Beautiful Soup的用法
BEAUTIFUL SOUP的介绍
# 导入库 # 或者
soup = BeautifulSoup(open("index.html"))
# 打印对象的内容,进行格式化的输出
print(soup.prettify())
BEAUTIFUL SOUP的安装
easy_install beautifulsoup4
pip install beautifulsoup4
BEAUTIFUL SOUP的使用
2. 初识BeautifulSoup以及使用
# 导入库
from bs4 import BeautifulSoup
# 或者
soup = BeautifulSoup(open("index.html"))
# 打印对象的内容,进行格式化的输出
print(soup.prettify())
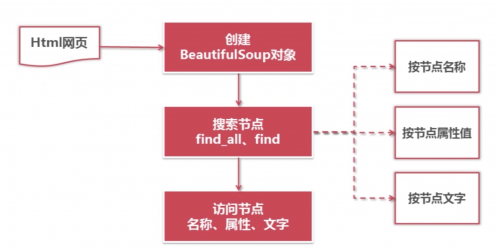
其实上述的代码就是将一段html的代码被BeautifulSoup解析,有了这个soup对象之后,其实我们就可以使用BeautifulSoup提供给我们大量的方法进行解析数据了
3. BeautifulSoup的解析器
3.1 Python标准库 (一般使用这个)
使用方法: BeautifulSoup(html_doc,"html.parser")
优势:Python内置,执行速度适中,文档容错能力强
劣势:Python 2.7.3 or 3.2.2)前 的版本中文档容错能力差
3.2 lxml解析器(推荐使用)
使用方法:BeautifulSoup(html_doc,'lxml')
优势:速度快,文档容错能力强(C编写),推荐使用
3.3 html5lib
使用方法:BeautifulSoup(html_doc,"html5lib")
优势:最好的容错性,已浏览器的方式解析文档,生成Html5格式的文档
劣势:速度慢,不依赖外部扩展
BEAUTIFULSOUP的四大对象及属性方法
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种: Tag
NavigableString
BeautifulSoup
Commen
1. Tag对象
<title>The Dormouse's story</title><a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>那我们怎样通过soup对象方便的获取HTML的内容呢?
其实非常的简单,我们可以使用soup.标签名的方式来轻松的获取内容,不过如果有多个相同的标签,只会找出第一个,如要查询所有的符合条件的标签,后续会介绍到
# 获取标题
print(soup.title)
# 获取head信息
print(soup.head)
# 获取a信息
print(soup.a)
Tag对象包含两个重要的属性:name和attrs
name
print(soup.name)
print(soup.head.name)
soup 对象本身比较特殊,它的 name 即为 [document],对于其他内部标签,输出的值便为标签本身的名称。
attrs 键值对格式
获取所有的属性
print(soup.p.attrs) #{'class': ['title'], 'name': 'dromouse'}
获取单独的某个属性
print(soup.p['class']) #['title']
print(soup.p.get('class')) #['title']
修改属性
soup.p['class']="newClass"
print(soup.p) #<p class="newClass" name="dromouse"><b>The Dormouse's story</b></p>
删除属性
del soup.p['class']
print(soup.p)
2.NavigableString
我们使用Tag对象获取了整个标签,那我们想要获取标签内部的内容怎么办?
使用 .string 属性 或者 get_text() 函数即可
print(soup.p.string) #The Dormouse's story
print(type(soup.p.string)) #<class 'bs4.element.NavigableString'>
print(soup.p.get_text())
3. BeautifulSoup
BeautifulSoup 对象表示的是一个文档的全部内容.大部分时候,可以把它当作 Tag 对象,是一个特殊的 Tag,我们可以分别获取它的类型,名称,以及属性来感受一下
print(type(soup.name))
#<type 'unicode'>
print(soup.name)
# [document]
print(soup.attrs)
#{} 空字典
1. 直接子节点
- .contents属性
tag 的 .content 属性可以将tag的子节点以列表的方式输出
print(soup.head.contents)
#[<title>The Dormouse's story</title>]
输出方式为列表,我们可以用列表索引来获取它的某一个元素
print(soup.head.contents[0])
#<title>The Dormouse's story</title>
- .children
调用返回的是一个列表生成器对象,我们可以通过遍历来获取所有的节点
print(soup.head.children)
#<listiterator object at 0x7f71457f5710>
循环遍历获取
for child in soup.body.children:
print(child)
2. 所有的子孙节点
.descendants
.contents 和 .children 属性仅包含tag的直接子节点,.descendants 属性可以对所有tag的子孙节点进行递归循环,和 children类似,我们也需要遍历获取其中的内容
for child in soup.descendants:
print(child)
3. 节点内容
- .string
如果一个标签里面没有标签了,那么 .string 就会返回标签里面的内容。如果标签里面只有唯一的一个标签了,那么 .string 也会返回最里面的内容。例如
print(soup.head.string)
#The Dormouse's story
print(soup.title.string)
#The Dormouse's story
如果tag包含了多个子节点,tag就无法确定,string 方法应该调用哪个子节点的内容, .string 的输出结果是 None
print(soup.html.string )
# None
4. 获取多个内容
常用查找方法
1. find_all( name , attrs , recursive , text , **kwargs )
find_all() 方法搜索当前tag的所有子节点,并判断是否符合过滤器的条件
下面是各项参数的解释
name参数
name 参数可以查找所有名字为 name 的tag
传字符串标签
soup.find_all('b')# [<b>The Dormouse's story</b>]
print soup.find_all('a')
#
[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
传列表
soup.find_all(["a", "b"]) # [<b>The Dormouse's story</b>,<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
传true
#True 可以匹配任何值,下面代码查找到所有的tag,但是不会返回字符串节点
for tag in soup.find_all(True):
print(tag.name) # html head title body p b p a a
关键字参数
传入一个指定的关键字参数如下
soup.find_all(id='link2') # [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
注意:如果想以class关键字查找,但class是python的关键字,怎么办?只需要class_即可,加一个下划线即可
soup.find_all("a", class_="sister")
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
可以传入多个指定名字的参数
soup.find_all(class_="sister", id='link1') # [<a class="sister" href="http://example.com/elsie" id="link1">three</a>]
但有些属性也是不能够使用,比如HTML5中的 data-* 属性
data_soup = BeautifulSoup('<div data-foo="value">foo!</div>')
data_soup.find_all(data-foo="value")
# SyntaxError: keyword can't be an expression
解决方法: 通过 find_all() 方法的 attrs 参数定义一个字典参数来搜索包含特殊属性的tag
data_soup.find_all(attrs={"data-foo": "value"}) # [<div data-foo="value">foo!</div>]
limit参数
find_all() 方法返回全部的搜索结构,如果文档树很大那么搜索会很慢.如果我们不需要全部结果,可以使用 limit 参数限制返回结果的数量.效果与SQL中的limit关键字类似,当搜索到的结果数量达到 limit 的限制时,就停止搜索返回结果.
soup.find_all("a", limit=2)
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
recursive参数
调用tag的 find_all() 方法时,Beautiful Soup会检索当前tag的所有子孙节点,如果只想搜索tag的直接子节点,可以使用参数 recursive=False
soup.html.find_all("title") # [<title>The Dormouse's story</title>]
soup.html.find_all("title", recursive=False) # []
2. find( name , attrs , recursive , text , **kwargs )
它与 find_all() 方法唯一的区别是 find_all() 方法的返回结果是值包含一个元素的列表,而 find() 方法直接返回结果
Beautiful Soup的用法的更多相关文章
- Python之Beautiful Soup的用法
1. Beautiful Soup的简介 简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据.官方解释如下: Beautiful Soup提供一些简单的.pyt ...
- Python爬虫利器二之Beautiful Soup的用法
上一节我们介绍了正则表达式,它的内容其实还是蛮多的,如果一个正则匹配稍有差池,那可能程序就处在永久的循环之中,而且有的小伙伴们也对写正则表达式的写法用得不熟练,没关系,我们还有一个更强大的工具,叫Be ...
- python爬虫(7)--Beautiful Soup的用法
1.Beautiful Soup简介 简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据. Beautiful Soup提供一些简单的.python式的函数用来 ...
- python 爬虫5 Beautiful Soup的用法
1.创建 Beautiful Soup 对象 from bs4 import BeautifulSoup html = """ <html><head& ...
- Beautiful Soup的用法(五):select的使用
原文地址:http://www.bugingcode.com/blog/beautiful_soup_select.html select 的功能跟find和find_all 一样用来选取特定的标签, ...
- 推荐一些python Beautiful Soup学习网址
前言:这几天忙着写分析报告,实在没精力去研究django,虽然抽时间去看了几遍中文文档,还是等实际实践后写几篇操作文章吧! 正文:以下是本人前段时间学习bs4库找的一些网址,在学习的可以参考下,有点多 ...
- Beautiful Soup库
原文传送门:静觅 » Python爬虫利器二之Beautiful Soup的用法
- python爬虫之Beautiful Soup的基本使用
1.简介 简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据.官方解释如下: Beautiful Soup提供一些简单的.python式的函数用来处理导航.搜索 ...
- 使用Beautiful Soup
Beautiful Soup初了解 # 解析工具Beautiful Soup,借助网页的结构和属性等特性来解析网页(简单的说就是python的一个HTML或XML的解析库)# Beautiful So ...
随机推荐
- 关于react的一些东西
Facebook 官方推出Create-React-App脚手架,基本可以零配置搭建基于webpack的React开发环境,内置了热更新等功能. 使用的原因以及特性: 无需配置:集成了对 React, ...
- Django HTTP_X_FORWARDED_FOR 和 REMOTE_ADDR
使用django来获取用户访问的IP地址,如果用户是正常情况下 request.META['REMOTE_ADDR'] 可以获得用户的IP地址.但是有些网站服务器会使用ngix等代理http,或者是该 ...
- centos 7 安装redis 3.2.1
https://www.cnblogs.com/zuidongfeng/p/8032505.html 下载安装包: http://download.redis.io/releases/ 根据需要自己选 ...
- JavaScript RegExp.$1
我们不生产代码 我们只是代码的搬运工 JavaScript RegExp.$1 RegExp 是javascript中的一个内置对象.为正则表达式. RegExp.$1是RegExp的一个属性,指的是 ...
- java多线程系列6 synchronized 加强版 ReentrantLock
ReentrantLock类是可重入.互斥.实现了Lock接口的锁,它与使用synchronized方法和快具有相同的基本行为和语义,并且扩展了其能力.ReenreantLock类的常用方法有: Re ...
- Zookeeper系列1 快速入门
Zookeeper的简介这里我就不说了,在接下来的几篇文章会涉及zookeeper环境搭建,watcher以及相关配置说明, 三种操作zookeeper的方式(原生API方式,zkclient,Cur ...
- 第二阶段第二次spring会议
昨天我对39个组发表了建议以及总结了改进意见和改进方案. 今天我对便签加上了清空回收站功能 private void 清空回收站ToolStripMenuItem_Click(object sende ...
- atom编辑器使用“apm install”无法响应的解决方案
工具:shadowsocks 利用ss建立代理服务,之后apm --help,得到apm的配置命令: apm - Atom Package Manager powered by https://ato ...
- Linux环境下java开发环境搭建一 JDK搭建
第一步:下载jdk压缩文件 第二步:上传到家目录下的soft目录下,可以采用winscp,此处下载的是.tar.gz文件 第三步:解压压缩文件,并在/usr/local目录下创建一个jdk7的目录,并 ...
- SAS对数据变量的处理
SAS对数据变量的处理 在使用DATA步基于已经存在的数据集生成新数据集时,可以指定在新数据集中不需要包含的变量而仅读取其他变量,或者指定仅需要在 新数据集中包含的变量.该功能可以通过DATA步中的S ...