SQL Server 2008新特性——更改跟踪
在大型的数据库应用中,经常会遇到部分数据的脱机和多个数据库的合并问题。比如现在有一个全省范围使用的应用程序,每个市都部署了单独的相同的应用程序服务器和数据库服务器,每个月需要将全省所有市的数据全部汇总起来用于出全省的报表,这是一种很常见的数据库合并问题。再比如我们做了一个SmartClient的应用程序,每个客户端都有应用程序和数据库,另外还有一个中心数据库用于汇总所有客户端的数据。每个智能客户端上都可以对自己的数据库进行增删改查,一旦智能客户端连接到网络上时,系统就将客户端数据库中的数据更改全部应用到中心数据库中,这种偶尔连接的应用程序也是需要数据库的同步的。
对于前面说到的这些应用,最简单的同步方法就是删除原有数据,然后重新填充新的数据,对于小数据量的表来说这并没有什么问题,但是如果每个市都有几百万几千万条数据,那么要将省数据库中的数据删除了再把每个市中的数据全部填充到省数据库中显然是不可行的。这种情况下应该使用跟踪数据更改的方法,将每个市这个月的数据更改应用到省数据库中(感觉有点像是差异备份一样,只记录更改的)。在SQL Server 2008中提供了两种跟踪数据更改的方案:
- 变更数据捕获(Change Data Capture)
- 更改跟踪(Chang Tracking)
今天我主要说的是更改跟踪,变更数据捕获在以后进行讲解。
启用更改跟踪
更改跟踪是SQL Server 2008的一个新特性,默认情况下是没启用的。更改跟踪可以应用跟踪到具体一个数据库中的具体表甚至是具体的列。更改跟踪并不会创建触发器之类的对象,只是在用户对启用了更改跟踪的表进行了增加、修改和删除操作时,系统自动将该操作生成一个版本号,记录下操作的时间戳、操作的类型、受影响的数据的主键等信息。启用更改跟踪后对数据操作的性能影响不是很大。这些信息是记录到SQL Server系统表中的,系统自动负责清理和维护。
要使用更改跟踪需要启用数据库的更改跟踪功能和表的更改跟踪功能。在SSMS中数据库的属性窗口中可以启用数据库的更改跟踪:
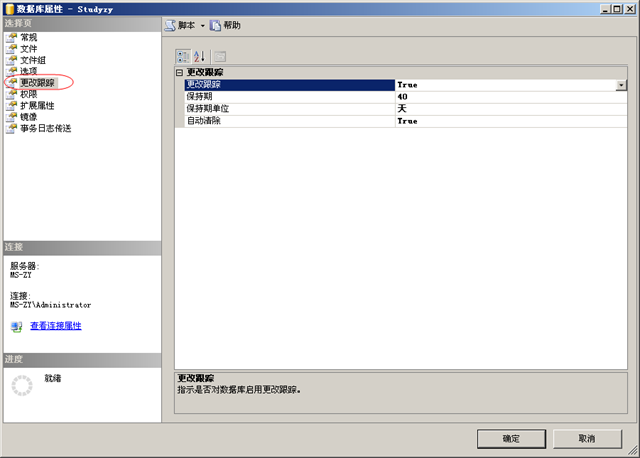
这里将更改跟踪选项设置为true既可启用更改跟踪。另外3个选项就是跟踪的数据自动清理的开关和清理的时间,这个自动清理的时间必须大于我们要同步数据的周期,比如我们的数据是一个月同步一次,那么这个保持期就应该大于31天,如果设置保持期太短,那么我们的跟踪数据还没来得及同步就被自动清理了。
这里只是启用了数据库的更改跟踪,接下来是要启用表的更改跟踪。这里我们创建一个新的表t1并初始化几条数据:
CREATE TABLE t1
(
c1 INT IDENTITY PRIMARY KEY,
c2 VARCHAR(50) NOT NULL,
c3 DATETIME NOT NULL,
c4 VARCHAR(max)
)
GO
INSERT INTO t1 VALUES ( 'test1','2009-1-1','www.cnblogs.com/studyzy' )
INSERT INTO t1 VALUES ( 'test2','2009-1-1','www.cnblogs.com/studyzy' )
INSERT INTO t1 VALUES ( 'test3','2009-1-2','www.cnblogs.com/studyzy' )
接下来在SSMS中查看表t1的属性窗口,可以在属性窗口中启用该表的更改跟踪功能:
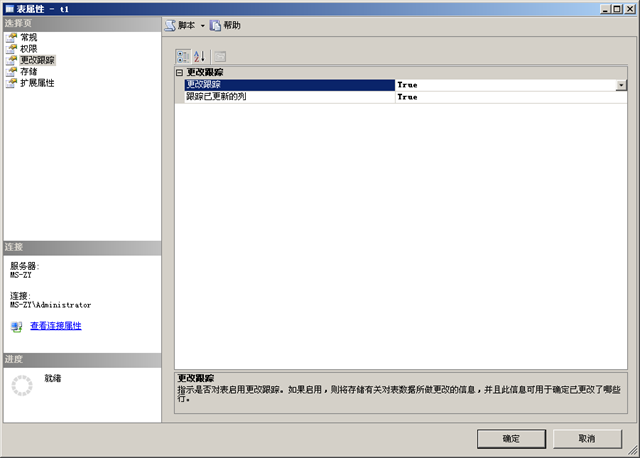
其中第二个选项“跟踪已更新的列”是表示是否将更改跟踪细化到列上。对于一般的表来说,我们只需要知道具体哪些行进行了更改,然后在合并数据时将整行数据更新到中心数据库既可,但是如果表中有大对象列(text image varchar(max) varbinary(max) xml等数据类型的列)时,将整行进行更新可能非常慢,所以我们可以启用“跟踪已更新的列”将具体更新了哪些列记录下来,这样在合并数据时就直接更新这些列既可。
更改跟踪常用函数
在更改跟踪中最重要的一点就是版本号,版本号从0开始一直递增,对表的每一次更改操作都会产生一个新的版本号。使用
SELECT CHANGE_TRACKING_MIN_VALID_VERSION( OBJECT_ID('dbo.t1'))
可以获得t1表最小版本号,由于是刚创建更改跟踪,所以这里返回的是0,如果我们进行了大量的操作以后,而且这些操作的时间已经超过了数据库更改跟踪中设置的保持期时间,那么过期的版本就会被系统自动清理,清理后最小版本就不是0了,而是保留的可用的最早版本。
SELECT CHANGE_TRACKING_CURRENT_VERSION()可以获得当前数据库的更改跟踪的最新版本。这里由于我们启用更改跟踪后还没有进行数据库操作,所以返回的也是0。
现在我们向表t1中插入一条数据,然后查看当前最新版本:
INSERT INTO t1 VALUES ( 'test','2009-1-4','www.cnblogs.com/studyzy' )
SELECT CHANGE_TRACKING_CURRENT_VERSION() --返回1
现在返回的版本号就是1了。
接下来我们再修改2条数据和删除1条数据,再查看版本号:
UPDATE t1 SET c3=GETDATE() WHERE c1<3 --受影响2条数据
DELETE FROM t1 WHERE c2='test3' --受影响1条数据
SELECT CHANGE_TRACKING_CURRENT_VERSION() --返回3
这里我们总共影响了4条数据,但是版本号为3说明版本号并不是以受影响的行实来定的,一次更新操作中不管影响了好多条数据(当然这里不能为0条)版本号只增加1。
现在版本号有了,接下来就是查询出这段时间t1的更改情况,需要使用表值函数:CHANGETABLE(CHANGES [要查询更改跟踪的表名], 从哪个版本开始的更改)。这里要查询t1表从0版本开始到现在的所有数据更改,那么对应的查询语句是:
SELECT *
FROM CHANGETABLE(CHANGES dbo.t1,0) as ct
系统返回结果:
| SYS_CHANGE_VERSION | SYS_CHANGE_CREATION_VERSION | SYS_CHANGE_OPERATION | SYS_CHANGE_COLUMNS | SYS_CHANGE_CONTEXT | c1 |
| 2 | NULL | U | 0x0000000003000000 | NULL | 1 |
| 2 | NULL | U | 0x0000000003000000 | NULL | 2 |
| 3 | NULL | D | NULL | NULL | 3 |
| 1 | 1 | I | NULL | NULL | 4 |
这里每个列的数据类型、含义等在联机丛书里面解释的很清楚,我这里只简单介绍下返回的这个表:
在版本号为1的数据更改操作中是插入了一条数据,插入数据的主键c1=4;在版本号2的操作中更新了2条数据,分别是c1=1和c1=2的行;在版本3的操作中删除了c1=3的一条数据。
根据更改跟踪同步数据
现在所有的更改已经查询出来了,接下来就可以根据查询出来的这个结果同步数据了。为了演示方便,我这里将在同一个实例中建立TestDB1数据库并初始化t1表用于表示中心数据库。那么同步数据的操作应该是:
--首先将新增的数据插入到中心数据库中:
SET IDENTITY_INSERT TestDB1.dbo.t1 ON
INSERT INTO TestDB1.dbo.t1(c1,c2,c3,c4)
SELECT t1.*
FROM CHANGETABLE(CHANGES dbo.t1,0) AS ct
INNER JOIN t1
ON ct.c1=t1.c1
WHERE ct.SYS_CHANGE_OPERATION='I' --接下来将更改的数据应用到中心数据库中:
UPDATE TestDB1.dbo.t1
SET c2=newt1.c2,c3=newt1.c3,c4=newt1.c4
FROM CHANGETABLE(CHANGES dbo.t1,0) AS ct
INNER JOIN dbo.t1 AS newt1
ON ct.c1=newt1.c1
WHERE ct.SYS_CHANGE_OPERATION='U' AND t1.c1=newt1.c1 --将删除的数据从中心数据库删除:
DELETE FROM TestDB1.dbo.t1
WHERE c1 IN (
SELECT c1
FROM CHANGETABLE(CHANGES dbo.t1,0) AS ct
WHERE ct.SYS_CHANGE_OPERATION='D')
这样我们就使用更改跟踪实现了数据库的同步。该同步操作时的版本号是3,这个版本号必须要单独记下来,那么下次再进行同步是就从3开始查询。
通过更改跟踪更新列
前面的同步脚本中关于数据update操作是:
UPDATE TestDB1.dbo.t1
SET c2=newt1.c2,c3=newt1.c3,c4=newt1.c4
由于c4是大对象数据类型,如果里面存放了几十兆或者更大的数据,而实际上我们更新的并不是c4列,那么这种更新方式必然很浪费时间和资源。前面我们对t1表已经启用了“跟踪已更新的列”,那么就可以根据实际更新的列来更新数据。
使用CHANGE_TRACKING_IS_COLUMN_IN_MASK()函数可以判断一个列是否发生了更改,如果发生了更改则返回1,没有更改则返回0。比如查询c2是否发生更改:
SELECT * ,CHANGE_TRACKING_IS_COLUMN_IN_MASK ( COLUMNPROPERTY( OBJECT_ID('dbo.t1'),'c2','ColumnId') , SYS_CHANGE_COLUMNS )
FROM CHANGETABLE(CHANGES dbo.t1,0) AS ct
WHERE ct.SYS_CHANGE_OPERATION='U'
这里返回0说明没有更改c2列,同样的方法可以判断出c3列发生了更改。
既然可以判断哪些列发生了更改,那么就可以根据发生更改的列来更新该列的数据,比如对于c2的更新语句就是:
UPDATE TestDB1.dbo.t1
SET c2=newt1.c2 --更新c2列
FROM CHANGETABLE(CHANGES dbo.t1,0) AS ct
INNER JOIN dbo.t1 AS newt1
ON ct.c1=newt1.c1
WHERE ct.SYS_CHANGE_OPERATION='U' AND t1.c1=newt1.c1
AND CHANGE_TRACKING_IS_COLUMN_IN_MASK(COLUMNPROPERTY(OBJECT_ID('dbo.t1'),'c2','ColumnId') , ct.SYS_CHANGE_COLUMNS )=1 --发生更改时才更新
同样的方法可以写出c3列、c4列的更新语句。如果觉得这样重复的写很麻烦,那么可以写一个存储过程,传入列名,检查该列是否更改,如果更改了则更新。
总结
更改跟踪是在偶尔连接的数据库应用和同步数据时非常有用的一个特性。更改跟踪里面的核心就是版本号,每次在同步数据时记录下当前的版本号,下次再同步时CHANGETABLE函数就传入上次同步的版本号,这样可以避免重复同步。
更改跟踪的跟踪记录数据是保存到系统表中的,由系统来维护,在开启数据库的更改跟踪时可以设置自动清除的时间,从而保证系统不会因为记录太多的跟踪数据而导致数据库文件大小急剧膨胀。
更改跟踪启用后对一般的DML操作(增删改)是不会有影响的,所有的DML SQL语句照常使用,而且启用更改跟踪后并不会对系统性能造成明细影响。
SQL Server 2008新特性——更改跟踪的更多相关文章
- SQL Server 2008新特性——策略管理
策略管理是SQL Server 2008中的一个新特性,用于管理数据库实例.数据库以及数据库对象的各种属性.策略管理在SSMS的对象资源管理器数据库实例下的“管理”节点下,如图: 从图中可以看到,策略 ...
- 小心SQL SERVER 2014新特性——基数评估引起一些性能问题
在前阵子写的一篇博文"SQL SERVER 2014 下IF EXITS 居然引起执行计划变更的案例分享"里介绍了数据库从SQL SERVER 2005升级到 SQL SERVER ...
- SQL Server 2014新特性——Buffer Pool扩展
Buffer Pool扩展 Buffer Pool扩展是buffer pool 和非易失的SSD硬盘做连接.以SSD硬盘的特点来提高随机读性能. 缓冲池扩展优点 SQL Server读以随机读为主,S ...
- SQL Server 2014 新特性——内存数据库
SQL Server 2014 新特性——内存数据库 目录 SQL Server 2014 新特性——内存数据库 简介: 设计目的和原因: 专业名词 In-Memory OLTP不同之处 内存优化表 ...
- 谈谈我的微软特约稿:《SQL Server 2014 新特性:IO资源调控》
一.本文所涉及的内容(Contents) 本文所涉及的内容(Contents) 背景(Contexts) 撰写经历(Experience) 特约稿正文(Content-body) 第一部分:生活中资源 ...
- SQL Server ->> 深入探讨SQL Server 2016新特性之 --- Temporal Table(历史表)
原文:SQL Server ->> 深入探讨SQL Server 2016新特性之 --- Temporal Table(历史表) 作为SQL Server 2016(CTP3.x)的另一 ...
- SQL Server 2014 新特性:IO资源调控
谈谈我的微软特约稿:<SQL Server 2014 新特性:IO资源调控> 2014-07-01 10:19 by 听风吹雨, 570 阅读, 16 评论, 收藏, 收藏 一.本文所涉及 ...
- SQL Server 2014新特性:五个关键点带你了解Excel下的Data Explorer
SQL Server 2014新特性:五个关键点带你了解Excel下的Data Explorer Data Explorer是即将发布的SQL Server 2014里的一个新特性,借助这个特性讲使企 ...
- SQL Server 2016新特性:列存储索引新特性
SQL Server 2016新特性:列存储索引新特性 行存储表可以有一个可更新的列存储索引,之前非聚集的列存储索引是只读的. 非聚集的列存储索引支持筛选条件. 在内存优化表中可以有一个列存储索引,可 ...
随机推荐
- CentOS_6.5_x64:VNC安装配置
1.安装软件前首先检查下系统是否已经安装了这个软件:rpm -qa tigervnc-server 2.根据前面命令的查询,显示系统还是没有安装VNC服务器端软件,那么我们就使用命令进行安装一下:yu ...
- 为通过ClickOnce部署的应用程序进行数字签名
为通过ClickOnce部署的应用程序进行数字签名 ClickOnce是.NET用于Windows应用程序的一种便捷部署方式.不过由于便捷,导致缺少自定义操作的空间.比如需要对通过ClickOnce部 ...
- Python学习入门基础教程(learning Python)--6.3 Python的list切片高级
上节"6.2 Python的list访问索引和切片"主要学习了Python下的List的访问技术:索引和切片的基础知识,这节将就List的索引index和切片Slice知识点做进一 ...
- php处理金额显示的一些笔记
最近一直在做关于结算方面的需求,也熟悉了一些处理金额显示的方法,总结如下: 1.每三位数字以逗号分隔,比如1000 => 1,000. 可以直接使用number_format函数.eg:echo ...
- ASP.NET MVC with Entity Framework and CSS一书翻译系列文章之第四章:更高级的数据管理
在这一章我们将学习如何正确地删除分类信息,如何向数据库填充种子数据,如何使用Code First Migrations基于代码更改来更新数据库,然后学习如何执行带有自定义错误消息的验证. 注意:如果你 ...
- oracle表空间表分区详解及oracle表分区查询使用方法(转+整理)
欢迎和大家交流技术相关问题: 邮箱: jiangxinnju@163.com 博客园地址: http://www.cnblogs.com/jiangxinnju GitHub地址: https://g ...
- CentOS下使用NVM
查看CentOS版本 # rpm -q centos-release centos-release-6-8.el6.centos.12.3.x86_64 安装epel源 32位系统选择: rpm -i ...
- JAVA基础之内部类
JAVA基础之内部类 2017-01-13 1.java中的内部类都有什么?! 成员内部类 局部内部类 匿名内部类 静态内部类 2.内部类详解 •成员内部类 在一个类的内部再创建一个类,成为内部类 1 ...
- python绝技 — 使用PyGeoIP关联IP地址和物理位置
准备工作 要关联IP与物理位置,我们需要有一个包含这样对应关系的数据库. 我们可以使用开源数据库GeoLiteCity,它能够较为准确地把IP地址与所在城市关联起来 下载地址:http://dev.m ...
- OpenCV备忘
都是转来的内容的,算是整理一下 OpenCV备忘 深度和通道的理解 CV_8UC1 是指一个8位无符号整型单通道矩阵, CV_32FC2是指一个32位浮点型双通道矩阵 CV_8UC1 CV_8SC1 ...