Hadoop项目开发环境搭建(Eclipse\MyEclipse + Maven)
写在前面的话
可详细参考,一定得去看
HBase 开发环境搭建(Eclipse\MyEclipse + Maven)
Zookeeper项目开发环境搭建(Eclipse\MyEclipse + Maven)
Hive项目开发环境搭建(Eclipse\MyEclipse + Maven)
MapReduce 开发环境搭建(Eclipse\MyEclipse + Maven)
我这里,相信,能看此博客的朋友,想必是有一定基础的了。我前期写了大量的基础性博文。可以去补下基础。
步骤一:File -> New -> Project -> Maven Project

步骤二:自行设置,待会创建的myHBase工程,放在哪个目录下。
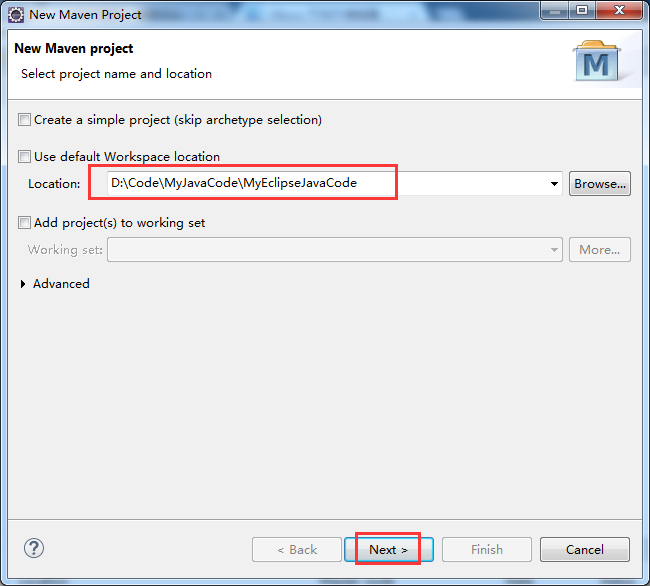
步骤三:
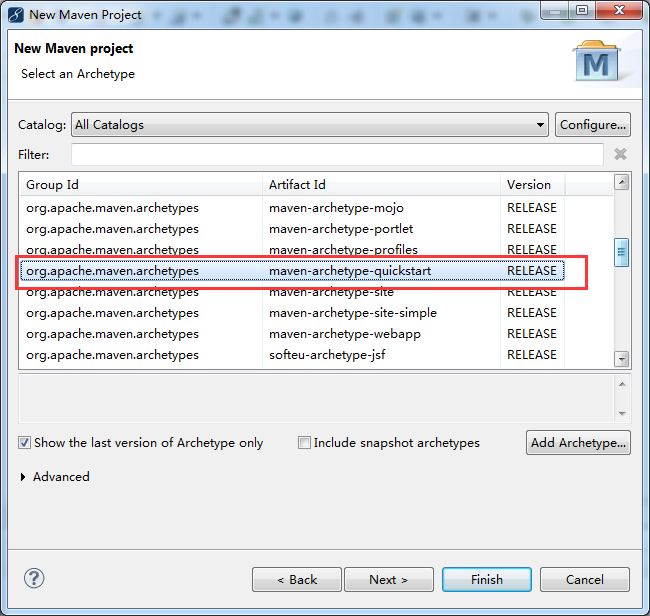
步骤四:自行设置

步骤五:修改jdk
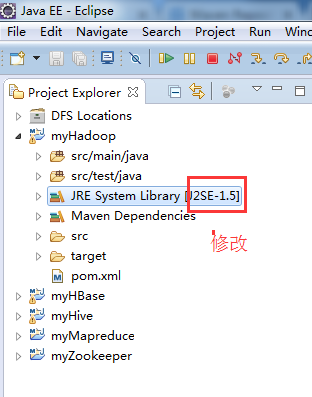
省略,很简单!
步骤六:修改pom.xml配置文件
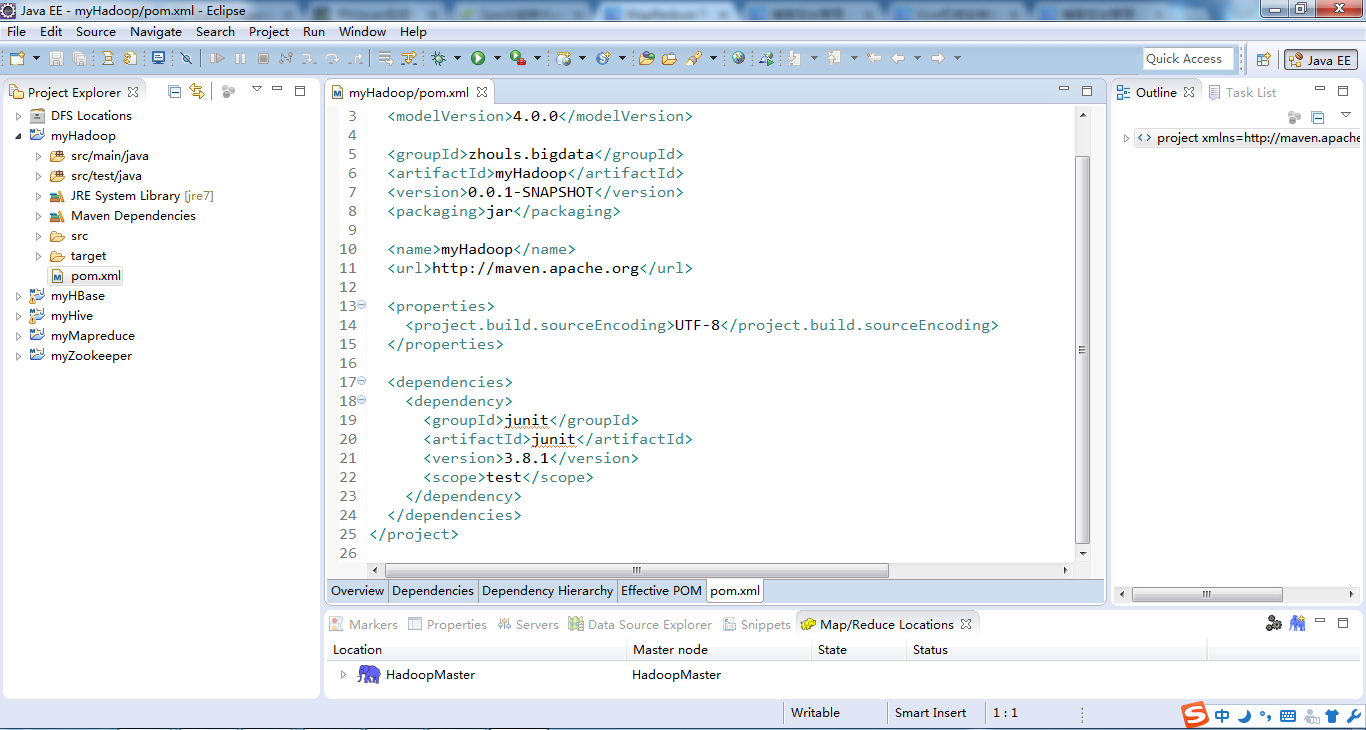
参考: http://blog.itpub.net/26495863/viewspace-1328030/
http://blog.csdn.net/kongxx/article/details/42339581 (推荐)
官网Maven的Hadoop配置文件内容:
http://www.mvnrepository.com/search?q=hadoop

因为我的hadoop版本是hadoop-2.6.0
1、
2、
3、

4、

暂时这些吧,以后需要,可以自行再加呢!
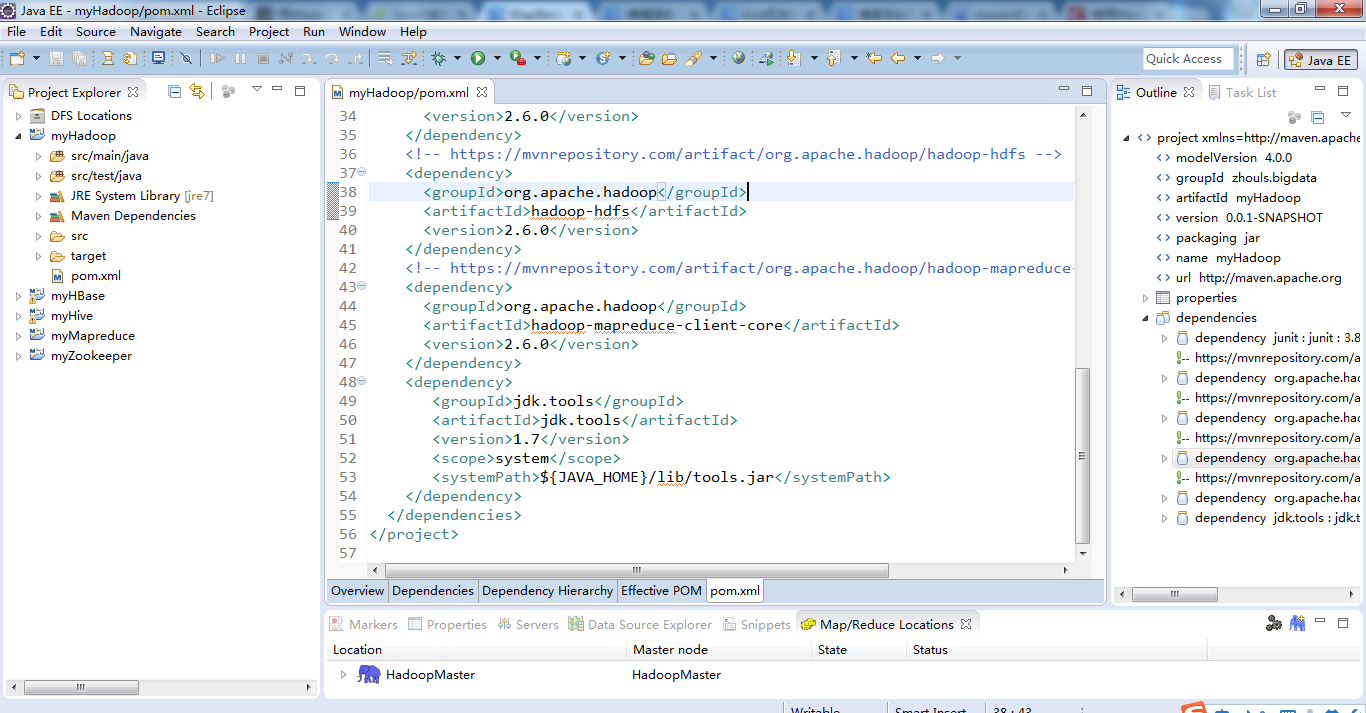
最后的pom.xml配置文件为
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>zhouls.bigdata</groupId>
<artifactId>myHadoop</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>myHadoop</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-hdfs -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.6.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-mapreduce-client-core -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
<version>1.7</version>
<scope>system</scope>
<systemPath>${JAVA_HOME}/lib/tools.jar</systemPath>
</dependency>
</dependencies>
</project>
当然,这只是初步而已,最简单的,以后可以自行增删。
步骤七:这里,给大家,通过一组简单的Hive应用程序实例来向大家展示Hive的某些功能。
类名为HadoopTestCase.java
当然,这里,分hdfs和mapreduce测试。具体不多赘述了!很简单的
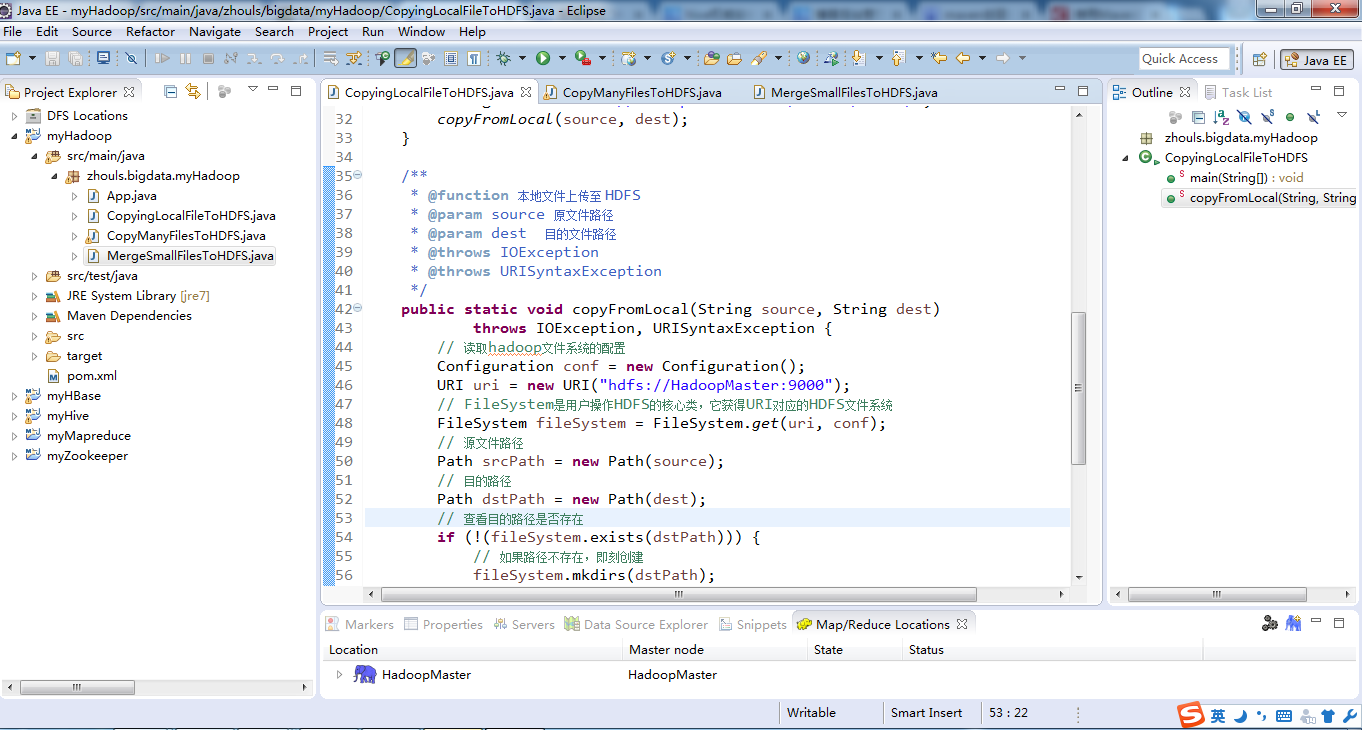
比如CopyingLocalFileToHDFS.java 、 CopyManyFilesToHDFS.java 、 MergeSmallFilesToHDFS.java
package zhouls.bigdata.myHadoop;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
/**
*
* @author
* @function Copying from Local file system to HDFS
*
*/
public class CopyingLocalFileToHDFS
{
/**
* @function Main() 方法
* @param args
* @throws IOException
* @throws URISyntaxException
*/
public static void main(String[] args) throws IOException,URISyntaxException
{
// 本地文件路径
String source = "D://Data/weibo.txt";
// hdfs文件路径
String dest = "hdfs://HadoopMaster:9000/middle/weibo/";
copyFromLocal(source, dest);
}
/**
* @function 本地文件上传至 HDFS
* @param source 原文件路径
* @param dest 目的文件路径
* @throws IOException
* @throws URISyntaxException
*/
public static void copyFromLocal(String source, String dest)
throws IOException, URISyntaxException {
// 读取hadoop文件系统的配置
Configuration conf = new Configuration();
URI uri = new URI("hdfs://HadoopMaster:9000");
// FileSystem是用户操作HDFS的核心类,它获得URI对应的HDFS文件系统
FileSystem fileSystem = FileSystem.get(uri, conf);
// 源文件路径
Path srcPath = new Path(source);
// 目的路径
Path dstPath = new Path(dest);
// 查看目的路径是否存在
if (!(fileSystem.exists(dstPath))) {
// 如果路径不存在,即刻创建
fileSystem.mkdirs(dstPath);
}
// 得到本地文件名称
String filename = source.substring(source.lastIndexOf('/') + 1,source.length());
try {
// 将本地文件上传到HDFS
fileSystem.copyFromLocalFile(srcPath, dstPath);
System.out.println("File " + filename + " copied to " + dest);
} catch (Exception e) {
System.err.println("Exception caught! :" + e);
System.exit(1);
} finally {
fileSystem.close();
}
}
}
package zhouls.bigdata.myHadoop;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.FileUtil;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.PathFilter;
/**
* @function 将指定格式的多个文件上传至 HDFS
* @author 小讲
*
*/
public class CopyManyFilesToHDFS {
private static FileSystem fs = null;
private static FileSystem local = null;
/**
* @function Main 方法
* @param args
* @throws IOException
* @throws URISyntaxException
*/
public static void main(String[] args) throws IOException,URISyntaxException
{
//文件源路径 这是在 Windows 下测试运行,如果在 Linux 修改srcPath路径即可
String srcPath = "/home/hadoop/djt/data/*";
//String srcPath = "D://Data/testdata/*";
//或者Path srcPath =new Path("D://Data/testdata/*");
//文件目的路径 如果在 Hadoop 环境下运行,使用 dstPath 的相对路径"/middle/filter/"也可以
String dstPath = "hdfs://HadoopMaster:9000/middle/filter/";
//或者Path dstPath = new Path("hdfs://HadoopMaster:9000/middle/filter/");
//调用文件上传 list 方法
list(srcPath,dstPath);
}
/**
* function 过滤文件格式 将多个文件上传至 HDFS
* @param dstPath 目的路径
* @throws IOException
* @throws URISyntaxException
*/
//2.接下来在 list 方法中,使用 globStatus 方法获取所有 txt 文件,然后通过 copyFromLocalFile 方法将文件上传至 HDFS。
public static void list(String srcPath,String dstPath) throws IOException, URISyntaxException {
//读取hadoop配置文件
Configuration conf = new Configuration();
//获取默认文件系统 在Hadoop 环境下运行,也可以使用此种方法获取文件系统
fs = FileSystem.get(conf);
//HDFS接口和获取文件系统对象,本地环境运行模式
//URI uri = new URI("hdfs://djt002:9000");
//fs = FileSystem.get(uri, conf);
//获得本地文件系统
local = FileSystem.getLocal(conf);
//只上传Data/testdata 目录下 txt 格式的文件 ,获得文件目录,即D://Data/testdata/
//FileStatus[] localStatus = local.globStatus(new Path("D://Data/testdata/*"),new RegexAcceptPathFilter("^.*txt$"));
FileStatus[] localStatus = local.globStatus(new Path("/home/hadoop/djt/data/*"),new RegexAcceptPathFilter("^.*txt$"));
// 获得所有文件路径
Path[] listedPaths = FileUtil.stat2Paths(localStatus);
Path out= new Path(dstPath);
//循坏所有文件
for(Path p:listedPaths)
{
//将本地文件上传到HDFS
fs.copyFromLocalFile(p, out);
}
}
/**
* @function 只接受 txt 格式的文件
* @author
*
*/
// 1.首先定义一个类 RegexAcceptPathFilter实现 PathFilter,过滤掉 txt 文本格式以外的文件。
public static class RegexAcceptPathFilter implements PathFilter
{
private final String regex;
public RegexAcceptPathFilter(String regex)
{
this.regex = regex;
}
// 如果要接收 regex 格式的文件,则accept()方法就return flag; 如果想要过滤掉regex格式的文件,则accept()方法就return !flag。
public boolean accept(Path path)
{
// TODO Auto-generated method stub
boolean flag = path.toString().matches(regex);
//只接受 regex 格式的文件
return flag;
}
}
}
package zhouls.bigdata.myHadoop;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.FileUtil;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.PathFilter;
import org.apache.hadoop.io.IOUtils;
/**
* function 合并小文件至 HDFS
* @author 小讲
*
*/
public class MergeSmallFilesToHDFS
{
private static FileSystem fs = null; //定义文件系统对象,是HDFS上的
private static FileSystem local = null; //定义文件系统对象,是本地上的
/**
* @function main
* @param args
* @throws IOException
* @throws URISyntaxException
*/
public static void main(String[] args) throws IOException,URISyntaxException
{
list();
}
/**
*
* @throws IOException
* @throws URISyntaxException
*/
public static void list() throws IOException, URISyntaxException
{
// 读取hadoop配置文件
Configuration conf = new Configuration();
// 文件系统访问接口和创建FileSystem对象,在本地上运行模式
URI uri = new URI("hdfs://HadoopMaster:9000");
fs = FileSystem.get(uri, conf);
// 获得本地文件系统
local = FileSystem.getLocal(conf);
// 过滤目录下的 svn 文件
FileStatus[] dirstatus = local.globStatus(new Path("D://Data/tvdata/*"),new RegexExcludePathFilter("^.*svn$"));
//获取D:\Data\tvdata目录下的所有文件路径
Path[] dirs = FileUtil.stat2Paths(dirstatus);
FSDataOutputStream out = null;
FSDataInputStream in = null;
for (Path dir : dirs)
{//比如拿2012-09-17为例
//将文件夹名称2012-09-17的-去掉,直接,得到20120901文件夹名称
String fileName = dir.getName().replace("-", "");//文件名称
//只接受20120917日期目录下的.txt文件
FileStatus[] localStatus = local.globStatus(new Path(dir+"/*"),new RegexAcceptPathFilter("^.*txt$"));
// 获得20120917日期目录下的所有文件
Path[] listedPaths = FileUtil.stat2Paths(localStatus);
// 输出路径
Path block = new Path("hdfs://HadoopMaster:9000/middle/tv/"+ fileName + ".txt");
System.out.println("合并后的文件名称:"+fileName+".txt");
// 打开输出流
out = fs.create(block);
//循环20120917日期目录下的所有文件
for (Path p : listedPaths)
{
in = local.open(p);// 打开输入流
IOUtils.copyBytes(in, out, 4096, false); // 复制数据
// 关闭输入流
in.close();
}
if (out != null)
{
// 关闭输出流
out.close();
}
//当循环完20120917日期目录下的所有文件之后,接着依次20120918,20120919,,,
}
}
/**
*
* @function 过滤 regex 格式的文件
*
*/
public static class RegexExcludePathFilter implements PathFilter
{
private final String regex;
public RegexExcludePathFilter(String regex)
{
this.regex = regex;
}
public boolean accept(Path path)
{
// TODO Auto-generated method stub
boolean flag = path.toString().matches(regex);
return !flag;
}
}
/**
*
* @function 接受 regex 格式的文件
*
*/
public static class RegexAcceptPathFilter implements PathFilter
{
private final String regex;
public RegexAcceptPathFilter(String regex)
{
this.regex = regex;
}
public boolean accept(Path path)
{
// TODO Auto-generated method stub
boolean flag = path.toString().matches(regex);
return flag;
}
}
}
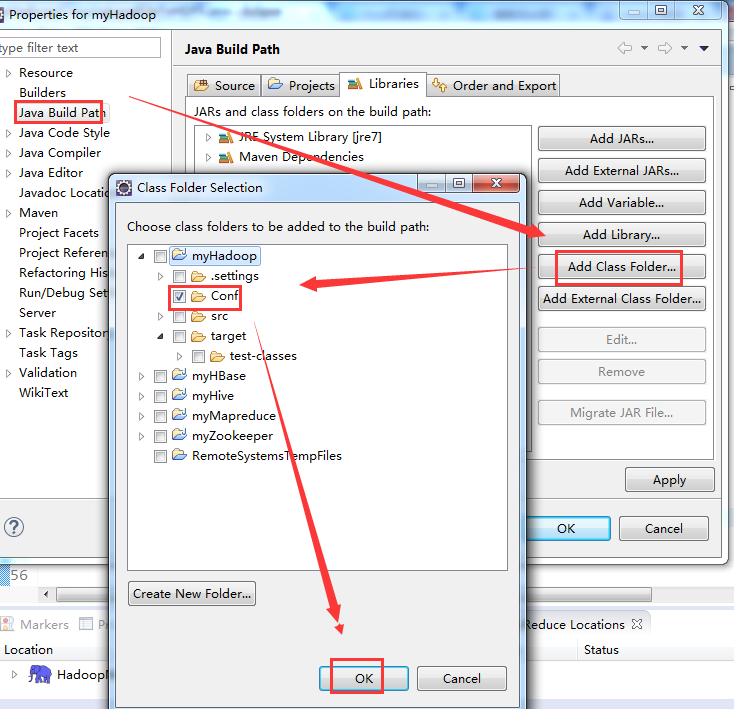
步骤八:作为补充,
参考: http://blog.itpub.net/26495863/viewspace-1328030/
从Hadoop集群环境下载hadoop配置文件
- core-site.xml
- hdfs-site.xml
- mapred-site.xml
myHadoop -> New -> Folder


具体下载,不多赘述了。
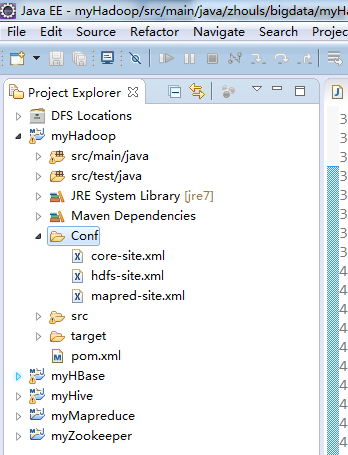
删除原自动生成的文件:App.java和AppTest.java
后面的深入学习,可以参考
http://blog.itpub.net/26495863/viewspace-1328030/
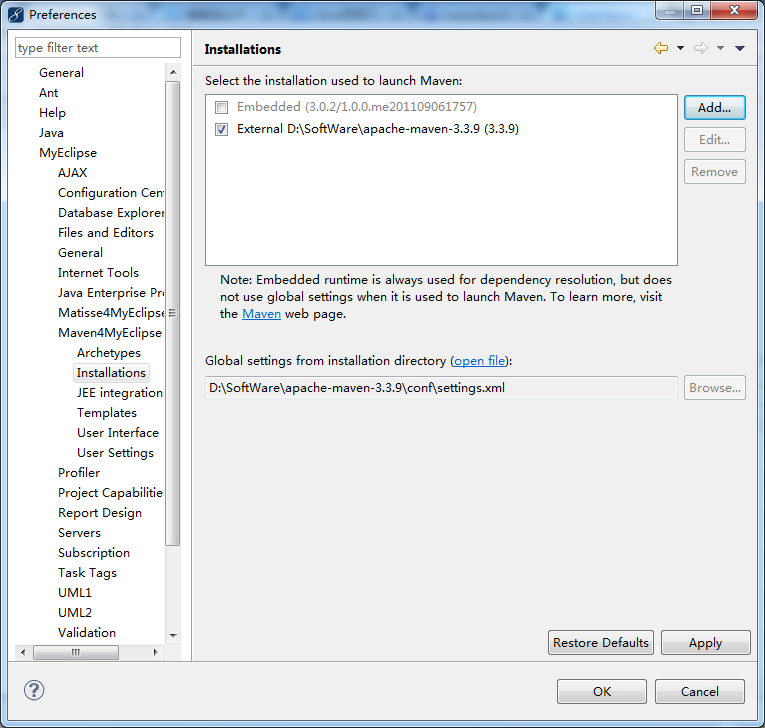
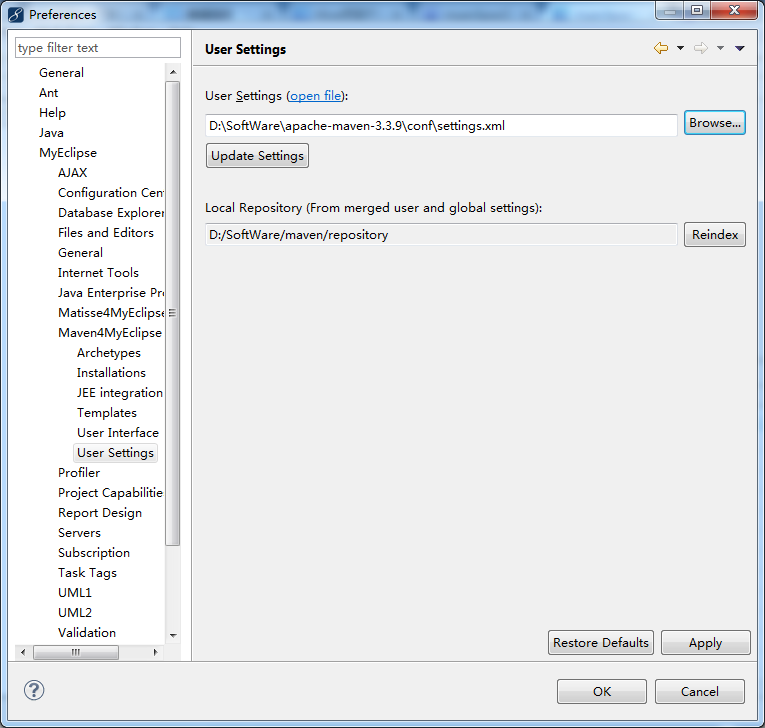
若是MyEclipse里,需要注意一下
MyEclipse *的安装步骤和破解(32位和64位皆适用)

Hadoop项目开发环境搭建(Eclipse\MyEclipse + Maven)的更多相关文章
- Hive项目开发环境搭建(Eclipse\MyEclipse + Maven)
写在前面的话 可详细参考,一定得去看 HBase 开发环境搭建(Eclipse\MyEclipse + Maven) Zookeeper项目开发环境搭建(Eclipse\MyEclipse + Mav ...
- Zookeeper项目开发环境搭建(Eclipse\MyEclipse + Maven)
写在前面的话 可详细参考,一定得去看 HBase 开发环境搭建(Eclipse\MyEclipse + Maven) 我这里,相信,能看此博客的朋友,想必是有一定基础的了.我前期写了大量的基础性博文. ...
- iOS项目——项目开发环境搭建
在开发项目之前,我们需要做一些准备工作,了解iOS扩展--Objective-C开发编程规范是进行开发的必备基础,学习iOS学习--Xcode9上传项目到GitHub是我们进行版本控制和代码管理的选择 ...
- 利用maven开发springMVC项目——开发环境搭建(版本错误解决)
申明:部分内容参见别人的博客,没有任何的商业用途,只是作为自己学习使用.(大佬博客) 一.相关环境 - eclipse :eclipse-jee-oxygen-3-win32-x86_64(下载地址) ...
- Java WEB开发环境搭建以及创建Maven Web项目
根据此链接博文学习配置: http://www.cnblogs.com/zyw-205520/p/4767633.html 1.JDK的安装 自行百度,(最好是jdk1.7版本的) 测试如下图,即完成 ...
- 【hadoop之翊】——windows 7使用eclipse下hadoop应用开发环境搭建
由于一些缘故,这节内容到如今才写.事实上弄hadoop有一段时间了,能够编写一些小程序了,今天来还是来说说环境的搭建.... 说明一下:这篇文章的步骤是接上一篇的hadoop文章的:http://bl ...
- Hadoop基本开发环境搭建(原创,已实践)
软件包: hadoop-2.7.2.tar.gz hadoop-eclipse-plugin-2.7.2.jar hadoop-common-2.7.1-bin.zip eclipse jdk1.8 ...
- 【原创干货】大数据Hadoop/Spark开发环境搭建
已经自学了好几个月的大数据了,第一个月里自己通过看书.看视频.网上查资料也把hadoop(1.x.2.x).spark单机.伪分布式.集群都部署了一遍,但经历短暂的兴奋后,还是觉得不得门而入. 只有深 ...
- android开发1:安卓开发环境搭建(eclipse+jdk+sdk)
计划折腾折腾安卓开发了,从0开始的确很痛苦,不过相信上手应该也不会太慢.哈哈 一.Android简介 Android 是基于Linux内核的软件平台和操作系统. Android构架主要由3部分组成,l ...
随机推荐
- 【BZOJ 1185】 凸包+旋转卡壳
Description [分析] 打计算几何真的可以哭出来... 跟那个求线段最远点差不多,这题弄三个东西转一转,一个表示左端最远点,一个表示右端最远点,一个表示上面最远点. 左右两边的最远点用点积判 ...
- BZOJ 3123 SDOI2013 森林
首先对于查询操作就是裸的COT QAQ 在树上DFS建出主席树就可以了 对于连接操作,我们发现并没有删除 所以我们可以进行启发式合并,每次将小的树拍扁插入大的树里并重构即可 写完了之后第一个和第二个点 ...
- PHP开发工具介绍之zendStudio
1.PHP开发工具介绍之zendStudio 下载:进入官网:http://www.zend.com/en/products/studio 选择下载安装 注意这里的工作空间要和你Apache的工作目录 ...
- C# Winform应用程序占用内存较大解决方法整理
微软的 .NET FRAMEWORK 现在可谓如火如荼了.但是,.NET 一直所为人诟病的就是“胃口太大”,狂吃内存,虽然微软声称 GC 的功能和智能化都很高,但是内存的回收问题,一直存在困扰,尤其 ...
- POJ1159——Palindrome(最长公共子序列+滚动数组)
Palindrome DescriptionA palindrome is a symmetrical string, that is, a string read identically from ...
- python的常用概念
常用的概念 主体字符串 主体列表 内置函数和方法的区别 映射表 引用 迭代器: 1. 字典:单步遍历迭代器 2. 文件:逐行读取的迭代器
- Ubuntu12.04 VMware Tools的安装
Ubuntu12.04VMware Tools的安装 备注:xp+VMware.Workstation.v8.0.3 1. VMware Tools的概述 VMware Tools是VMwa ...
- 函数flst_add_last
/********************************************************************//** Adds a node as the last no ...
- Java [Leetcode 226]Invert Binary Tree
题目描述: Invert a binary tree. 4 / \ 2 7 / \ / \ 1 3 6 9 to 4 / \ 7 2 / \ / \ 9 6 3 1 解题思路: 我只想说递归大法好. ...
- 【转】armeabi和armeabi-v7a
原文网址:http://blog.csdn.net/dxpqxb/article/details/7721156 在我们android APK的根目录有一个 libs文件夹,此文件夹下包含了armea ...