利用xlrd模块读取excel利用json模块生成相应的json文件的脚本
excel的格式如下
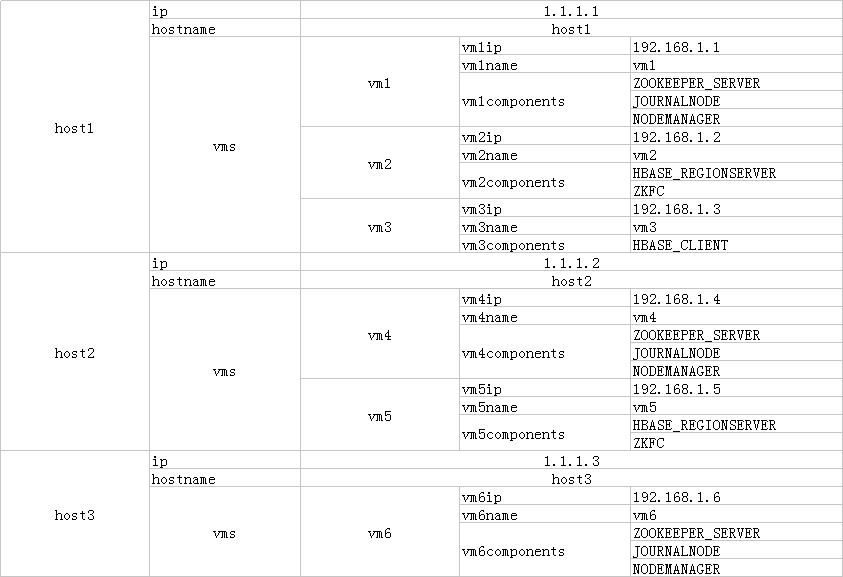
python代码如下,这里最难的就是合并单元格的处理
import xlrd
import json excel_obj = xlrd.open_workbook("test.xlsx") sheet_name = excel_obj.sheet_names()[0] sheet_obj = excel_obj.sheet_by_index(0) hadoop_dict = {
"services": [
"AMBARI_METRICS",
"HBASE",
"HDFS",
"HIVE",
"KAFKA",
"MAPREDUCE2",
"PIG",
"SLIDER",
"SMARTSENSE",
"SPARK2",
"STORM",
"TEZ",
"YARN",
"ZOOKEEPER"
],
"pm_group" :[],
"host_groups":[]
} host = {}
vm = {}
# components_list = [] r_num = sheet_obj.nrows
c_num = sheet_obj.ncols merge_cell_list = sheet_obj.merged_cells # for i in range(r_num):
# if sheet_obj.cell_value(i,c_num-1):
# components_list.append(sheet_obj.cell_value(i,c_num-1)) # 获取最后一列的所有数据 for i in merge_cell_list:
if i[2] == 0:
host[sheet_obj.cell_value(i[0],i[2])] = [i[0],i[1],i[2],i[3]] # 存放所有合并的单元格 for k,v in host.items():
host_dict = {}
print(sheet_obj.cell_value(v[0],1),sheet_obj.cell_value(v[0],2),sep="---->")
# 获取主机的ip地址
pm_ip = sheet_obj.cell_value(v[0],2)
print(pm_ip,"物理机地址") print(sheet_obj.cell_value(v[0] + 1,1),sheet_obj.cell_value(v[0] + 1,2),sep="---->")
# 获取主机的主机名
pm_name = sheet_obj.cell_value(v[0] + 1,2) host_dict["ip"] = pm_ip
host_dict["hostname"] = pm_name
host_dict["vms"] = [] for vms_cell in merge_cell_list:
vm_dict = {}
vm_components_dict = {}
if vms_cell[1] <= host[k][1] and vms_cell[2] == 2 and vms_cell[0] > host[k][0] + 1:
print(sheet_obj.cell_value(vms_cell[0],2))
# 获取虚拟机的名称
print(sheet_obj.cell_value(vms_cell[0],vms_cell[2] + 1))
# 获取虚拟机的ip的k print(sheet_obj.cell_value(vms_cell[0],vms_cell[2] + 2))
# 获取虚拟机的ip地址
vm_ip = sheet_obj.cell_value(vms_cell[0], vms_cell[2] + 2) print(sheet_obj.cell_value(vms_cell[0] + 1, vms_cell[2] + 1))
# 获取虚拟机的虚拟机名称的k print(sheet_obj.cell_value(vms_cell[0] + 1, vms_cell[2] + 2))
# 获取虚拟机的名字的值 vm_name = sheet_obj.cell_value(vms_cell[0] + 1, vms_cell[2] + 2) vm_name = sheet_obj.cell_value(vms_cell[0] + 1, vms_cell[2] + 2)
vm_dict = {
"hostname":vm_name,
} vm_components_dict["ip"] = vm_ip
vm_components_dict["hostname"] = vm_name
vm_components_dict["components"] = [] host_dict["vms"].append(vm_dict) vmcomponents_location_start = vms_cell[0] + 2
vmcomponents_location_end = vms_cell[1]
# print(vmcomponents_location_start,vmcomponents_location_end,"我是大傻逼")
vm_components_info_list = []
for i in range(vmcomponents_location_start,vmcomponents_location_end):
temp_components = sheet_obj.cell_value(i,c_num-1)
vm_components_info_list.append(temp_components) for component in vm_components_info_list:
temp_dict = {}
temp_dict["name"] = component
vm_components_dict["components"].append(temp_dict) hadoop_dict["host_groups"].append(vm_components_dict) # 获取每个虚拟机的components信息
hadoop_dict["pm_group"].append(host_dict) import json
file_name = "journalnode_".upper() + "test_journalnode_case_1" + "." + "json"
my_file_obj = open(file_name,"w") json.dump(hadoop_dict,my_file_obj,indent=4)
my_file_obj.close()
最后按照要求生成制定格式的json文件
{
"services": [
"AMBARI_METRICS",
"HBASE",
"HDFS",
"HIVE",
"KAFKA",
"MAPREDUCE2",
"PIG",
"SLIDER",
"SMARTSENSE",
"SPARK2",
"STORM",
"TEZ",
"YARN",
"ZOOKEEPER"
],
"pm_group": [
{
"ip": "1.1.1.1",
"hostname": "host1",
"vms": [
{
"hostname": "vm1"
},
{
"hostname": "vm2"
},
{
"hostname": "vm3"
}
]
},
{
"ip": "1.1.1.2",
"hostname": "host2",
"vms": [
{
"hostname": "vm4"
},
{
"hostname": "vm5"
}
]
},
{
"ip": "1.1.1.3",
"hostname": "host3",
"vms": [
{
"hostname": "vm6"
}
]
}
],
"host_groups": [
{
"ip": "192.168.1.1",
"hostname": "vm1",
"components": [
{
"name": "ZOOKEEPER_SERVER"
},
{
"name": "JOURNALNODE"
},
{
"name": "NODEMANAGER"
}
]
},
{
"ip": "192.168.1.2",
"hostname": "vm2",
"components": [
{
"name": "HBASE_REGIONSERVER"
},
{
"name": "ZKFC"
}
]
},
{
"ip": "192.168.1.3",
"hostname": "vm3",
"components": [
{
"name": "HBASE_CLIENT"
}
]
},
{
"ip": "192.168.1.4",
"hostname": "vm4",
"components": [
{
"name": "ZOOKEEPER_SERVER"
},
{
"name": "JOURNALNODE"
},
{
"name": "NODEMANAGER"
}
]
},
{
"ip": "192.168.1.5",
"hostname": "vm5",
"components": [
{
"name": "HBASE_REGIONSERVER"
},
{
"name": "ZKFC"
}
]
},
{
"ip": "192.168.1.6",
"hostname": "vm6",
"components": [
{
"name": "ZOOKEEPER_SERVER"
},
{
"name": "JOURNALNODE"
},
{
"name": "NODEMANAGER"
}
]
}
]
}
利用xlrd模块读取excel利用json模块生成相应的json文件的脚本的更多相关文章
- 利用 pandas库读取excel表格数据
利用 pandas库读取excel表格数据 初入IT行业,愿与大家一起学习,共同进步,有问题请指出!! 还在为数据读取而头疼呢,请看下方简洁介绍: 数据来源为国家统计局网站下载: 具体方法 代码: i ...
- Python xlrd模块读取Excel表中的数据
1.xlrd库的安装 直接使用pip工具进行安装(当然也可以使用pycharmIDE进行安装,这里就不详述了) pip install xlrd 2.xlrd模块的一些常用命令 ①打开excel文件并 ...
- Xlrd模块读取Excel文件数据
Xlrd模块使用 excel文件样例:
- Python-用xlrd模块读取excel,数字都是浮点型,日期格式是数字的解决办法
excel文件内容: 读取excel: # coding=utf-8 import xlrd import sys reload(sys) sys.setdefaultencoding('utf-8' ...
- 猜想-未做 利用office组件读取excel数据
---未实际使用过 用SQL-Server访问Office的Access和Excel http://blog.sina.com.cn/s/blog_964237ea0101532x.html 2007 ...
- python 利用三方的xlrd模块读取excel文件,处理合并单元格
目的: python能使用xlrd模块实现对Excel数据的读取,且按照想要的输出形式. 总体思路: (1)要想实现对Excel数据的读取,需要用到第三方应用,直接应用. (2)实际操作时候和我 ...
- 后端Nodejs利用node-xlsx模块读取excel
后端Nodejs(利用node-xlsx模块) /** * Created by zh on 16-9-14. */ var xlsx = require("node-xlsx") ...
- 基础补充:使用xlrd模块读取excel文件
因为接口测试用例使用excel文件来维护的,所以有必要学习下操作excel的基本方法 参考博客:python 3 操作 excel 把自己练习的代码贴出来,是一些基本的操作,每行代码后面都加了注释. ...
- python-利用xlrd模块读取excel数据,将excel数据转换成字典格式
前言 excel测试案例数据 转换成这种格式 实现代码 import os import xlrd excel_path = '..\data\\test_case.xlsx' data_path = ...
随机推荐
- PLSQLDeveloper_免安装自带client
PLSQLDeveloper_解压版 免安装并且自带有client客户端. 要安装解压附带的readme.txt进行配置. 一. 目录结构 D:\install\PLSQL |-- instantcl ...
- 爬虫--requests模块高级(代理和cookie操作)
代理和cookie操作 一.基于requests模块的cookie操作 引言:有些时候,我们在使用爬虫程序去爬取一些用户相关信息的数据(爬取张三“人人网”个人主页数据)时,如果使用之前requests ...
- block原理
block原理 block的本质是一个结构体,包含引用的外部变量及一个需要执行的函数的函数指针,在内存中可以有三个位置,即堆上.栈上和全局区(静态区).当block中没有引用外部变量时,block的位 ...
- list<T>中的按特定顺序排序
前段时间有个任务,就是把参数要按特定顺序排序,就是要是在一张大的参数表中,只选取,2,5,12,9,13,10 这几个参数,并按上述顺序进行排序. 假设这个参数在一个类中.例如: 上述参数序列就存在P ...
- zabbix监控haproxy
首先修改haproxy.cfg listen monitor_stat : stats uri /ihaproxy-stats stats realm Haproxy\ Statistics stat ...
- 剑指offer例题——裴波那契数列
编程题:大家都知道裴波那契数列,现在要求输入一个整数n,请你输出裴波那契数列的第n项(从0开始,第0项为0).n<=39 public class Solution { public int F ...
- C++17尝鲜:string_view
string_view string_view 是C++17所提供的用于处理只读字符串的轻量对象.这里后缀 view 的意思是只读的视图. 通过调用 string_view 构造器可将字符串转换为 s ...
- SQL Server 生成 数据字典 / 数据库文档
1. 工具生成 2.SQL语句生成 参考地址:http://blog.csdn.net/qq289523052/article/details/22174721 1.在 表 上右键 - 扩展属性 - ...
- Jupter 7个进阶功能
1. 执行shell命令 Shell是一种与计算机进行文本交互的方式. 一般来讲,当你正在使用Python编译器,需要用到命令行工具的时候,要在shell和IDLE之间进行切换. 但是,如果你用的是 ...
- 配置linux的ip、网络等
之前配过ubuntu的..以为centos的也是这么配置,结果照抄下来,启动报错哈哈...网上搜下资料发现centos配置需要不少文件.忘了以后再参考下- ubuntu的,这样配置 vim /et ...