做了三个对比实验,实验结果
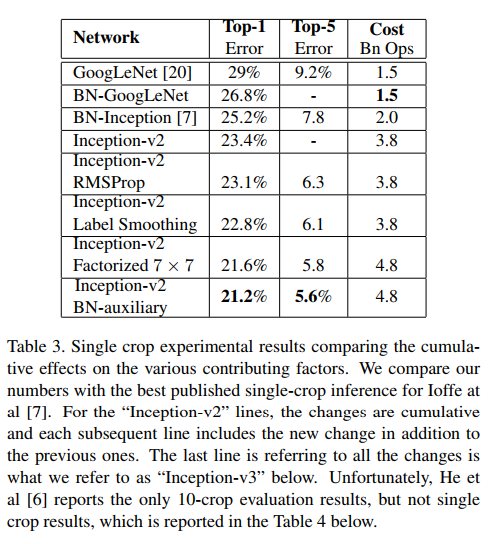
10. Experimental Results and Comparisons
实验结果和对比

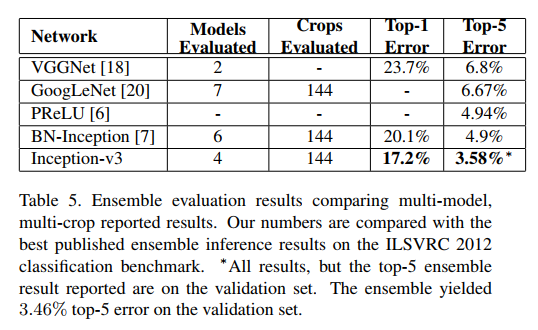
11. Conclusions
提供了几个扩大规模的设计原则卷积网络,并在其背景下进行了研究初始架构。这个指导可以导致很高的性能视觉网络有一个相对较小的计算成本比较简单,更单一架构。参数有效减小,计算量降低。我们还表明,输入分辨率79×79仍可以达到高达高质量结果。这可能有助于检测较小物体的系统。 我们研究了如何在神经网络中进行因式分解和积极维度降低可以导致网络具有相对低的计算成本,同时保持高质量。较低参数计数和附加正则化与批量归一化辅助分类器和标签平滑的组合允许在相对适度的训练集上训练高质量网络。
本文参考的博客
https://arxiv.org/abs/1512.00567
http://blog.csdn.net/KangRoger/article/details/69218625
http://blog.csdn.net/zhangjunhit/article/details/53894221
GoogleNet:inceptionV3论文学习的更多相关文章
- Faster RCNN论文学习
Faster R-CNN在Fast R-CNN的基础上的改进就是不再使用选择性搜索方法来提取框,效率慢,而是使用RPN网络来取代选择性搜索方法,不仅提高了速度,精确度也更高了 Faster R-CNN ...
- 《Explaining and harnessing adversarial examples》 论文学习报告
<Explaining and harnessing adversarial examples> 论文学习报告 组员:裴建新 赖妍菱 周子玉 2020-03-27 1 背景 Sz ...
- 论文学习笔记 - 高光谱 和 LiDAR 融合分类合集
A³CLNN: Spatial, Spectral and Multiscale Attention ConvLSTM Neural Network for Multisource Remote Se ...
- Apache Calcite 论文学习笔记
特别声明:本文来源于掘金,"预留"发表的[Apache Calcite 论文学习笔记](https://juejin.im/post/5d2ed6a96fb9a07eea32a6f ...
- 卷积神经网络之GoogleNet:inceptionV3模型学习
Rethinking the Inception Architecture for Computer Vision 论文地址:https://arxiv.org/abs/1512.00567 Abst ...
- 论文学习-系统评估卷积神经网络各项超参数设计的影响-Systematic evaluation of CNN advances on the ImageNet
博客:blog.shinelee.me | 博客园 | CSDN 写在前面 论文状态:Published in CVIU Volume 161 Issue C, August 2017 论文地址:ht ...
- SAGAN:Self-Attention Generative Adversarial Networks - 1 - 论文学习
Abstract 在这篇论文中,我们提出了自注意生成对抗网络(SAGAN),它是用于图像生成任务的允许注意力驱动的.长距离依赖的建模.传统的卷积GANs只根据低分辨率图上的空间局部点生成高分辨率细节. ...
- IEEE Trans 2008 Gradient Pursuits论文学习
之前所学习的论文中求解稀疏解的时候一般采用的都是最小二乘方法进行计算,为了降低计算复杂度和减少内存,这篇论文梯度追踪,属于贪婪算法中一种.主要为三种:梯度(gradient).共轭梯度(conjuga ...
- Raft论文学习笔记
先附上论文链接 https://pdos.csail.mit.edu/6.824/papers/raft-extended.pdf 最近在自学MIT的6.824分布式课程,找到两个比较好的githu ...
随机推荐
- 51nod_1040:最大公约数之和(数论)
题目链接:https://www.51nod.com/onlineJudge/questionCode.html#!problemId=1040 给出一个n,求1-n这n个数,同n的最大公约数的和. ...
- JMeter 监控和记录&常用功能
使用https连接时,如果对应站点的CA 证书错误,会直接报连接不到服务器的错误,org.apache.commons.httpclient.NoHttpResponseException,把错误证书 ...
- (转)sql union和union all的用法及效率
1 熟悉union的相关操作 UNION指令的目的是将两个SQL语句的结果合并起来.从这个角度来看, 我们会产生这样的感觉,UNION跟JOIN似乎有些许类似,因为这两个指令都可以由多个表格中撷取资料 ...
- plsql 数据迁移——导出表结构,表数据,表序号
场景:项目开发完之后要部署在不同的环境进行测试,这时候就需要将数据库中的表结构,序号,数据进行迁移,这时候就需要能够熟练的使用plsql. 问题: 导出的表结构,在另一个数据库中无法导入 部分表的数据 ...
- MySQL学习笔记(四):存储引擎的选择
一:几种常用存储引擎汇总表 二:如何选择 一句话:除非需要InnoDB 不具备的特性,并且没有其他办法替代,否则都应该优先考虑InnoDB:或者,不需要InnoDB的特性,并且其他的引擎更加合适当前情 ...
- AngularJS $compile动态生成html
angular.module('app') .directive('compile', function ($compile) { return function (scope, element, a ...
- year:2017 month:8 day:3
2017-08-03 JAVAse 1:静态变量和成员变量的区别: 所属不同:静态变量属于类,所以也称为类变量 成员变量属于对象,也称为实例变量 内存中位置不同:静态变量存储余方法区的静态区 成员变量 ...
- [补档]暑假集训D3总结
考试 集训第一次考试,然而- - 总共四道题,两道打了DFS,一道暴力,一道~~输出样例~~乱搞,都是泪啊- - 目前只改了三道,回头改完那道题再上题解吧- - T2 [Poi2010]Monot ...
- 表达式求值(二叉树方法/C++语言描述)(五)
本例中的二叉树图是使用Graphviz绘制的(Graphviz官网),在Ubuntu Linux下可以使用apt-get命令安装它: sudo apt-get install graphviz 表达式 ...
- CSS3伪类实现动画旋转效果
一个简单的动画效果demo,keyframes为关键帧,图片贴在代码下方.利用了伪类实现css3动画效果,初学者可以看一下,恩.<!doctype html> <html lang= ...