Structrued Streaming业务数据实时分析



先启动spark-shell,记得启动nc服务
输入以下代码

scala> import org.apache.spark.sql.functions._
import org.apache.spark.sql.functions._ scala> import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.SparkSession scala> import spark.implicits._
import spark.implicits._ scala> val lines = spark.readStream.format("socket").option("host", "bigdata-pro01.kfk.com").option("port", ).load()
// :: WARN TextSocketSourceProvider: The socket source should not be used for production applications! It does not support recovery.
lines: org.apache.spark.sql.DataFrame = [value: string] scala> val words = lines.as[String].flatMap(_.split(" "))
words: org.apache.spark.sql.Dataset[String] = [value: string] scala> val wordCounts = words.groupBy("value").count()
wordCounts: org.apache.spark.sql.DataFrame = [value: string, count: bigint] scala> val query = wordCounts.writeStream.outputMode("complete").format("console").start()
query: org.apache.spark.sql.streaming.StreamingQuery = org.apache.spark.sql.execution.streaming.StreamingQueryWrapper@4e260e04
在nc输入几个单词


我们再输入一些单词

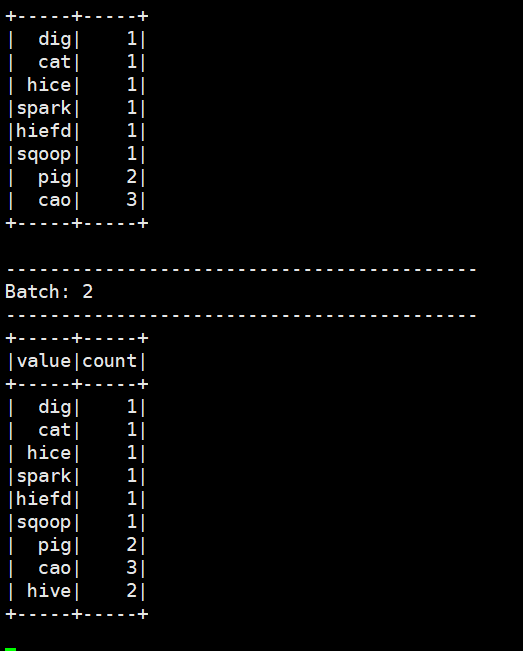
我们改一下代码换成update模式
首先重新启动一次spark-shell,记得启动nc




换成append模式
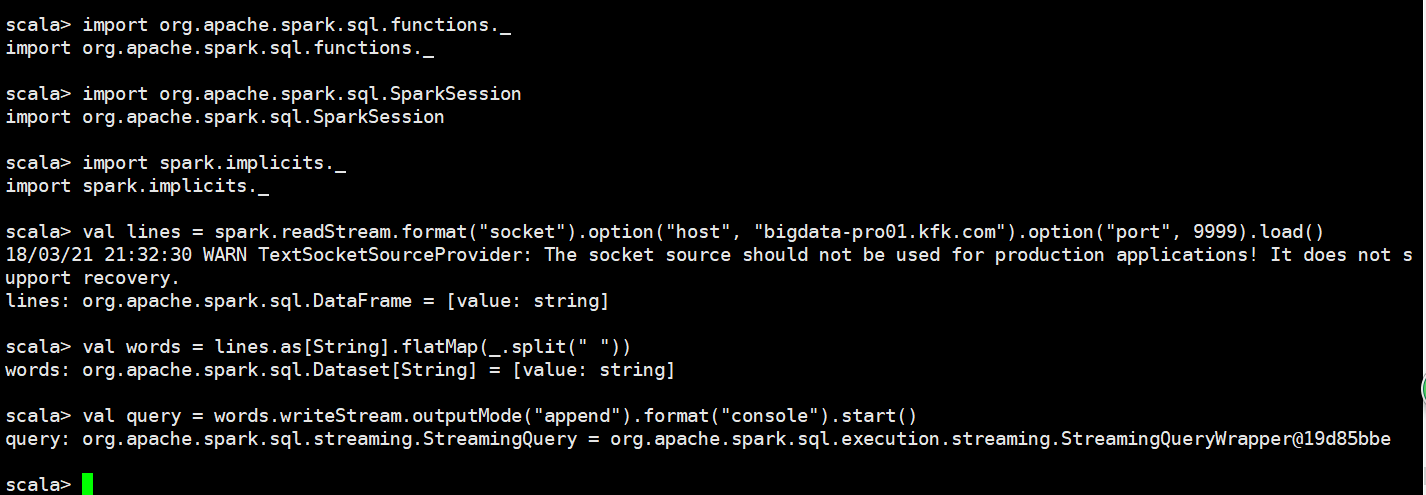
scala> import org.apache.spark.sql.functions._
import org.apache.spark.sql.functions._ scala> import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.SparkSession scala> import spark.implicits._
import spark.implicits._ scala> val lines = spark.readStream.format("socket").option("host", "bigdata-pro01.kfk.com").option("port", ).load()
// :: WARN TextSocketSourceProvider: The socket source should not be used for production applications! It does not support recovery.
lines: org.apache.spark.sql.DataFrame = [value: string] scala> val words = lines.as[String].flatMap(_.split(" "))
words: org.apache.spark.sql.Dataset[String] = [value: string] scala> val query = words.writeStream.outputMode("append").format("console").start()
query: org.apache.spark.sql.streaming.StreamingQuery = org.apache.spark.sql.execution.streaming.StreamingQueryWrapper@19d85bbe

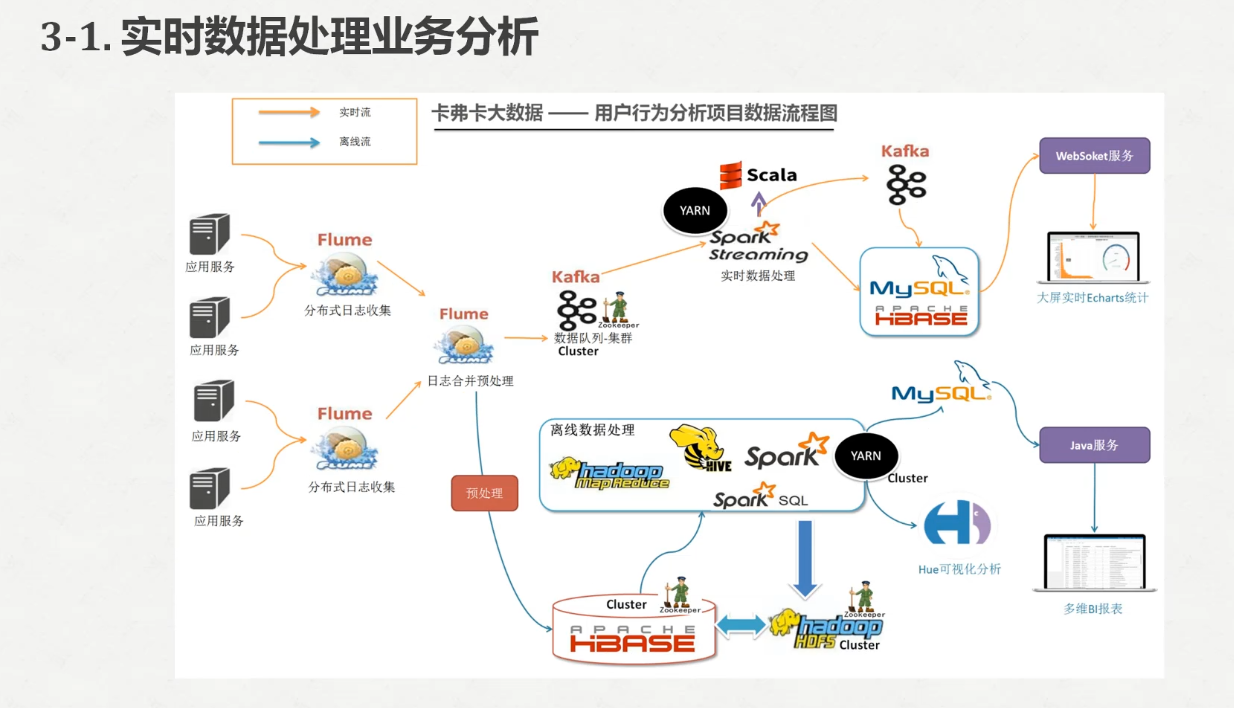

因为我们之前的kafka的版本低了,我下载一个0.10.0版本的
下载地址 http://kafka.apache.org/downloads

我们把kafka0.9版本的配置文件直接复制过来
为了快一点我直接在虚拟机里操作了
复制这几个配置文件

把kafka0.10的覆盖掉

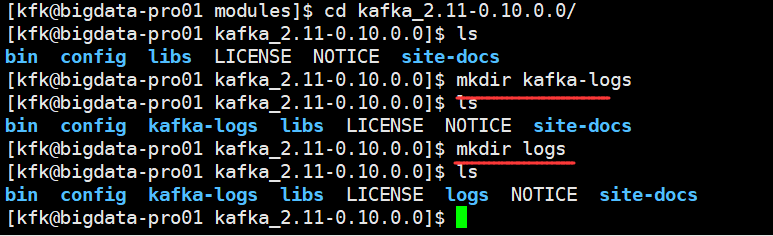
修改一下配置文件

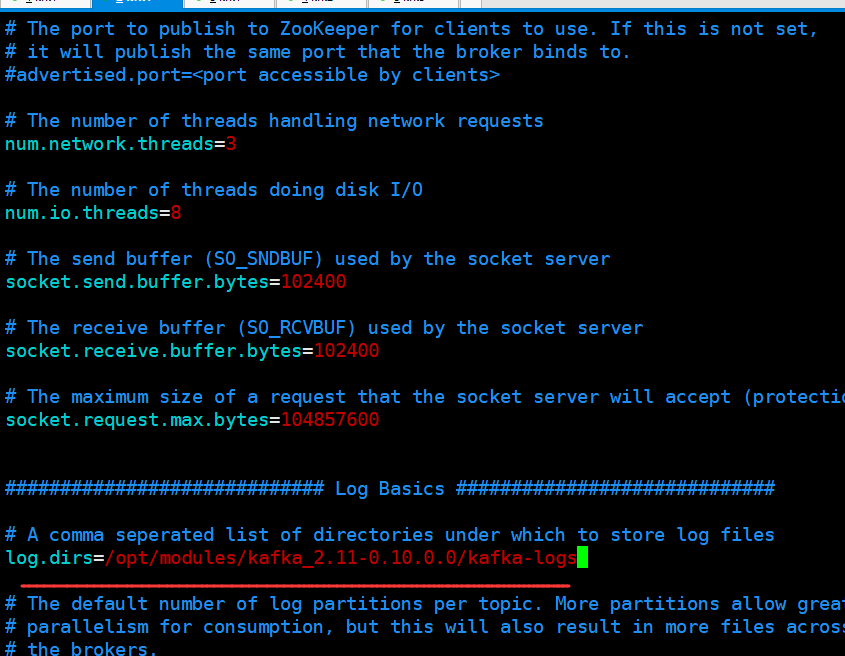
把kafka分发都另外的两个节点去


在节点2和节点3也把相应的配置文件修改一下
server.properties




在idea里重新建一个scala类
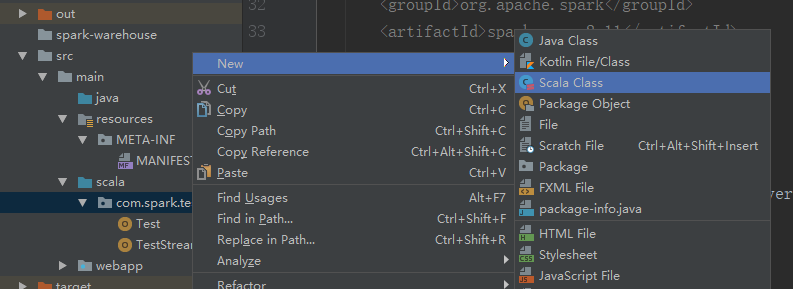

加上如下代码
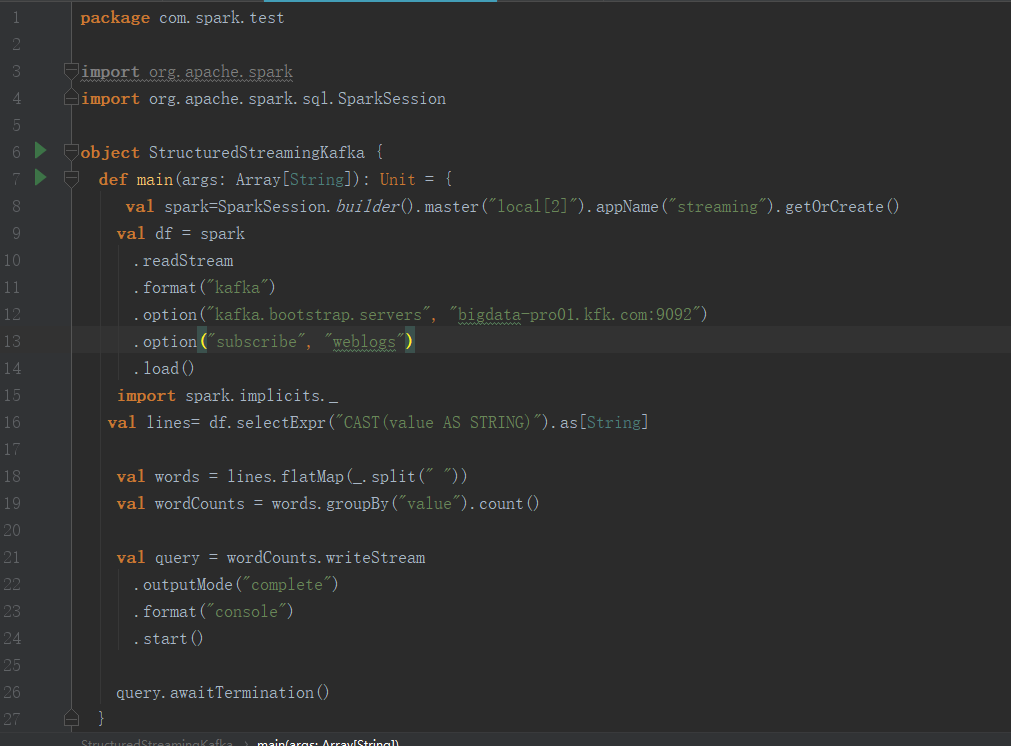
package com.spark.test import org.apache.spark
import org.apache.spark.sql.SparkSession object StructuredStreamingKafka {
def main(args: Array[String]): Unit = {
val spark=SparkSession.builder().master("local[2]").appName("streaming").getOrCreate()
val df = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "bigdata-pro01.kfk.com:9092")
.option("subscribe", "weblogs")
.load()
import spark.implicits._
val lines= df.selectExpr("CAST(value AS STRING)").as[String] val words = lines.flatMap(_.split(" "))
val wordCounts = words.groupBy("value").count() val query = wordCounts.writeStream
.outputMode("complete")
.format("console")
.start() query.awaitTermination()
}
}
跑一下我们的程序

如果报错了提示需要0.10版本的可以先不用管
我们启动一下kafka


可以看到程序已经在跑了

我们在kafak里创建一个生产者

bin/kafka-console-producer.sh --broker-list bigdata-pro01.kfk.com: --topic weblogs
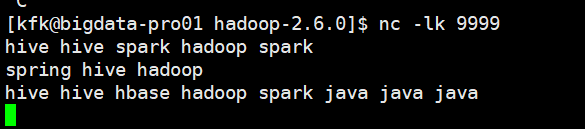
我们输入几个单词

可以看到idea这边的结果
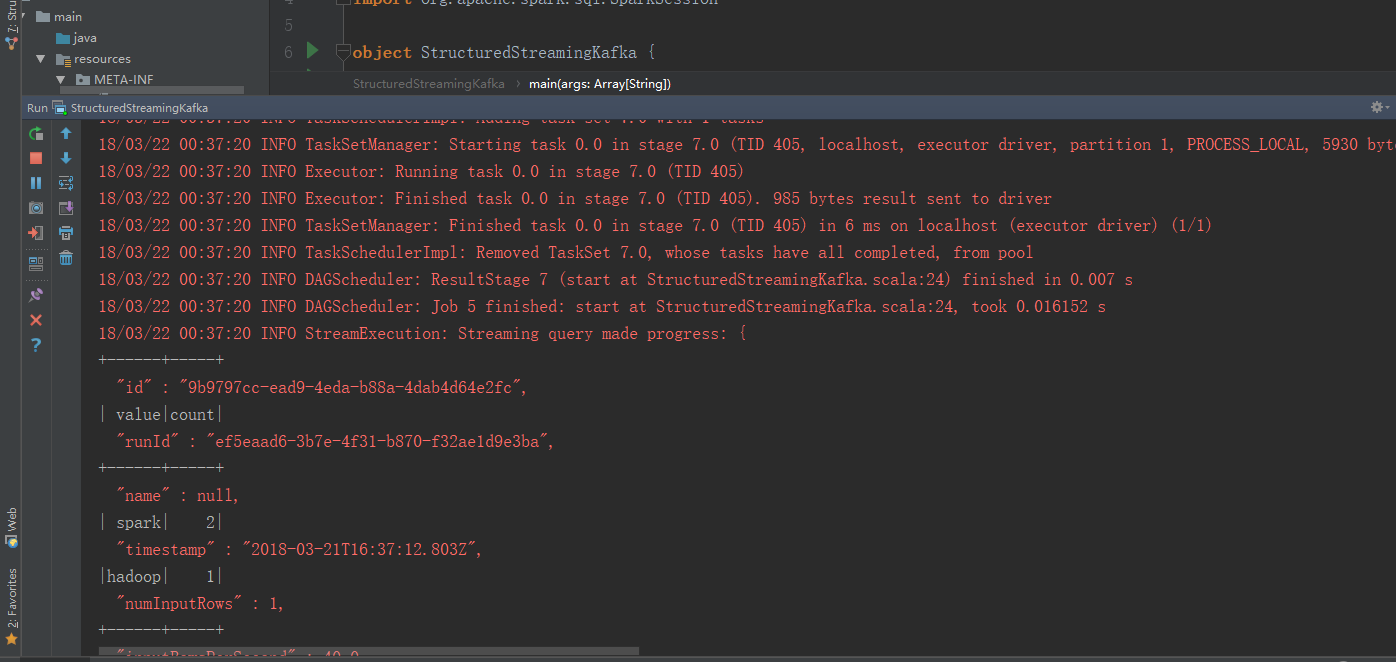
我们可以换成update模式


程序跑起来了
输入单词

这个是运行的结果


我们把包上传上来(3个节点都这样做)
启动spark-shell
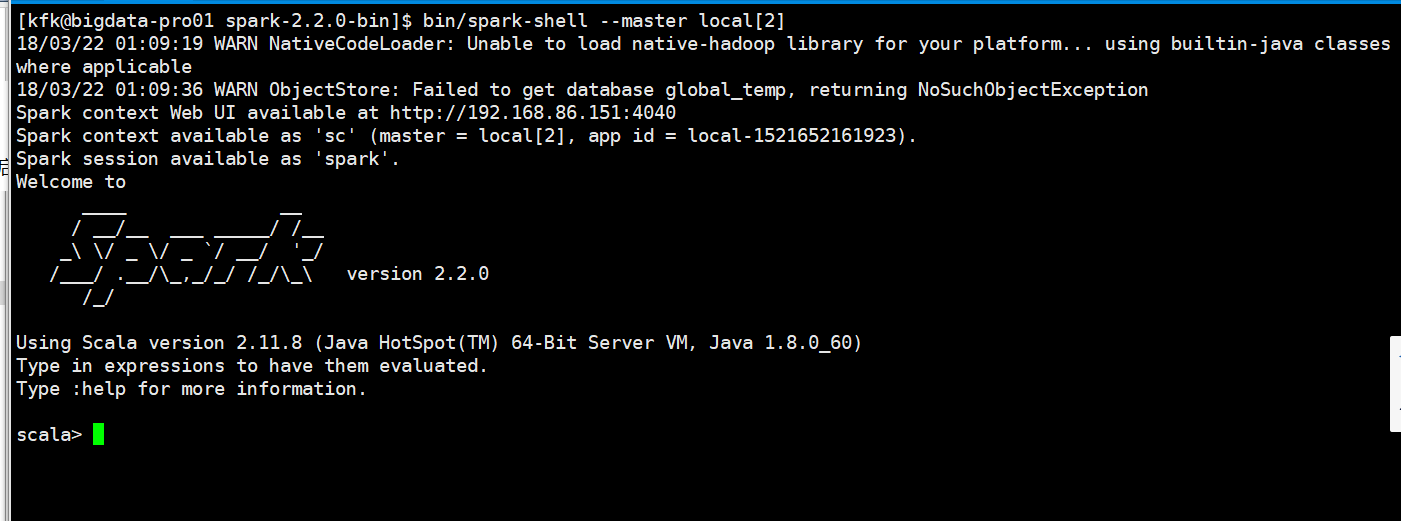
把代码拷贝进来
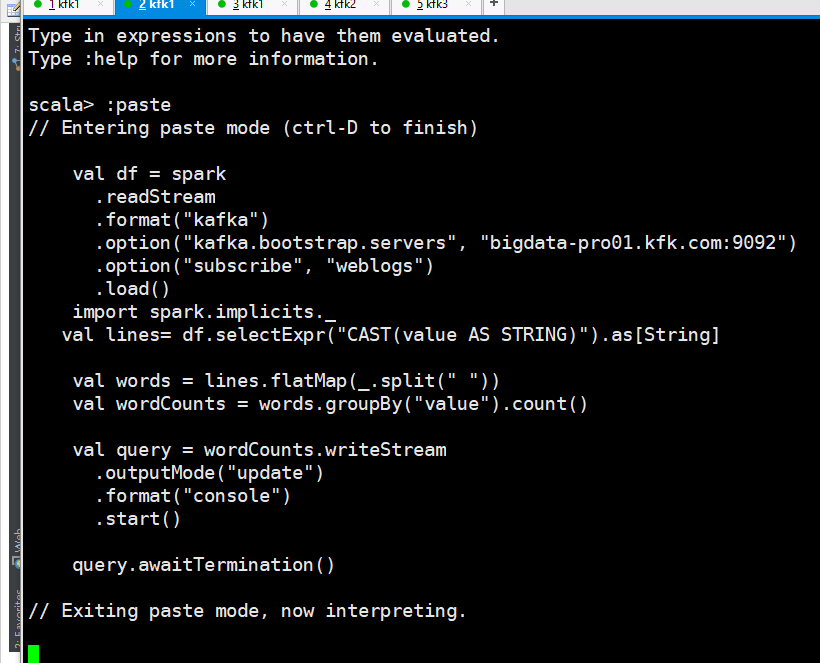
val df = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "bigdata-pro01.kfk.com:9092")
.option("subscribe", "weblogs")
.load()
import spark.implicits._
val lines= df.selectExpr("CAST(value AS STRING)").as[String] val words = lines.flatMap(_.split(" "))
val wordCounts = words.groupBy("value").count() val query = wordCounts.writeStream
.outputMode("update")
.format("console")
.start() query.awaitTermination()
这个时候一定要保持kafka和生产者是开启的
我在生产者这边输入几个单词

回到spark-shell界面可以看到统计结果


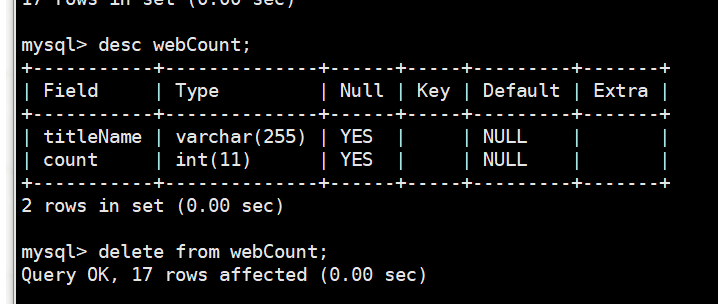
我们先把mysqld的test数据库的webCount的表的内容清除
打开idea,我们编写两个程序
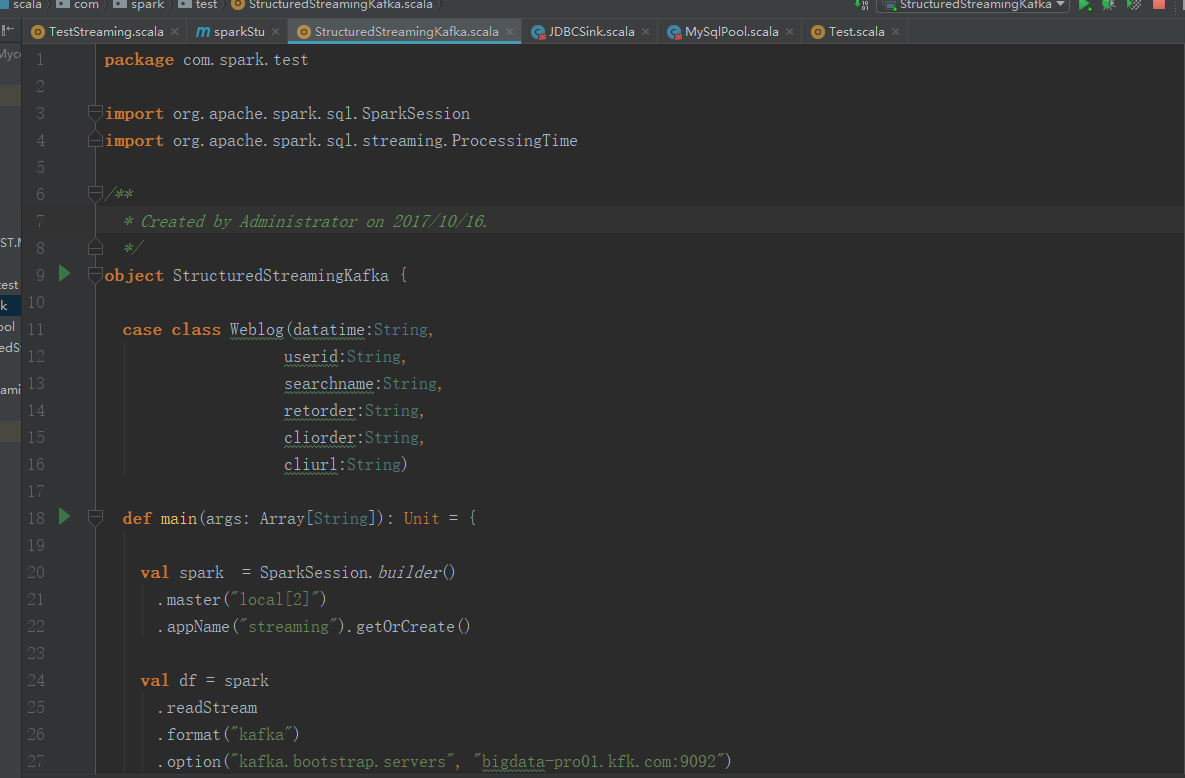
package com.spark.test import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.streaming.ProcessingTime /**
* Created by Administrator on 2017/10/16.
*/
object StructuredStreamingKafka { case class Weblog(datatime:String,
userid:String,
searchname:String,
retorder:String,
cliorder:String,
cliurl:String) def main(args: Array[String]): Unit = { val spark = SparkSession.builder()
.master("local[2]")
.appName("streaming").getOrCreate() val df = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "bigdata-pro01.kfk.com:9092")
.option("subscribe", "weblogs")
.load() import spark.implicits._
val lines = df.selectExpr("CAST(value AS STRING)").as[String]
val weblog = lines.map(_.split(","))
.map(x => Weblog(x(), x(), x(),x(),x(),x()))
val titleCount = weblog
.groupBy("searchname").count().toDF("titleName","count") val url ="jdbc:mysql://bigdata-pro01.kfk.com:3306/test"
val username="root"
val password="root" val writer = new JDBCSink(url,username,password)
val query = titleCount.writeStream
.foreach(writer)
.outputMode("update")
//.format("console")
.trigger(ProcessingTime("5 seconds"))
.start()
query.awaitTermination()
} }
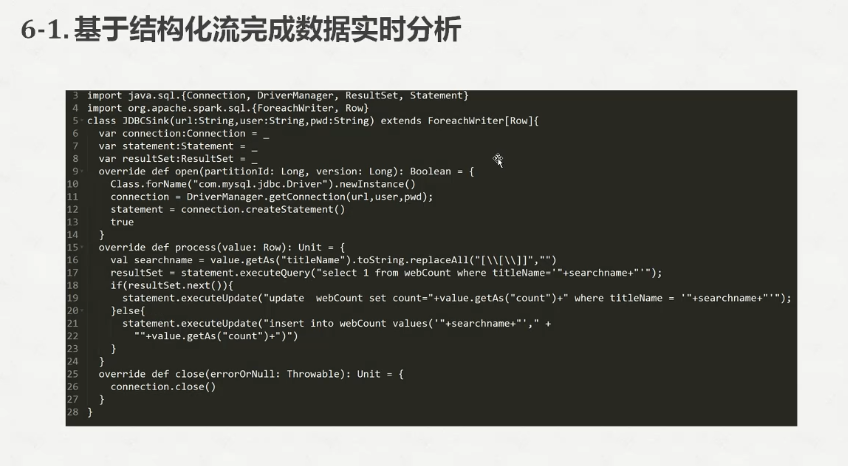
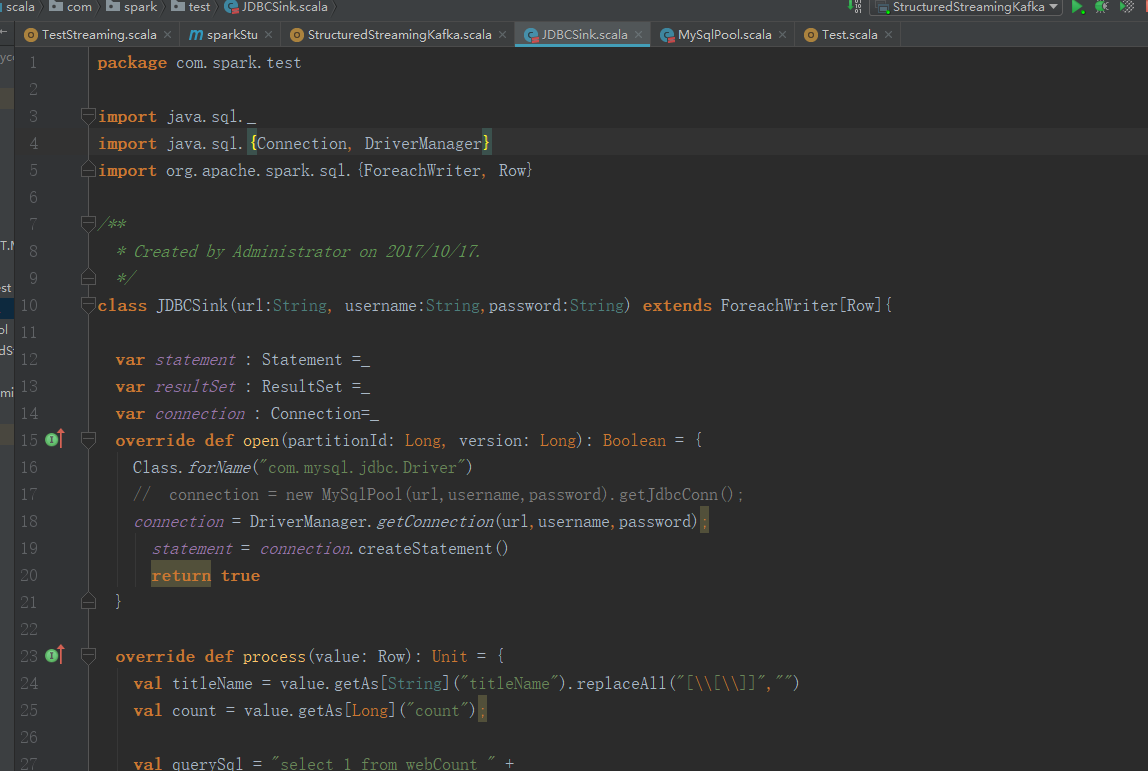
package com.spark.test import java.sql._
import java.sql.{Connection, DriverManager}
import org.apache.spark.sql.{ForeachWriter, Row} /**
* Created by Administrator on 2017/10/17.
*/
class JDBCSink(url:String, username:String,password:String) extends ForeachWriter[Row]{ var statement : Statement =_
var resultSet : ResultSet =_
var connection : Connection=_
override def open(partitionId: Long, version: Long): Boolean = {
Class.forName("com.mysql.jdbc.Driver")
// connection = new MySqlPool(url,username,password).getJdbcConn();
connection = DriverManager.getConnection(url,username,password);
statement = connection.createStatement()
return true
} override def process(value: Row): Unit = {
val titleName = value.getAs[String]("titleName").replaceAll("[\\[\\]]","")
val count = value.getAs[Long]("count"); val querySql = "select 1 from webCount " +
"where titleName = '"+titleName+"'" val updateSql = "update webCount set " +
"count = "+count+" where titleName = '"+titleName+"'" val insertSql = "insert into webCount(titleName,count)" +
"values('"+titleName+"',"+count+")" try{ var resultSet = statement.executeQuery(querySql)
if(resultSet.next()){
statement.executeUpdate(updateSql)
}else{
statement.execute(insertSql)
}
}catch {
case ex: SQLException => {
println("SQLException")
}
case ex: Exception => {
println("Exception")
}
case ex: RuntimeException => {
println("RuntimeException")
}
case ex: Throwable => {
println("Throwable")
}
} } override def close(errorOrNull: Throwable): Unit = {
// if(resultSet.wasNull()){
// resultSet.close()
// }
if(statement==null){
statement.close()
}
if(connection==null){
connection.close()
}
} }
在pom.xml文件里添加这个依赖包
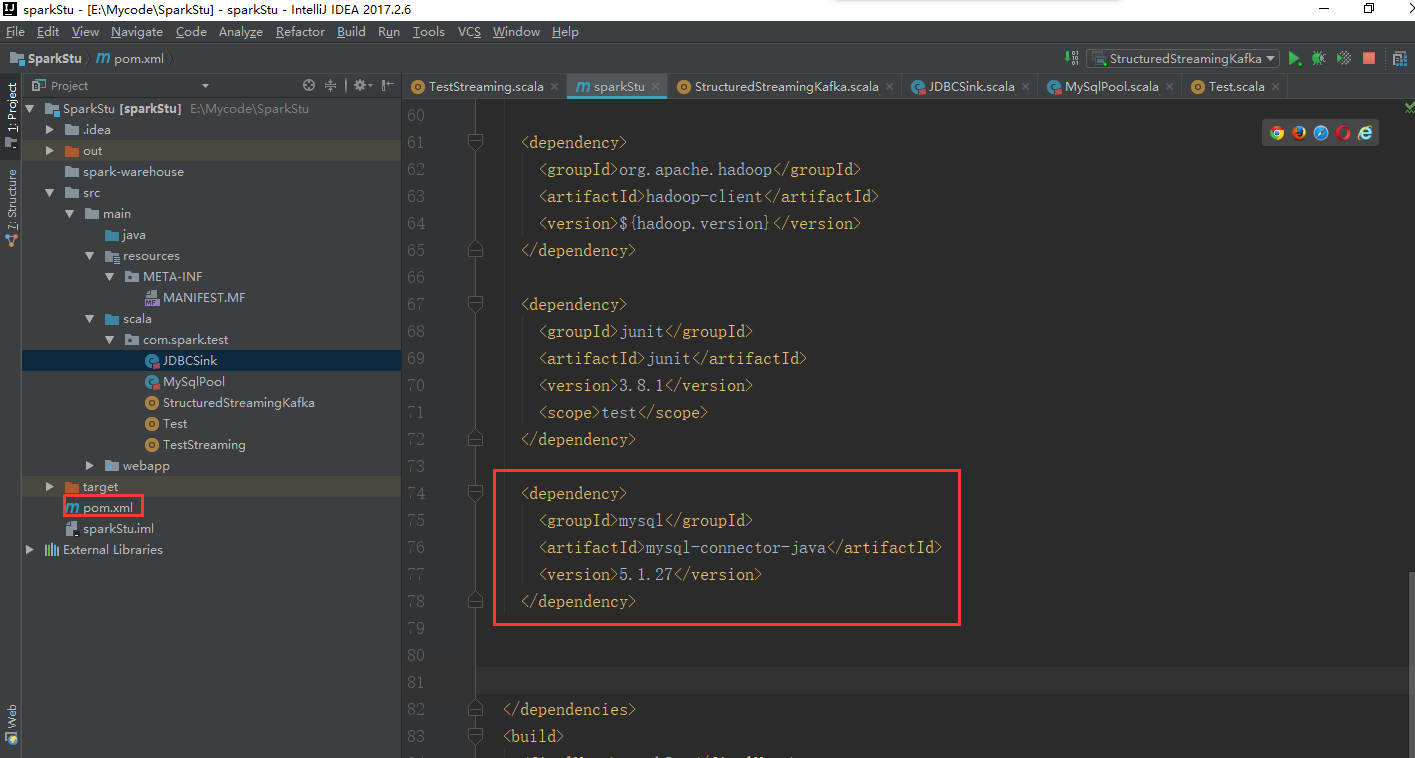
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.</version>
</dependency>
我在这里说一下这个依赖包版本的选择上最好要跟你集群里面的依赖包版本一样,不然可能会报错的,可以参考hive里的Lib路径下的版本
保持集群的dfs,hbase,yarn,zookeeper,都是启动的状态
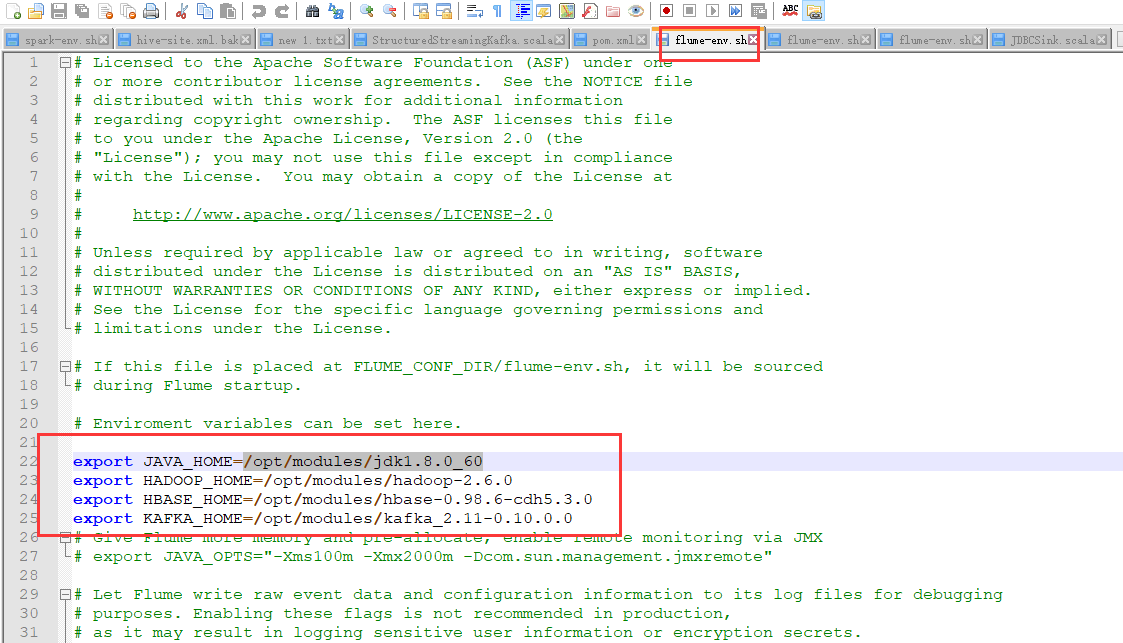
启动我们节点1和节点2的flume,在启动之前我们先修改一下flume的配置,因为我们把jdk版本和kafka版本后面更换了,所以我们要修改配置文件(3个节点的都改)
启动节点1的flume
启动节点1的kafka
bin/kafka-server-start.sh config/server.properties
启动节点2的flume
在节点2上把数据启动起来,实时产生数据
回到idea我们把程序运行一下
注意了,现在程序是没有报错的,因为我前期工作做得不是太好,给idea分配的内存小了,所以跑得很慢


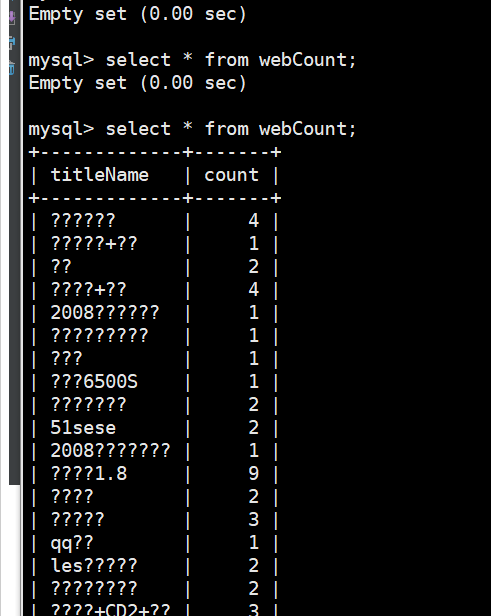
回到mysql里面查看webCount表,已经有数据进来了



我们把配置文件修改如下

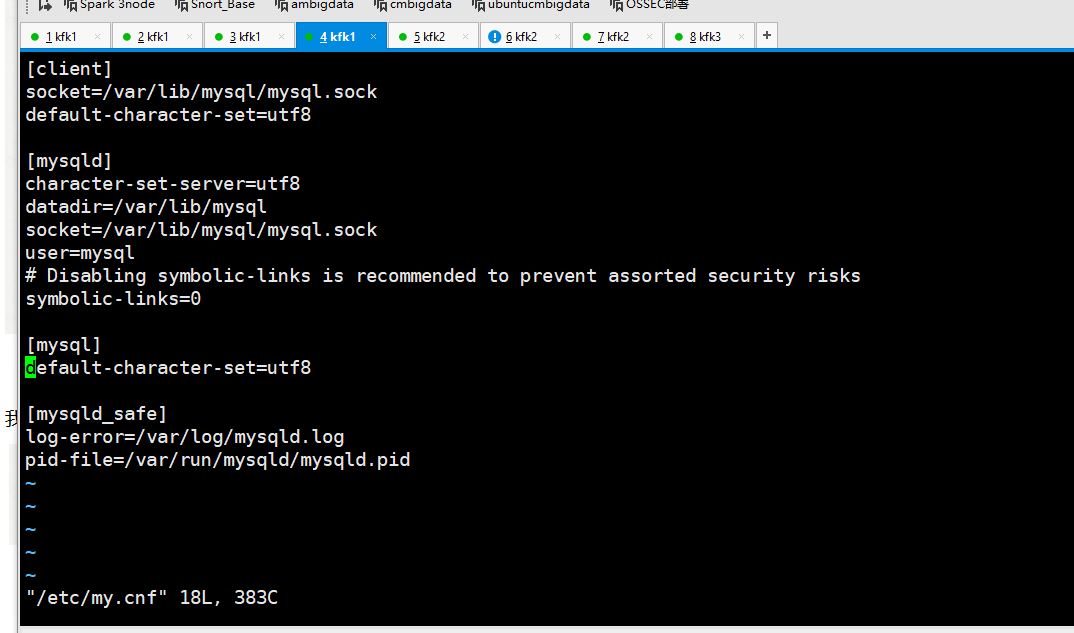
[client]
socket=/var/lib/mysql/mysql.sock
default-character-set=utf8 [mysqld]
character-set-server=utf8
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
user=mysql
# Disabling symbolic-links is recommended to prevent assorted security risks
symbolic-links= [mysql]
default-character-set=utf8 [mysqld_safe]
log-error=/var/log/mysqld.log
pid-file=/var/run/mysqld/mysqld.pid
把表删除了
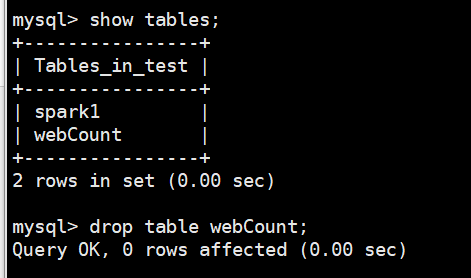
重新创建表
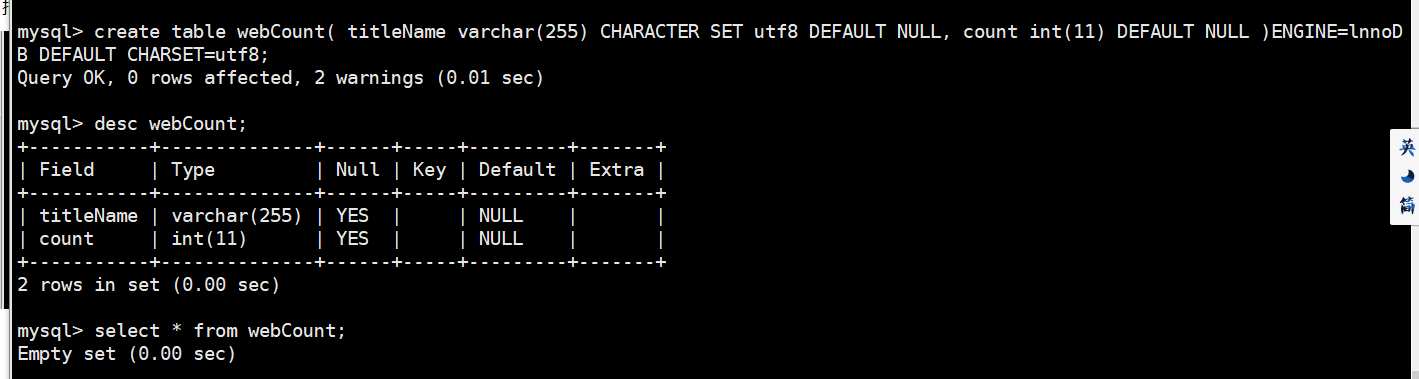
create table webCount( titleName varchar() CHARACTER SET utf8 DEFAULT NULL, count int() DEFAULT NULL )ENGINE=lnnoDB DEFAULT CHARSET=utf8;
重新在运行一次程序
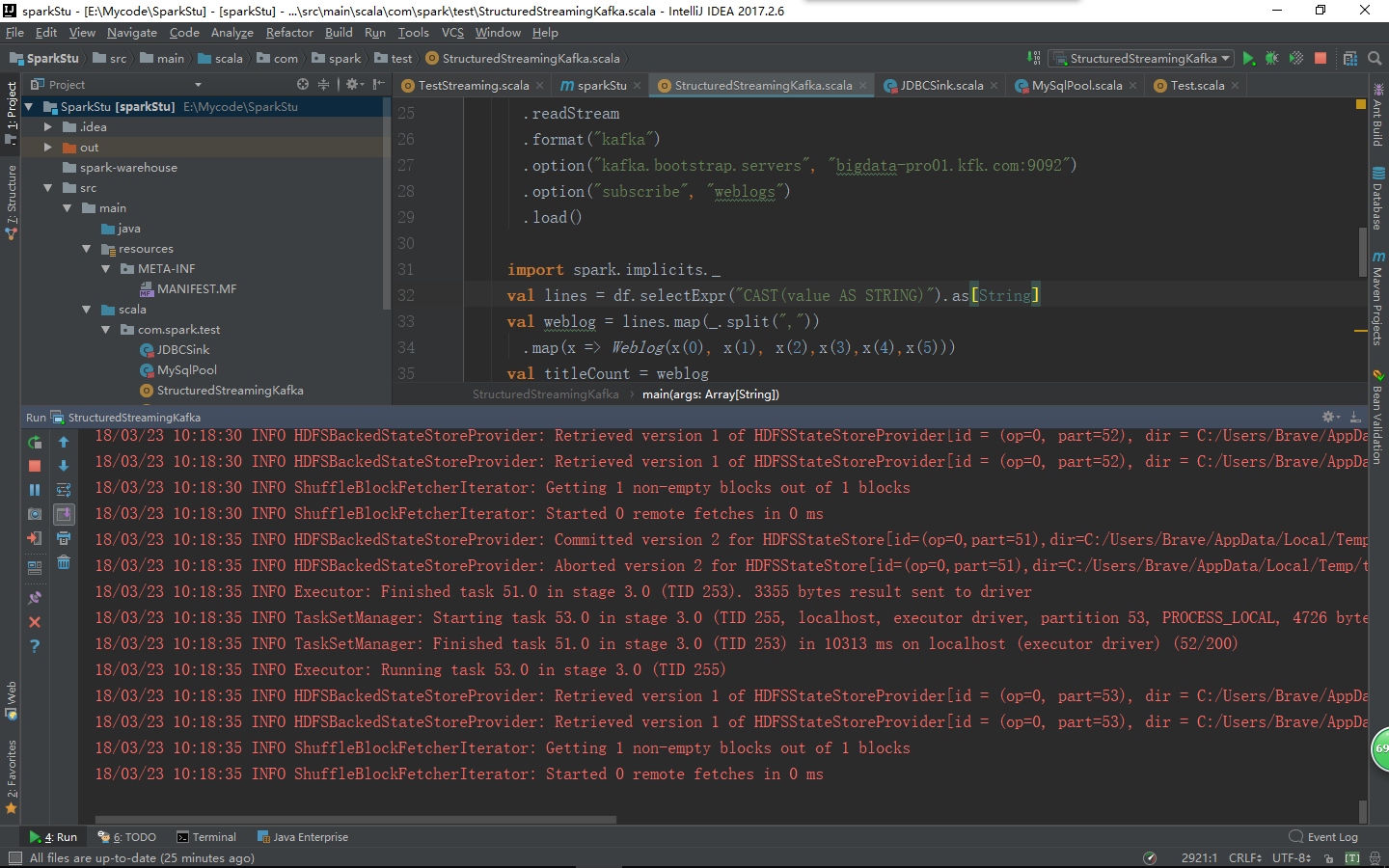

可以看到没有中文乱码了。
同时我们通过可视化工具连接mysql查看
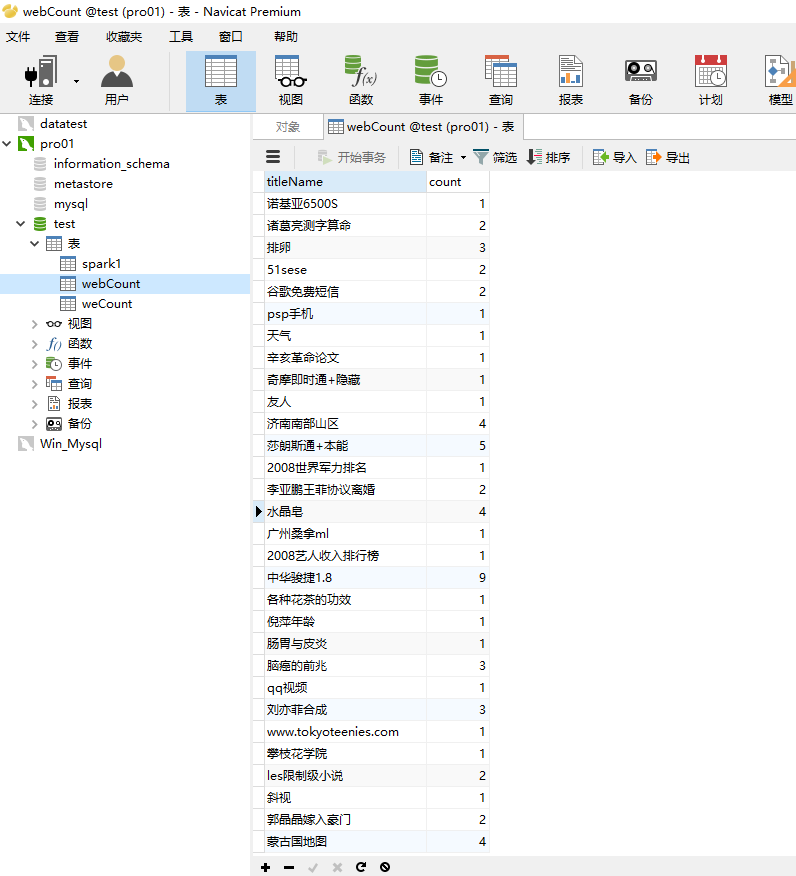
Structrued Streaming业务数据实时分析的更多相关文章
- 新闻网大数据实时分析可视化系统项目——19、Spark Streaming实时数据分析
1.Spark Streaming功能介绍 1)定义 Spark Streaming is an extension of the core Spark API that enables scalab ...
- 苏宁基于Spark Streaming的实时日志分析系统实践 Spark Streaming 在数据平台日志解析功能的应用
https://mp.weixin.qq.com/s/KPTM02-ICt72_7ZdRZIHBA 苏宁基于Spark Streaming的实时日志分析系统实践 原创: AI+落地实践 AI前线 20 ...
- 数据实时分析平台 Heron
Twitter发布了新开发的数据实时分析平台Heron,以下为官方文档摘译: 我们每天在Twitter上处理着数十亿的事件.正如你猜测的那样,实时分析这些事件是一个巨大的挑战.目前,我们主要的分析平台 ...
- 5.Flink实时项目之业务数据准备
1. 流程介绍 在上一篇文章中,我们已经把客户端的页面日志,启动日志,曝光日志分别发送到kafka对应的主题中.在本文中,我们将把业务数据也发送到对应的kafka主题中. 通过maxwell采集业务数 ...
- 6.Flink实时项目之业务数据分流
在上一篇文章中,我们已经获取到了业务数据的输出流,分别是dim层维度数据的输出流,及dwd层事实数据的输出流,接下来我们要做的就是把这些输出流分别再流向对应的数据介质中,dim层流向hbase中,dw ...
- P2P小贷网站业务数据流程分享
P2P小贷网站业务数据流程分享 引言 这是去年年底开发的一个项目,完成后和用户的衔接没有很好的做起来,所以项目就搁浅了.9月以来,看各路P2P风声水起,很是热闹:这里分享下我的设计文档,算是抛砖引玉, ...
- 业务数据实体(model) 需要克隆的方法
业务数据实体(model) 需要克隆的时候 可以使用 Json.Deserialize<InquireResult>(Json.Serialize<InquireResult> ...
- Vue单页面中进行业务数据的上报
为什么要在标题里加上一个业务数据的上报呢,因为在咱们前端项目中,可上报的数据维度太多,比如还有性能数据.页面错误数据.console捕获等.这里我们只讲解业务数据的埋点. 业务数据的上报主要分为: 各 ...
- SharePoint中使用Visio Service展示业务数据
SharePoint中可以通过Visio Service可以在浏览器中查看Visio图,功能部署到系统中,一切安好. 而现实总是很折磨人,使用该功能后,相关使用者随后提出,Visio图能否与我的业务数 ...
随机推荐
- oracle之 单实例监听修改端口
Oracle 单一主机多个实例多个监听器配置要点 1. 一台服务器主机, 有多个实例, 如: TSDB/ORCL; 又需要配置多个监听器 2. 需要指定不同的LISTENER端口 3.pmon ...
- create-react-app-typescript 知识点
github:https://github.com/wmonk/create-react-app-typescript 报错:Import sources within a group must be ...
- Centos Java环境(转)
https://jingyan.baidu.com/article/d7130635e6118213fdf47589.htm 解压jdk的安装包. 将解压后的文件夹重命名,便于后续操作(非必需) ...
- spring-配置事务
使用注解方式配置事务: 一.事物管理 事务是一系列的动作,一旦其中有一个动作出现错误,必须全部回滚,系统将事务中对数据库的所有已完成的操作全部撤消,滚回到事务开始的状态,避免出现由于数据不一致而导致的 ...
- Maven install报MojoFailureException
[ERROR] 位置: 类 com.spark.test.JavaDirectKafkaWordCount [ERROR] /I:/TrueTimeControlOnSparkByJava/src/m ...
- 回顾<Video Timing Controller v6.1>
回顾<Video Timing Controller v6.1> VTC总体架构图: 对于最基本的功能:视频时序产生
- Qsys 设计流程---Qsys System Design Tutorial
Qsys 设计流程 ---Qsys System Design Tutorial 1.Avalon-MM Pipeline Bridge Avalon-MM Pipeline Bridge在slave ...
- win764位系统上让32位程序能申请到4GB内存方法
win764位系统上让32位程序能申请到4GB内存方法. 2016年09月18日 18:36:26 阅读数:1550 最近测试一个32位程序总是在1.2G左右内存时崩溃,怀疑是内存申请失败,本身32位 ...
- 自定义自己的jQury插件
对于一个商业插件来说,自定义插件的样式是必不可少的.我们可以通过我们自己输入不同的样式,来改变开发者的默认样式.比如说最常见的 width.height.url.color等等.要是没有这些自定义的东 ...
- 53题看透java线程
1) 什么是线程? 线程是操作系统能够进行运算调度的最小单位,它被包含在进程之中,是进程中的实际运作单位.程序员可以通过它进行多处理器编程,你可以使用多线程对运算密集型任务提速.比如,如果一个线程完成 ...