目标检测(四)Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
作者:Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun
SPPnet、Fast R-CNN等目标检测算法已经大幅降低了目标检测网络的运行时间。可是尽管如此,仍然不能在工程上做到实时检测,这主要是因为region proposal computation耗时在整个网络用时中的占比较高。比如,Fast R-CNN如果忽略提取region proposals所花费的时间,就几乎可以做到实时性。为此,该论文介绍了Region Proposal Network(RPN)用以解决该问题。经实验证实,应用该算法的系统在GPU上的处理速度可以达到5fps的帧率。下面将从Faster R-CNN的网络结构、算法过程、训练方法等方面进行记录。
1. Faster R-CNN 网络结构
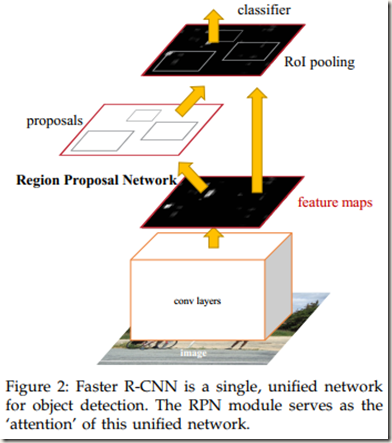
Fig. 2展示了网络的大致结构。可以发现,Fast R-CNN网络分为两部分,一部分是Region Proposal Network(RPN),另一部分是Fast R-CNN object detection network。其中RPN包括图中proposals和conv layers,detection network包括conv layers、ROI pooling及后面全连接层等部分。另外,conv layers被RPN和Fast R-CNN object detection network两部分共享。
RPN网络部分会告诉Fast R-CNN object detection network去看哪里,即搜索到的region proposals的location。这里使用的是神经网络中流行的“attention” mechanisms。
2. Region Proposal Networks
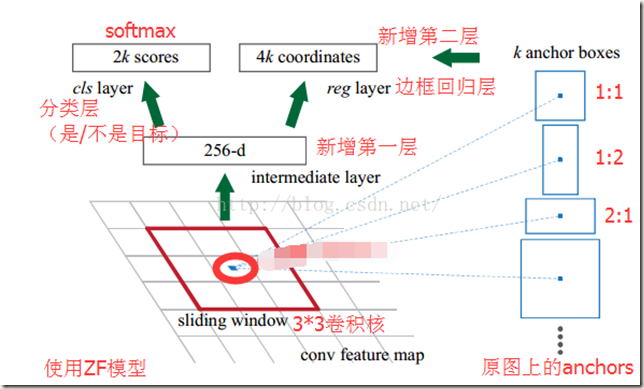
Fig. Region Proposal Networks
RPN网络可以输入一个任何尺寸的图像,然后利用anchors和softmax初步提取出foreground anchors作为候选区域。
该网络的前部是共享卷积层(conv layers),论文中作者使用两种模型作为共享卷积层:一种是Zeiler and Fergus model(ZF),它有5层可共享的卷积层;另一种是Simonyan and Zisserman model(VGG-16),它有13层可共享的卷积层。
RPN网络的卷积过程如下图(ZF):
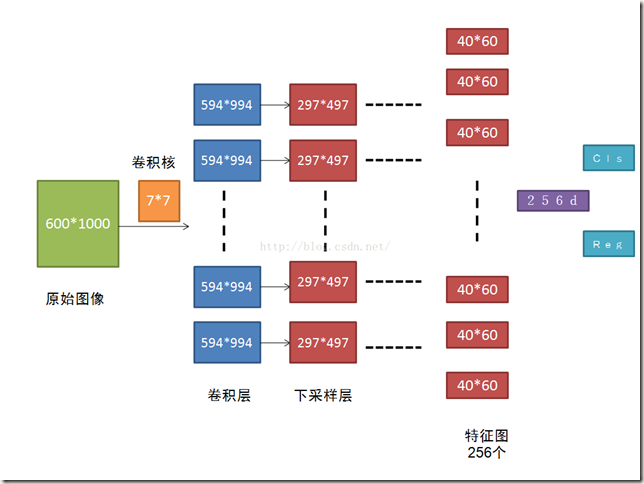
Fig. 3PN网络卷积过程
图中原始图像(600*1000)经过卷积层后输出256个40*60的feature maps,即论文中提到的W x H(typically,~2,400)。这些feature maps被RPN网络和Fast R-CNN detector共享。
那么如何利用一幅图像生成region proposals呢?下面以共享卷积层为VGG16为例进行说明:
Fig. 4是网上找到的一幅图,该图更加详细地展示了 Faster R-CNN 网络结构的细节。需要注意的是,图中共享的卷积层(conv layers) 选择的是 Simonyan and Zisserman 模型,即VGG16(13层共享卷积层):
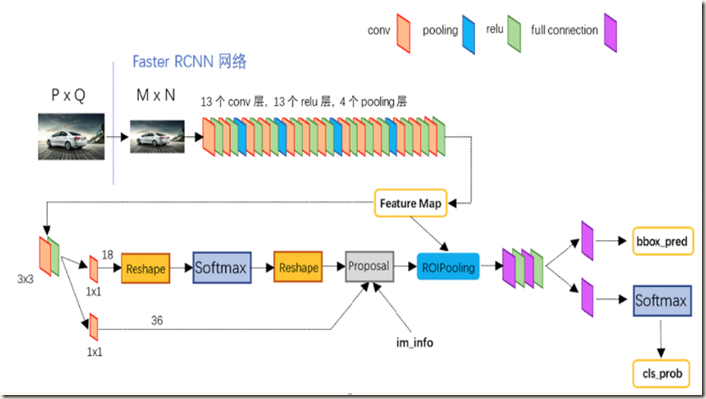
Fig. 4 aster RCNN具体结构
RPN输入一幅图像image(resized,论文中设置为800*600)后经共享卷积层生成通道数为256的feature maps,然后使用一个size为n*n(二维)的空间sliding window与feature maps(50*38*256)进行非标准的卷积运算(strides=1,padding=(n-1)/2,单通道卷积核,运算和标准池化类似,运算前后通道数不变),计算结果仍然是50*38*256。可以发现,每个位置通过卷积求得的特征是256-d,这就是论文中说到的将每个sliding window都被映射到一个256-d的低维特征。而anchors的生成过程具体是这样:sliding window的中心在image上对应一片区域(相当于中心位置的神经元在image上的感受野,当n=3时,ZF 模型中中心位置的神经元在image上的感受野大小为171*171;VGG 模型中为228*228),计算出该区域的中心位置后以该位置为中心,按3种scale(即面积,128*128,256*256,512*512)、每种scale各有3种aspect ratios(即长宽比,1:1,1:2,2:1)要求取9个(默认为9个)矩形区域。这些区域就是提取到的anchors boxes。可见,feature maps中的一个位置,共有9个anchors,提取到的候选anchors的大致位置也被获悉(后面会有修正)。另外,3种scale也是可以根据具体情况更改的,更改时最好能使最大的scale能基本将input image覆盖。作者将输入图像resize成最短边s=600,可以发现,最大的scale已经几乎能覆盖整幅图像,这也是借助anchors能实现尺度不变的原因。图Fig.5中左边是每个位置对应的9个anchors在image上的分布情况,右图是所有anchors的分布情况。对于50*388的feature maps,共有50*38*9个anchors。
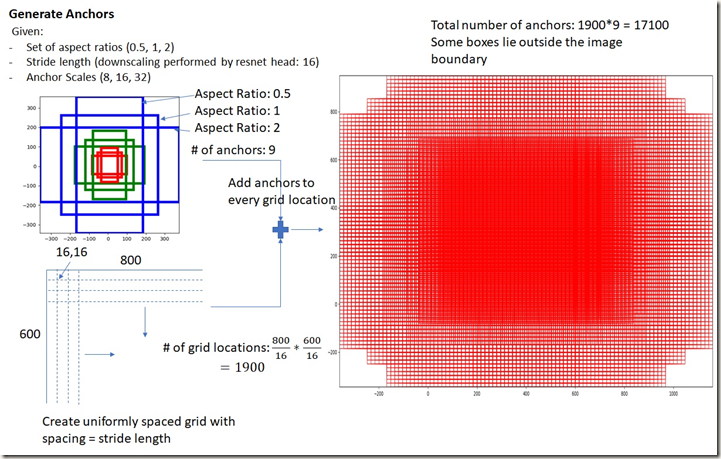
Fig. 5 9个anchors在input image上的分布
为什么这样操作?作者在论文中也说Faster R-CNN是通过pyramids of reference boxes实现multiple scales and sizes的
网上有个解释我觉得比较合理,大致如下:
anchor的本质是SPP(spatial pyramid pooling)思念的逆向。SPP的作用是从不同尺寸的输入提取相同尺寸的特征,那么SPP的逆向就是从相同尺寸的输出倒推得到不同尺寸的输入。以上面提取region proposals的过程为例,对于一个n*n的sliding window,它对feature maps进行卷积后提取的固定长度特征所对应的输入应该是sliding window的中心在image上的投射区域内。为了实现多尺度、多长宽比,我们以投射区域的中心为中心从大到小提取不同尺度的anchors。可以认为,特征就是通过对这些候选anchors进行池化得到的。可是,论文中对3*3大小的区域进行卷积(不是1*1)作为9个anchors的特征,网上说这样做相当于每个点又融合了周围3*3的空间信息,或许是为了更鲁棒。
在确定大量anchors之后,我们就能确定相应的位置信息,但这是不准确的,不过没关系,后面会有2次bounding-box regression对位置进行修正。
在通过“卷积”获得每个位置的低维特征后(50*38*256)会经过一层ReLU(如Fig.4示,论文中也有提及),紧接着是两路全连接层。第一路使用softmax classifier对anchors进行二分类(object or non-object),输出两个概率值,以判断anchors是否为前景,如下:

Fig.6 RPN网络cls部分结构
特征先经过1*1的卷积得到50*38*18(9*2)大小的矩阵。不了解计算过程,但是结果合理。因为每个位置对应了9个anchors,每个anchor有前景和背景两种可能。
然后接一个reshape layer,这是为了便于softmax分类。至于原因则与caffe中softmax的实现形式有关。caffe的基本数据结构blob用如下形式保存数据:blob=[bacth_size, channel, height, width]
上面的50*38*18大小的矩阵在blob中的存储形式为[1,2*9,50,38]([1,2*9,H,W]),而在softmax分类时需要进行二分类,所以reshape layer会将其变为[1,2,9*50,38](即[1,2,9*H,W]),即将channel这个维度空出以存放两个概率值。待分类完成后会再次reshape回原状。这时已经将带有object的anchors通过分类器挑选出来。
另一路的作用是计算对于anchors的bounding box regression偏移量,以获得精确的位置信息。这是进行第一次修正(bounding-box regression),过程如下:
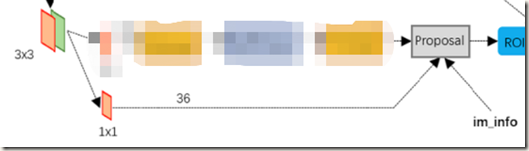
Fig.7 RPN网络reg部分结构
同样,特征先经过1*1的卷积,不过得到的是50*38*36(9*4)大小的矩阵。意思是每个位置有9个anchors,每个anchor的位置信息有4个用于回归的参数。
后面接的是一个box-regression layer(reg),对anchors的位置进行修正。
RPN网络的最后一层是Proposal layer,该层的作用是综合foreground anchors和bounding box regression偏移量生成region proposals,同时剔除太小和超出边界的proposals,最后将提取到的proposals提交给后面的检测网络。im_info的作用是保存输入图像的缩放信息(输入Faster RCNN的图像都会先缩放到固定尺寸)以及卷积过程中的strides(用于计算anchor的偏移量)。下面一段摘自网络:
Proposal Layer forward(caffe layer的前传函数)按照以下顺序依次处理:
- 生成anchors,利用
对所有的anchors做bbox regression回归(这里的anchors生成和训练时完全一致)
- 按照输入的foreground softmax scores由大到小排序anchors,提取前pre_nms_topN(e.g. 6000)个anchors,即提取修正位置后的foreground anchors。
- 限定超出图像边界的foreground anchors为图像边界(防止后续roi pooling时proposal超出图像边界)
- 剔除非常小(width<threshold or height<threshold)的foreground anchors
- 进行nonmaximum suppression
- 再次按照nms后的foreground softmax scores由大到小排序fg anchors,提取前post_nms_topN(e.g. 300)结果作为proposal输出。
到这里可以很清楚的发现,RPN的作用就是先在原图image上搜索出密密麻麻的候选anchors,然后再去判断哪些anchor对应的区域是有目标的前景,哪些是没有目标的背景(二分类),并对位置偏移量进行修正。其实,RPN已经初步完成了目标的检测与定位,但是并不知道目标的类别(只知道是否为前景),location也需要进一步修正,这些都是后面Fast RCNN的工作。
移不变与尺度不变:
- Translation-Invariant Anchors
Faster R-CNN解决平移不变的方法是:通过卷积核中心(用来生成region proposals的Anchor)进行不同尺度、宽高比的采样,使用3种尺度和3种比例来产生9种anchor。
平移不变:当Image中的object移动时,对应的proposal也会移动,系统能够使用相同的函数预测到在任何位置的proposal。这个特性就是移不变
移不变特性降低了模型的规模
- Multi-Scale Anchors as Regression References
multi-scale prediction有两种流行的实现方法:第一种是基于image/feature pyramids。图像被调整为多个尺度,对于每个尺度的图像均计算feature maps或deep convolutional features,该方法很耗时;第二种是对feature maps使用multi-scale(and/or aspect ratios)的sliding windows。该方法解决多尺度问题时可以被视为“pyramid of filters”。第二种方法通常与第一种方法一起使用。
论文中提出的anchor提供了一种新颖的multiple scales and acpect ratios解决方法(anchor-based method)。(scale一般指面积;aspect ratio指长宽比)
该方法建立在一个pyramid of anchors之上,相比传统的方法效率更高。该方法根据多尺度多长宽比的anchors对bounding boxes进行分类和回归,并且只使用单尺度的images和feature maps。
得益于基于anchors的多尺度设计,我们可以像Fast R-CNN detector那样,仅使用一幅单尺度图像计算得到的convolutional features。这里,多尺度anchors是关键,它使得Faster R-CNN能够共享特征而不需要再去解决多尺度的问题。
3. Fast R-CNN object detection network
Faster RCNN的第二部分和Fast RCNN中object detction network相同,这里不再赘述。这部分只记录些细节。
- bounding-box regression(边框回归)原理
之所以需要做边框回归主要是因为region proposal或者anchors与ground-truth box的交并比(IoU)不高,没有比较精确地检测出object的位置,这时通过bounding-box regression就能得到一个接近ground-truth box的边界框。如下图所示:

Fig.8
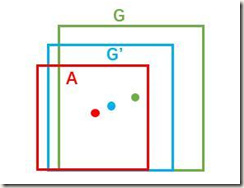
红色区域被分类器识别为飞机,但是与绿色的边界框交并比不高,导致定位误差很大。这时候就可以对红色的框进行微调,使得经过微调后的predicted窗口与Ground-truth box尽可能一致。
边框一般使用4维向量(x,y,w,h)表示。前两个参数表示边框中心的坐标,后面两个参数表示边框的宽和高。在Fig.9中,红色的框A表示提取到的原始region proposal,绿色的框G表示标记出的Ground-truth box,且与A属于同一类。回归的目标就是寻找一个映射使得A经过映射得到一个与真实窗口G尽可能接近的窗口G’。
可用公式表达如下,式中映射 f 即为待寻找的目标。:
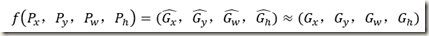
回归原理很简单,就是先做平移使得框中心尽可能重合,然后进行尺度缩放,使面积接近。
- 先平移(Δx,Δy),Δx=Pwdx(P),Δy=Phdy(P)
也就是R-CNN论文中描述的
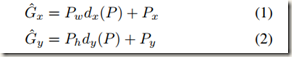
- 后尺度缩放(Sw,Sh),Sw =Pwdw(P),Sh=Phdh(P)
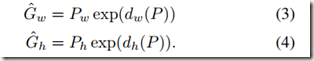
回归需要得到的就是上面公式中的四个线性函数dx(P),dy(P),dw(P),dh(P)
另外我们需要注意的是,只有当region proposal与ground-truth相差较小时,才能认为二者之间的变换是一种线性变换,这样就可以使用线性回归来建模对窗口进行微调。所以R-CNN中选择的判断条件是IoU>0.6,Faster RCNN中设置的是IoU>0.7。如果我们使用与ground-truth相差太大的region proposal训练回归模型,那么得到的回归模型效果会很差,甚至不能工作。这主要是因为离得太远时二者已经是非线性关系,用来训练线性模型的话肯定不合适。
线性回归就是给定输入的特征向量X(不是边框的四个参数),学习一组权重参数W,使得经过线性回归后得到的输出值(偏移量)dx(P),dy(P),dw(P),dh(P)相对于ground truth 的真实值非常接近,从而利用偏移量得到接近ground-truth的预测框。
理想的偏移量(tx,ty,tw,th)可以表示如下:
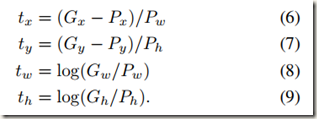
公式(6)(7)(8)(9)是根据(1)(2)(3)(4)变换得到的
如果Region proposal P的特征表示为Φ(P),需要学习的线性回归模型的参数记为W*,四个参数的理想偏移量表示为t*,那么回归模型的四个输出表示成d*(P)=WT*Φ(P),那么线性回归模型的目标函数如下(*表示x,y,w,h):
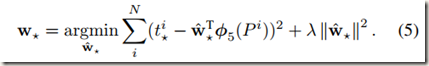
接下来的任务就是通过优化上面的目标函数学习到模型参数W*
得到模型参数W*后就可以对窗口进行回归。如果提取到的特征是Φ(P),那么预测到的偏移量就是d*(P)=WT*Φ(P),再根据公式(1)(2)(3)(4)即可得到蓝色框G‘的坐标表示,即预测到的bounding-box的位置。
- nonmaximum suppression (非极大值抑制)

- RoI pooling layer
作用:将不同尺度proposals的feature maps先转换为若干层金字塔,再逐层池化输出固定长度的特征。
输入有两个:
- 整幅图像的feature maps
- Region proposals(通过SS或RPN)
具体可以查看论文《Fast R-CNN》
4. RPN网络训练
- Loss Function 损失函数
为了训练RPN网络,作者对每一个anchor使用了二值化类标签。论文中将两种anchors标记为positive:与一个ground-truth box有最高IoU的anchor;与任何ground-truth box的IoU都超过0.7的anchor。由此可见,一个ground-truth box可能会将多个anchors判定为positive。虽然通常第二种情况已经能充分判定出positive examples,但是依然会结合第一种判定方法使用,因为在有些时候,第二种判定方法可能会找不到positive sample。另外,将与所有ground-truth的IoU都低于0.3的non-positive anchor标记为negative,那些既不是positive也不是negative的anchors将会被忽略,不考虑进目标函数。
借助以上定义以及Fast R-CNN中的多任务损失,定义出一幅Image的loss function,如下:
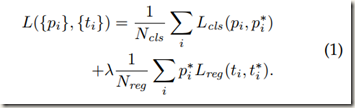
上式中,i 是mini-batch中anchor的索引;pi 是anchor带有目标(前景)的预测概率。如果anchor是positive sample的话,ground-truth label p*i 为1;anchor是negative的话 p*i 为0;non-positive 和non-negative的anchor不考虑进目标函数。ti 是回归预测出的四个坐标的向量表示,t*i 是与一个positive anchor相关的ground-truthbox的坐标向量表示,ti 和t*i 只考虑positive anchors。
分类损失Lcls是两个类别(object vs. not object)上的log loss。回归损失则表示为Lreg(ti ,t*i )=R(ti - t*i ),其中R是定义在Fast R-CNN中的robust loss fuction(smooth L1),如下:
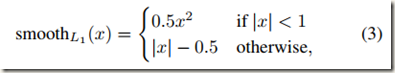
另外还可以发现,目标函数中的回归损失只能被positive anchors激活(p*i =1 for positive anchor,p*i =0 for others)
损失函数中的两项分别被Ncls和Nreg归一化,并且被平衡参数λ加权。作者在论文中取Ncls为256(mini-batch size)、Nreg为2400(the number of anchor locations,也就是feature maps上的位置数量)。λ取默认值10,这样的话cls和reg两项的加权系数就基本相等(256~2400/10)。作者在论文的后面通过实验说明了实验结果对λ在大范围内变化不敏感,如下:

同时,作者也提醒,上面的归一化不是必须的并且可以简化。
至于RPN网络中的边框回归,作者使用了一种和以往RoI-based方法不同方法。在Fast R-CNN和SPPnet中,边框回归使用的都是SPP layer从任意尺寸RoI中提取到的固定长度特征,并且回归模型的权重对于不同尺寸的RoI是共享的。而在Faster R-CNN中,线性回归使用的固定长度特征是通过相同空间尺寸的窗口获得的。考虑到一个位置处的k个anchors拥有不同scale和aspect ratio,作者就使用了k个bounding-box regressors。每个regressor负责一种scale和一种aspect ratio,并且这k个regressors不共享权重,即各个regressor是独立的。
回归的原理与R-CNN中描述的类似,这里只做简要说明。需要的参数如下:
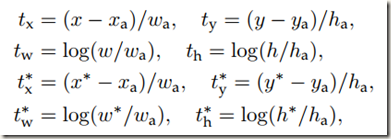
t* 是预测的边框与anchor box边框的偏移量;t**是理想的偏移量,即ground-truth与anchor box间的偏移量。二者的差会作为线性回归的目标函数。边框回归可以被认为是将anchor box映射到一个接近ground-truth box的位置。
- Training RPNs
RPN网络可以使用反向传播和SGD进行端到端的训练。
在mini-batch的选取上,作者并没有使用一幅图像中的所有anchors来优化loss function,因为anchors中negative samples占比非常高,这样训练出的模型会偏向negative samples,使用模型进行预测时会出现很多false positive samples。相反,作者在一幅图像的anchors中随机抽取256个anchors作为一个mini-batch来计算loss function,而且这256个anchors由positive samples和negative samples按照1:1的比例构成。如果一幅image中的positive samples的数量少于128个,那么就用negative samples填充mini-batch.
共享卷积层使用的是pre-trained model(for ImageNet classification),因此不需要初始化参数。而那些new layers的权重则使用随机从均值为0、标准差为0.01的高斯分布中提取的数值进行初始化。
微调时,如果使用的是ZF net,那么微调所有层;如果使用的是VGG net,那么微调conv3_1及后面的layers,这样能够节省内存
微调时,前60k个mini-batches使用学习速率0.001,接下来的20k mini-batches使用0.0001。动量设为0.9,权重衰减取为0.0005
5. Fast R-CNN和RPN的联合训练
Faster R-CNN中的detection network使用的是Fast R-CNN,训练和测试方法完全一致。Region Proposals Network网络的训练方法前面也大致介绍清楚,接下来记录在带有共享卷积层的情况下如何统一训练二者。
很明显,RPN和Fast R-CNN不能单独训练,否则卷积层的参数会不断被修改而无法收敛。这里作者提出了三种训练带有共享特征的网络的方法。
- Alternating training(交替训练)
先训练RPN,然后使用得到的proposals来训练Fast R-CNN,接着使用Fast R-CNN微调后的网络来初始化RPN…..不断迭代该过程即可
该论文中的所有实验都使用这种训练方法
- Approximate joint training(近似联合训练)
在训练时将RPN和Fast R-CNN融合成一个网络训练。在每次迭代中,前向过程产生region proposals被视为固定的、已经计算正确的proposals,并且被用来训练Fast R-CNN detector。反向传播和一般情况相同,不过对于共享卷积层而言,反向传播的信号同时来自于RPN loss 和 Fast R-CNN loss。
这种方法很容易使用,但是这种方法忽视了proposal boxes 坐标的导数,因而这种方法是近似的。
在实验中作者发现,这种方法能够产生与准确结果接近的效果。同时,与交替训练相比,该方法的训练时间降低了25%-50%。在作者提供的Python code中包含了这种方法。
- Non-approximate joint training(非近似联合训练)
就像上面讨论的那样,RPN预测的bounding boxes也是网络的响应。Fast R-CNN中的RoI pooling layer 接受卷积特征和RPN预测的bounding boxes,那么一个理论上有效的反向传播求解器也应该包括boxes坐标的梯度。这些梯度在Approximate joint training中被忽略了。在本方法中,我们需要RoI pooling layer对box coordinates是可微的。这是一个非常重要的问题,可以通过《Instance-aware semantic segmentation via multi-task network cascades》中介绍的“RoI warping” layer给出解决方案,这超出了本文的范围,不予介绍。
下面重点介绍4-Step Alternating training(交替训练):
论文采用一种实用的四步训练算法,通过交替优化来学习共享特征(共享卷积层)。
- 训练RPN。 RPN网络使用一个ImageNet-pre-trained model来初始化参数,并端到端地对region proposal task进行微调。
- 使用第一步中RPN产生的proposals训练独立的 detection network(Fast R-CNN)。 Detection network也使用ImageNet-pre-trained model来初始化参数。到这里时,这两个网络并不共享卷积层。
- 使用detection network来初始化RPN训练,但是固定共享卷积层的参数,只对RPN特有的layers进行微调。至此,两个网络已经共享卷积层
- 保持卷积层参数不变,微调Fast R-CNN特有的layers。像这样,两个网络共享了卷积层,并且形成了一个统一的网络。类似的交替训练可以迭代更多次,但是作者在论文中说迭代后观察到的改善微不足道。
6. Implementation Details(应用细节)
- 训练和测试RPN和detection network使用的均是single-scale image(单一尺度图像)
- 将输入images resize成最短边s=600 pixels
- Multi-scale feature extraction(多尺度特征提取,即输入一幅image的多个尺度,使用图像金字塔)也许会提升精度,但是需要考虑速度与精度的平衡
- 对于anchors,作者使用的3中scales指的是128*128、256*256、512*512 pixels,3种aspect ratios指的是1:1、1:2和2:1。这些超参数不是为特定的数据集专门选择的,后面作者也做了实验,如下:
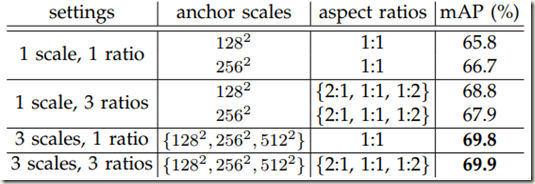
- 论文提出的方法不需要使用Image pyramid和filter pyramid来预测regions of multiple scales,节省了运行时间
- 超出image边界的anchor boxes需要谨慎处理(训练和测试时处理方式不同)。在训练时,作者忽略了所有超出边界的anchors,所以它们不会影响loss。对于一幅1000 * 600的image,一共会有大约20000(~60*40*9,即(1000/16)*(600/16)*9)个anchors。如果忽略超出边界的anchors,每幅图像大概会剩下6000个用来训练。如果训练时不忽略超出边界的anchors,它们会在目标函数中带来难以纠正的error terms,并且训练不会收敛。但是在训练时,我们仍然将RPN应用到整幅图像。这样也许会产生超出边界的proposal boxes,这时作者没有采取忽略这些跨界anchors的做法,而是将这些超出边界的anchors裁剪到image的边界处,即剪掉超出image的部分,剩余的部分保留作为proposals。
- 一些RPN产生的proposals彼此高度重合。为了减少冗余,作者根据region proposals的cls scores对它们进行非极大值抑制处理(NMS)。论文中将NMS使用的IoU阈值设为0.7,这个阈值能为每幅图片保留下来大约2000个region proposals。作者在论文的后面也证实了NMS不会影响最终的检测精度,但是大幅降低了proposals的数量。
- 在NMS之后,作者使用了top-N ranked proposal regions来进行检测,也就是将scores排在前N的proposal regions传给detection network。接下来就是使用2000个RPN proposals训练Fast R-CNN,但在测试时使用的proposals的数量需要进行评估。
7. 总结
笔记的最后我想把Faster R-CNN的训练和测试过程详细地描述一下,方便以后查看和修改。(可能有错误的地方,)
Faster R-CNN分为两部分,一部分是用来生成region proposals的Region Proposals Network, 另一部分是用来对region proposals进行分类和二次位置修正的Fast R-CNN detector network,二者共享前部的卷积层。因为Faster R-CNN的训练比较复杂。
首先是RPN的训练。
- 输入一幅image后,经过卷积获得该图像的feature maps
- 根据anchor选取的scales和aspect ratios从Image中提取到大量的anchor boxes(粗略的位置信息已知,还进行的正负划分),并利用3*3的卷积计算得到对应的256-d或512-d的低维特征
- 将特征分为两路输出,一路用来经过二分类softmax classifier输出anchor boxes为foreground和background两个概率值;另一路使用全连接网络对边框的位置进行回归,第一次修正使得边框的location稍微精确些
- 损失函数loss function不是由所有的anchor boxes决定的,而是由划分的positive samples和negative samples影响
- 训练时使用的单个mini-batch全部来自于一幅图像(我想和Fast R-CNN一样,使用同一幅image是为了减少运算),容量为256,由128个positive samples和128个negative samples构成。如果image中的positive samples数目不足128,那就用negative samples补充。
- 损失函数分为两部分,一部分是边界框坐标偏移量线性回归的误差,这部分只统计positive samples的误差;另一部分是分类误差,针对所有的正负样本
- 应用反向传播和SGD就可以对RPN进行训练
- 训练完成后剔除超出边界的anchors,然后按照scores进行NMS
- NMS之后scores按照从高到低排序,将前N个anchors提供给Fast R-CNN detection network用来检测
Fast R-CNN detection network的训练在Fast R-CNN的笔记里已经介绍过,这里就不再介绍,不过训练过程和RPN类似
两部分的统一训练也不总结了。。。
测试的话和训练类似,只不过没有标签。另外,测试时,RPN产生的超出边界的region proposals不会被剔除,而是剪去超出部分,留下未超出部分。
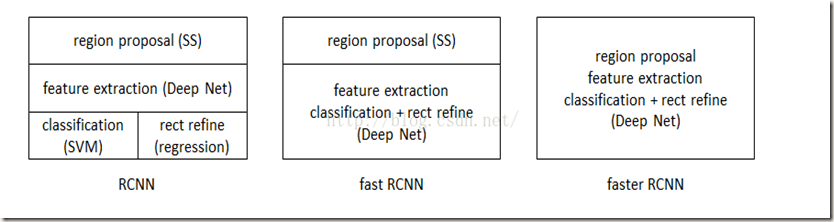
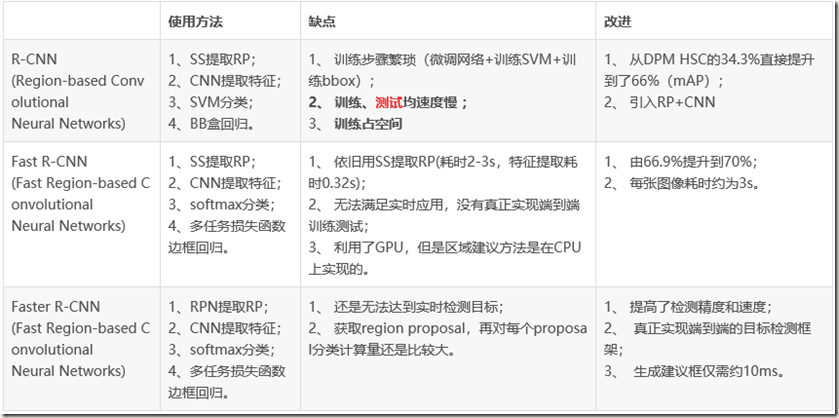
R-CNN、Fast R-CNN、Faster R-CNN三者关系
参考:
目标检测(四)Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks的更多相关文章
- 中文版 Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks 摘要 最先进的目标检测网络依靠区域提出算法 ...
- 深度学习论文翻译解析(十三):Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
论文标题:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks 标题翻译:基于区域提议(Regi ...
- [论文理解] Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks 简介 Faster R-CNN是很经典的t ...
- 论文阅读笔记二十七:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks(CVPR 2016)
论文源址:https://arxiv.org/abs/1506.01497 tensorflow代码:https://github.com/endernewton/tf-faster-rcnn 室友对 ...
- Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks论文理解
一.创新点和解决的问题 创新点 设计Region Proposal Networks[RPN],利用CNN卷积操作后的特征图生成region proposals,代替了Selective Search ...
- Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks(理解)
0 - 背景 R-CNN中检测步骤分成很多步骤,fast-RCNN便基于此进行改进,将region proposals的特征提取融合成共享卷积层问题,但是,fast-RCNN仍然采用了selectiv ...
- Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
将 RCN 中下面 3 个独立模块整合在一起,减少计算量: CNN:提取图像特征 SVM:目标分类识别 Regression 模型:定位 不对每个候选区域独立通过 CN 提取特征,将整个图像通过 CN ...
- 【CV论文阅读】Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
由RCNN到FAST RCNN一个很重要的进步是实现了多任务的训练,但是仍然使用Selective Search算法来获得ROI,而FASTER RCNN就是把获得ROI的步骤使用一个深度网络RPN来 ...
- 目标检测系列 --- RCNN: Rich feature hierarchies for accurate object detection and semantic segmentation Tech report
目标检测系列 --- RCNN: Rich feature hierarchies for accurate object detection and semantic segmentation Te ...
随机推荐
- Openwrt 刷机后配置WAN口,安装luci和设置中文、安装挂载USB存储。
官方版本的ROM编译时时没有把luci和uhttpd打包进去的,所以,要ssh登录到路由器后手动安装,默认用户名root,密码是空. 如果你的路由器是挂载在其他路由下面的,DHCP可以获取到IP,能正 ...
- vivado和modelsim联合调试仿真
vivado和modelsim联合调试仿真 0赞 发表于 2017/5/10 19:10:59 阅读(881) 评论(0) 使用vivado和modelsim联合调试仿真时,在破解完modelsim后 ...
- iis asp.net4.0注册
asp.net4.0下载地址:https://download.microsoft.com/download/9/5/A/95A9616B-7A37-4AF6-BC36-D6EA96C8DAAE/do ...
- neo1973 audio subsystem
fhttp://wiki.openmoko.org/wiki/Neo_1973_audio_subsystem using Bluetooth headset with GSM NOTE none o ...
- RTT(往返时间)和RPC
RTT(Round-Trip Time)往返时间在计算机网络中它是一个重要的性能指标.表示从发送端发送数据开始,到发送端收到来自接收端的确认(接收端收到数据后便立即发送确认,不包含数据传输时间)总共经 ...
- 使用Go语言操作MySQL数据库的思路与步骤
最近在做注册登录服务时,学习用Go语言操作MySQL数据库实现用户数据的增删改查,现将个人学习心得总结如下,另外附有代码仓库地址,欢迎各位有兴趣的fork. 软件环境:Goland.Navicat f ...
- Linux 文件普通权限_011
一.文件权限10个字符对应类型和权限 二.Linux普通文件和Linux目录读.写.执行权限说明 标注:Linux 中的文件名是存在于父目录的block里面,并指向这个文件的inode节点 1.lin ...
- 如何查看SQL SERVER数据库当前连接数
SELECT * FROM[Master].[dbo].[SYSPROCESSES] WHERE [DBID] IN ( SELECT [DBID]FROM [Master].[dbo].[SYSDA ...
- python什么时候加self,什么时候不加self
1.self是什么,一般都说指对象本身,这样说了没了用,说了后还是很难懂,因为这样说了后,仍然完全搞不清楚,什么时候变量前需要加self,什么时候不需要加self. 造成很多人,已经怕了self,不停 ...
- js返回上一页并刷新、返回上一页、自动刷新页面
一.返回上一页并刷新 <a href="javascript:" onclick="self.location=document.referrer;"&g ...