机器学习与Tensorflow(4)——卷积神经网络与tensorflow实现
1.标准卷积神经网络
标准的卷积神经网络由输入层、卷积层(convolutional layer)、下采样层(downsampling layer)、全连接层(fully—connected layer)和输出层构成。
- 卷积层也称为检测层
- 下采样层也称为池化层(pooling layer)
2.卷积神经网络的优势:
第一个特点和优势就是:局部感知
- 在传统神经网络中每个神经元都要与图片上每个像素相连接,
- 这样的话就会造成权重的数量巨大造成网络难以训练。
- 而在含有卷积层的神经网络中每个神经元的权重个数都时卷积核的大小,
- 这样就相当于神经元只与对应图片部分的像素相连接。
- 这样就极大的减少了权重的数量。同时我们可以设置卷积操作的步长,
- 但是步长的设置并无定值需要使用者自己尝试
第二个特点和优势就是:参数共享
- 卷积核的权重是经过学习得到的,并且在卷积过程中卷积核的权重是不会改变的,这就是参数共享的思想。
- 通过一个卷积核的操作提取了原图的不同位置的同样特征。
- 简单来说就是在一幅图片中的不同位置的相同目标,它们的特征是基本相同的
第三个特点和优势就是:多卷积核
- 我们用一个卷积核操作只能得到一部分特征可能获取不到全部特征,
- 所以为了能够得到图像更多的特征信息我们引入了多核卷积。
- 用多个卷积核来学习图像更多的不同的特征(每个卷积核学习到不同的权重)。
- 主要注意的是在多核卷积的过程中每一层的多个卷积核的大小应该是相同的。
3.关于卷积
先了解卷积运算:内卷积和外卷积(具体如下图)
内卷积:

外卷积:

卷积层的作用:
- 卷积层的每一个卷积滤波器作用于整个感受野中,对输入图像进行卷积,
- 卷积的结果构成了输入图像的特征图,从而经过卷积层后就提取出了图像的局部特征。
- 所以卷积层的主要作用就是可以利用不同的卷积核(也叫滤波器)来提取图像不同的特征。
- 它是识别图像最核心的部分。
4.关于池化
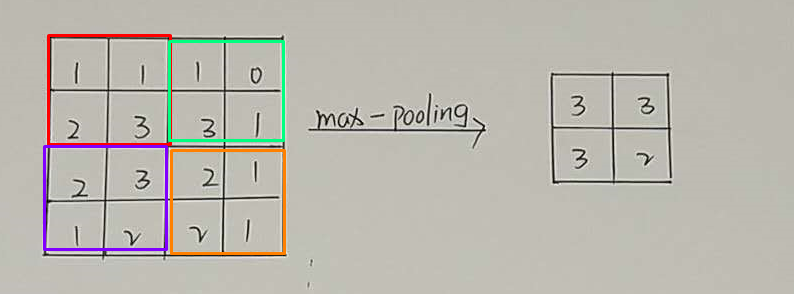
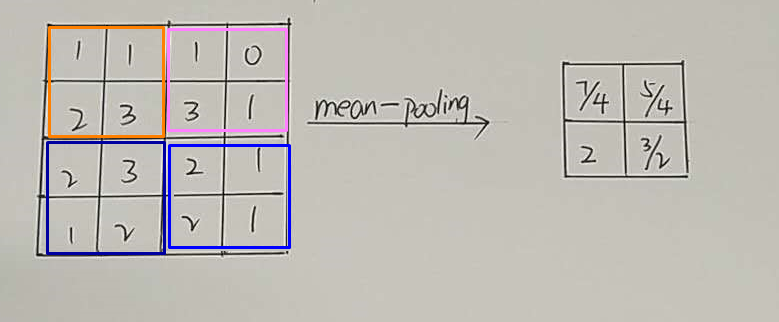
池化方式:(最大池化、平均池化)
- 池化层的具体操作与卷基层的操作基本相同,只不过池化层的卷积核为只取对应位置的最大值或平均值(最大池化、平均池化),
- 并且不会随着反向传播发生变化。一般池化层的filter取2*2,最大取3*3,stride取2,特征信息压缩为原来的1/4。
最大池化方式(每个小块中的最大值):
平均池化方式(每个小块中的平均值):
池化层的作用:
- 池化层可对提取到的特征信息进行降维,
- 一方面使特征图变小,简化网络计算复杂度并在一定程度上避免过拟合的出现;一方面进行特征压缩,提取主要特征。
- 最大池采样在计算机视觉中的价值体现在两个方面:(1)、它减小了来自上层隐藏层的计算复杂度;(2)、这些池化单元具有平移不变性,即使图像有小的位移,提取到的特征依然会保持不变。由于增强了对位移的鲁棒性,这样可以忽略目标的倾斜、旋转之类的相对位置的变化,以此提高精度,最大池采样方法是一个高效的降低数据维度的采样方法。
- 需要注意的是:这里的pooling操作是特征图缩小,有可能影响网络的准确度。
5.Tensorflow实现
- def conv2d(input, filter, strides, padding, use_cudnn_on_gpu=None,data_format=None, name=None)
除去name参数用以指定该操作的name,与方法有关的一共五个参数:
第一个参数input:
- 指需要做卷积的输入图像,它要求是一个Tensor,具有[batch, in_height, in_width, in_channels]这样的shape,
- 具体含义是[训练时一个batch的图片数量, 图片高度, 图片宽度, 图像通道数],
- 注意这是一个4维的Tensor,要求类型为float32和float64其中之一
第二个参数filter:
- 相当于CNN中的卷积核,它要求是一个Tensor,具有[filter_height, filter_width, in_channels, out_channels]这样的shape,
- 具体含义是[卷积核的高度,卷积核的宽度,图像通道数,卷积核个数],
- 要求类型与参数input相同,
- 有一个地方需要注意,第三维in_channels,就是参数input的第四维
第三个参数strides:
- 卷积时在图像每一维的步长,这是一个一维的向量,长度4
- strides[0] = strides[3] = 1
- strides[1]代表x方向的步长,strides[2]代表y方向的步长
第四个参数padding:
- string类型的量,只能是"SAME","VALID"其中之一,这个值决定了不同的卷积方式
- 对于卷积操作:
- SAME PADDING代表给平面外部补0,卷积窗口采样后得到一个跟原来平面大小相同的平面
- VALID PADDING代表不会超出平面外部,卷积窗口采样后得到比原来平面小的平面。
- 对于池化操作:
- SAME PADDING代表可能会给平面外部补0
- VALID PADDING代表不会超出平面外部
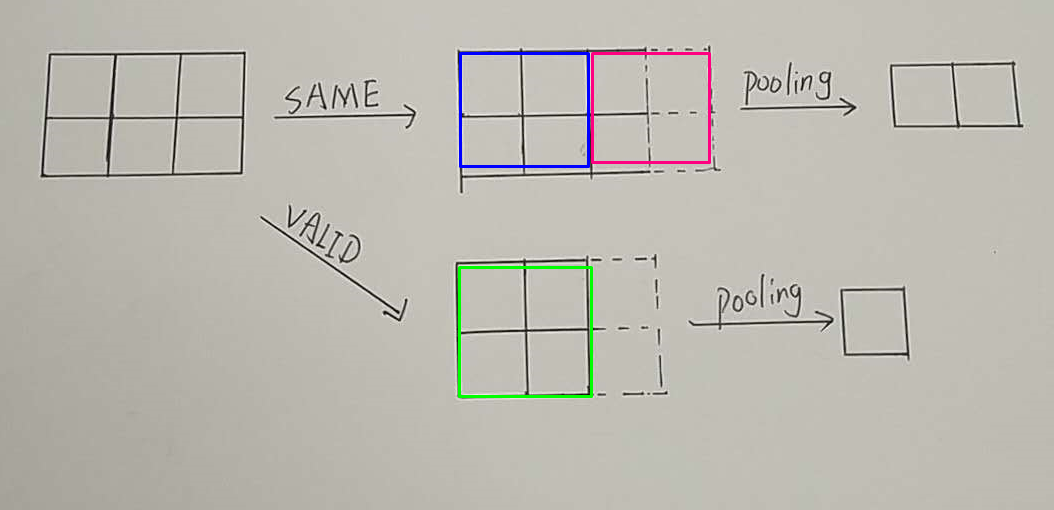
举例理解:
假如有一个28*28的平面,用2*2并且步长为2的窗口对其进行pooling操作
使用SAME PADDING的方式,得到14*14的平面
使用VALID PADDING的方式,得到14*14的平面
假如有一个2*3的平面,用2*2并且步长为2的窗口对其进行pooling操作
使用SAME PADDING的方式,得到1*2的平面
使用VALID PADDING的方式,得到1*1的平面
第五个参数:use_cudnn_on_gpu:bool类型,是否使用cudnn加速,默认为true
结果返回一个Tensor,这个输出,就是我们常说的feature map
6.卷积神经网络对MNIST手写数据集识别优化
实现代码:
- import os
- os.environ['TF_CPP_MIN_LOG_LEVEL'] = ''
- import tensorflow as tf
- from tensorflow.examples.tutorials.mnist import input_data
- #载入数据集
- mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
- #每个批次的大小
- batch_size = 100
- #计算一个有多少个批次
- n_batch = mnist.train.num_examples // batch_size
- #初始化权值
- def weight_variable(shape):
- initial = tf.truncated_normal(shape, stddev=0.1)#生成一个截断的正态分布
- return tf.Variable(initial)
- #初始化偏置
- def bias_variable(shape):
- initial = tf.constant(0.1, shape=shape)
- return tf.Variable(initial)
- #卷积层
- def conv2d(x,W):
- # x input tensor of shape `[batch, in_height, in_width, in_channels]`
- # W filter / kernel tensor of shape [filter_height, filter_width, in_channels, out_channels]
- # `strides[0] = strides[3] = 1`. strides[1]代表x方向的步长,strides[2]代表y方向的步长
- # padding: A `string` from: `"SAME", "VALID"`
- return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
- #池化层
- def max_pool_2x2(x):
- # ksize [1,x,y,1]
- return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
- #定义两个placeholder
- x = tf.placeholder(tf.float32, [None, 784]) #28*28
- y = tf.placeholder(tf.float32, [None,10])
- #改变x的格式转为4D的向量[batch,in_height,in_width,in_channels]
- x_image = tf.reshape(x, [-1, 28, 28, 1])
- #初始化第一个卷积层的权值和偏置
- W_conv1 = weight_variable([5, 5, 1, 32]) #5*5的采样窗口,32个卷积核从1个平面抽取特征
- b_conv1 = bias_variable([32]) #每一个卷积核一个偏置值
- #把x_image和权值向量进行卷积,再加上偏置值,然后应用于relu激活函数
- h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
- h_pool1 = max_pool_2x2(h_conv1)
- #初始第二个卷积层的权值和偏置值
- W_conv2 = weight_variable([5, 5, 32, 64])#5*5的采样窗口,64个卷积核从32个平面抽取特征
- b_conv2 = bias_variable([64])
- #把h_pool1和权值向量进行卷积,再加上偏置值,然后应用于relu激活函数
- h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
- h_pool2 = max_pool_2x2(h_conv2)
- #28*28的图片第一次卷积后还是28*28,第一次池化后变成14*14
- #第二次卷积为14*14,第二次池化后变成可7*7
- #经过上面的操作后得到64张7*7的平面
- #初始化第一个全连接层的权值
- W_fc1 = weight_variable([7*7*64, 1024])#上一层有7*7*64个神经元,全连接层有1024个神经元
- b_fc1 = bias_variable([1024])#1024个节点
- #把池化层2的输出扁平化为1维
- h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64])
- #求第一个全连接层的输出
- h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
- #keep_prob用来表示神经元的输出概率
- keep_prob = tf.placeholder(tf.float32)
- h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
- #初始化第二个全连接层
- W_fc2 = weight_variable([1024, 10])
- b_fc2 = bias_variable([10])
- #计算输出
- prediction = tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
- #交叉熵代价函数
- cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y, logits=prediction))
- #使用AdmaOptimizer进行优化
- train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
- #结果存放在一个布尔列表中
- correct_prediction = tf.equal(tf.argmax(prediction, 1), tf.argmax(y, 1))
- #求准确率
- accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
- #变量初始化
- init = tf.global_variables_initializer()
- with tf.Session() as sess:
- sess.run(init)
- for epoch in range(21):
- for batch in range(n_batch):
- batch_xs, batch_ys = mnist.train.next_batch(batch_size)
- sess.run(train_step, feed_dict={x: batch_xs, y: batch_ys, keep_prob: 0.7})
- acc = sess.run(accuracy, feed_dict={x: mnist.test.images[:5000], y: mnist.test.labels[:5000], keep_prob: 1.0})
- print('Iter : ' + str(epoch) + ',Testing Accuracy = ' + str(acc))
#写在后面:
好久没有做学习总结
最近一直在给老师处理轴承数据,然后用深度学习做分类
每天就是忙忙忙
然后还要去健身
昨天是自己的生日,吃了一个超级可爱的小蛋糕
感觉自己还像个孩子
永远18岁
最近烦心事有点多
很多时候不必向别人解释自己
懂你的人自然而然就会懂
不懂得人解释也不懂
加油吧!小伙郭
加油,每一个为了生活而努力向前的人!
机器学习与Tensorflow(4)——卷积神经网络与tensorflow实现的更多相关文章
- TensorFlow 实战卷积神经网络之 LeNet
欢迎大家关注我们的网站和系列教程:http://www.tensorflownews.com/,学习更多的机器学习.深度学习的知识! LeNet 项目简介 1994 年深度学习三巨头之一的 Yan L ...
- 使用TensorFlow的卷积神经网络识别自己的单个手写数字,填坑总结
折腾了几天,爬了大大小小若干的坑,特记录如下.代码在最后面. 环境: Python3.6.4 + TensorFlow 1.5.1 + Win7 64位 + I5 3570 CPU 方法: 先用MNI ...
- Chinese-Text-Classification,用卷积神经网络基于 Tensorflow 实现的中文文本分类。
用卷积神经网络基于 Tensorflow 实现的中文文本分类 项目地址: https://github.com/fendouai/Chinese-Text-Classification 欢迎提问:ht ...
- TensorFlow实现卷积神经网络
1 卷积神经网络简介 在介绍卷积神经网络(CNN)之前,我们需要了解全连接神经网络与卷积神经网络的区别,下面先看一下两者的结构,如下所示: 图1 全连接神经网络与卷积神经网络结构 虽然上图中显示的全连 ...
- Kaggle系列1:手把手教你用tensorflow建立卷积神经网络实现猫狗图像分类
去年研一的时候想做kaggle上的一道题目:猫狗分类,但是苦于对卷积神经网络一直没有很好的认识,现在把这篇文章的内容补上去.(部分代码参考网上的,我改变了卷积神经网络的网络结构,其实主要部分我加了一层 ...
- tensorflow CNN 卷积神经网络中的卷积层和池化层的代码和效果图
tensorflow CNN 卷积神经网络中的卷积层和池化层的代码和效果图 因为很多 demo 都比较复杂,专门抽出这两个函数,写的 demo. 更多教程:http://www.tensorflown ...
- TensorFlow构建卷积神经网络/模型保存与加载/正则化
TensorFlow 官方文档:https://www.tensorflow.org/api_guides/python/math_ops # Arithmetic Operators import ...
- Tensorflow之卷积神经网络(CNN)
前馈神经网络的弊端 前一篇文章介绍过MNIST,是采用的前馈神经网络的结构,这种结构有一个很大的弊端,就是提供的样本必须面面俱到,否则就容易出现预测失败.如下图: 同样是在一个图片中找圆形,如果左边为 ...
- 跟我学算法-tensorflow 实现卷积神经网络
我们采用的卷积神经网络是两层卷积层,两层池化层和两层全连接层 我们使用的数据是mnist数据,数据训练集的数据是50000*28*28*1 因为是黑白照片,所以通道数是1 第一次卷积采用64个filt ...
随机推荐
- Java虚拟机 内存区域划分
(图片来自https://www.cnblogs.com/whgk/p/6138522.html) 先从线程私有区开始介绍 虚拟机栈 Java虚拟机栈是由一个个栈帧组成的,当一个方法被调用时,代表这个 ...
- [剑指Offer]7-重建二叉树
链接 https://www.nowcoder.com/practice/8a19cbe657394eeaac2f6ea9b0f6fcf6?tpId=13&tqId=11157&tPa ...
- 【c++】内存检查工具Valgrind介绍,安装及使用以及内存泄漏的常见原因
转自:https://www.cnblogs.com/LyndonYoung/articles/5320277.html Valgrind是运行在Linux上一套基于仿真技术的程序调试和分析工具,它包 ...
- 863. All Nodes Distance K in Binary Tree 到制定节点距离为k的节点
[抄题]: We are given a binary tree (with root node root), a target node, and an integer value K. Retur ...
- linearlayout 中ImageView 居中等问题
linearlayout 下的子控件使用android:layout_gravity=”center” 控件居左,没有达到居中的效果, 父窗体只能指定一种控件摆放方向 横向还是竖向 下面我弄了三个 ...
- win10自带输入法的标点符号切换
快捷键是ctrl+句号 然后开启设置,把中文也用英文标点也选上.
- gitlab 10安装
电脑环境:centos6.2+gitlab10.0 gitlab10.0 (gitlab-ce-10.0.0-ce.0.el6.x86_64.rpm)下载地址:https://mirrors.tuna ...
- flex布局之flex-basis采坑
场景: 容器设置为display: flex,容器里的子项目部分设置 flex: auto,子项目的宽高自适应正常,但如果再往子项目里嵌套一个(如:div),并设置高度(如:height: 100%) ...
- instr()函数--支持模糊查询
1)instr()函数的格式 (俗称:字符查找函数) 格式一:instr( string1, string2 ) / instr(源字符串, 目标字符串) 格式二:instr( strin ...
- noip第15课资料