harbor高可用集群配置
说明
在上一篇企业级镜像管理系统Harbor中,我们简要说明了单机版本harbor的配置。然而这种单机部署显然无法满足在生产中需求,必须要保证应用的高可用性。
目前有两种主流的方案来解决这个问题:
- 双主复制
- 多harbor实例共享后端存储
双主复制
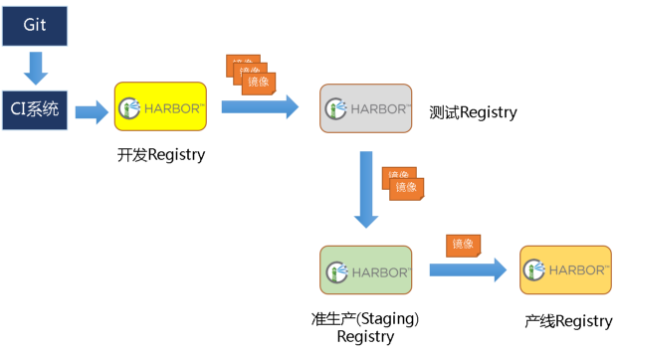
主从同步
harbor官方默认提供主从复制的方案来解决镜像同步问题,通过复制的方式,我们可以实时将测试环境harbor仓库的镜像同步到生产环境harbor,类似于如下流程:
在实际生产运维的中,往往需要把镜像发布到几十或上百台集群节点上。这时,单个Registry已经无法满足大量节点的下载需求,因此要配置多个Registry实例做负载均衡。手工维护多个Registry实例上的镜像,将是十分繁琐的事情。Harbor可以支持一主多从的镜像发布模式,可以解决大规模镜像发布的难题:
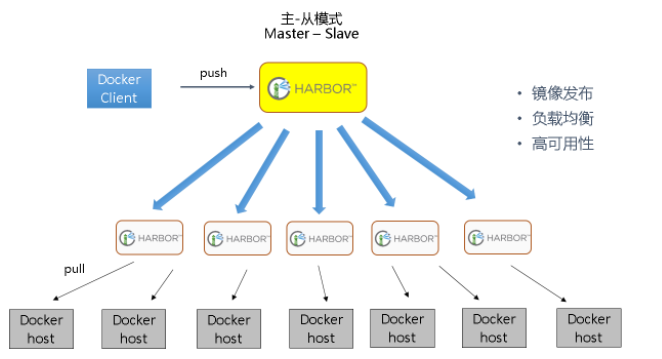
只要往一台Registry上发布,镜像就像“仙女散花”般地同步到多个Registry中,高效可靠。
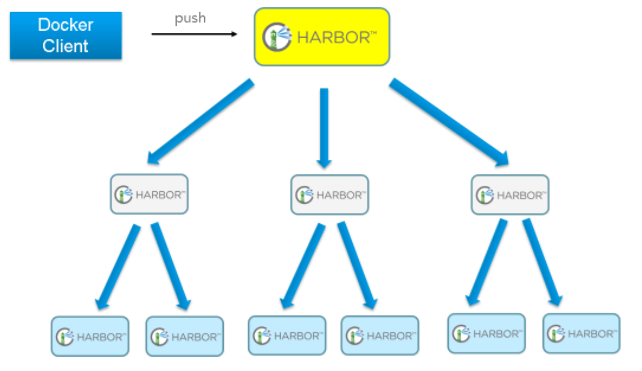
如果是地域分布较广的集群,还可以采用层次型发布方式,如从集团总部同步到省公司,从省公司再同步到市公司:
然而单靠主从同步,仍然解决不了harbor主节点的单点问题。
双主复制说明
所谓的双主复制其实就是复用主从同步实现两个harbor节点之间的双向同步,来保证数据的一致性,然后在两台harbor前端顶一个负载均衡器将进来的请求分流到不同的实例中去,只要有一个实例中有了新的镜像,就是自动的同步复制到另外的的实例中去,这样实现了负载均衡,也避免了单点故障,在一定程度上实现了Harbor的高可用性:
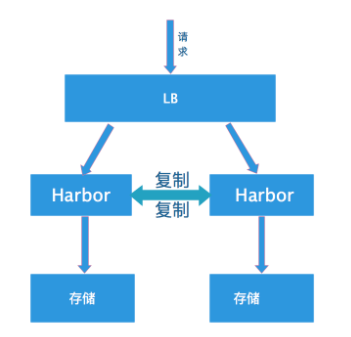
这个方案有一个问题就是有可能两个Harbor实例中的数据不一致。假设如果一个实例A挂掉了,这个时候有新的镜像进来,那么新的镜像就会在另外一个实例B中,后面即使恢复了挂掉的A实例,Harbor实例B也不会自动去同步镜像,这样只能手动的先关掉Harbor实例B的复制策略,然后再开启复制策略,才能让实例B数据同步,让两个实例的数据一致。
另外,我还需要多吐槽一句,在实际生产使用中,主从复制十分的不靠谱。
所以这里推荐使用下面要说的这种方案。
多harbor实例共享后端存储
方案说明
共享后端存储算是一种比较标准的方案,就是多个Harbor实例共享同一个后端存储,任何一个实例持久化到存储的镜像,都可被其他实例中读取。通过前置LB进来的请求,可以分流到不同的实例中去处理,这样就实现了负载均衡,也避免了单点故障:
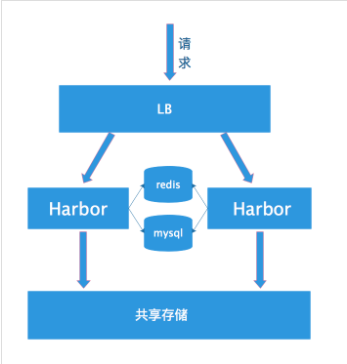
这个方案在实际生产环境中部署需要考虑三个问题:
- 共享存储的选取,Harbor的后端存储目前支持AWS S3、Openstack Swift, Ceph等,在我们的实验环境里,就直接使用nfs
- Session在不同的实例上共享,这个现在其实已经不是问题了,在最新的harbor中,默认session会存放在redis中,我们只需要将redis独立出来即可。可以通过redis sentinel或者redis cluster等方式来保证redis的可用性。在我们的实验环境里,仍然使用单台redis
- Harbor多实例数据库问题,这个也只需要将harbor中的数据库拆出来独立部署即可。让多实例共用一个外部数据库,数据库的高可用也可以通过数据库的高可用方案保证。
环境说明
实验环境:
| ip | role |
|---|---|
| 192.168.198.133 | harbor |
| 192.168.198.135 | harbor |
| 192.168.198.136 | redis、mysql、nfs |
需要强调的是,我们的环境中,不包括负载均衡器的配置,请自行查阅负载均衡配置相关文档
配置说明
安装nfs
# 安装nfs
apt install nfs-kernel-server nfs-common
# 编辑/etc/exports文件
/data *(rw,no_root_squash)
chmod 777 -R /data
systemctl start nfs-server
安装redis和mysql
这里我们就直接通过docker安装,docker-compose.yml文件内容如下:
version: '3'
services:
mysql-server:
hostname: mysql-server
container_name: mysql-server
image: mysql:5.7
network_mode: host
volumes:
- /mysql57/data:/var/lib/mysql
command: --character-set-server=utf8
environment:
MYSQL_ROOT_PASSWORD: 123456
redis:
hostname: redis-server
container_name: redis-server
image: redis:3
network_mode: host
启动:
docker-compose up -d
导入registry数据库
配置好了mysql以后,还需要往mysql数据库中导入harbor registry库。在《企业级镜像管理系统》中,我们安装了一个单机版harbor,启动了一个mysql,里面有一个registry数据库,直接导出来,然后再导入到新数据库中:
# 导出数据库:
docker exec -it harbor_db /bin/bash
mysqldump -uroot -p --databases registry > registry.dump
# 在宿主机上将registry.dump复制出来
docker cp harbor_db:/registry.dump ./
# 将宿主机上的registry.dump复制到独立的mysql容器中
docker cp ./registry.dump <mysql-server-container>:/registry.dump
# 在独立的mysql容器将将registry数据库导入
docker exec -it <mysql-server-container> /bin/bash
mysql -uroot -p
mysql> source /registry.dump
配置harbor
挂载nfs目录
在harbor节点上挂载nfs目录:
mount -t nfs 192.168.198.136:/data /data
修改harbor.cfg配置
在harbor节点上,下载好harbor的安装包,生成好自签名证书,修改prepare文件,可直接参考《企业级镜像管理系统Harbor》,不同的是,harbor.cfg文件需要修改数据库及redis配置如下:
db_host = 192.168.198.136
db_password = 123456
db_port = 3306
db_user = root
redis_url = 192.168.198.136:6379
修改docker-compose.yml配置
与单机版harbor相比,集群配置不再需要启动mysql和redis,所以docker-compose.yml也需要作相应修改。事实上,在harbor的安装目录中,有个ha的目录,里面已经提供了我们需要的docker-compose.yml文件,只需要复制出来即可。实际上,在这个目录中,还提供了使用lvs作为负载均衡器时,keepalived的配置。
cp ha/docker-compose.yml
./prepare
./install.sh
在两个harbor节点上完成安装以后,我们可以通过绑定hosts到不同的节点来验证两个节点的负载均衡效果。
harbor高可用集群配置的更多相关文章
- MongoDB高可用集群配置的方案
>>高可用集群的解决方案 高可用性即HA(High Availability)指的是通过尽量缩短因日常维护操作(计划)和突发的系统崩溃(非计划)所导致的停机时间,以提高系统和应用的可用性. ...
- SpringCloud-day04-Eureka高可用集群配置
5.4Eureka高可用集群配置 在高并发的情况下一个注册中心难以满足,因此一般需要集群配置多台. 我们再新建两个module microservice-eureka-server-2002, m ...
- Eureka注册中心高可用集群配置
Eureka高可用集群配置 当注册中心扛不住高并发的时候,这时候 要用集群来扛: 我们再新建两个module microservice-eureka-server-2002 microservic ...
- MongoDB高可用集群配置方案
原文链接:https://www.jianshu.com/p/e7e70ca7c7e5 高可用性即HA(High Availability)指的是通过尽量缩短因日常维护操作(计划)和突发的系统崩溃(非 ...
- Hadoop入门学习笔记-第三天(Yarn高可用集群配置及计算案例)
什么是mapreduce 首先让我们来重温一下 hadoop 的四大组件:HDFS:分布式存储系统MapReduce:分布式计算系统YARN: hadoop 的资源调度系统Common: 以上三大组件 ...
- harbor高可用集群搭建
高可用harbor集群搭建 一.安装部署 1.节点角色 角色 数量 名称 备注 harbor主节点 2 harbor-1 harbor-2 双主模式 haproxy 2 HA-1 HA-2 需要通过k ...
- RHCS高可用集群配置(luci+ricci+fence)
一.什么是RHCS RHCS是Red Hat Cluster Suite的缩写,也就是红帽集群套件,RHCS是一个能够提供高可用性.高可靠性.负载均衡.存储共享且经济廉价的集群工具集合,它将集群 ...
- MongoDB分片技术原理和高可用集群配置方案
一.Sharding分片技术 1.分片概述 当数据量比较大的时候,我们需要把数分片运行在不同的机器中,以降低CPU.内存和Io的压力,Sharding就是数据库分片技术. MongoDB分片技术类似M ...
- Hadoop(25)-高可用集群配置,HDFS-HA和YARN-HA
一. HA概述 1. 所谓HA(High Available),即高可用(7*24小时不中断服务). 2. 实现高可用最关键的策略是消除单点故障.HA严格来说应该分成各个组件的HA机制:HDFS的HA ...
随机推荐
- HTML基础语法
目录 HTML基础语法 1.全局架构标签 2.标题 3.段落 4.文本 5.属性 6.链接 7.图片 8.列表 9.表格 10.区块 11.布局 12.表单 13.框架 14.头部 HTML基础语法 ...
- 设计模式 笔记 备忘录模式 Memento
//---------------------------15/04/27---------------------------- //Memento 备忘录模式----对象行为型模式 /* 1:意图 ...
- LHS 和 RHS----你所不知道的JavaScript系列(1)
变量的赋值操作会执行两个动作, 首先编译器会在当前作用域中声明一个变量(如果之前没有声明过), 然后在运行时引擎会在作用域中查找该变量, 如果能够找到就会对它赋值.----<你所不知道的Ja ...
- Scrapy的日志等级和请求传参
日志等级 日志信息: 使用命令:scrapy crawl 爬虫文件 运行程序时,在终端输出的就是日志信息: 日志信息的种类: ERROR:一般错误: WARNING:警告: INFO:一般的信息: ...
- SSM整合配置(Spring+Spring MVC+Mybatis)
一.配置准备 通过Maven工程,在eclipse中整合SSM,并在Tomcat服务器上运行 在进行配置前,先理清楚要配置哪些文件,如图,除web.xml外,其余三个配置文件名称均可自定义: 如图 ...
- idea创建web项目教程
官网下载idea,安装配置好后,双击进来,第一次创建项目时新建是这样的 第一步: 第二步:创建项目名和项目存放的路径 点finish进入这里 第三步: 第二步点OK进入这个页面,点上面那个加号 ...
- Scrum Meeting NO.1
Scrum Meeting No.1 1.会议内容 不出所料地,组员们都在忙着写编译.编译大作业的进度已经接近尾声,码农们已经磨刀霍霍向软工-- 在上一周,bugphobia和我们组决定共同使用一套后 ...
- Linux内核分析(第四周)
扒开系统调用的三层皮(上) 一.用户态.内核态.中断 (上周课件有学习到) 1.地址空间是一个显著的标志(是逻辑地址,不是物理地址) 2.CPU每条指令的读取都是通过cs:eip这两个寄存器:0xc0 ...
- rethinking virtual network embedding..substrate support for path splitting and migration阅读笔记
1.引言 网络虚拟化, 1.支持同一个底层网络有多种网络架构,每种架构定制一个应用或用户社区. 2.也可以让多个服务提供者在共同的物理基础设施上定制端到端的服务.如Voice over IP(VoIP ...
- “一片空白”的c#
using System; using System.Collections.Generic; using System.Text; namespace FindTheNumber ...