MySQL优化小结

数据库的配置是基础、SQL优化最重要(贯穿始终,每日必做),由图可知,越往上优化的面越小,最基本的SQL优化是最重要的,往上各个参数也没太多调的,也不可能说调一个innodb参数性能就会好多少,而动不动就加配置那更是不对的
Ⅰ、数据库配置
1.1 关于内存的
innodb_buffer_pool_size = 总内存的60%~80%甚至更高
innodb_buffer_pool_instances = cpu数量或者一半
innodb_page_size = 不要设置太小,现在的业务保持默认8k或者设置为16k
innodb_flush_method = O_DIRECT 必须设置,避免做两次缓存,不设置性能可能会好一些,但实际用了额外内存
5.7.6 online resize buffer pool
set global innodb_buffer_pool_size=256*1024*1024; 这个不能直接=xxx M,会报错1232
set global innodb_disable_resize_buffer_pool_debug = off; 云数据库中用的多
1.2 关于刷新的
innodb_io_capacity = write的性能 fuzzy checkpoint 刷部分脏页,对系统影响较小,5.6独立刷新线程,5.7并行刷新线程
innodb_page_cleaners = cpu的数量或者一半
innodb_fast_shutdown = 1 innodb关闭时候,bp中dirty page刷但磁盘上 sharp checkpoint刷新全部脏页,系统hang住
innodb_flush_neighbors = ssd设置为0
1.3 redo
记录page的操作日志,与二进制日志完全不同,它是循环覆盖写的,默认没有类似pg或者oracle的归档
innodb_log_file_size = 4G 5.6版本至少4G,存储性能非常好可以设置为8G或者16G
innodb_log_buffer_size = 8M
innodb_log_files_in_group = 3
innodb_log_group_home_dir = /redolog/
1.4 undo
undo段,实现回滚,实现mvcc功能,不怎么需要调整,问题不大
undo段的数量 5.5之前1024,5.5开始128*1024
undo的回收是purge来做
innodb_undo_directory=/undolog/
innodb_undo_logs=128
innodb_undo_table_spaces=3
innodb_undo_log_truncate=1
innodb_max_undo_log_siz=1G
innodb_purge_reseg_truncate_frequency=128
innodb_purge_batch_size=300
innodb_purge_threads=4/8 这个参数可以稍微多开几个,回收undo,真正删除记录会快一点
1.5 开启线程池
并发上千的情况下,线程池开和不开性能会相差很大(近百倍),秒杀等业务,还要做双保险,前端和数据库都做一层限流,前端可以用redis,数据库开线程池,保障高并发下的性能平稳
MariaDB线程池没有优先级队列,推荐MySQL/InnoSQL/Percona线程池
thread_handling=pool-of-threads
thread_pool_size=32
thread_pool_oversubscribe=3
extra_port=3333
1.6 日志配置
binary log、error log、slow log、general log(通常不推荐,用P_S中events_statements_current、events_statements_history、events_statements_history_long等来代替)
log_output = file
slow_query_log = 1
slow_query_log_file = slow.log
long_query_time = 2
min_examined_row_limit = 100
log_queries_not_using_indexes = 1
log_slow_admin_statements = 1
log_slow_slave_statements = 1 在从上开启慢日志,意义不大
log_throttle_queries_not_using_indexes = 10
log_timestamps = 'system'
bind_address = xxx.xxx.xxx.xxx 绑定ip
Ⅱ、SQL优化
这里咱们都默认是简单查询只提两个重点
2.1 子查询
对于in,5.6之前是lazy(rewrite to exsits,poor performance)的,5.6开始(MariaDB 5.3)会弄成semi-join,固性能基本没问题
(root@localhost) [performance_schema]> show variables like 'optimizer_switch'\G
*************************** 1. row ***************************
Variable_name: optimizer_switch
Value: index_merge=on,index_merge_union=on,index_merge_sort_union=on,index_merge_intersection=on,engine_condition_pushdown=on,index_condition_pushdown=on,mrr=on,mrr_cost_based=on,block_nested_loop=on,batched_key_access=off,materialization=on,semijoin=on,loosescan=on,firstmatch=on,duplicateweedout=on,subquery_materialization_cost_based=on,use_index_extensions=on,condition_fanout_filter=on,derived_merge=on
1 row in set (0.00 sec)
但是对exists,永远是相关子查询,性能比较糟糕,看exists后面的子查询有没有反复的迭代操作,有的话就很差,in的话问题不大
2.2 join
MySQL只支持nested-loop-join
具体算法等详见join算法分析
大表连接一定要创建索引,否则性能特别差,不支持hash join
行号问题,千万别弄子查询做,会变为相关子查询
rank排名的实现,尽量不要在MySQL中做,一般在redis里面搞
Ⅲ、软硬件配置
3.1 内存
关闭numa(Non-uniform Memory Access——非一致存储访问结构)
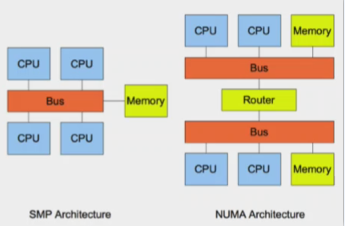
numa的内存分配策略有四种
- linux下default 总是在本地节点分配内存
- bind 强制分配到指定节点上
- interleave 在所有节点或者指定节点上交织分配
- preferred 在指定节点上分配,失败则在其他节点上分配
如果只在本地分配内存,那就存在还有内存,MySQL却oom了的情况,所以要用interleave模式来启动mysql
oom的时候发现系统还有剩余内存,首先考虑这个问题
yum install -y numactl
numactl --interleave=all mysqld&
写到启动脚本里去 vim /etc/init.d/mysql.server
单实例MySQL关闭numa的几种方法
MySQL启动时关(如上)
BIOS中关
系统启动关闭
vim /boot/grub/grub.conf
numa=off
多实例MySQL可通过numa绑定指定cpu
numactl --hardware
numactl -cpubind=0-localalloc
tips:
MySQL5.7版本推出了一个参数叫innodb_numa_interleave 默认off
很奇怪,5.7.9就说可以设置为interleave,但是到现在为止还是没这个参数,要自己编译才会有,二进制版本是没有的,5.7.17已经OK
另外请把swap关掉
echo "vm.swappiness=0" >> /etc/sysctl.conf
3.2 网卡软中断
qps不超过一万基本上遇不到,淘宝双十一一台机器qps达到40w,现在可以跑到100w,这时候网卡就是瓶颈
这个优化通常不在数据库中做,数据库打不满CPU,一般在redis和memcached中做
top看下,cpu某个核的soft非常高,cpu要做上下文切换,会把整个性能拖慢,特别是在缓存系统中
解决方案:
启用网卡多队列,跑谷歌的一个脚本,set_irq_affinity.sh
service irqbalance stop 操作系统自带的中断平衡的服务关掉,它并不能平衡
3.3 RAID卡
现在一般都是lsi的raid卡
BBU
Battery Back Unit,非低端RAID卡都带BBU,需要电池保证写入的可靠性,电池有充放电时间
RAID卡缓存
Write Backup、Write Through,写缓存并非默认开启,打开性能会好很多
查看电量百分比
megacli -AdpBbuCmd -GetBbuStatus -aALL |grep "Relative State of Charge"
查看充电状态
megacli -AdpBbuCmd -GetBbuStatus -aALL |grep "Charger Status"
查看缓存策略
megacli -LDGetProp -LAll -a0
3.4 SSD
磁盘调度算法设置为:deadline或者noop
innodb存储引擎设置
innodb_flush_neighbors = 0
innodb_log_file_size = 4G
Ⅳ、文件系统与操作系统
4.1 文件系统
- 推荐xfs/ext4
noatime可以提升5%,nobarrier,接raid卡影响不大,不接的话,影响比较大,写到存储的缓存就返回,并不一定要写到存储系统,ssd内置了cache,写到cache就可以了
4.2 操作系统
- 推荐linux、关闭swap
- noatime、nobarrier
mount -o noatime,nobarrier /dev/sdb1/data
MySQL优化小结的更多相关文章
- mysql优化, 删除数据后物理空间未释放(转载)
mysql优化, 删除数据后物理空间未释放(转载) OPTIMIZE TABLE 当您的库中删除了大量的数据后,您可能会发现数据文件尺寸并没有减小.这是因为删除操作后在数据文件中留下碎片所致.OPTI ...
- MySQL优化聊两句
原文地址:http://www.cnblogs.com/verrion/p/mysql_optimised.html MySQL优化聊两句 MySQL不多介绍,今天聊两句该如何优化以及从哪些方面入手, ...
- 0104探究MySQL优化器对索引和JOIN顺序的选择
转自http://www.jb51.net/article/67007.htm,感谢博主 本文通过一个案例来看看MySQL优化器如何选择索引和JOIN顺序.表结构和数据准备参考本文最后部分" ...
- mysql 优化
1.存储过程造数据 CREATE DEFINER=`root`@`localhost` PROCEDURE `generate_test_data`(`n` int) begin declare i ...
- mysql优化笔记之分页
过年闲得蛋疼,于是看看mysql优化,看了网上好多关于分页的优化方法,但是呢,我亲自试上一把的时候,没有出现他们说的现象...难道是我的机器问题么? 下面看看我的实践记录,希望看到的加入进来交流一下O ...
- MySQL优化概述
一. MySQL优化要点 MySQL优化是一门复杂的综合性技术,主要包括: 1 表的设计合理化(符合 3NF,必要时允许数据冗余) 2.1 SQL语句优化(以查询为主) 2.2 适当添加索引(主键索引 ...
- MySQL优化实例
这周就要从泰笛离职了,在公司内部的wiki上,根据公司实际的项目,写了一些mysql的优化方法,供小组里的小伙伴参考下,没想到大家的热情很高,还专门搞了个ppt讲解了一下. 举了三个大家很容易犯错的地 ...
- Mysql优化系列(2)--通用化操作梳理
前面有两篇文章详细介绍了mysql优化举措:Mysql优化系列(0)--总结性梳理Mysql优化系列(1)--Innodb引擎下mysql自身配置优化 下面分类罗列下Mysql性能优化的一些技巧,熟练 ...
- mysql优化记录
老板反应项目的反应越来越慢,叫优化一下,顺便学习总结一下mysql优化. 不同引擎的优化,myisam读的效果好,写的效率差,使用场景 非事务型应用只读类应用空间类应用 Innodb的特性,innod ...
随机推荐
- 【MVP时间】5节课助你破解物联网硬件接入难点
视频播放链接:https://mvp.aliyun.com/topic/10?spm=5176.8961170.detail.18.31a3yK4zyK4zUc 1.会上网的鸡,有啥不一样? http ...
- 通过apicloud实现的混合开发App的Demo
技术:html+css+js+apicloud封装的api 概述 本Demo主要基本的HTML+CSS+JS实现的混合App,通过第三方平台apicloud主要页面有首页资讯+商城,目前数据都是静 ...
- Python内置的urllib模块不支持https协议的解决办法
Django站点使用django_cas接入SSO(单点登录系统),配置完成后登录,抛出“urlopen error unknown url type: https”异常.寻根朔源发现是python内 ...
- 【VS2019】F12跳转到源码,关闭浏览器不停止项目【转】
[VS2019]F12跳转到源码 1.工具->选项 2.文本编辑器->C#->高级->勾选支持导航到反编译源码 3.关闭浏览器不停止项目
- 动态绑定事件到特定dom元素上,包含新增加的
$('body').on('click', 'a.detail-data', function (e) { //动态事件绑定 为body元素下所有的a.detail-data元素添加一个事件 包括新增 ...
- 19.翻译系列:EF 6中定义自定义的约定【EF 6 Code-First约定】
原文链接:https://www.entityframeworktutorial.net/entityframework6/custom-conventions-codefirst.aspx EF 6 ...
- 企业和个人都需要的终极跨平台全端解决方案 UniApp
相信大家在平时开发过程中都会遇到这两类问题: 很多中小型企业要快速开发一个产品,这个产品至少需要覆盖平台范围为:ios.Android.web/H5.微信/支付宝小程序,那么需要的投入的人力成本.时间 ...
- TensorFlow官网无法访问
相信很多搞深度学习的小伙伴最近都为访问不了 TensorFlow官网 而苦恼吧!虽然网上也给出了一些方法,但是却缺少一个很重要的步骤.接下来,我就给大家讲解一个完整的过程,大牛绕过. 1.更改Host ...
- Kafka Docker集群搭建
1. Zookeeper下载 http://apache.org/dist/zookeeper/ http://mirrors.hust.edu.cn/apache/zookeeper/zookeep ...
- hdoj:2058
#include <iostream> #include <cmath> #include <vector> using namespace std; stru ...