mysql Group By
1、概述
“Group By”从字面意义上理解就是根据“By”指定的规则对数据进行分组,所谓的分组就是将一个“数据集”划分成若干个“小区域”,然后针对若干个“小区域”进行数据处理。
2、原始表
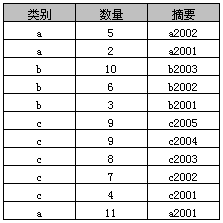
3、简单Group By
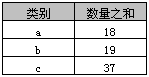
示例1
select 类别, sum(数量) as 数量之和
from A
group by 类别
返回结果如下表,实际上就是分类汇总。
4、Group By 和 Order By
示例2
select 类别, sum(数量) AS 数量之和
from A
group by 类别
order by sum(数量) desc
返回结果如下表
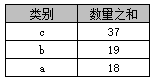
在Access中不可以使用“order by 数量之和 desc”,但在SQL Server中则可以。
5、Group By中Select指定的字段限制
示例3
select 类别, sum(数量) as 数量之和, 摘要
from A
group by 类别
order by 类别 desc
示例3执行后会提示下错误,如下图。这就是需要注意的一点,在select指定的字段要么就要包含在Group By语句的后面,作为分组的依据;要么就要被包含在聚合函数中。

6、Group By All
示例4
select 类别, 摘要, sum(数量) as 数量之和
from A
group by all 类别, 摘要
示例4中则可以指定“摘要”字段,其原因在于“多列分组”中包含了“摘要字段”,其执行结果如下表
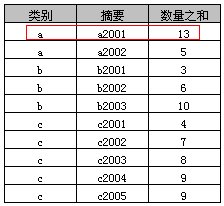
“多列分组”实际上就是就是按照多列(类别+摘要)合并后的值进行分组,示例4中可以看到“a, a2001, 13”为“a, a2001, 11”和“a, a2001, 2”两条记录的合并。
SQL Server中虽然支持“group by all”,但Microsoft SQL Server 的未来版本中将删除 GROUP BY ALL,避免在新的开发工作中使用 GROUP BY ALL。Access中是不支持“Group By All”的,但Access中同样支持多列分组,上述SQL Server中的SQL在Access可以写成
select 类别, 摘要, sum(数量) AS 数量之和
from A
group by 类别, 摘要
7、Group By与聚合函数
在示例3中提到group by语句中select指定的字段必须是“分组依据字段”,其他字段若想出现在select中则必须包含在聚合函数中,常见的聚合函数如下表:
| 函数 | 作用 | 支持性 |
|---|---|---|
| sum(列名) | 求和 | |
| max(列名) | 最大值 | |
| min(列名) | 最小值 | |
| avg(列名) | 平均值 | |
| first(列名) | 第一条记录 | 仅Access支持 |
| last(列名) | 最后一条记录 | 仅Access支持 |
| count(列名) | 统计记录数 | 注意和count(*)的区别 |
示例5:求各组平均值
select 类别, avg(数量) AS 平均值 from A group by 类别;
示例6:求各组记录数目
select 类别, count(*) AS 记录数 from A group by 类别;
示例7:求各组记录数目
8、Having与Where的区别
- where 子句的作用是在对查询结果进行分组前,将不符合where条件的行去掉,即在分组之前过滤数据,where条件中不能包含聚组函数,使用where条件过滤出特定的行。
- having 子句的作用是筛选满足条件的组,即在分组之后过滤数据,条件中经常包含聚组函数,使用having 条件过滤出特定的组,也可以使用多个分组标准进行分组。
示例8
select 类别, sum(数量) as 数量之和 from A
group by 类别
having sum(数量) > 18
示例9:Having和Where的联合使用方法
select 类别, SUM(数量)from A
where 数量 gt;8
group by 类别
having SUM(数量) gt; 10
9、Compute 和 Compute By
select * from A where 数量 > 8
执行结果:

示例10:Compute
select *
from A
where 数量>8
compute max(数量),min(数量),avg(数量)
执行结果如下:

compute子句能够观察“查询结果”的数据细节或统计各列数据(如例10中max、min和avg),返回结果由select列表和compute统计结果组成。
示例11:Compute By
select *
from A
where 数量>8
order by 类别
compute max(数量),min(数量),avg(数量) by 类别
执行结果如下:
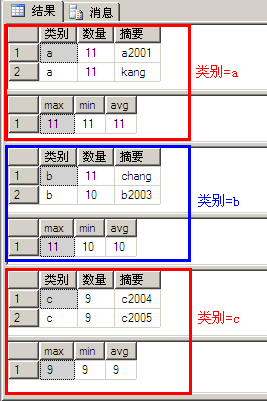
示例11与示例10相比多了“order by 类别”和“... by 类别”,示例10的执行结果实际是按照分组(a、b、c)进行了显示,每组都是由改组数据列表和改组数统计结果组成,另外:
- compute子句必须与order by子句用一起使用
- compute...by与group by相比,group by 只能得到各组数据的统计结果,而不能看到各组数据
在实际开发中compute与compute by的作用并不是很大,SQL Server支持compute和compute by,而Access并不支持
mysql Group By的更多相关文章
- MySQL Group Replication 技术点
mysql group replication,组复制,提供了多写(multi-master update)的特性,增强了原有的mysql的高可用架构.mysql group replication基 ...
- mysql group by 用法解析(详细)
在使用mysql时,有时需要查询出某个字段不重复的记录,虽然mysql提供 有distinct这个关键字来过滤掉多余的重复记录只保留一条,但往往只用它来返回不重复记录的条数,而不是用它来返回不重记录的 ...
- (转载)mysql group by 用法解析(详细)
(转载)http://blog.tianya.cn/blogger/post_read.asp?BlogID=4221189&PostID=47881614 mysql distinct 去重 ...
- 细细探究MySQL Group Replicaiton — 配置维护故障处理全集
本文主要描述 MySQL Group Replication的简易原理.搭建过程以及故障维护管理内容.由于是新技术,未在生产环境使用过,本文均是虚拟机测试,可能存在考虑不周跟思路有误 ...
- MySQL Group Replication 动态添加成员节点
前提: MySQL GR 3节点(node1.node2.node3)部署成功,模式定为多主模式,单主模式也是一样的处理. 在线修改已有GR节点配置 分别登陆node1.node2.node3,执行以 ...
- MySQL Group Replication-MGR集群
简介 MySQL Group Replication(简称MGR)字面意思是mysql组复制的意思,但其实他是一个高可用的集群架构,暂时只支持mysql5.7和mysql8.0版本. 是MySQL官方 ...
- mysql group by组内排序
mysql group by组内排序: 首先是组外排序: SELECT z.create_time,z.invoice_id from qf_invoice_log z where z ...
- Docker Images for MySQL Group Replication 5.7.14
In this post, I will point you to Docker images for MySQL Group Replication testing. There is a new ...
- Percona XtraDB Cluster vs Galera Cluster vs MySQL Group Replication
Percona XtraDB Cluster vs Galera Cluster vs MySQL Group Replication Overview Galera Cluster 由 Coders ...
- Mysql 5.7 基于组复制(MySQL Group Replication) - 运维小结
之前介绍了Mysq主从同步的异步复制(默认模式).半同步复制.基于GTID复制.基于组提交和并行复制 (解决同步延迟),下面简单说下Mysql基于组复制(MySQL Group Replication ...
随机推荐
- org.apache.commons.lang3.StringUtils类中isBlank和isEmpty方法的区别
相信很多java程序员在写代码的时候遇到判断某字符串是否为空的时候会用到StringUtils类中isBlank和isEmpty方法,这两个方法到底有什么区别呢?我们用一段代码来阐述这个区别吧: @T ...
- java反射机制(1)
反射,当时经常听他们说,自己也看过一些资料,也可能在设计模式中使用过,但是感觉对它没有一个较深入的了解,这次重新学习了一下,感觉还行吧! 一,先看一下反射的概念: 主要是指程序可以访问,检测和修改它本 ...
- log4j.properties文件的配置
Log4j有三个主要的组件:Loggers(记录器),Appenders (输出源)和Layouts(布局).这里可简单理解为日志类别,日志要输出的地方和日志以何种形式输出.综合使用这三个组件可以轻松 ...
- varnish屏蔽control+F5导致缓存失效
刚刚接触Varnish缓存,对静态资源进行缓存.目前问题,当浏览器Control+F5刷新页面,导致缓存失效. 参照:http://zhangxugg-163-com.iteye.com/blog/1 ...
- How can I create an Asynchronous function in Javascript?
哈哈:)我的codepen 的代码笔记是:http://codepen.io/shinewaker/pen/eBwPxJ --------------------------------------- ...
- python&MongoDB
1 #!/usr/bin/python 2 #-*- coding:utf-8 3 import pymongo 4 connection=pymongo.MongoClient() 5 tdb=co ...
- sql 将表B中不存在表A的数据 插入到表A中
insert into tableA select * from tableB b where not exists(select 1 from tableA a where a.id = b.id) ...
- 快速破解ps方法
1.首先现在ps安装包和破解包. 2.运行Block Adobe Activation,防止ADOBE激活程序启动,按操作提示即可. 3.运行Adobe CS6安装程序. 4.选择“试用”. 5.输入 ...
- over 分析函数之 lag() lead()
/*语法*/ lag(exp_str,offset,defval) over() 取前 Lead(exp_str,offset,defval) over() 取后 --exp_str要取的列 -- ...
- 第四十一节,xml处理模块
XML是实现不同语言或程序之间进行数据交换的协议,XML文件格式如下 读xml文件 <data> <country name="Liechtenstein"> ...