MapReduce编程解析
MapReduce编程模型之案例
wordcount

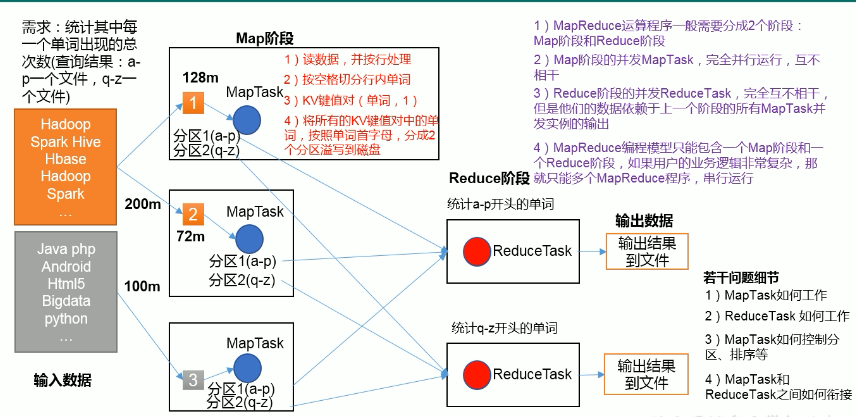
输入数据
atguigu atguigu
ss ss
cls cls
jiao
banzhang
xue
hadoop输出数据
atguigu 2
banzhang 1
cls 2
hadoop 1
jiao 1
ss 2
xue 1Mapper
将MapTask传给我们的文本内容先转换成String
atguigu atguigu
根据空格将这一行切分成单词
atguigu
atguigu
将单词输出为<单词,1>
atguigu,1
atguigu,1
Reduce
汇总各个key的个数
atguigu,1
atguigu,1
输出该key的总次数
atguigu,2
Driver
获取配置信息,获取job对象实例
指定本程序的jar包所在的本地路径
关联Mapper/Reduce业务类
指定Mapper输出数据的kv类型
指定最终输出的数据的kv类型
指定job的输入原始文件所在目录
指定job的输出结果所在目录
提交作业

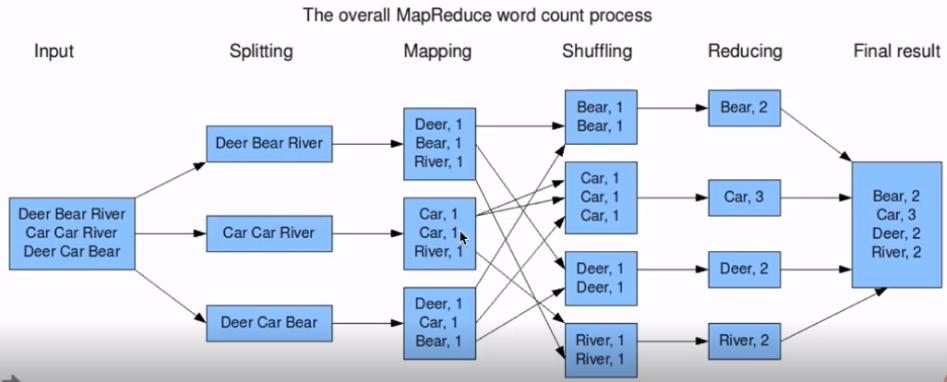
MapReduce编程模型之Map和Reduce
将作业拆分成Map阶段和Reduce
Map阶段:Map Tasks
Reduce阶段:Reduce Tasks
MapReduce编程模型之Map和Reduce
准备map处理的输入数据
Mapper处理
Shuffle
Reduce处理
结果输出

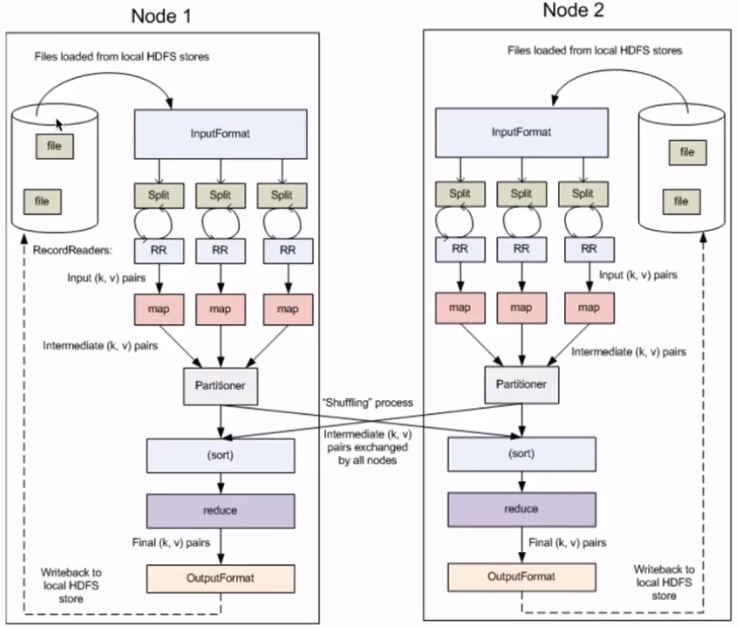
核心概念
Split:交由MapReduce作业来处理的数据块,是MapReduce中最小的计算单元
HDFS:blocksize是HDFS中最小的存储单元 128M
默认情况下:他们两是一一对应的,当然我们也可以手工设置他们之间的关系
InputFormat
OutputFormat
Combiner
Partitioner

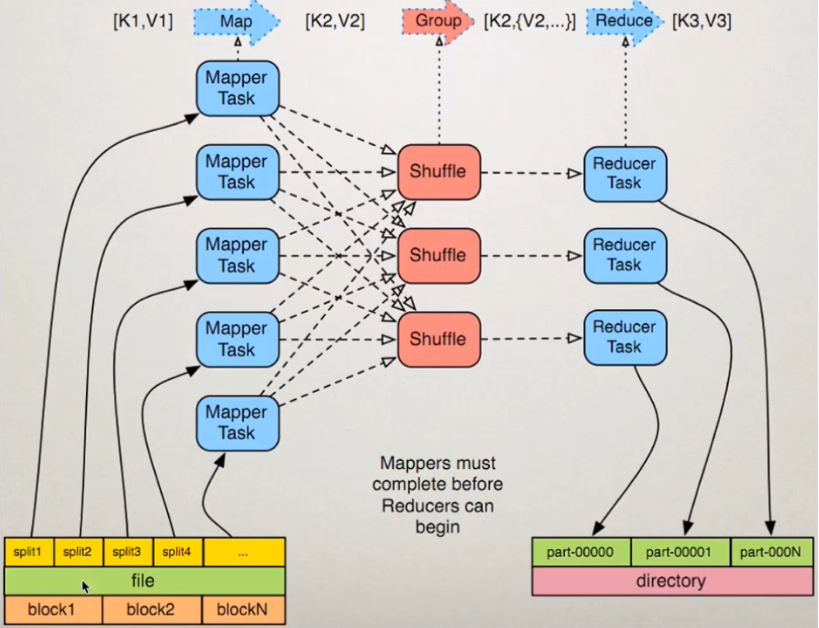
MapReduce框架原理
InputFormat数据输入
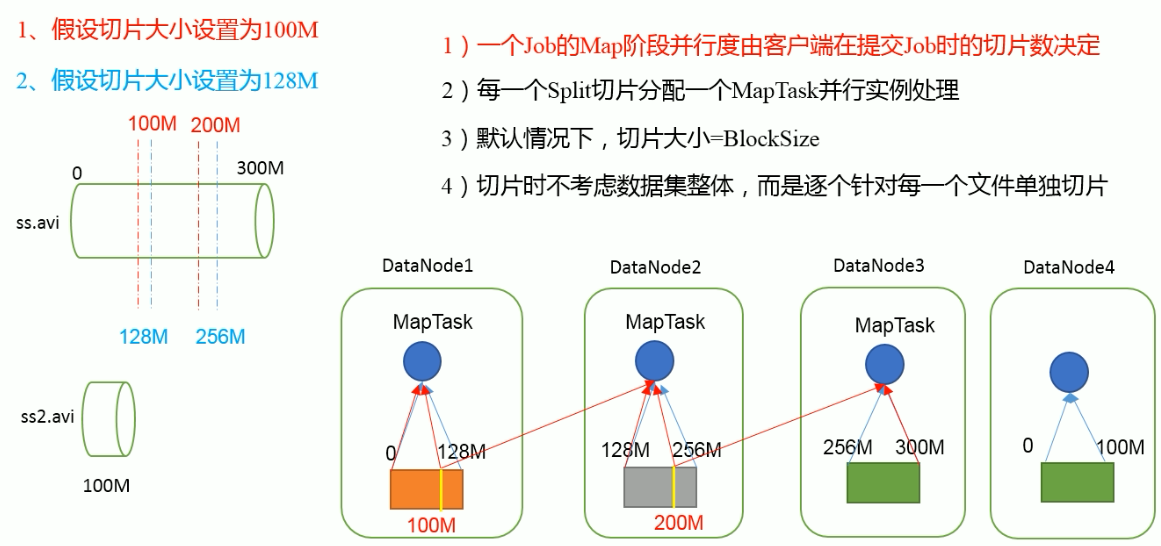
切片与MapTask并行度决定机制
MapTask的并行度决定Map阶段的任务处理并发度,进而影响到整个job的处理速度。
MapTask并行度决定机制
数据块:Block是HDFS物理上把数据分成一块一块
数据切片:数据切片只是在逻辑上对输入进行切片,并不会在磁盘上将其切分成片进行存储

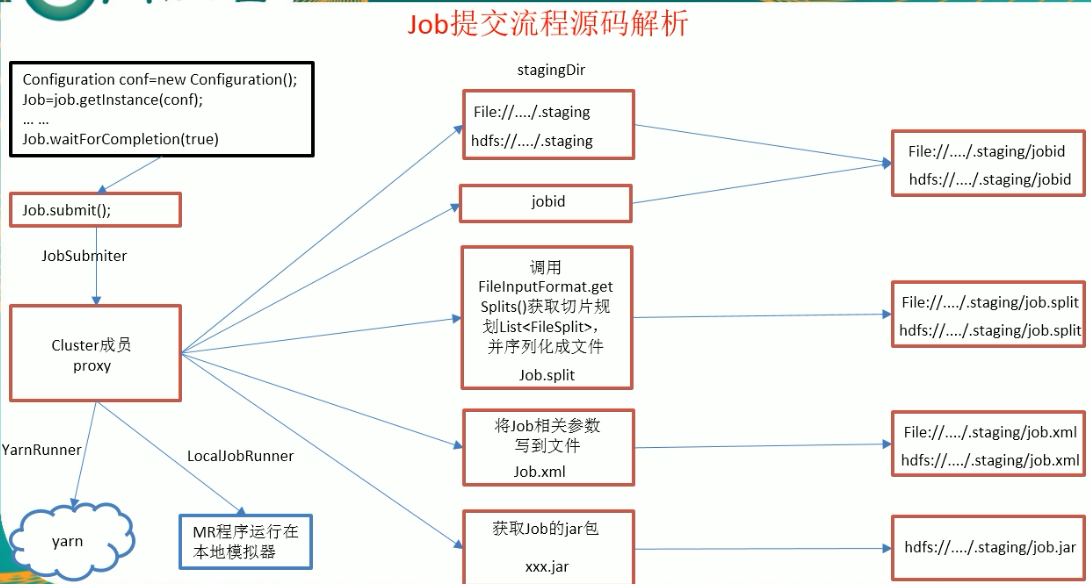
job提交流程源码解析

FileInputFormat切片源码解析(input.getSplits(job))
程序先找到你的数据存储的目录
开始遍历处理(规划切片)目录下的每一个文件
遍历第一个文件ss.txt(300M)
获取文件大小fs.sizeOf(ss.txt)
计算切片大小
computeSliteSize(Math.max(minSize,Math.min(maxSize,blocksize)))=blocksize=128M
默认情况下,切片大小=blocksize
开始切,形成第一个切片:ss.txt---0:128M 第二个切片ss.txt---128:256M 第三切片ss.txt---256M:300M(每次切片时,都要判断切完剩下的部分是否大于块的1.1倍,不大于1.1倍就切分一块切片)
将切片信息写到一个切片规划文件中,
整个切片的核心过程在getSplit()方法中完成
InputSplit只记录了切片的元数据信息,比如起始位置、长度以及所在的节点列表等。
提交切片规划文件到YARN上,YARN上的MrAppMaster就可以根据切片规划文件计算开启MapTask个数
FileInputFormat切片机制
切片机制
简单地按照文件的内容长度进行切片
切片大小,默认等于Block大小
切片时不考虑数据集整体,而是逐个针对每个文件单独切片
案例分析
输入两个文件:file1.text 320M ,file2.txt 10M
经过FileInputFormat的切片机制运算后,形成的切片信息如下:
file1.text.split1-- 0~128
file1.text.split2-- 128~256
file1.text.split3-- 256~320
file2.text.split1-- 0~10
源码中计算切片大小的公式
Math.max(minSize,Math.min(maxSize,blocksize));
mapreduce.input.fileinputformat.split.minsize=1 默认值为1
mapreduce.input.fileinputformat.split.maxsize=Long.MAXValue 默认值Long.MAXValue
因此,默认情况下,切片大小=blocksize。
切片大小设置
maxsize(切片最大值):参数如果调得比blockSize小,则会让切片变小,而且就等于配置的这个参数
minsize(切片最小值):参数调的比blockSize大,则可以让切片变得比blockSize还大
获取切片信息API
//获取切片的文件名称
String name = inputSplit.getPath().getName();
//根据文件类型获取切片信息
FileSplit inputSplit = (FileSplit)context.getInputSplit();
CombineTextInputFormat切片机制
框架默认的TextInputFormat切片机制时对任务按文件规划切片,不管文件多小,都会是一个单独的切片,都会交给一个MapTask,这样如果有大量小文件,就会产生大量的MapTask,处理效率极其低下。
应用场景:
CombineTextInputFormat用于小分件过多的场景,它可以将多个小文件从逻辑上规划到一个切片中,这样,多个小文件就可以交给一个MapTask处理。
MapReduce编程解析的更多相关文章
- Hadoop MapReduce编程 API入门系列之压缩和计数器(三十)
不多说,直接上代码. Hadoop MapReduce编程 API入门系列之小文件合并(二十九) 生成的结果,作为输入源. 代码 package zhouls.bigdata.myMapReduce. ...
- hadoop2.2编程:使用MapReduce编程实例(转)
原文链接:http://www.cnblogs.com/xia520pi/archive/2012/06/04/2534533.html 从网上搜到的一篇hadoop的编程实例,对于初学者真是帮助太大 ...
- MapReduce 编程模型
一.简单介绍 1.MapReduce 应用广泛的原因之中的一个在于它的易用性.它提供了一个因高度抽象化而变得异常简单的编程模型. 2.从MapReduce 自身的命名特点能够看出,MapReduce ...
- 暴力破解MD5的实现(MapReduce编程)
本文主要介绍MapReduce编程模型的原理和基于Hadoop的MD5暴力破解思路. 一.MapReduce的基本原理 Hadoop作为一个分布式架构的实现方案,它的核心思想包括以下几个方面:HDFS ...
- MapReduce编程模型简介和总结
MapReduce应用广泛的原因之一就是其易用性,提供了一个高度抽象化而变得非常简单的编程模型,它是在总结大量应用的共同特点的基础上抽象出来的分布式计算框架,在其编程模型中,任务可以被分解成相互独立的 ...
- 指导手册05:MapReduce编程入门
指导手册05:MapReduce编程入门 Part 1:使用Eclipse创建MapReduce工程 操作系统: Centos 6.8, hadoop 2.6.4 情景描述: 因为Hadoop本身 ...
- MapReduce 编程模型概述
MapReduce 编程模型给出了其分布式编程方法,共分 5 个步骤:1) 迭代(iteration).遍历输入数据, 并将之解析成 key/value 对.2) 将输入 key/value 对映射( ...
- MapReduce编程实例5
前提准备: 1.hadoop安装运行正常.Hadoop安装配置请参考:Ubuntu下 Hadoop 1.2.1 配置安装 2.集成开发环境正常.集成开发环境配置请参考 :Ubuntu 搭建Hadoop ...
- mapreduce编程--(准备篇)
mapreduce编程准备 学习mapreduce编程之前需要做一些概念性的了解,这是做的一些课程学习笔记,以便以后时不时的翻出来学习下,之前看过一篇文章大神们都是时不时的翻出基础知识复习下,我也做点 ...
随机推荐
- 解决sublime3不能编辑插件default settings的问题
一.遇见问题 今天给sublime安装了View In Browser,想更改一下默认启动的浏览器 preferences-Package settings-View In Browser-setti ...
- [中英对照]Introduction to DPDK: Architecture and Principles | DPDK概论: 体系结构与实现原理
[中英对照]Introduction to DPDK: Architecture and Principles | DPDK概论: 体系结构与实现原理 Introduction to DPDK: ...
- 可迭代对象(Iterable)和迭代器(Iterator)
迭代是访问集合元素的一种方式. 迭代器是一个可以记住遍历的位置的对象. 迭代器对象从集合的第一 个元素开始访问,直到所有的元素被访问完结束.迭代器只能往前不会后退. 1. 可迭代对象 以直接作用于 ...
- CButtonST|CUniButton等按钮类的使用
CButtonST CButtonST类的使用参考链接:http://www.cnblogs.com/lidabo/archive/2012/12/17/2821122.html CCeButtonS ...
- JSP脚本元素(声明 %! 表达式 %= 脚本 %)
JSP脚本元素包括声明.表达式.脚本 声明(declaration):用于在JSP页面中声明合法的变量和方法.以“<%!”开始,以“%>”结束. 在JSP页面中,一个声明可以出现在任何地方 ...
- 使用iTEXT库生成pdf
iTEXT下载地址 https://sourceforge.net/projects/itext/files/ 选择绿色的按钮,下载最新版本,解压后是一些jar包 为了使用方便,将文件夹放到JAVA_ ...
- [FreeMind] 绘制思维时遇到的常见问题解决办法
如何改变节点的摆放方向? 如果是新建节点,选择要放置节点的那一侧,按enter键,或者鼠标右键,插入平行节点即可. 如果是已经建好的节点,可以用ctrl+x, ctrl+v粘贴到另一边,或者选中子节点 ...
- office 2007,SQL Server 2008,VS2010安装步骤
office 2007,SQL Server 2008,VS2010的安装顺序是不是office 2007,SQL Server 2008,VS2010呢? 前几天先安装了SQL Server 200 ...
- linux 和 主机通信的另类方法
偶然发现,linux可以从github上直接下载代码.这样就能用windows写好代码,直接给linux来跑了.很方便. 当然是因为我还不会配置网络来让linux和windows通信.弄了一个下午也没 ...
- 安装ADT和ADK到eclipse
1.安装好JDK后,配置一下环境变量: 为了配置JDK的系统变量环境,我们需要设置三个系统变量,分别是JAVA_HOME,Path和CLASSPATH.下面是这三个变量的设置防范. JAVA_HOME ...