Day4 装饰器——迭代器——生成器
一 装饰器
1.1 函数对象
一 函数是第一类对象,即函数可以当作数据传递
- #1 可以被引用
- #2 可以当作参数传递
- #3 返回值可以是函数
- #3 可以当作容器类型的元素
二 利用该特性,优雅的取代多分支的if
- def foo():
- print('foo')
- def bar():
- print('bar')
- dic={
- 'foo':foo,
- 'bar':bar,
- }
- while True:
- choice=input('>>: ').strip()
- if choice in dic:
- dic[choice]()
1.2 函数嵌套
一 函数的嵌套调用
- def max(x,y):
- return x if x > y else y
- def max4(a,b,c,d):
- res1=max(a,b)
- res2=max(res1,c)
- res3=max(res2,d)
- return res3
- print(max4(1,2,3,4))
二 函数的嵌套定义
- def f1():
- def f2():
- def f3():
- print('from f3')
- f3()
- f2()
- f1()
- f3() #报错,为何?请看下一小节
1.3 名称空间和作用域
一 什么是名称空间?
- #名称空间:存放名字的地方,三种名称空间,(之前遗留的问题x=1,1存放于内存中,那名字x存放在哪里呢?名称空间正是存放名字x与1绑定关系的地方)
二 名称空间的加载顺序
- python test.py
- #1、python解释器先启动,因而首先加载的是:内置名称空间
- #2、执行test.py文件,然后以文件为基础,加载全局名称空间
- #3、在执行文件的过程中如果调用函数,则临时产生局部名称空间
三 名字的查找顺序
- 局部名称空间--->全局名称空间--->内置名称空间
- #需要注意的是:在全局无法查看局部的,在局部可以查看全局的,如下示例
- # max=1
- def f1():
- # max=2
- def f2():
- # max=3
- print(max)
- f2()
- f1()
- print(max)
四 作用域
- #1、作用域即范围
- - 全局范围(内置名称空间与全局名称空间属于该范围):全局存活,全局有效
- - 局部范围(局部名称空间属于该范围):临时存活,局部有效
- #2、作用域关系是在函数定义阶段就已经固定的,与函数的调用位置无关,如下
- x=1
- def f1():
- def f2():
- print(x)
- return f2
- x=100
- def f3(func):
- x=2
- func()
- x=10000
- f3(f1())
- #3、查看作用域:globals(),locals()
- LEGB 代表名字查找顺序: locals -> enclosing function -> globals -> __builtins__
- locals 是函数内的名字空间,包括局部变量和形参
- enclosing 外部嵌套函数的名字空间(闭包中常见)
- globals 全局变量,函数定义所在模块的名字空间
- builtins 内置模块的名字空间
五 global与nonlocal关键字
1.4 闭包函数
一 什么是闭包?
- #内部函数包含对外部作用域而非全局作用域的引用
- #提示:之前我们都是通过参数将外部的值传给函数,闭包提供了另外一种思路,包起来喽,包起呦,包起来哇
- def counter():
- n=0
- def incr():
- nonlocal n
- x=n
- n+=1
- return x
- return incr
- c=counter()
- print(c())
- print(c())
- print(c())
- print(c.__closure__[0].cell_contents) #查看闭包的元素
二 闭包的意义与应用
- #闭包的意义:返回的函数对象,不仅仅是一个函数对象,在该函数外还包裹了一层作用域,这使得,该函数无论在何处调用,优先使用自己外层包裹的作用域
- #应用领域:延迟计算(原来我们是传参,现在我们是包起来)
- from urllib.request import urlopen
- def index(url):
- def get():
- return urlopen(url).read()
- return get
- baidu=index('http://www.baidu.com')
- print(baidu().decode('utf-8'))
1.5 装饰器
一 为何要用装饰器
- #开放封闭原则:对修改封闭,对扩展开放
二 什么是装饰器
- 装饰器他人的器具,本身可以是任意可调用对象,被装饰者也可以是任意可调用对象。
- 强调装饰器的原则:1 不修改被装饰对象的源代码 2 不修改被装饰对象的调用方式
- 装饰器的目标:在遵循1和2的前提下,为被装饰对象添加上新功能
三 装饰器的使用
- import time
- def timmer(func):
- def wrapper(*args,**kwargs):
- start_time=time.time()
- res=func(*args,**kwargs)
- stop_time=time.time()
- print('run time is %s' %(stop_time-start_time))
- return res
- return wrapper
- @timmer
- def foo():
- time.sleep(3)
- print('from foo')
- foo()
- 无参装饰器
无参装饰器
- def auth(driver='file'):
- def auth2(func):
- def wrapper(*args,**kwargs):
- name=input("user: ")
- pwd=input("pwd: ")
- if driver == 'file':
- if name == 'egon' and pwd == '':
- print('login successful')
- res=func(*args,**kwargs)
- return res
- elif driver == 'ldap':
- print('ldap')
- return wrapper
- return auth2
- @auth(driver='file')
- def foo(name):
- print(name)
- foo('egon')
- 有参装饰器
有参装饰器
四 装饰器语法
- 被装饰函数的正上方,单独一行
- @deco1
- @deco2
- @deco3
- def foo():
- pass
- foo=deco1(deco2(deco3(foo)))
五 装饰器补充:wraps
- from functools import wraps
- def deco(func):
- @wraps(func) #加在最内层函数正上方
- def wrapper(*args,**kwargs):
- return func(*args,**kwargs)
- return wrapper
- @deco
- def index():
- '''哈哈哈哈'''
- print('from index')
- print(index.__doc__)
六 练习
一:编写函数,(函数执行的时间是随机的)
二:编写装饰器,为函数加上统计时间的功能
三:编写装饰器,为函数加上认证的功能
四:编写装饰器,为多个函数加上认证的功能(用户的账号密码来源于文件),要求登录成功一次,后续的函数都无需再输入用户名和密码
注意:从文件中读出字符串形式的字典,可以用eval('{"name":"egon","password":"123"}')转成字典格式
五:编写装饰器,为多个函数加上认证功能,要求登录成功一次,在超时时间内无需重复登录,超过了超时时间,则必须重新登录
六:编写下载网页内容的函数,要求功能是:用户传入一个url,函数返回下载页面的结果
七:为题目五编写装饰器,实现缓存网页内容的功能:
具体:实现下载的页面存放于文件中,如果文件内有值(文件大小不为0),就优先从文件中读取网页内容,否则,就去下载,然后存到文件中
扩展功能:用户可以选择缓存介质/缓存引擎,针对不同的url,缓存到不同的文件中
八:还记得我们用函数对象的概念,制作一个函数字典的操作吗,来来来,我们有更高大上的做法,在文件开头声明一个空字典,然后在每个函数前加上装饰器,完成自动添加到字典的操作
九 编写日志装饰器,实现功能如:一旦函数f1执行,则将消息2017-07-21 11:12:11 f1 run写入到日志文件中,日志文件路径可以指定
注意:时间格式的获取
import time
time.strftime('%Y-%m-%d %X')
- #题目一:
- import time,random
- ran = random.random()
- def foo():
- time.sleep(ran)
- print("Done")
- foo()
- #题目二:
- import time,random
- ran = random.random()
- def timer(func):
- def inner():
- start_time = time.time()
- func()
- stop_time = time.time()
- print("TIME>> %s" %(stop_time-start_time))
- return inner
- @timer
- def foo():
- time.sleep(ran)
- print("Done")
- foo()
- #题目三:
- import time,random
- ran = random.random()
- def auth(bar):
- def inner():
- info = {
- "lizhong":123,
- "hehe":234,
- }
- name = input("user>>").strip()
- if name in info:
- pwd = int(input("pwd>>").strip())
- if pwd == info[name]:
- print("Login success")
- bar()
- else:
- print("Login faild")
- else:
- print("No such user")
- return inner
- def timer(func):
- def inner():
- start_time = time.time()
- func()
- stop_time = time.time()
- print("TIME>> %s" %(stop_time-start_time))
- return inner
- @auth
- @timer
- def foo():
- time.sleep(ran)
- print("Done")
- while True:
- foo()
- #题目四:
- db='db.txt'
- login_status={'user':None,'status':False}
- def auth(auth_type='file'):
- def auth2(func):
- def wrapper(*args,**kwargs):
- if login_status['user'] and login_status['status']:
- return func(*args,**kwargs)
- if auth_type == 'file':
- with open(db,encoding='utf-8') as f:
- dic=eval(f.read())
- name=input('username: ').strip()
- password=input('password: ').strip()
- if name in dic and password == dic[name]:
- login_status['user']=name
- login_status['status']=True
- res=func(*args,**kwargs)
- return res
- else:
- print('username or password error')
- elif auth_type == 'sql':
- pass
- else:
- pass
- return wrapper
- return auth2
- @auth()
- def index():
- print('index')
- @auth(auth_type='file')
- def home(name):
- print('welcome %s to home' %name)
- # index()
- # home('egon')
- #题目五
- import time,random
- user={'user':None,'login_time':None,'timeout':0.000003,}
- def timmer(func):
- def wrapper(*args,**kwargs):
- s1=time.time()
- res=func(*args,**kwargs)
- s2=time.time()
- print('%s' %(s2-s1))
- return res
- return wrapper
- def auth(func):
- def wrapper(*args,**kwargs):
- if user['user']:
- timeout=time.time()-user['login_time']
- if timeout < user['timeout']:
- return func(*args,**kwargs)
- name=input('name>>: ').strip()
- password=input('password>>: ').strip()
- if name == 'egon' and password == '':
- user['user']=name
- user['login_time']=time.time()
- res=func(*args,**kwargs)
- return res
- return wrapper
- @auth
- def index():
- time.sleep(random.randrange(3))
- print('welcome to index')
- @auth
- def home(name):
- time.sleep(random.randrange(3))
- print('welcome %s to home ' %name)
- index()
- home('egon')
- #题目六:
- import requests
- import os
- def wget(url):
- res = requests.get(url)
- return res
- print(wget("http://baidu.com/"))
- #题目七:简单版本
- import requests
- import os
- cache_file='cache.txt'
- def make_cache(func):
- def wrapper(*args,**kwargs):
- if not os.path.exists(cache_file):
- with open(cache_file,'w'):pass
- if os.path.getsize(cache_file):
- with open(cache_file,'r',encoding='utf-8') as f:
- res=f.read()
- else:
- res=func(*args,**kwargs)
- with open(cache_file,'w',encoding='utf-8') as f:
- f.write(res)
- return res
- return wrapper
- @make_cache
- def get(url):
- return requests.get(url).text
- # res=get('https://www.python.org')
- # print(res)
- #题目七:扩展版本
- import requests,os,hashlib
- engine_settings={
- 'file':{'dirname':'./db'},
- 'mysql':{
- 'host':'127.0.0.1',
- 'port':3306,
- 'user':'root',
- 'password':''},
- 'redis':{
- 'host':'127.0.0.1',
- 'port':6379,
- 'user':'root',
- 'password':''},
- }
- def make_cache(engine='file'):
- if engine not in engine_settings:
- raise TypeError('egine not valid')
- def deco(func):
- def wrapper(url):
- if engine == 'file':
- m=hashlib.md5(url.encode('utf-8'))
- cache_filename=m.hexdigest()
- cache_filepath=r'%s/%s' %(engine_settings['file']['dirname'],cache_filename)
- if os.path.exists(cache_filepath) and os.path.getsize(cache_filepath):
- return open(cache_filepath,encoding='utf-8').read()
- res=func(url)
- with open(cache_filepath,'w',encoding='utf-8') as f:
- f.write(res)
- return res
- elif engine == 'mysql':
- pass
- elif engine == 'redis':
- pass
- else:
- pass
- return wrapper
- return deco
- @make_cache(engine='file')
- def get(url):
- return requests.get(url).text
- # print(get('https://www.python.org'))
- print(get('https://www.baidu.com'))
- #题目八
- route_dic={}
- def make_route(name):
- def deco(func):
- route_dic[name]=func
- return deco
- @make_route('select')
- def func1():
- print('select')
- @make_route('insert')
- def func2():
- print('insert')
- @make_route('update')
- def func3():
- print('update')
- @make_route('delete')
- def func4():
- print('delete')
- print(route_dic)
- #题目九
- import time
- import os
- def logger(logfile):
- def deco(func):
- if not os.path.exists(logfile):
- with open(logfile,'w'):pass
- def wrapper(*args,**kwargs):
- res=func(*args,**kwargs)
- with open(logfile,'a',encoding='utf-8') as f:
- f.write('%s %s run\n' %(time.strftime('%Y-%m-%d %X'),func.__name__))
- return res
- return wrapper
- return deco
- @logger(logfile='aaaaaaaaaaaaaaaaaaaaa.log')
- def index():
- print('index')
- index()
二 迭代器和生成器
2.1 迭代器
一 迭代的概念
- #迭代是一个重复的过程,每次重复即一次迭代,并且每次迭代的结果都是下一次迭代的初始值
- while True: #只是单纯地重复,因而不是迭代
- print('===>')
- l=[1,2,3]
- count=0
- while count < len(l): #迭代
- print(l[count])
- count+=1
二 为何要有迭代器?什么是可迭代对象?什么是迭代器对象?
- #1、为何要有迭代器?
- 对于序列类型:字符串、列表、元组,我们可以使用索引的方式迭代取出其包含的元素。但对于字典、集合、文件等类型是没有索引的,若还想取出其内部包含的元素,则必须找出一种不依赖于索引的迭代方式,这就是迭代器
- #2、什么是可迭代对象?
- 可迭代对象指的是内置有__iter__方法的对象,即obj.__iter__,如下
- 'hello'.__iter__
- (1,2,3).__iter__
- [1,2,3].__iter__
- {'a':1}.__iter__
- {'a','b'}.__iter__
- open('a.txt').__iter__
- #3、什么是迭代器对象?
- 可迭代对象执行obj.__iter__()得到的结果就是迭代器对象
- 而迭代器对象指的是即内置有__iter__又内置有__next__方法的对象
- 文件类型是迭代器对象
- open('a.txt').__iter__()
- open('a.txt').__next__()
- #4、注意:
- 迭代器对象一定是可迭代对象,而可迭代对象不一定是迭代器对象
三 迭代器对象的使用
- dic={'a':1,'b':2,'c':3}
- iter_dic=dic.__iter__() #得到迭代器对象,迭代器对象即有__iter__又有__next__,但是:迭代器.__iter__()得到的仍然是迭代器本身
- iter_dic.__iter__() is iter_dic #True
- print(iter_dic.__next__()) #等同于next(iter_dic)
- print(iter_dic.__next__()) #等同于next(iter_dic)
- print(iter_dic.__next__()) #等同于next(iter_dic)
- # print(iter_dic.__next__()) #抛出异常StopIteration,或者说结束标志
- #有了迭代器,我们就可以不依赖索引迭代取值了
- iter_dic=dic.__iter__()
- while 1:
- try:
- k=next(iter_dic)
- print(dic[k])
- except StopIteration:
- break
- #这么写太丑陋了,需要我们自己捕捉异常,控制next,python这么牛逼,能不能帮我解决呢?能,请看for循环
四 for循环
- #基于for循环,我们可以完全不再依赖索引去取值了
- dic={'a':1,'b':2,'c':3}
- for k in dic:
- print(dic[k])
- #for循环的工作原理
- #1:执行in后对象的dic.__iter__()方法,得到一个迭代器对象iter_dic
- #2: 执行next(iter_dic),将得到的值赋值给k,然后执行循环体代码
- #3: 重复过程2,直到捕捉到异常StopIteration,结束循环
五 迭代器的优缺点
- #优点:
- - 提供一种统一的、不依赖于索引的迭代方式
- - 惰性计算,节省内存
- #缺点:
- - 无法获取长度(只有在next完毕才知道到底有几个值)
- - 一次性的,只能往后走,不能往前退
2.2 生成器
一 什么是生成器
- #只要函数内部包含有yield关键字,那么函数名()的到的结果就是生成器,并且不会执行函数内部代码
- def func():
- print('====>first')
- yield 1
- print('====>second')
- yield 2
- print('====>third')
- yield 3
- print('====>end')
- g=func()
- print(g) #<generator object func at 0x0000000002184360>
二 生成器就是迭代器
- g.__iter__
- g.__next__
- #2、所以生成器就是迭代器,因此可以这么取值
- res=next(g)
- print(res)
三 练习
1、自定义函数模拟range(1,7,2)
2、模拟管道,实现功能:tail -f access.log | grep '404'
- #题目一:
- def my_range(start,stop,step=1):
- while start < stop:
- yield start
- start+=step
- #执行函数得到生成器,本质就是迭代器
- obj=my_range(1,7,2) #1 3 5
- print(next(obj))
- print(next(obj))
- print(next(obj))
- print(next(obj)) #StopIteration
- #应用于for循环
- for i in my_range(1,7,2):
- print(i)
- #题目二
- import time
- def tail(filepath):
- with open(filepath,'rb') as f:
- f.seek(0,2)
- while True:
- line=f.readline()
- if line:
- yield line
- else:
- time.sleep(0.2)
- def grep(pattern,lines):
- for line in lines:
- line=line.decode('utf-8')
- if pattern in line:
- yield line
- for line in grep('',tail('access.log')):
- print(line,end='')
- #测试
- with open('access.log','a',encoding='utf-8') as f:
- f.write('出错啦404\n')
四 协程函数
- #yield关键字的另外一种使用形式:表达式形式的yield
- def eater(name):
- print('%s 准备开始吃饭啦' %name)
- food_list=[]
- while True:
- food=yield food_list
- print('%s 吃了 %s' % (name,food))
- food_list.append(food)
- g=eater('egon')
- g.send(None) #对于表达式形式的yield,在使用时,第一次必须传None,g.send(None)等同于next(g)
- g.send('蒸羊羔')
- g.send('蒸鹿茸')
- g.send('蒸熊掌')
- g.send('烧素鸭')
- g.close()
- g.send('烧素鹅')
- g.send('烧鹿尾')
五 练习
1、编写装饰器,实现初始化协程函数的功能
2、实现功能:grep -rl 'python' /etc
- #题目一:
- def init(func):
- def wrapper(*args,**kwargs):
- g=func(*args,**kwargs)
- next(g)
- return g
- return wrapper
- @init
- def eater(name):
- print('%s 准备开始吃饭啦' %name)
- food_list=[]
- while True:
- food=yield food_list
- print('%s 吃了 %s' % (name,food))
- food_list.append(food)
- g=eater('egon')
- g.send('蒸羊羔')
- #题目二:
- #注意:target.send(...)在拿到target的返回值后才算执行结束
- import os
- def init(func):
- def wrapper(*args,**kwargs):
- g=func(*args,**kwargs)
- next(g)
- return g
- return wrapper
- @init
- def search(target):
- while True:
- filepath=yield
- g=os.walk(filepath)
- for dirname,_,files in g:
- for file in files:
- abs_path=r'%s\%s' %(dirname,file)
- target.send(abs_path)
- @init
- def opener(target):
- while True:
- abs_path=yield
- with open(abs_path,'rb') as f:
- target.send((f,abs_path))
- @init
- def cat(target):
- while True:
- f,abs_path=yield
- for line in f:
- res=target.send((line,abs_path))
- if res:
- break
- @init
- def grep(pattern,target):
- tag=False
- while True:
- line,abs_path=yield tag
- tag=False
- if pattern.encode('utf-8') in line:
- target.send(abs_path)
- tag=True
- @init
- def printer():
- while True:
- abs_path=yield
- print(abs_path)
- g=search(opener(cat(grep('你好',printer()))))
- # g.send(r'E:\CMS\aaa\db')
- g=search(opener(cat(grep('python',printer()))))
- g.send(r'E:\CMS\aaa\db')
六 yield总结
- #1、把函数做成迭代器
- #2、对比return,可以返回多次值,可以挂起/保存函数的运行状态
2.3 面向过程编程
- #1、首先强调:面向过程编程绝对不是用函数编程这么简单,面向过程是一种编程思路、思想,而编程思路是不依赖于具体的语言或语法的。言外之意是即使我们不依赖于函数,也可以基于面向过程的思想编写程序
- #2、定义
- 面向过程的核心是过程二字,过程指的是解决问题的步骤,即先干什么再干什么
- 基于面向过程设计程序就好比在设计一条流水线,是一种机械式的思维方式
- #3、优点:复杂的问题流程化,进而简单化
- #4、缺点:可扩展性差,修改流水线的任意一个阶段,都会牵一发而动全身
- #5、应用:扩展性要求不高的场景,典型案例如linux内核,git,httpd
- #6、举例
- 流水线1:
- 用户输入用户名、密码--->用户验证--->欢迎界面
- 流水线2:
- 用户输入sql--->sql解析--->执行功能
三 三元表达式、列表推导式、生成器表达式
3.1 三元表达式
- name=input('姓名>>: ')
- res='SB' if name == 'alex' else 'NB'
- print(res)
3.2 列表推导式
- #1、示例
- egg_list=[]
- for i in range(10):
- egg_list.append('鸡蛋%s' %i)
- egg_list=['鸡蛋%s' %i for i in range(10)]
- #2、语法
- [expression for item1 in iterable1 if condition1
- for item2 in iterable2 if condition2
- ...
- for itemN in iterableN if conditionN
- ]
- 类似于
- res=[]
- for item1 in iterable1:
- if condition1:
- for item2 in iterable2:
- if condition2
- ...
- for itemN in iterableN:
- if conditionN:
- res.append(expression)
- #3、优点:方便,改变了编程习惯,可称之为声明式编程
3.3 生成器表达式
- #1、把列表推导式的[]换成()就是生成器表达式
- #2、示例:生一筐鸡蛋变成给你一只老母鸡,用的时候就下蛋,这也是生成器的特性
- >>> chicken=('鸡蛋%s' %i for i in range(5))
- >>> chicken
- <generator object <genexpr> at 0x10143f200>
- >>> next(chicken)
- '鸡蛋0'
- >>> list(chicken) #因chicken可迭代,因而可以转成列表
- ['鸡蛋1', '鸡蛋2', '鸡蛋3', '鸡蛋4',]
- #3、优点:省内存,一次只产生一个值在内存中
3.4 练习
1、将names=['egon','alex_sb','wupeiqi','yuanhao']中的名字全部变大写
2、将names=['egon','alex_sb','wupeiqi','yuanhao']中以sb结尾的名字过滤掉,然后保存剩下的名字长度
3、求文件a.txt中最长的行的长度(长度按字符个数算,需要使用max函数)
4、求文件a.txt中总共包含的字符个数?思考为何在第一次之后的n次sum求和得到的结果为0?(需要使用sum函数)
5、思考题
- with open('a.txt') as f:
- g=(len(line) for line in f)
- print(sum(g)) #为何报错?
6、文件shopping.txt内容如下
求总共花了多少钱?
打印出所有商品的信息,格式为[{'name':'xxx','price':333,'count':3},...]
求单价大于10000的商品信息,格式同上
- #题目一
- names=['egon','alex_sb','wupeiqi','yuanhao']
- names=[name.upper() for name in names]
- #题目二
- names=['egon','alex_sb','wupeiqi','yuanhao']
- names=[len(name) for name in names if not name.endswith('sb')]
- #题目三
- with open('a.txt',encoding='utf-8') as f:
- print(max(len(line) for line in f))
- #题目四
- with open('a.txt', encoding='utf-8') as f:
- print(sum(len(line) for line in f))
- print(sum(len(line) for line in f)) #求包换换行符在内的文件所有的字符数,为何得到的值为0?
- print(sum(len(line) for line in f)) #求包换换行符在内的文件所有的字符数,为何得到的值为0?
- #题目五(略)
- #题目六:每次必须重新打开文件或seek到文件开头,因为迭代完一次就结束了
- with open('a.txt',encoding='utf-8') as f:
- info=[line.split() for line in f]
- cost=sum(float(unit_price)*int(count) for _,unit_price,count in info)
- print(cost)
- with open('a.txt',encoding='utf-8') as f:
- info=[{
- 'name': line.split()[0],
- 'price': float(line.split()[1]),
- 'count': int(line.split()[2]),
- } for line in f]
- print(info)
- with open('a.txt',encoding='utf-8') as f:
- info=[{
- 'name': line.split()[0],
- 'price': float(line.split()[1]),
- 'count': int(line.split()[2]),
- } for line in f if float(line.split()[1]) > 10000]
- print(info)
四 json & pickle 模块
之前我们学习过用eval内置方法可以将一个字符串转成python对象,不过,eval方法是有局限性的,对于普通的数据类型,json.loads和eval都能用,但遇到特殊类型的时候,eval就不管用了,所以eval的重点还是通常用来执行一个字符串表达式,并返回表达式的值。
- import json
- x="[null,true,false,1]"
- print(eval(x)) #报错,无法解析null类型,而json就可以
- print(json.loads(x))
什么是序列化?
我们把对象(变量)从内存中变成可存储或传输的过程称之为序列化,在Python中叫pickling,在其他语言中也被称之为serialization,marshalling,flattening等等,都是一个意思。
为什么要序列化?
1:持久保存状态
需知一个软件/程序的执行就在处理一系列状态的变化,在编程语言中,'状态'会以各种各样有结构的数据类型(也可简单的理解为变量)的形式被保存在内存中。
内存是无法永久保存数据的,当程序运行了一段时间,我们断电或者重启程序,内存中关于这个程序的之前一段时间的数据(有结构)都被清空了。
在断电或重启程序之前将程序当前内存中所有的数据都保存下来(保存到文件中),以便于下次程序执行能够从文件中载入之前的数据,然后继续执行,这就是序列化。
具体的来说,你玩使命召唤闯到了第13关,你保存游戏状态,关机走人,下次再玩,还能从上次的位置开始继续闯关。或如,虚拟机状态的挂起等。
2:跨平台数据交互
序列化之后,不仅可以把序列化后的内容写入磁盘,还可以通过网络传输到别的机器上,如果收发的双方约定好实用一种序列化的格式,那么便打破了平台/语言差异化带来的限制,实现了跨平台数据交互。
反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化,即unpickling。
如何序列化之json和pickle:
json
如果我们要在不同的编程语言之间传递对象,就必须把对象序列化为标准格式,比如XML,但更好的方法是序列化为JSON,因为JSON表示出来就是一个字符串,可以被所有语言读取,也可以方便地存储到磁盘或者通过网络传输。JSON不仅是标准格式,并且比XML更快,而且可以直接在Web页面中读取,非常方便。
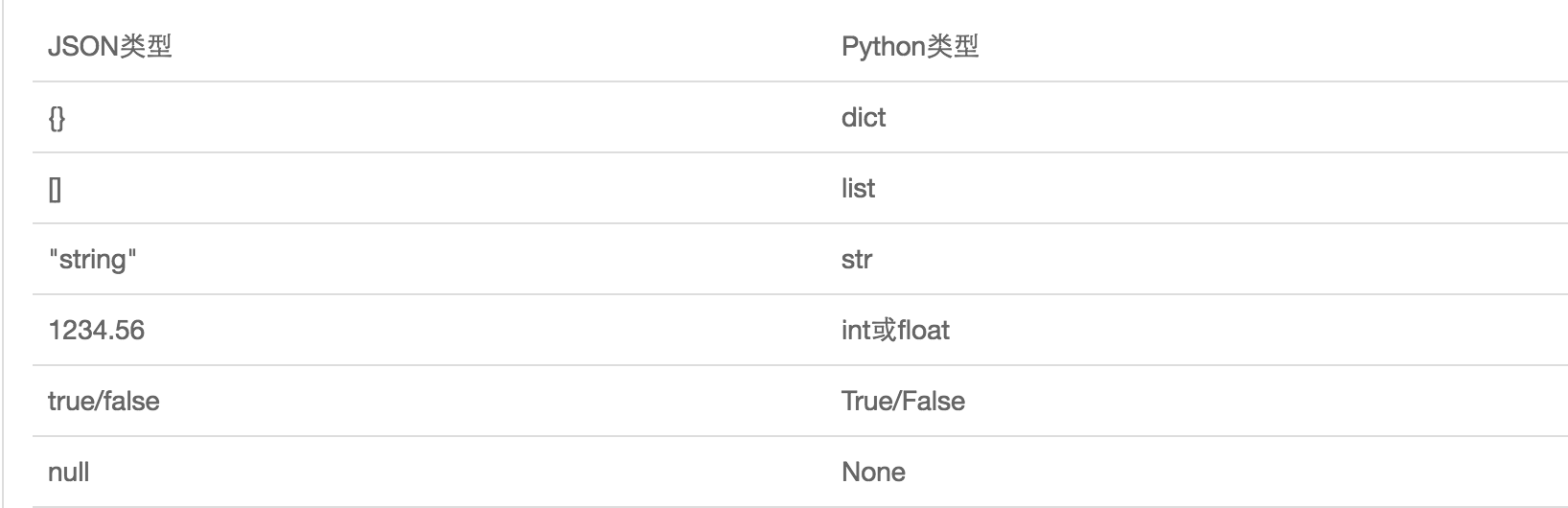
JSON表示的对象就是标准的JavaScript语言的对象,JSON和Python内置的数据类型对应如下:

- import json
- dic={'name':'alvin','age':23,'sex':'male'}
- print(type(dic))#<class 'dict'>
- j=json.dumps(dic)
- print(type(j))#<class 'str'>
- json.dump(obj,文件对象(w方式))
- json.load(文件对象(r模式)
- f=open('序列化对象','w')
- f.write(j) #-------------------等价于json.dump(dic,f)
- f.close()
- #-----------------------------反序列化<br>
- import json
- f=open('序列化对象')
- data=json.loads(f.read())# 等价于data=json.load(f)
pickle

- import pickle
- dic={'name':'alvin','age':23,'sex':'male'}
- print(type(dic))#<class 'dict'>
- j=pickle.dumps(dic)
- print(type(j))#<class 'bytes'>
- f=open('序列化对象_pickle','wb')#注意是w是写入str,wb是写入bytes,j是'bytes'
- f.write(j) #-------------------等价于pickle.dump(dic,f)
- f.close()
- #-------------------------反序列化
- import pickle
- f=open('序列化对象_pickle','rb')
- data=pickle.loads(f.read())# 等价于data=pickle.load(f)
- print(data['age'])
Pickle的问题和所有其他编程语言特有的序列化问题一样,就是它只能用于Python,并且可能不同版本的Python彼此都不兼容,因此,只能用Pickle保存那些不重要的数据,不能成功地反序列化也没关系。
Day4 装饰器——迭代器——生成器的更多相关文章
- day4装饰器-迭代器&&生成器
一.装饰器 定义:本质是函数,(装饰其他函数)就是为其它函数添加附加功能 原则:1.不能修改被装饰的函数的源代码 2.不能修改被装饰的函数的调用方式 实现装饰器知识储备: 1.函数及“变量” 2.高阶 ...
- python中的装饰器迭代器生成器
装饰器: 定义:本质是函数(装饰其它函数) 为其它函数添加附加功能 原则: 1 不能修改被装饰函数源代码 2 不修改被装饰函数调用方式 实现装饰器知识储备: 1 函数即‘’变量‘’ 2 高阶函数 ...
- Python学习---装饰器/迭代器/生成器的学习【all】
Python学习---装饰器的学习1210 Python学习---生成器的学习1210 Python学习---迭代器学习1210
- day04 装饰器 迭代器&生成器 Json & pickle 数据序列化 内置函数
回顾下上次的内容 转码过程: 先decode 为 Unicode(万国码 ) 然后encode 成需要的格式 3.0 默认是Unicode 不是UTF-8 所以不需要指定 如果非要转为U ...
- python_装饰器——迭代器——生成器
一.装饰器 1.什么是装饰器? 器=>工具,装饰=>增加功能 1.不修改源代码 2.不修改调用方式 装饰器是在遵循1和2原则的基础上为被装饰对象增加功能的工具 2.实现无参装饰器 1.无参 ...
- python装饰器,迭代器,生成器,协程
python装饰器[1] 首先先明白以下两点 #嵌套函数 def out1(): def inner1(): print(1234) inner1()#当没有加入inner时out()不会打印输出12 ...
- python笔记3 闭包 装饰器 迭代器 生成器 内置函数 初识递归 列表推导式 字典推导式
闭包 1, 闭包是嵌套在函数中的 2, 闭包是内层函数对外层函数的变量(非全局变量)的引用(改变) 3,闭包需要将其作为一个对象返回,而且必须逐层返回,直至最外层函数的返回值 闭包例子: def a1 ...
- Python中的装饰器,迭代器,生成器
1. 装饰器 装饰器他人的器具,本身可以是任意可调用对象,被装饰者也可以是任意可调用对象. 强调装饰器的原则:1 不修改被装饰对象的源代码 2 不修改被装饰对象的调用方式 装饰器的目标:在遵循1和2的 ...
- 装饰器、生成器,迭代器、Json & pickle 数据序列化
1. 列表生成器:代码例子 a=[i*2 for i in range(10)] print(a) 运行效果如下: D:\python35\python.exe D:/python培训/s14/day ...
随机推荐
- expander graph&random walk的一个小应用
此文主要总结的是一种随机算法,旨在判断一个expander图上两点是否连通.复杂度O(logn).算法思路清奇. expander graph博大精深,如果对expander graph的生成,fam ...
- hr用法
定义和用法 <hr> 标签在 HTML 页面中创建一条水平线. 水平分隔线(horizontal rule)可以在视觉上将文档分隔成各个部分. HTML 与 XHTML 之间的差异 在 H ...
- webpack教程(六)——分离组件代码
先来运行一下webpack命令, 看到app.js才4k. 安装一下react npm install react --sava-dev 在app/index.js文件内引入react 运行webpa ...
- Centos7.2下Nginx配置SSL支持https访问(站点是基于.Net Core2.0开发的WebApi)
准备工作 1.基于nginx部署好的站点(本文站点是基于.Net Core2.0开发的WebApi,有兴趣的同学可以跳http://www.cnblogs.com/GreedyL/p/7422796. ...
- 可编辑的EditorGridPanel
1.创建pannel是为可编辑的: new Ext.grid.EditorGridPanel 2.设置单击可以编辑属性: clickstoEdit: 1 3.在列设置添加文本编辑框 {header:& ...
- postman 第1节 安装启动(转)
安装: 1.mac app安装 浏览器访问https://www.getpostman.com/apps,选择Get the Mac App,下载安装即可 2.chrome app安装 浏览器访问ht ...
- Spring上传文件,图片,以及常见的问题
1. 在工程依赖库下添加文件上传jar包 commons-fileupload-1.2.2.jar commons-io-2.4.jar 2.在springMVC配置文件中配置视图解析multipar ...
- nginx小问题
配置nginx与ftp图片服务器:安装后,要在/usr/local/nginx/conf/nginx.conf里面的server中(带有localhost的那一块)修改为location \ {roo ...
- string和double之间的相互转换(C++)
很多人都写过这个标题的文章,但本文要解决的是确保负数的string和double也可以进行转换. 代码如下: string转double double stringToDouble(string nu ...
- 软件工程(GZSD2015)第三次作业提交进度
第三次作业题目请查看这里:软件工程(GZSD2015)第三次作业 开始进入第三次作业提交进度记录中,童鞋们,虚位以待哈... 2015年4月19号 徐镇.尚清丽,C语言 2015年4月21号 毛涛.徐 ...