一个可以代替冗长switch-case的消息分发小框架
在项目中,我需要维护一个应用层的字节流协议。这个协议的每条报文都是一个字节数组,数组的头两个字节表示消息的传送方向,第三、四个字节表示消息ID,也就是消息种类,再往后是消息内容、时间戳、校验码等……整个消息看起来差不多长这样:
| Message Head | Message ID | Content | Timestamp | Checksum |
| 2 bytes | 2 bytes | n bytes | 8 bytes | 1 byte |
Message ID指定了消息类型,根据不同的消息类型,对Content有不同的解析方法。在处理报文的类中,我们不得不用一个switch-case结构去处理不同类型的报文:
switch(messageID){
case 0x01: doSomething(); break;
case 0x02: doAnotherThing(); break;
case 0x03: doSomeOtherThing(); break;
...
}
在某些报文的消息内容中还存在一个子消息ID,这个子ID会定义具体要实现的操作分类。于是在switch-case中,我们还要再加入嵌套的switch-case去处理对应的子ID:
switch(messageID){
case 0x01: doSomething(); break;
case 0x02: doAnotherThing(); break;
case 0x03:
byte subID = getSubID();
switch(subID)
case 0x01: process1In3(); break;
case 0x02: process2In3(); break;
...
break;
...
}
由于需求一直在变化,我们自身的功能也在演变,协议中经常会增减消息,对同一个消息的处理也常常会变化,渐渐地这个switch-case达到了300多行,而我经常要从这300多行中找到对应的消息去修改它的处理代码,稍不注意就会出错,真是苦不堪言。
一个大神同事提示我,可以用注解解决这个问题。定义一个Handler接口作为消息处理器,再定义一个注解去标示该处理器要处理的消息ID,然后提供一个Util类,利用反射机制读取注解,自动将不同的消息ID和对应的Handler加载到一个Map中,形成一个微型的消息分发处理框架。在这个框架的作用下,上面的switch-case语句变成了这样:
//存放消息ID和对应的MessageHandler
private Map<Byte, MessageHandler> handlersMap = null;
void init() {
//读取注解,将下列定义的HANDLER_1,2,3加载到handlersMap中
handlersMap = MessageHandlerUtil.loadMessageHandlers(this);
} //接收消息的回调函数
public void onDataReceived(CommData command) {
byte commandID = getCommandId(command);
handlersMap.get(commandID).process(command);//调用对应的Handler处理
} //消息ID为01的Handler
@Handle(messageID=0x01)
private final MessageHandler HANDLER_1 = (command) -> { doSomething(); };
//消息ID为02的Handler
@Handle(messageID=0x02)
private final MessageHandler HANDLER_2 = (command) -> { doAnotherThing(); };
//消息ID为03的Handler
@Handle(messageID=0x03)
private final MessageHandler HANDLER_3 = (command) -> { doSomeOtherThing(); };
在这个微型框架之下,要实现报文解析,只需要准备一个HashMap,在初始化时调用MessageHandlerUtil.loadMessageHandlers(this), MessageHandlerUtil这个辅助类会自动将类中所有带@Handle注解的MessageHandler加载到一个Map中并返回,用户在收到消息时,只需要从Map中拿到消息对应的Handler,调用Handler的process方法即可。在增减消息时,只需要增减带@Handle注解的MessageHandler;就算要修改某一个消息的处理,也能比较快速地定位到对应的Handler,在这个独立的Handler里面修改即可,比起之前的switch-case,可以说是更好地遵守了开放-封闭原则(对扩展开放,对更改封闭)。
不得不说,这个框架还是有一点小问题,那就是不能支持子消息的分类。在我负责的业务中,只有一个消息(记为A消息)有子消息,于是我偷懒定义了一个@SubHandle注解,在加载时将@SubHandler注解的MessageHandler加载到另一个Map中,当收到的消息为A消息时,再手动将对应的MessageHandler从第二个Map中取出。这种做法可以说是十分hard code了,还好我负责的业务比较固定,暂时还能用。另外,返回的HashMap是裸露的,用户可以随意修改,看起来似乎也不是很妥当。
周一来上班时,惊喜地发现大神把我的微型框架重构并加入了项目的通用类库中。重构后的框架加强了对数据结构的封装,并且实现了很强的通用性,可以支持三层以上的子消息结构,却只用了两个Map。下面我们就一起来看看他是怎么做的。
首先,还是通过客户代码来看一下这个框架的使用场景。(对于下面的分析,我们都假设消息是一个String类型以使叙述简洁。如果要处理byte数组或其他类型的消息,可以在客户代码中进行转型,或者像大神一样在框架中加入对byte数组的支持,在此就不赘述了)
private HandlerDispatcher<String> handlerDispatcher;//消息分发器
void init(){
handlerDispatcher = new HandlerDispatcherImpl<>();
handlerDispatcher.load(this); //将注解的Handler加载到分发器
}
public void onReceivedMessage(String data) {
//第一个char为消息ID
handlerDispatcher.getHandler(data.charAt(0)+"").process(data);
}
final Supplier<HandlerDispatcher<String>> supplier = () -> handlerDispatcher;
@Mapped("1") //第一层,处理消息ID为1的消息
final CustomizedHandler A = (data) -> { log("A"); };
@Mapped("2") //第一层,处理消息ID为2的消息
final ParentHandler<String> B = ParentHandler.build(supplier, (data) -> (data.charAt(1)+""));
@Parent("B")
@Mapped("1") //第二层,处理消息ID为2,子消息ID为1的消息
final ParentHandler<String> B1 = ParentHandler.build(supplier, (data) -> (data.charAt(2)+""));
@Parent("A")
@Mapped("1") //第二层,处理消息ID为1,子消息ID也为1的消息
final CustomizedHandler A1 = (data) -> { log("A1"); };
@Parent("B1")
@Mapped("1") //第三层,处理消息ID为1,子消息ID为2,子子消息ID为1的消息
final CustomizedHandler B11 = (data) -> { log("B11"); };
示例中定义了三层消息的解析器,用@Mapped(value = messageID)注解定义对应的消息ID,只有该注解的是第一层消息的解析器,同时定义了@Mapped和@Parent注解的是第二层及以下的解析器,其中@Parent(value = parentName)定义了其父消息的解析器名称。
除了能支持多层子消息以外,新的设计将消息分发这个过程封装到了HandlerDispatcher类中,更好地符合了单一指责原则,这样业务模块就能更专心地处理业务逻辑了,而HandlerDispatcher的实现类也可以随时根据业务来调整消息分发的逻辑。
至于上文中的Supplier和ParentHandler.build(),此处可能暂时看不懂,但它们并不是很重要,可以先跳过。
既然说到了HandlerDispatcher,我们就来说一下这个小框架的类结构,其实十分简单:
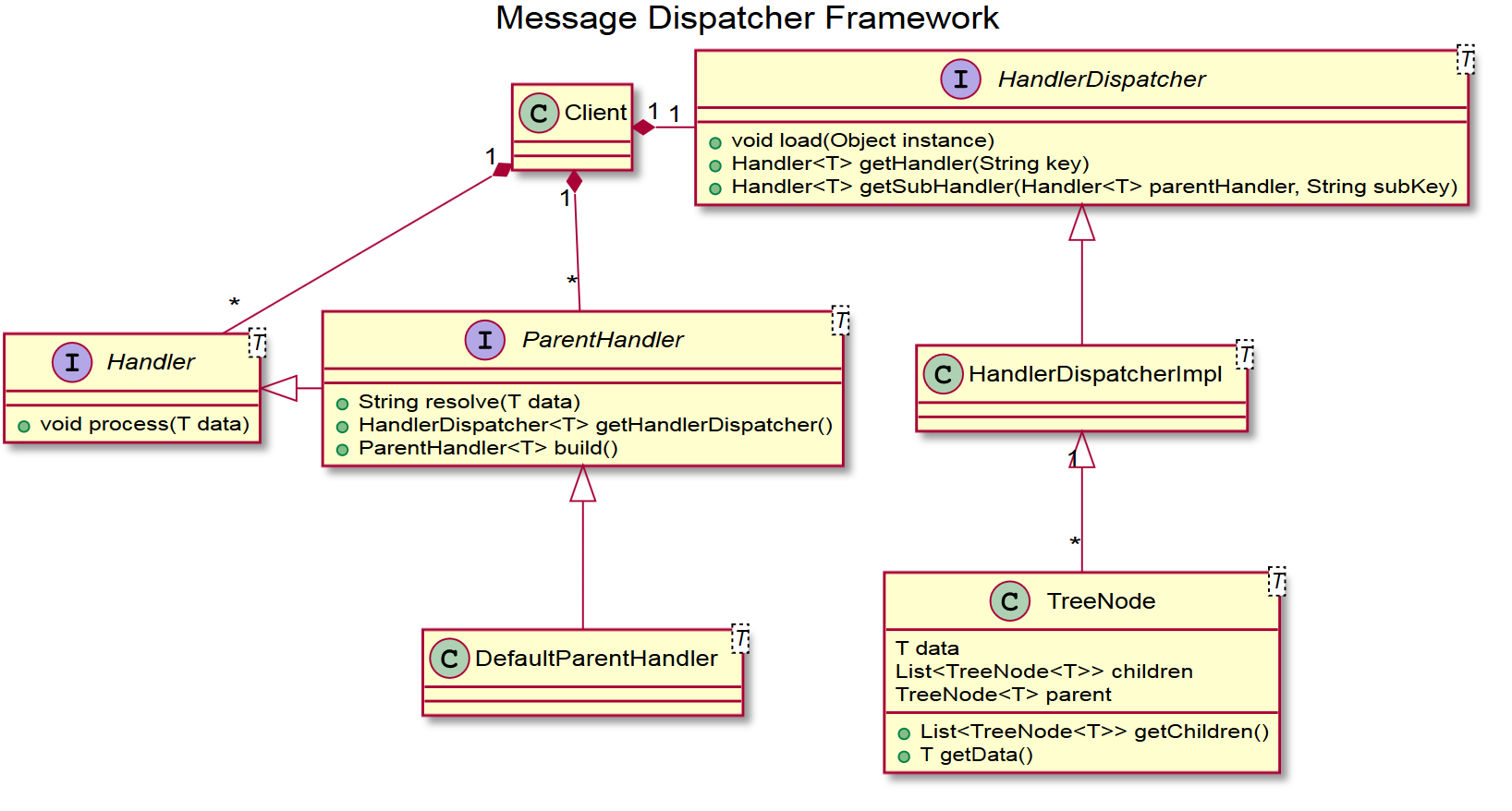
图1:消息分发小框架类图
各个类的关系图中已经比较清楚了,核心类HandlerDispatcher负责加载和分发消息到对应的Handler。框架提供了一个ParentHandler接口供用户在有子消息的场景使用,该接口对上层接口Handler中的process()方法做了默认实现:
@Override
default void process(T data) {
getHandlerDispatcher().getSubHandler(this, resolve(data)).process(data);
}
这是整个框架中我觉得比较聪明的地方之一,也或许是面向对象和面向过程的程序员的思维区别之一。在多级消息分发器的结构中,消息分发到下层的逻辑是由上层消息分发器定义的,而不是在用户模块中或者HandlerDispatcher中定义的。也就是说在整个框架中并没有一个全能选手统揽全局,每个对象都像流水线上的工人,只要把产品加工后传给下一个工人,就完成了自己的责任。
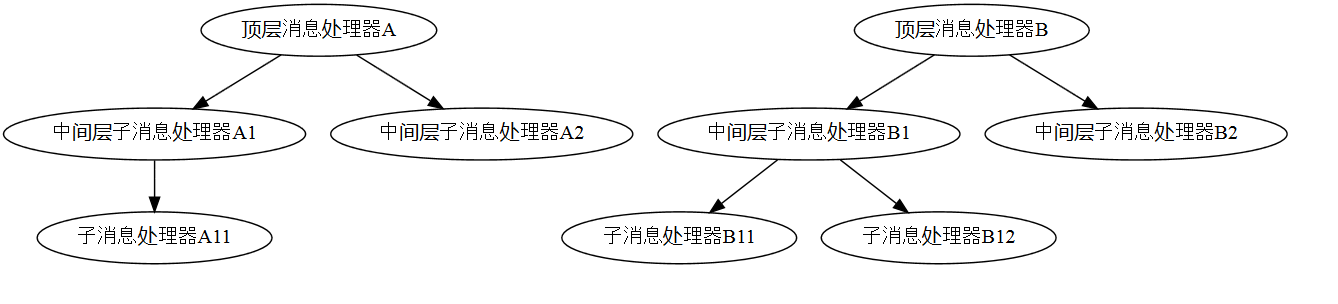
图2:消息分发结构示例
如果我们有一个上图所示的消息分发结构,那么顶层和中间层的消息处理器可以使用框架提供的ParentHandler,也可以使用自己定义的处理逻辑。如果使用ParentHandler,则process()方法会从HandlerDispatcher拿到当前Handle的子Handler进行处理,即自动实现了到下层的消息分发;如果用户需要一些特殊处理,比如分发到下层之前先打印出一些信息,或者要分发给多个子消息处理器,则可以继承ParentHandler并重写其中的process()方法,或者定义自己的Handler。
看到这里,我们应该已经基本熟悉了消息分发小框架的结构。下面我们来看一下HandlerDispatcher是如何加载和找到一个对应的Handler的。
在设计加载算法之前,再来复习一下使用场景:对于顶层消息,我们用handlerDispatcher.getHandler(getMessageIDSomehow()).process(data)来处理;顶层以下的消息,按照ParentHandler的默认实现,通过getHandlerDispatcher().getSubHandler(this, resolve(data)).process(data)处理。也就是说,HandlerDispatcher加载所有Handler之后需要达到两个效果, 一是通过messageID拿到顶层Handler,二是通过上层Handler和subID拿到对应的下层Handler。
对于第一点,只要用一个HashMap<String, Handler>就可以实现。第二点有点难办,考虑到消息的层级结构,我们先用一个树来保存不同层级的Handler。在加载时,读取@Parent来获取上下层级的对应关系。TreeNode类的定义如下:
public class TreeNode<T> {
T data;
List<TreeNode<T>> children = new ArrayList<>();
TreeNode<T> parent;
public TreeNode(TreeNode<T> parent, T data){
Objects.requireNonNull(parent);
this.parent = parent;
this.data = data;
parent.children.add(this);
}
public TreeNode(T data){
this.data = data;
}
public List<TreeNode<T>> getChildren() {
return children;
}
public T getData() {
return data;
}
}
图2示意的框架如果用TreeNode装载,可以表示如下:
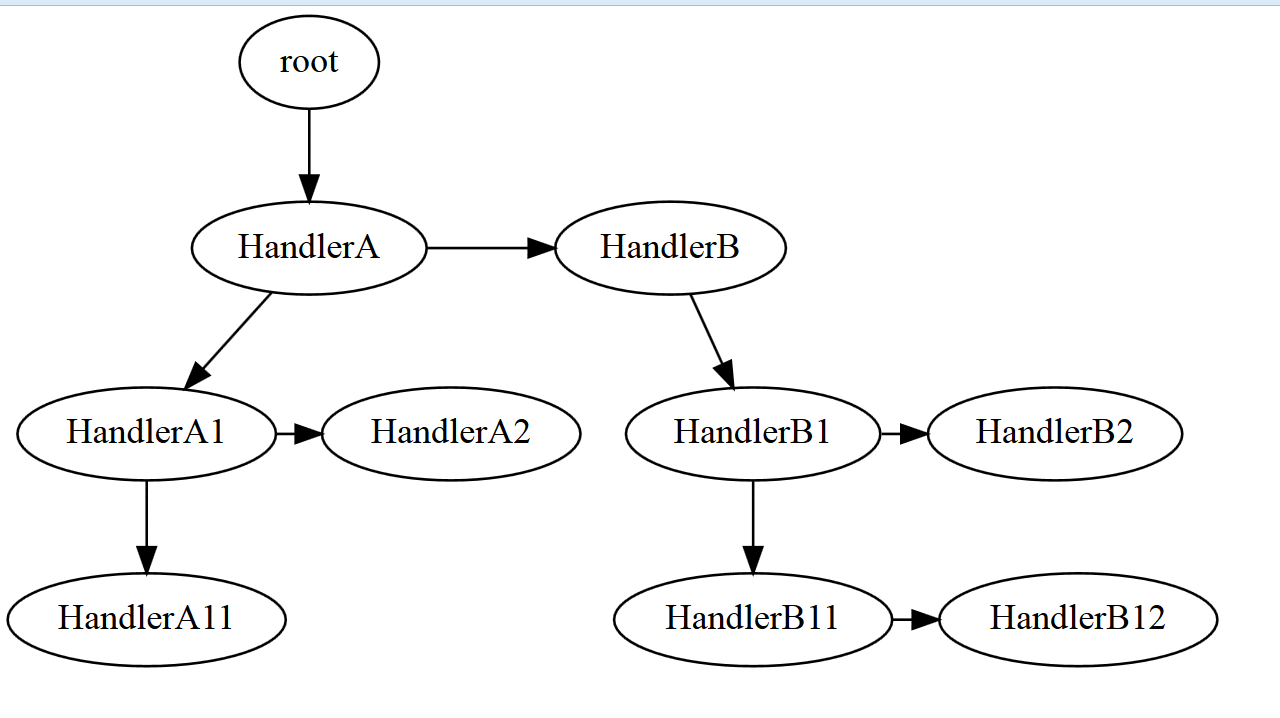
以上只是简略图,实际上TreeNode<T>是一个泛型类,泛型T代表树节点中存储的数据。为了表示messageID与Handler的对应关系,我们还会设计一个NodeData类把两者都存放起来,而这个NodeData就成为TreeNode<T>中对应的T。
class NodeData{
Handler<V> handler;
String key;
public NodeData(String key, Handler<V> handler) {
Objects.requireNonNull(key);
this.key = key;
this.handler = handler;
}
public boolean accept(String anotherKey){
return anotherKey != null && key.equals(anotherKey);
}
public Handler<V> getHandler() {
return handler;
}
}
按照TreeNode去存放后,我们就可以找到某一个父消息的子消息处理器了。但这样要求我们先遍历树,找到对应的父消息处理器;再遍历父消息处理器的孩子节点,找到子消息处理器。为了节省第一步的时间,我们把所有的父消息处理器和它们对应的树节点存在Map中,这样就可以直接按照父消息的id拿到父消息处理器了。
总结起来,我们一共设计了一个树,两个Map。将它们定义在HandlerDispatcherImpl类中作为私有域:
private Map<String, Handler<V>> topMap;
private Map<Handler<V>, TreeNode<NodeData>> nodeMap;
private TreeNode<NodeData> root;
下面我们来看一下HandlerDispatcherImpl中的load方法是怎么把Handler加载到这三个数据结构的。
首先,我们按照刚才的设计,将带注释的域分为两类:带@Parent的和不带@Parent的,分别放入两个数组中。
//Scan all fields
Class<?> instanceClass = instance.getClass();
Field[] fields = instanceClass.getDeclaredFields();
List<Field> topHandlerFields = new LinkedList<>();
List<Field> subHandlerFields = new LinkedList<>(); //Find fields with "@Mapped" annotation, insert them into
//topHandlerFields and subHandlerFields
for(Field field : fields){
Mapped mapped = field.getAnnotation(Mapped.class);
if(mapped == null) continue;
Class<?> fieldType = field.getType();
if(!Handler.class.isAssignableFrom(fieldType))
continue;
Parent parent = field.getAnnotation(Parent.class);
if(parent == null) topHandlerFields.add(field);
else subHandlerFields.add(field);
}
注意,在这里我们对域类型做了一个判断,只有域是Handler的实现类时才会被加载,否则会被无视。
将所有域加载到两个数组中以后,首先处理顶层消息对应的域,把它们放到topMap中,同时也把对应的树节点存在nodeMap中。
//insert topHandlerFields into topMap; link them with tree
topHandlerFields.forEach(field -> {
String key = extractKeyFromField(field);
try {
field.setAccessible(true);
Handler<V> handler = (Handler<V>) field.get(instance);
topMap.put(key, handler);
NodeData nodeData = new NodeData(key, handler);
TreeNode<NodeData> treeNode = new TreeNode<NodeData>(root, nodeData);
nodeMap.put(handler, treeNode);
} catch (IllegalArgumentException | IllegalAccessException e) {
e.printStackTrace(out);
}
});
然后处理非顶层消息的处理器域。这里,考虑到用户不一定是按由顶向下的顺序定义的,加载时可能先读取到子处理器,后读取父处理器,这样就无法有效地形成一个完整的树结构。于是我们采用一种循环加载的方式,先加载父节点已在树中的处理器,并将已加载的域放在一个叫processed的链表中做记录;父节点还没有被加载的那些处理器留待下一次循环时再尝试加载。(不得不佩服大神同事的考虑十分周到……)
//link subHandlerFields with tree
List<Field> processed = new LinkedList<>();
while(processed.size() < subHandlerFields.size()){
subHandlerFields.stream().filter(field -> !processed.contains(field)).forEach(field -> {
linkWithParent(field, processed, instance);
});
}
private void linkWithParent(Field field, List<Field> processed, Object instance) {
field.setAccessible(true);
Class<?> instanceClass = instance.getClass();
//Firstly, see if we could find parent field
String key = extractKeyFromField(field);
String parentName = field.getAnnotation(Parent.class).value();
Field parentHandlerField = null;
try {
parentHandlerField = instanceClass.getDeclaredField(parentName);
} catch (NoSuchFieldException | SecurityException e) {
log("Dude, your parent " + parentName + " doesn't exist.");
processed.add(field);
e.printStackTrace(); return;
}
//Try to get parentHandler, and its corresponding value in nodeMap
try {
parentHandlerField.setAccessible(true);
Handler<V> parentHandler = (Handler<V>) parentHandlerField.get(instance);
TreeNode<NodeData> parentNode = nodeMap.get(parentHandler);
if(parentNode == null){
log("Parent " + parentName + " of field " + field + " not processed yet. Will wait a while.");
return;
}
//Add subHandler as a child to parentHandler
Handler<V> subHandler = null;
subHandler = (Handler<V>) field.get(instance);
NodeData subHandlerNodeData = new NodeData(key, subHandler);
TreeNode<NodeData> childNode = new TreeNode<>(parentNode, subHandlerNodeData);
nodeMap.put(subHandler, childNode);
processed.add(field);
log("Attached " + field);
}catch (IllegalArgumentException | IllegalAccessException e) {
//should not happen
e.printStackTrace(out);
processed.add(field);
}
}
搞定了加载,我们再来看看获取。顶层Handler的获取十分容易,只要从Map拿一下就好了:
public Handler<V> getHandler(String key) {
return topMap.get(key);
}
获取子Handler也不难,先从nodeMap中找到父节点对应的树节点,然后遍历其子节点就可以了。
public Handler<V> getSubHandler(Handler<V> parentHandler, String subKey) {
TreeNode<NodeData> parentNode = nodeMap.get(parentHandler);
final Predicate<TreeNode<NodeData>> SUBHANDLER_ACCEPTS_KEY = (treeNode) -> (
((NodeData)treeNode.getData()).accept(subKey)
);
Result<TreeNode<NodeData>> result = new Result<>();
parentNode.getChildren().stream().filter(SUBHANDLER_ACCEPTS_KEY).findFirst().ifPresent(result::set);
return result.isNULL() ? null : result.get().getData().getHandler();
}
至此,我们基本完成了消息加载的小框架的核心代码啦。现在再看看开头的的示例程序中,我们看不懂的那一部分:
final Supplier<HandlerDispatcher<String>> supplier = () -> handlerDispatcher;
@Mapped("2") //第一层,处理消息ID为2的消息
final ParentHandler<String> B = ParentHandler.build(supplier, (data) -> (data.charAt(1)+""));
这里有两个问题。第一是ParentHandler.build。其实这是一个静态Util方法,用于快速生成一个ParentHandler的实现类。看一下这个方法的定义:
static <T> ParentHandler<T> build(final Supplier<HandlerDispatcher<T>> supplier, Resolver<T> resolver){
ParentHandler<T> parentHandler = new ParentHandler<T>(){
@Override
public String resolve(T data) {
return resolver.apply(data);
}
@Override
public HandlerDispatcher<T> getHandlerDispatcher() {
return supplier.get();
}
};
return parentHandler;
}
这里的Resolver是一个简单的接口,它的定义如下:
public interface Resolver<T> extends Function<T, String>{}
其实它就是一个Function接口,功能是输入消息类型T返回String,即定义一个返回子消息ID的方法。在build方法定义的ParentHandler中,通过resolver.apply(data)即可返回子消息的ID。
第二个问题是supplier。Supplier<T>类型是Java 1.8引进的一个接口,它的功能与Function类似,返回一个T类型,在这里我们定义它为HandlerDispatcher的供应者,它返回的用户定义的一个HandlerDispatcher对象。那么为什么不能直接用HandlerDispatcher对象呢?
我们先来复习一下Java类初始化的顺序:
- 当用户创建某类的对象或使用该类的静态变量/方法时,Java解释器会在classpath中寻找.class文件并加载。
- 进行所有的静态初始化。即某一个类的静态初始化只进行一次。
- 在内存堆中按需分配该对象的内存。
- 初始化该类的所有非静态变量至0或null。
- 按照类中变量的定义对变量进行初始化。
- 调用构造函数。
注意步骤5和6,JVM是先对类中的域进行初始化,再调用构造函数的。在我们的用户模块中,所有的Handler都定义为对象中的域,所以它们会先被初始化。而
handlerDispatcher = new HandlerDispatcherImpl<>();
是在构造函数中才被调用的。也就是说,如果我们不使用Supplier,我们必须要这么写:
@Mapped("2") //第一层,处理消息ID为2的消息
final ParentHandler<String> B = ParentHandler.build(handlerDispatcher, (data) -> (data.charAt(1)+""));
可是这里的handlerDispatcher是一个空指针。那么后续再通过handlerDispatcher查找子处理器的时候,会抛出空指针错误。
supplier定义了一个拿到handlerDispatcher对象的方法。虽然在定义supplier时,handlerDispatcher也是空的,但是由于我们传进去的是一个方法,所以没关系。
通过学习大神的代码,除了学到了一点大神的设计思路,还了解了一些Java 1.8的新特性,如流式编程和函数式编程,同时心里也产生了许多疑问。对于这些疑问,就让我们在以后的文章中慢慢道来吧。
消息分发小框架源码:戳这里
一个可以代替冗长switch-case的消息分发小框架的更多相关文章
- 简谈switch case
工作中从buff里截取了一个字符串,然后和配置文件中的字符串名字对比 ,如果一样,处理,不一样,elseif 再判断,再处理! switch(){case : case :...... }先说语法,再 ...
- 2017-02-23 switch case 循环语句
另一个分支语句:switch..case.. switch(变量){ case 值:代码段;break; case 值:代码段;break; ... default:代码段;b ...
- Java基础之循环语句、条件语句、switch case 语句
Java 循环结构 - for, while 及 do...while 顺序结构的程序语句只能被执行一次.如果您想要同样的操作执行多次,,就需要使用循环结构. Java中有三种主要的循环结构: whi ...
- Java switch case和数组
Java switch case 语句 switch case 语句判断一个变量与一系列值中某个值是否相等,每个值称为一个分支. 语法 switch case 语句格式: switch(express ...
- Java-Runoob:Java switch case
ylbtech-Java-Runoob:Java switch case 1.返回顶部 1. Java switch case 语句 switch case 语句判断一个变量与一系列值中某个值是否相等 ...
- JavaSE基础(七)--Java流程控制语句之switch case 语句
Java switch case 语句 switch case 语句判断一个变量与一系列值中某个值是否相等,每个值称为一个分支. 语法 switch case 语句语法格式如下: switch(exp ...
- delphi VCL研究之消息分发机制-delphi高手突破读书笔记
1.VCL 概貌 先看一下VCL类图的主要分支,如图4.1所示.在图中可以看到,TObject是VCL的祖先类,这也是Object Pascal语言所规定的.但实际上,TObject以及TObject ...
- 为什么switch...case语句比if...else执行效率高
在C语言中,教科书告诉我们switch...case...语句比if...else if...else执行效率要高,但这到底是为什么呢?本文尝试从汇编的角度予以分析并揭晓其中的奥秘. 第一步,写一个d ...
- 使用反射+策略模式代替项目中大量的switch case判断
我这里的业务场景是根据消息类型将离线消息存入mongoDB不同的collection中.其中就涉及到大量的分支判断,为了增强代码的可读性和可维护性,对之前的代码进行了重构. 先对比一下使用反射+策略模 ...
随机推荐
- Oracle EBS AP 创建贷项通知单并核销到相应发票
--1.0 生成与发票一样的贷项通知单 created by jenrry 20170423 DECLARE L_CUSTOMER_TRX_ID NUMBER; L_INVOICE_NUMBER VA ...
- mysql中InnoDB表为什么要建议用自增列做主键
InnoDB引擎表的特点 1.InnoDB引擎表是基于B+树的索引组织表(IOT) 关于B+树 (图片来源于网上) B+ 树的特点: (1)所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关 ...
- 转:C#综合揭秘——细说进程、应用程序域与上下文之间的关系
引言 本文主要是介绍进程(Process).应用程序域(AppDomain)..NET上下文(Context)的概念与操作.虽然在一般的开发当中这三者并不常用,但熟悉三者的关系,深入了解其作用,对提高 ...
- Asp连接Oracle (包含绿色版12.2客户端和ODBC驱动安装)
我能操作的终端电脑是一台linux系统可以上互联网 ,服务器在部署在独立的私网上,不方便上互联网.服务器是2008R2.安装vs不是很方便.其所linux下作开发不是不可以,java php mono ...
- unknown host www.baidu.com 解决方法
今晚一开机发现无法更新yum了,本机是连着wife的,咋无法更新呢,作为小白,一脸懵逼.于是ping了一下百度,网络不可达.... 于是我查看了一下DNS,发现设置了,于是看了一下物理机的DNS,发现 ...
- oracle like模糊查询简单用法
like 用法介绍: 1.“_”:匹配单个任意字符 select * from bqh3 where name like '_崔'; 2.“%”:匹配0个或多个任意字符.但有三种情况如下: like ...
- 李嘉诚 《Are you ready》
当你们梦想着为伟大成功的时候,你有没有刻苦的准备? 当你们有野心作领袖的时候,你有没有服务于人的谦恭? 我们常常都想有所获得,但我们有没有付出的情操? 我们都希望别人听到自己的话,我们有没有耐性聆听别 ...
- qt designer启动后不显示界面问题的原因与解决办法
Qt 5.6.1无论是在vs里双击ui文件还是直接启动designer.exe都一直无法显示界面,但任务管理器中可以看到该进程是存在的.前几天还正常的,但昨天加了一块NVIDIA的显卡(机器自带核显) ...
- 卸载CocoaPods
1. 移除pod组件 这条指令会告诉你Cocoapods组件装在哪里 : $ which pod 你可以手动移除这个组件 : $ sudo rm -rf <path> 2.移除 RubyG ...
- js指定范围随机整数
js获取指定范围内随机整数,例如 6-10 (m-n) 计算公式: Math.floor(Math.random()*(n-m))+m // 6-10随机数,用循环得出一组测试随机数 var str ...