写一写关于python开发面试的常遇到的问题以及解答吧,持续更新——看心情
1,什么是python中的魔术方法?
魔术方法是重载运算符的昵称,形式是__init__类似这样的前后双下滑线组成的,常用的__init__,__new__,__call__,__str__,__getitem__……等一堆。(过一段时间我会在博客里面更新一下关于这些运算符具体使用方法。)
2,什么是闭包,和装饰器有什么关系?
在一个外函数中定义了一个内函数,内函数里运用了外函数的临时变量,并且外函数的返回值是内函数的引用。这样就构成了一个闭包。
各位老铁们,是不是不懂啊,那就对了。接着往下看,看装饰器的写法(装饰器是闭包的最好体现)
那特么啥又是装饰器?,就是不改变原有代码的情况下给原有程序添加额外的功能,并减少重复代码的东东。
import time def deco(func):
def wrapper():
startTime = time.time()
func()
endTime = time.time()
msecs = (endTime - startTime)*1000
print("time is %d ms" %msecs)
return wrapper @deco
def func():
print("hello")
time.sleep(1)
稍有基础的小朋友应该秒懂,就是在外面定一个函数,在原函数上加@装饰器名字嘛!
如果现在已经懵懂了,那就让你变得在懵懂些吧!
import time
def register(active=True)
def deco(func):
def wrapper():
if active:
startTime = time.time()
func()
endTime = time.time()
msecs = (endTime - startTime)*1000
print("time is %d ms" %msecs)
else:
func()
return wrapper
return deco @deco(active=False)
def func():
print("hello")
time.sleep(1)
这个就是设了一个开关,判断,如果为真,就计算时间,否则,不算时间。
三,
l = [1,3.,5,7,9,0]
l = l.sort()
请问l现在是多少?
l = [1,3.,5,7,9,0]
l = l.sort()
print(l) >>>None
很多初学的小伙伴可能迷糊啊
这是因为直接调用sort是在原有基础上排序,没有返回值的!!
想有咋弄?
l = [1,3.,5,7,9,0]
l = sorted(l)
print(l) >>>[0, 1, 3.0, 5, 7, 9]
四,生成器和迭代器的区别?
生成器的本质就是迭代器,生成器本质就是函数里面有yield的关键字
yield和return的区别在于函数遇到yield,不会结束,只是hang住,但是return下就结束了
yield有个send()方法,可以给yield赋值
五,写一个裴波那契算法:
def fib(n):
a, b = 0, 1
while a < n:
print(a, end=' ')
a, b = b, a+b
print(a)
fib(1000)
六,<'.*'>和<'.*?'>区别?
贪心匹配和非贪心匹配,前者匹配尽可能长,后者匹配尽可能短。
七,统计一篇英文文章内每个单词出现频率,并返回出现频率最高的前10个单词及其出现次数
from collections import Counter
import re with open('a.txt', 'r', encoding='utf-8') as f:
txt = f.read()
c = Counter(re.split('\W+',txt)) #取出每个单词出现的个数
print(c)
ret = c.most_common(10) #取出频率最高的前10个
print(ret)
八,解释一下cookie和session
cookie和session本质上就是一系列的键值对,不过cookie是在浏览器生成保留的,但是session是一种服务端机制,相对而言session更加安全。将cookie替换为session方法,request.session['user]=username
九,django中常见的命令
python manage.py makemigrations
python manage.py migrate
python manage.py runserver
十,django字段模型常见的几个类型
1,AutoField,一个IntegerField类型的自动增量
2,BooleanField,用于存放布尔值类型的数据(True或者说False)
3,CharField,用于存放字符型的数据,必须指定max_length
4,DateField,日期的类型,必须是‘YYYY-MM-DD’的格式
5,DateTimeField,这个也是日期的类型,必须是‘YYYY-MM-DD HH:MM[:ss[.uuuuuu]][TZ]’格式!
6,DecimalField,小数型,用于存放小数的数字
7,EmailField,电子邮箱的类型
8,FilePathField,文件路径类型
9,FloatField,用于存放浮点型数据
10,IntegerField,integer类型,数值范围从-214783648——214783648
11,BigIntegerField,大的integer类型
12,GenericIpAdressField,存放IP地址类型的,字符串格式
13,NullBooleanField,像BooleanField类型,但是准许为空
14,PositiveIntegerField,像integerField类型,但是必须是正数或者是0
15,PositiveSmallIntegerField,像PositiveIntegerField类型,但是只是从0——23767
16,SlugField,Slug是短标签,只包括字母与数字与下划线与字符,通常在网址上使用,像CharField一样,必须指定max_length
17,SmallIntegerField,像IntegerField类型,范围从-32768——32767
18,TextField,用于存放文本类型的数据
19,TimeField,时间类型,‘HH:MM[:ss[.uuuuuu]]’格式
20,URLField,用于存放URL地址
21,BinaryField,存储原始二进制数据的字段。
十一,你是怎么做Django测试
unittest单元测试框架
关于单元测试,首先澄清两点误区:
1,不用单元测试框架一样可以编写单元测试,单元测试本质上就是通过一段代码去测试另一段代码
2,单元测试框架不仅可以用于程序单元级别的测试,同样可以用于UI自动化测试、接口自动化测试,以及移动APP自动化测试等。
十二,django的请求周期
Web服务器网关接口(Python Web Server Gateway Interface,缩写为WSGI)
1、首先走wsgi模块,这个模块也是一个协议,包括wsgiref和uwsgi。经过中间件
2、然后路由分配-------views视图
3、从数据库取数据-----------渲染到html
4、出中间件
十三,关于HTTP你了解多少?
HTTP协议是一种请求响应模型,永远都是客户端发送请求,客户端去响应请求。
他也是一种无状态协议,具体来说是什么意思呢?就像这次请求和上次请求之间没有关系一样。
一次HTTP操作称为事务,一般来讲分为4个步骤
①首先客户端和服务端建立连接。比方说点击一个连接……
②建立连接之后客户端会给服务端发送一个请求:格式如下:统一资源标识符URL,协议版本号,后面是MIME信息。包括服务器信息,实体信息和一些内容。
③服务器收到请求之后会给客户端一个及时的回应,格式为一种状态行,包括协议版本号,成功或者错误的代码。后面是MIME信息,服务器信息,实体信息等一堆内容。
④客户端收到信息之后,在用户显示屏上面显示信息,然后客户端和服务端断开连接。
如果在此过程中的任何一步产生错误的话,那么错误信息将会显示在用户的屏幕上,这个是HTTP协议自己完成的。
HTTP的头部信息:
头部是由众多头域组成的每一个头域是由域名、冒号(:)和域值三部分组成的。域名是和大小写是无关的。
域值之前可以有任意多个空格符,头域可以被扩展为多行,在每一行的开始处,都要有一个空格或者制表符为开头。
HTTP的请求方式:
GET、POST、HEAD、PUT、DELETE、OPTIONS、TRACE、CONNECT。
最常用的方式是GET/POST
------------------------------------------ 更新于2019年8月14日晚22.08---------------------------------------------------------------------------
一: 语言特性
1, Python 和其他语言的区别
python是一门语法简洁优美但功能强大的动态性语言,它具备强大且完备的第三方库;是解释型编程语言,属于动态语言
C语言和python相比,python的优点在于,第三方的库比较齐全,并且使用简洁,少量的代码就能够实现一些功能,如果使用c去实现同样的功能的话就可能会比较复杂,但相对而言python的运行速度相对c来讲就比较慢了,但python降低了我们的学习成本。
2,简述解释型语言和编译型语言
解释型语言是在运行程序的时候才进行翻译,每执行一次,就需要翻译一次,效率较低;
编译型语言就是直接 编译成机器可以执行的,只需要翻译一次,所以相对来讲效率较高;
3,python的解释器种类以及相关的特点?
① CPython : C语言开发的,目前使用范围最为广泛;
② IPython : 基于cpython智商的一个交互计时器,交互方式增强功能和CPython一样
③ PyPy : 目标是执行效率,采用JIT技术,对python代码进行动态编译,提高执行效率
④ JPython : 运行在Java上的解释器,直接把Python代码编译成Java字节码执行
⑤ IronPython : 运行在微软的.NET平台上的解释器,把python编译成.NET字节码。
4,Python3和python2的区别?
① print在3中必须加括号
② python2 中存在xrange,但是python3中只有range
③ python2默认的字符串类型是ASCII,python3中是Unicode
④ Python2中/结果是整形,python3中是浮点类型
⑤ Python2中声明元类:_metaclass_ = MetaClass;Python3中声明元类:class newclass(metaclass=MetaClass): pass
⑥ python2中为正常显示中文,需要引入coding声明,python3中不需要
⑦ python2是raw_input() 但是python3是input()
5,python2和Python3中的int和long区别?
python2中有int和long类型。int类型最大值不能超过sys.maxint,而且这个最大值是和平台相关的。可以通过在数字末尾附上一个L来定义长整形,显然,他比int类型表示的数字范围更大。
Python3只有一种整数类型int,大多数情况下,和Python2中的长整形类似。
6,xrange和range的区别?
xrange是在Python2中的语法。Python3中已经取消。区别在于range返回的是一个list对象,而xrange返回的是一个生成器,节约内存
二,编码规范
1, 何为PEP8
8号Python增强提案又称PEP8,他针对的Python代码格式而编订的风格指南。
2,Python之禅
通过 import this 语句可以获取其具体的内容。他告诉我们如何写出一段高校整洁的代码
3,了解Python的类型注解吗?
PEP484引入了类型提示,这使得可以对Python代码进行静态类型检查,在使用ide的时候可以获取参数的类型,更方便掺入参数,使用格式如下:
def xyt(num: int) -> None:
print(f"接收到的数字是:{num}") # 上面是什么意思呢?
# 我们可以在函数的参数部分使用参数名+: +类型,来指定参数可以接受的类型,这里的话就是num参数为int类型
# 后面->接的是返回值的类型。这里的返回值为None,然后通过fsting格式化字符串输出传入的数字
4, 了解DocStrings吗?
DocStrings文档字符串是一个重要工具,用于解释文档程序,主要用来解释代码。
我们可以在函数体的第一行使用一对三个单引号 ''' 或者一对三个双引号 """ 来定义文档字符串。
我们可以使用 __doc__(注意双下划线)调用函数中的文档字符串属性。
DocStrings 文档字符串使用惯例:它的首行简述函数功能,第二行空行,第三行为函数的具体描述。
def printMax(x,y):
'''打印两个数中的最大值。 两个值必须都是在整形数。'''
x=int(x)
y=int(y)
if x>y:
print(x,'最大')
else:
print(y,'最大') printMax(3,5)
print (printMax.__doc__) # 调用 doc >>> 5 最大
打印两个数中的最大值。 两个值必须都是在整形数。
5,列举python对象的命名规范,比如类or变量?
① 类: 首字母大写单词串,如 MyClass。内部类可以使用额外的前导下划线
② 变量: 小写,由下划线连接各个单词。方法名类似 常量:常量名所有字母大写 等
6, Python的注释有几种?
① 单行注释: 单行注释在行首是 #
② 多行注释可以使用三个单引号或三个双引号,包括要注释的内容。
7, 如何给函数加注释?
可以使用 docstring 配合类型注解
见第4条
8,如何给变量加注释?
a: str = "this is string type"
9, Python 代码缩进中是否支持 Tab 键和空格混用?
不允许 tab 键和空格键混用,这种现象在使用 sublime 的时候尤为明显。
一般推荐使用 4 个空格替代 tab 键。
10, 是否可以在一句 import 中导入多个库?
可以是可以,但是不推荐。因为一次导入多个模块可读性不是很好,所以一行导入一个模块会比较好。
同样的尽量少用 from modulename import *,因为判断某个函数或者属性的 来源有些困难,不方便调试,可读性也降低了。
11, 在给 Py 文件命名的时候需要注意什么?
给文件命名的时候不要和标准库库的一些模块重复,比如 abc。 另外要名字要有意义,不建议数字开头或者中文命名。
12, 例举几个规范 Python 代码风格的工具
pylint 和 flake8
13, 列出5个python标准库
os:提供了不少与操作系统相关联的函数
sys: 通常用于命令行参数
re: 正则匹配
math: 数学运算
datetime: 处理时间日期
三, 数据类型
1, 列举 Python 中的基本数据类型?
Python3 中有六个标准的数据类型:字符串(String)、数字(Digit)、列表(List)、元组(Tuple)、集合(Sets)、字典(Dictionary)。
2, 如何区别可变的数据类型和不可变的数据类型?
应该从对象的内存地址上来说:
① 可变数据类型:在内存地址不变的情况下,值可改变(列表和字典是可变类型,但是字典中的 key 值必须是不可变类型)
② 不可变数据类型:内存改变,值也跟着改变。(数字,字符串,布尔类型,都是不可变类型)可以通过 id() 方法进行内存地址的检测。
3, 将"hello world"转换为首字母大写"Hello World"
① 这个得看清题目是要求两个单词首字母都要大写,如果只是第一个单词首字母大小的话,只使用 capitalize 即可,但是这里是两个单词,所以用下面的方法。
arr = "hello world".split(" ")
new_str = f"{arr[0].capitalize()} {arr[1].capitalize()}"
print(new_str)
②
"hello world".title()
4, 如何检测字符串中只含有数字?
s1 = "".isdigit()
print(s1) s2 = "12223a".isdigit()
print(s2) #结果如下:
#True
#False
5,将字符串"ilovechina"进行反转
s1 = "ilovechina"[::-1]
print(s1)
6, python字符串格式化的方式有哪些?
%s,format,fstring(Python3.6 开始才支持,现在推荐的写法)
7, 有一个字符串开头和末尾都有空格,比如“ adabdw ”,要求写一个函数把这个字符串的前后空格都去掉
因为题目要是写一个函数所以我们不能直接使用 strip,不过我们可以把它封装到函数啊
def strip_function(s1):
return s1.strip() s1 = " adabdw "
print(strip_function(s1))
8,获取字符串”123456“最后的两个字符。
a = ""
print(a[-2::])
print(a[-2:])
9, 一个编码为 GBK 的字符串 S,要将其转成 UTF-8 编码的字符串,应如何操作?
a= "S".encode("gbk").decode("utf-8",'ignore')
print(a)
10,
(1)s="info:xiaoZhang 33 shandong",用正则切分字符串输出['info', 'xiaoZhang', '33', 'shandong']。
import re
# 需要根据冒号或者空格来进行切分
s = "info:xiaoZhang 33 shandong"
res = re.split(r":| ", s)
print(res)
(2)a = "你好 中国 ",去除多余空格只留一个空格。
s = "你好 中国 "
print(" ".join(s.split()))
11,
(1) 怎样将字符串转换为小写。
使用字符串的 lower() 方法。
(2) 单引号、双引号、三引号的区别?
单独使用单引号和双引号没什么区别,但是如果引号里面还需要使用引号的时候,就需要这两个配合使用了,然后说三引号,同样的三引号也分为三单引号和三双引号,两个都可以声名长的字符串时候使用,如果使用 docstring 就需要使用三双引号。
12, 对列表去重
list(set(AList))
13, 给定两个 list,A 和 B,找出相同元素和不同元素
A、B 中相同元素:print(set(A)&set(B))
A、B 中不同元素:print(set(A)^set(B))
14, [[1,2],[3,4],[5,6]] 一行代码展开该列表,得出 [1,2,3,4,5,6]
one_list = [j fori in l forj in i]
print(one_list)
15, 合并列表 [1,5,7,9] 和 [2,2,6,8]
使用 extend 和 + 都可以。
a = [1,5,7,9]
b = [2,2,6,8]
a.extend(b)
print(a)
16, 如何打乱一个列表的元素?
import random a = [1, 2, 3, 4, 5]
random.shuffle(a)
print(a)
拓展: 如果不可以使用shuffle呢?
import random
l = []
li = [1, 2, 3, 4, 5, 6, 7, 8]
for i in range(len(li)):
l.append(li.pop(random.randint(0, len(li) - 1)))
print(l)
17, 字典操作中 del 和 pop 有什么区别?
del 可以根据索引(元素所在位置)来删除的,没有返回值。
pop 可以根据索引弹出一个值,然后可以接收它的返回值。(返回值便是他所删除的值)
18, 按照字典的内的年龄排序
d1 = [
{'name':'alice', 'age':38},
{'name':'bob', 'age':18},
{'name':'Carl', 'age':28},
]
》》》》
d1 = [
{'name': 'alice', 'age': 38},
{'name': 'bob', 'age': 18},
{'name': 'Carl', 'age': 28},
] print(sorted(d1, key=lambda x:x["age"]))
19, 请合并下面两个字典 a = {"A":1,"B":2},b = {"C":3,"D":4}
合并字典方法很多,可以使用 a.update(b) 或者下面字典解包的方式
a = {"A":1,"B":2}
b = {"C":3,"D":4}
print({**a,**b})
20, 如何使用生成式的方式生成一个字典,写一段功能代码
# 需求 3: 把字典的 key 和 value 值调换;
d = {'a':'', 'b':''} print({v:k for k,v in d.items()})
21, 如何把元组 ("a","b") 和元组 (1,2),变为字典 {"a":1,"b":2}
zip 的使用,但是最后记得把 zip 对象再转换为字典。
a = ("a", "b")
b = (1, 2)
print(dict(zip(a, b)))
22, 下列字典对象键类型不正确的是?
A: {1:0,2:0,3:0}
B: {"a":0, "b":0, "c":0}
C: {(1,2):0, (2,3):0}
D: {[1,2]:0, [2,3]:0}
D 因为只有可 hash 的对象才能做字典的键,列表是可变类型不是可 hash 对象,所以不能用列表做为字典的键。
23, 如何交换字典 {"A":1,"B":2}的键和值
s = {"A":1,"B":2}
#方法一:
dict_new = {value:key for key,value in s.items()}
# 方法二:
new_s= dict(zip(s.values(),s.keys()))
24, Python 里面如何实现 tuple 和 list 的转换?
Python 中的类型转换,一般通过类型强转即可完成 tuple 转 list 是 list() 方法 list 转 tuple 使用 tuple() 方法
25, 我们知道对于列表可以使用切片操作进行部分元素的选择,那么如何对生成器类型的对象实现相同的功能呢?
这个题目考察了 Python 标准库的 itertools 模快的掌握情况,该模块提供了操作生成器的一些方法。 对于生成器类型我们使用 islice 方法来实现切片的功能。
例子如下:
from itertools import islice
gen = iter(range(10)) #iter()函数用来生成迭代器
#第一个参数是迭代器,第二个参数起始索引,第三个参数结束索引,不支持负数索引
for i in islice(gen,0,4):
print(i)
26, 请将 [i for i in range(3)] 改成生成器
通过把列表生产式的中括号,改为小括号我们就实现了生产器的功能即,
(i for i in range(3))
27, a="hello" 和 b="你好" 编码成 bytes 类型
这个题目一共三种方式,第一种是在字符串的前面加一个 b,第二种可以使用 bytes 方法,第三种使用字符串 encode 方法。具体代码如下,abc 代表三种情况
a = b"hello"
b = bytes("你好", "utf-8")
c = "你好".encode("utf-8")
print(a, b, c)
28, 下面的代码输出结果是什么?
a = (1,2,3,[4,5,6,7],8)
a[2] = 2
我们知道元组里的元素是不能改变的所以这个题目的答案是出现异常。
29, 下面的代码输出的结果是什么?
a = (1,2,3,[4,5,6,7],8)
a[3][0] = 2
前面我说了元组的里元素是不能改变的,这句话严格来说是不准确的,如果元组里面元素本身就是可变类型,比如列表,那么在操作这个元素里的对象时,其内存地址也是不变的。a[3] 对应的元素是列表,然后对列表第一个元素赋值,所以最后的结果是: (1,2,3,[2,5,6,7],8)
30, 一行代码实现1^100的和?
sum(range(1, 101))
31, 如何在一个函数内部修改全局变量
__autor__ = 'zhouli'
__date__ = '2019/8/17 18:52' a = 5 def fn():
global a
a = 4 fn()
print(a)
#
32, python交换变量?
a , b = b ,a
这并不是元组解包,通过 dis 模块可以发现,这是交换操作的字节码是 ROT_TWO,意思是在栈的顶端做两个值的互换操作。
33,在读文件操作的时候会使用 read、readline 或者 readlines,简述它们各自的作用
# read() 每次读取整个文件,它通常用于将文件内容放到一个字符串变量中。
# 如果希望一行一行的输出那么就可以使用 readline(),该方法会把文件的内容加载到内存,所以对于对于大文件的读取操作来说非常的消耗内存资源,
# 此时就可以通过 readlines 方法,将文件的句柄生成一个生产器,然后去读就可以了。
34,json 序列化时,可以处理的数据类型有哪些?如何定制支持 datetime 类型?
可以处理的数据类型是 str、int、list、tuple、dict、bool、None, 因为 datetime 类不支持 json 序列化,所以我们对它进行拓展。
# 自定义时间序列化
import json
from datetime import datetime, date # JSONEncoder 不知道怎么去把这个数据转换成 json 字符串的时候
# ,它就会去调 default()函数,所以都是重写这个函数来处理它本身不支持的数据类型,
# default()函数默#认是直接抛异常的。
class DateToJson(json.JSONEncoder):
def default(self, obj):
if isinstance(obj, datetime):
return obj.strftime('%Y-%m-%d %H:%M:%S')
elif isinstance(obj, date):
return obj.strftime('%Y-%m-%d')
else:
return json.JSONEncoder.default(self, obj) d = {'name': 'cxa', 'data': datetime.now()}
print(json.dumps(d, cls=DateToJson))
值得注意的是,在django中对于queryset而言,可以用这种方法解决
from django.core import serializers
import json
from django.core import serializers
json_data = serializers.serialize('json', goods) # 这个直接传入questset
json_data = json.loads(json_data)
from django.http import HttpResponse, JsonResponse
return JsonResponse(json_data, safe=False)
其实通过serializers的源码我们可以发现,就是采用我们上面写的那种方法
35, json 序列化时,默认遇到中文会转换成 unicode,如果想要保留中文怎么办?
import json
a=json.dumps({"name":"张三"},ensure_ascii=False)
print(a)
# 通过 json.dumps 的 ensure_ascii 参数解决
36, 一行代码输出 1-100 之间的所有偶数
# 方法1
print([i for i in range(1, 101) if i & 0x1 == 0])
# 方法2:测试发现方法二效率更高
print(list(range(2, 101, 2)))
37, with 语句的作用,写一段代码?
with 语句适用于对资源进行访问的场合,确保不管使用过程中是否发生异常都会执行必要的“清理”操作,释放资源,比如文件使用后自动关闭、线程中锁的自动获取和释放等。
#一般访问文件资源时我们会这样处理: f = open(
'c:\test.txt', 'r')
data = f.read()
f.close()
# 这样写没有错,但是容易犯两个毛病:
# 1. 如果在读写时出现异常而忘了异常处理。
# 2. 忘了关闭文件句柄 #以下的加强版本的写法: f = open('c:\test.txt', 'r')
try:
data = f.read()
finally:
f.close() #以上的写法就可以避免因读取文件时异常的发生而没有关闭问题的处理了。代码长了一些。
#但使用 with 有更优雅的写法: with open(r'c:\test.txt', 'r') as f:
data = f.read()
#with 的实现 class Test:
def __enter__(self):
print('__enter__() is call!')
return self def dosomething(self):
print('dosomethong!') def __exit__(self, exc_type, exc_value, traceback):
print('__exit__() is call!')
print(f'type:{exc_type}')
print(f'value:{exc_value}')
print(f'trace:{traceback}')
print('__exit()__ is call!') with Test() as sample:
pass #当对象被实例化时,就会主动调用__enter__()方法,任务执行完成后就会调用__exit__()方法,
#另外,注意到,__exit__()方法是带有三个参数的(exc_type, exc_value, traceback),
#依据上面的官方说明:如果上下文运行时没有异常发生,那么三个参数都将置为 None,
#这里三个参数由于没有发生异常,的确是置为了 None, 与预期一致. # 修改后不出异常了
class Test:
def __enter__(self):
print('__enter__() is call!')
return self def dosomething(self):
x = 1/0
print('dosomethong!') def __exit__(self, exc_type, exc_value, traceback):
print('__exit__() is call!')
print(f'type:{exc_type}')
print(f'value:{exc_value}')
print(f'trace:{traceback}')
print('__exit()__ is call!')
return True with Test() as sample:
38, Python 垃圾回收机制?
主要体现在下面三个方法:
1.引用计数机制 2.标记-清除 3.分代回收
39, 魔法函数 _call_怎么使用?
_call_ 可以把类实例当做函数调用。 使用示例如下
class Bar:
def __call__(self, *args, **kwargs):
print('in call') if __name__ == '__main__':
b = Bar()
b()
40, 如何判断一个对象是函数还是方法?
from types import MethodType, FunctionType class Bar:
def foo(self):
pass def foo2():
pass def run():
print("foo 是函数", isinstance(Bar().foo, FunctionType))
print("foo 是方法", isinstance(Bar().foo, MethodType))
print("foo2 是函数", isinstance(foo2, FunctionType))
print("foo2 是方法", isinstance(foo2, MethodType)) if __name__ == '__main__':
run()
>>>
foo 是函数 False
foo 是方法 True
foo2 是函数 True
foo2 是方法 False
41,python如何做高并发:
现象:由于用户量的增长,服务器请求太多,来不及处理,甚至是请求被丢弃
用户所面临的就是等待时间过长或者出现错误。
原因: 服务器压力大:
1、---》资源不足--》提升硬件配置(性价比不高)
2、资源充足,考虑分配的问题
-- cpu
-- 内存
-- 磁盘I/O
-- 网络I/O
解决的思路和方案:
① CPU的问题,我们使用top命令看一下


那就升级CPU
②那如果是这样呢?
按1之后可以看到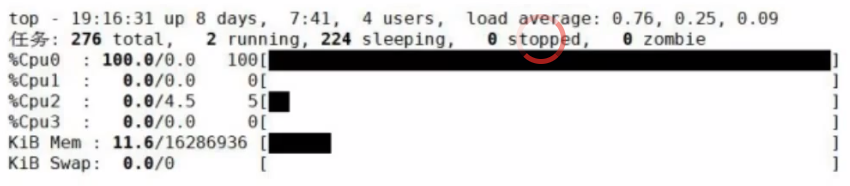
四核的cpu除了第一个占满了,但是其他的还很空闲,那如何解决呢?
利用多进程来增加cpu的任务处理能力
import multiprocessing
number = multiprocessing.cpu_count() - 1 # python中完成多进程-1是为了防止所有任务核心数被占满
pool = multiprocessing.Pool(number)
for i in range(number):
pool.apply_async(task)
pool.close()
pool.join()
使用进程池的好处就是减少开进程时候的开销
③使用缓存(我一般采用的是redis)
1, 适用于经常访问相同的数据(外卖、电商)
2, 查找缓存,有则返回,无则查找数据库并更新缓存
3, 写入数据库,更新缓存
问题:
① 当缓存崩溃了,压力全部到数据库
解决方案:设置随机失效时间;控制读DB线程
② 缓存和数据库中都没有,相当于缓存没起作用(缓存穿透)
解决方案: DB查询为空也写缓存;提前过滤
④查看网络状况
1,查看网卡带宽 ethtool软件
2,查看网卡流量
解决方案:
1, 升级网卡
2, DNS域名解析(更换域名服务器)
3, 内核参数的优化

⑥HTML页面静态化
⑦使用几圈
⑧使用负载均衡
upstream djangoserver {
server 192.168.72.49:8080;
server 192.168.72.49:8081;
}
⑨压缩js,css等或者直接托管到公共的js/css库
----一、django+uwsgi+nginx
----二、django+celery实现异步加载
写一写关于python开发面试的常遇到的问题以及解答吧,持续更新——看心情的更多相关文章
- python开发面试问题
python语法以及其他基础部分 可变与不可变类型: 浅拷贝与深拷贝的实现方式.区别:deepcopy如果你来设计,如何实现: __new__() 与 __init__()的区别: 你知道几种设计模式 ...
- 移动端WEBAPP开发遇到的坑,以及填坑方案!持续更新~~~~
前言:在移动端WEBAPP开发中会遇到各种各样的问题,通过此文对遇到的问题做一个归纳总结,方便自己日后查询,也给各位前端开发友人做一个参考. 此文中涉及的问题是本人开发中遇到的,解决方案是本人思考 ...
- 关于ASP.NET MVC开发设计中出现的问题与解决方案汇总 【持续更新】
最近一直用ASP.NET MVC 4.0 +LINQ TO SQL来开发设计公司内部多个业务系统网站,在这其中发现了一些问题,也花了不少时间来查找相关资料或请教高人,最终都还算解决了,现在我将这些问题 ...
- (转)iOS开发——来改掉那些被禁用的方法吧(持续更新中)
iOS平台在快速的发展,各种接口正在不断的更新.随着iOS9的发布,又有一批老方法不推荐使用了,你若调用这些方法,运行的结果是没有问题的,但是会出现警告“***is deprecated :first ...
- Python开发面试集锦
我正在编写一套python面试开发集锦,可以帮忙star一下,谢谢! 地址:GitHub专栏
- Python 开发面试总结
网络基础 如何确定发送过来的数据的完整性(有无中间人攻击)? 散列值校验(MD5.SHA-1).数字签名(PGP),需要用户亲自校验,若是散列值或数字签名本身被篡改,用户是无法判断出来的. HTTPS ...
- 关于Vue在面试中常常被提到的几点(持续更新……)
1.Vue项目中为什么要在列表组件中写key,作用是什么? 我们在业务组件中,会经常使用循环列表,当时用v-for命令时,会在后面写上:key,那么为什么建议写呢? key的作用是更新组件时判断两个节 ...
- IOS开发--常用工具类收集整理(Objective-C)(持续更新)
前言:整理和收集了IOS项目开发常用的工具类,最后也给出了源码下载链接. 这些可复用的工具,一定会给你实际项目开发工作锦上添花,会给你带来大大的工作效率. 重复造轮子的事情,除却自我多练习编码之外,就 ...
- Python 爬取的类封装【将来可能会改造,持续更新...】(2020年寒假小目标09)
日期:2020.02.09 博客期:148 星期日 按照要求,我来制作 Python 对外爬取类的固定部分的封装,以后在用 Python 做爬取的时候,可以直接使用此类并定义一个新函数来处理CSS选择 ...
随机推荐
- mybatis 异常和注意
1. Could not set parameters for mapping like语句出错,因将%%写入到mapper.xml中导致,将%%随同参数一并传入. 例:String userNam ...
- MySQL 创建自定义函数
语法:Create function function_name(参数列表)returns返回值类型 函数体 函数名,应合法的标识符,不应与系统关键字冲突. 一个函数应该属于某个数据库,可以使用db_ ...
- iOS 证书, provision profile作用
证书(certificate): 给app签名用的,针对开发者,app可以装在真机上的前提条件之一是被签名 Provision profile: 在app包中,用来校验app是否可以被装在真机上,一个 ...
- docker之手动构建新的镜像
转自:https://www.cnblogs.com/jsonhc/p/7766561.html 查看本地现有镜像: [root@docker ~]# docker images REPOSITORY ...
- wx小程序获取组件属性数据data-prop
在微信小程序中有时会在组件上定义一些属性,使用data-来定义 <view data-idvalue="id" data-Index-Name="IndexName ...
- 为了显示此页面,Firefox 必须发送将重复此前动作的数据(例如搜索或者下订单)
火狐浏览器重新加载页面出现下面提示,必须要点击“重新发送”才能完成刚才的请求: 这个是火狐的一个提示功能主要是防止同一页面的数据反复提交: 解决方法: 不要用location.reload();来刷新 ...
- JAVA程序员常用英语
JAVA程序员常用英语 干程序员这行实在是离不开英语,干程序员是一项很辛苦的工作,要成为一个高水平的程序员尤为艰难.这是因为计算机软件技术更新的速度越来越快,而这些技术大多来源于英语国家,我们在引进这 ...
- BindingFlags 枚举
https://msdn.microsoft.com/zh-cn/library/cexkb29a 官方解释: 指定控制绑定和由反射执行的成员和类型搜索方法的标志. 此枚举有一个 FlagsAttri ...
- Android辅助开发工具说明
1.aapt(Android Asset Packaging Tool):用于建立zip包(zip.jar.apk),也可用于将资源编译到二进制的assets:2.adb(Android Debug ...
- Spark MLlib特征处理:OneHotEncoder OneHot编码 ---原理及实战
http://m.blog.csdn.net/wangpei1949/article/details/53140372 Spark MLlib特征处理:OneHotEncoder OneHot编码 - ...