Hive-1.2.1_03_DDL操作
Hive官方文档:Home-UserDocumentation
Hive DDL官方文档:LanguageManual DDL
参考文章:Hive 用户指南
注意:各个语句的版本时间,有的是在 hive-1.2.1 之后才有的,这些语句我们在hive-1.2.1中是不能使用的。
注意:本文写的都是常用的知识点,更多细节请参考官网。
常用命令
select current_database(); # 当前使用哪个库
show databases; # 显示所有库名
show tables; # 显示当前库有哪些表
describe extended talbe_name; # 表的扩展信息 和 describe formatted talbe_name; 类似
describe formatted talbe_name; # 推荐使用★★★ 如:describe formatted t_sz01; # 描述表信息,也可知道是 MANAGED_TABLE 还是 EXTERNAL_TABLE
describe database test_db; # 查看数据库信息
show partitions t_sz03_part; # 查看分区表的分区信息
说明
本文章使用Hive操作时,可能是 HIVE的命令行,也可能是beeline
所以看到2种风格的命令行,请不要惊讶。
1. DDL- Database操作
1.1. Create Database
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name
[COMMENT database_comment]
[LOCATION hdfs_path]
[WITH DBPROPERTIES (property_name=property_value, ...)];
创建库
# 创建库
create database if not exists test_db
comment 'my frist db'; : jdbc:hive2://mini01:10000> describe database test_db; # 建库信息
+----------+--------------+----------------------------------------------------+-------------+-------------+-------------+--+
| db_name | comment | location | owner_name | owner_type | parameters |
+----------+--------------+----------------------------------------------------+-------------+-------------+-------------+--+
| test_db | my frist db | hdfs://mini01:9000/user/hive/warehouse/test_db.db | yun | USER | |
+----------+--------------+----------------------------------------------------+-------------+-------------+-------------+--+
1.2. Drop Database
DROP (DATABASE|SCHEMA) [IF EXISTS] database_name [RESTRICT|CASCADE];
# 默认为 RESTRICT,如果库下有表就不能删除库;如果使用 CASCADE 那么即使库下有表,也会删除库下的表和库。
1.3. Use Database
USE database_name; # 使用哪个库
USE DEFAULT; # 使用默认库
例如:
hive (default)> show databases; # 查询有哪些库
OK
default
test001
test_db
zhang
Time taken: 0.016 seconds, Fetched: row(s)
hive (default)> use test_db; # 使用哪个库
OK
Time taken: 0.027 seconds
hive (test_db)> select current_database(); # 当前使用的是哪个库
OK
test_db
Time taken: 1.232 seconds, Fetched: row(s)
2. DDL-Table
2.1. Create Table
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name
[(col_name data_type [COMMENT col_comment], ... [constraint_specification])]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] # PARTITIONED 分割
[CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS] # CLUSTERED 分群 BUCKETS 桶
[SKEWED BY (col_name, col_name, ...)
ON ((col_value, col_value, ...), (col_value, col_value, ...), ...)
[STORED AS DIRECTORIES]
[
[ROW FORMAT row_format]
[STORED AS file_format]
| STORED BY 'storage.handler.class.name' [WITH SERDEPROPERTIES (...)]
]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)] # TBLPROPERTIES 表属性
[AS select_statement]; -- (Note: Available in Hive 0.5.0 and later; not supported for external tables) CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name
LIKE existing_table_or_view_name
[LOCATION hdfs_path]; data_type
: primitive_type
| array_type
| map_type
| struct_type
| union_type -- (Note: Available in Hive 0.7.0 and later) primitive_type
: TINYINT
| SMALLINT
| INT
| BIGINT
| BOOLEAN
| FLOAT
| DOUBLE
| DOUBLE PRECISION -- (Note: Available in Hive 2.2.0 and later)
| STRING
| BINARY -- (Note: Available in Hive 0.8.0 and later)
| TIMESTAMP -- (Note: Available in Hive 0.8.0 and later)
| DECIMAL -- (Note: Available in Hive 0.11.0 and later)
| DECIMAL(precision, scale) -- (Note: Available in Hive 0.13.0 and later)
| DATE -- (Note: Available in Hive 0.12.0 and later)
| VARCHAR -- (Note: Available in Hive 0.12.0 and later)
| CHAR -- (Note: Available in Hive 0.13.0 and later) array_type
: ARRAY < data_type > map_type
: MAP < primitive_type, data_type > struct_type
: STRUCT < col_name : data_type [COMMENT col_comment], ...> union_type
: UNIONTYPE < data_type, data_type, ... > -- (Note: Available in Hive 0.7.0 and later) row_format
: DELIMITED [FIELDS TERMINATED BY char [ESCAPED BY char]] [COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]
[NULL DEFINED AS char] -- (Note: Available in Hive 0.13 and later)
| SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)] file_format:
: SEQUENCEFILE
| TEXTFILE -- (Default, depending on hive.default.fileformat configuration)
| RCFILE -- (Note: Available in Hive 0.6.0 and later)
| ORC -- (Note: Available in Hive 0.11.0 and later)
| PARQUET -- (Note: Available in Hive 0.13.0 and later)
| AVRO -- (Note: Available in Hive 0.14.0 and later)
| JSONFILE -- (Note: Available in Hive 4.0.0 and later)
| INPUTFORMAT input_format_classname OUTPUTFORMAT output_format_classname constraint_specification:
: [, PRIMARY KEY (col_name, ...) DISABLE NOVALIDATE ]
[, CONSTRAINT constraint_name FOREIGN KEY (col_name, ...) REFERENCES table_name(col_name, ...) DISABLE NOVALIDATE
注意:使用CREATE TABLE建表时,如果该表或视图已存在,那么会报错。可以使用IF NOT EXISTS 跳过该错误。
- 表名和列名大小写不明感,但是SerDe(Serializer/Deserializer的简写。hive使用Serde进行行对象的序列与反序列化)和property (属性)名大小写敏感。
- 表和列注释是字符串文本(需要单引号)。
- 一个表的创建没有使用EXTERNAL子句,那么被称为managed table(托管表);因为Hive管理它的数据。查看一个表是托管的还是外部的,可以通过 DESCRIBE EXTENDED 或者 table_name 查看tableType获知。【或者通过describe formatted table_name; 查看】 【参见示例1】
- TBLPROPERTIES 子句允许你使用自己的元数据key/value【键/值对】去标记表定义。一些预定义的表属性也存在,比如last_modified_user和last_modified_time,它们是由Hive自动添加和管理的。【参见示例1】
# 示例1
: jdbc:hive2://mini01:10000> create table t_sz05 (id int, name string) tblproperties ('key001'='value1', 'key200'='value200'); # 创建表
No rows affected (0.224 seconds)
: jdbc:hive2://mini01:10000> describe formatted t_sz05; # 查看表信息
+-------------------------------+-------------------------------------------------------------+-----------------------+--+
| col_name | data_type | comment |
+-------------------------------+-------------------------------------------------------------+-----------------------+--+
| # col_name | data_type | comment |
| | NULL | NULL |
| id | int | |
| name | string | |
| | NULL | NULL |
| # Detailed Table Information | NULL | NULL |
| Database: | zhang | NULL |
| Owner: | yun | NULL |
| CreateTime: | Sat Jul :: CST | NULL |
| LastAccessTime: | UNKNOWN | NULL |
| Protect Mode: | None | NULL |
| Retention: | | NULL |
| Location: | hdfs://mini01:9000/user/hive/warehouse/zhang.db/t_sz05 | NULL |
| Table Type: | MANAGED_TABLE 【# 如果是外部表,则为EXTERNAL_TABLE】 | NULL |
| Table Parameters: | NULL | NULL |
| | key001 【# 自定义】 | value1 |
| | key200 【# 自定义】 | value200 |
| | transient_lastDdlTime | |
| | NULL | NULL |
| # Storage Information | NULL | NULL |
| SerDe Library: | org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe | NULL |
| InputFormat: | org.apache.hadoop.mapred.TextInputFormat | NULL |
| OutputFormat: | org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat | NULL |
| Compressed: | No | NULL |
| Num Buckets: | - | NULL |
| Bucket Columns: | [] | NULL |
| Sort Columns: | [] | NULL |
| Storage Desc Params: | NULL | NULL |
| | serialization.format | |
+-------------------------------+-------------------------------------------------------------+-----------------------+--+
rows selected (0.153 seconds)
2.1.1. Managed Table
建表
# 可以通过 describe formatted table_name; # 查看表信息
hive (test_db)> create table t_sz01 (id int, name string comment 'person name')
comment 'a table of name'
row format delimited fields terminated by ',';
OK
Time taken: 0.311 seconds
hive (test_db)> show tables;
OK
t_sz01
Time taken: 0.031 seconds, Fetched: row(s)
通过 desc formatted t_sz01; 中的信息可知: Location: 为 hdfs://mini01:9000/user/hive/warehouse/test_db.db/t_sz01
添加表数据
[yun@mini01 hive]$ pwd
/app/software/hive
[yun@mini01 hive]$ cat t_sz01.dat
,zhnagsan
,李四
,wangwu
,赵六
,sunqi
,周八
,kkkkk
,zzzzz
[yun@mini01 hive]$ cp -a t_sz01.dat t_sz01.dat2 # 复制一份
[yun@mini01 hive]$ hadoop fs -put t_sz01.dat /user/hive/warehouse/test_db.db/t_sz01 # 数据上传
[yun@mini01 hive]$ hadoop fs -put t_sz01.dat2 /user/hive/warehouse/test_db.db/t_sz01 # 数据上传
[yun@mini01 hive]$ hadoop fs -ls /user/hive/warehouse/test_db.db/t_sz01 # 表下可以有多个数据文件
Found items
-rw-r--r-- yun supergroup -- : /user/hive/warehouse/test_db.db/t_sz01/t_sz01.dat
-rw-r--r-- yun supergroup -- : /user/hive/warehouse/test_db.db/t_sz01/t_sz01.dat2
通过hive查看数据
: jdbc:hive2://mini01:10000> select * from t_sz01;
+------------+--------------+--+
| t_sz01.id | t_sz01.name |
+------------+--------------+--+
| | zhnagsan |
| | 李四 |
| | wangwu |
| | 赵六 |
| | sunqi |
| | 周八 |
| | kkkkk |
| | zzzzz |
| | zhnagsan |
| | 李四 |
| | wangwu |
| | 赵六 |
| | sunqi |
| | 周八 |
| | kkkkk |
| | zzzzz |
+------------+--------------+--+
rows selected (0.159 seconds)
2.1.2. External Tables
外表就是自己提供一个LOCATION,而不使用默认的表位置。并且删除该表时,表中的数据是不会删除的。
建表
# 其中location也可省略 hdfs://mini01:9000 改为 /user02/hive/database/ext_table
# 其中如果location目录不存在,那么hive会创建
hive (test_db)> create external table t_sz02_ext (id int, name string)
comment 'a ext table'
row format delimited fields terminated by '\t'
location 'hdfs://mini01:9000/user02/hive/database/ext_table';
OK
Time taken: 0.065 seconds
hive (test_db)> show tables;
OK
t_sz01
t_sz02_ext
Time taken: 0.03 seconds, Fetched: row(s)
: jdbc:hive2://mini01:10000> select * from t_sz02_ext; # 无数据
+----------------+------------------+--+
| t_sz02_ext.id | t_sz02_ext.name |
+----------------+------------------+--+
+----------------+------------------+--+
No rows selected (0.094 seconds) # 通过desc formatted t_sz02_ext; 可能查询表的Location,得到下面的信息
# hdfs://mini01:9000/user02/hive/database/ext_table
添加表数据
[yun@mini01 hive]$ pwd
/app/software/hive
[yun@mini01 hive]$ ll
total
-rw-rw-r-- yun yun Jul : sz.dat
-rw-rw-r-- yun yun Jul : t_sz01.dat
-rw-rw-r-- yun yun Jul : t_sz02_ext.dat
[yun@mini01 hive]$ cat t_sz02_ext.dat # 最后有一行空行
刘晨
王敏
张立
刘刚
孙庆
易思玲
李娜
梦圆圆 [yun@mini01 hive]$ hadoop fs -put t_sz02_ext.dat /user02/hive/database/ext_table # 上传数据
[yun@mini01 hive]$ hadoop fs -ls /user02/hive/database/ext_table
Found items
-rw-r--r-- yun supergroup -- : /user02/hive/database/ext_table/t_sz02_ext.dat
通过hive查看数据
: jdbc:hive2://mini01:10000> select * from t_sz02_ext;
+----------------+------------------+--+
| t_sz02_ext.id | t_sz02_ext.name |
+----------------+------------------+--+
| | 刘晨 |
| | 王敏 |
| | 张立 |
| | 刘刚 |
| | 孙庆 |
| | 易思玲 |
| | 李娜 |
| | 梦圆圆 |
| NULL | NULL | # 原因是数据中,最后一行为空行
+----------------+------------------+--+
rows selected (0.14 seconds)
2.1.3. Partitioned Tables
分区表(Partitioned tables)可以使用 PARTITIONED BY 子句。一个表可以有一个或多个分区列,并且为每个分区列中的不同值组合创建一个单独的数据目录。
当创建一个分区表,你得到这样的错误:“FAILED: Error in semantic analysis: Column repeated in partitioning columns,【失败:语义分析错误:分区列重复列】”。意味着你试图在表的本身数据中包含分区列。你可能确实定义了列。但是,您创建的分区可以生成一个可以查询的伪列,因此必须将表的列重命名为其他(那样用户不会查询)。
例如,假设原始未分区表有三列:id、date和name。
id int,
date date,
name varchar
现在要按日期分区。你的Hive定义可以使用 "dtDontQuery"作为列名,以便 "date" 可以被用作分区(和查询)。
create table table_name (
id int,
dtDontQuery string,
name string
)
partitioned by (date string)
现在你的用户仍然查询"where date = '...'",但是第二列dtDontQuery将保存原始值。
建表
# 不能使用date作为表的字段【列】,因为date是关键字
hive (test_db)> create table t_sz03_part (id int, name string)
comment 'This is a partitioned table'
partitioned by (dt string, country string)
row format delimited fields terminated by ',';
添加数据
[yun@mini01 hive]$ pwd
/app/software/hive
[yun@mini01 hive]$ cat t_sz03_20180711.dat1
,张三_20180711
,lisi_20180711
,Wangwu_20180711
[yun@mini01 hive]$ cat t_sz03_20180711.dat2
,Tom_20180711
,Dvid_20180711
,cherry_20180711
[yun@mini01 hive]$ cat t_sz03_20180712.dat1
,张三_20180712
,lisi_20180712
,Wangwu_20180712
[yun@mini01 hive]$ cat t_sz03_20180712.dat2
,Tom_20180712
,Dvid_20180712
,cherry_20180712
#### 在Hive中导入数据
hive (test_db)> load data local inpath '/app/software/hive/t_sz03_20180711.dat1' into table t_sz03_part partition (dt='', country='CN');
Loading data to table test_db.t_sz03_part partition (dt=, country=CN)
Partition test_db.t_sz03_part{dt=, country=CN} stats: [numFiles=, numRows=, totalSize=, rawDataSize=]
OK
Time taken: 0.406 seconds
hive (test_db)> load data local inpath '/app/software/hive/t_sz03_20180711.dat2' into table t_sz03_part partition (dt='', country='US');
Loading data to table test_db.t_sz03_part partition (dt=, country=US)
Partition test_db.t_sz03_part{dt=, country=US} stats: [numFiles=, numRows=, totalSize=, rawDataSize=]
OK
Time taken: 0.453 seconds
hive (test_db)> load data local inpath '/app/software/hive/t_sz03_20180712.dat1' into table t_sz03_part partition (dt='', country='CN');
Loading data to table test_db.t_sz03_part partition (dt=, country=CN)
Partition test_db.t_sz03_part{dt=, country=CN} stats: [numFiles=, numRows=, totalSize=, rawDataSize=]
OK
Time taken: 0.381 seconds
hive (test_db)> load data local inpath '/app/software/hive/t_sz03_20180712.dat2' into table t_sz03_part partition (dt='', country='US');
Loading data to table test_db.t_sz03_part partition (dt=, country=US)
Partition test_db.t_sz03_part{dt=, country=US} stats: [numFiles=, numRows=, totalSize=, rawDataSize=]
OK
Time taken: 0.506 seconds
浏览器访问
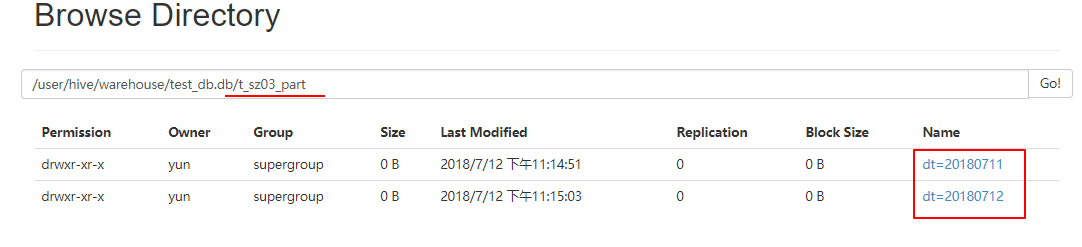

通过hive查看数据
: jdbc:hive2://mini01:10000> select * from t_sz03_part;
+-----------------+-------------------+-----------------+----------------------+--+
| t_sz03_part.id | t_sz03_part.name | t_sz03_part.dt | t_sz03_part.country |
+-----------------+-------------------+-----------------+----------------------+--+
| | 张三_20180711 | | CN |
| | lisi_20180711 | | CN |
| | Wangwu_20180711 | | CN |
| | Tom_20180711 | | US |
| | Dvid_20180711 | | US |
| | cherry_20180711 | | US |
| | 张三_20180712 | | CN |
| | lisi_20180712 | | CN |
| | Wangwu_20180712 | | CN |
| | Tom_20180712 | | US |
| | Dvid_20180712 | | US |
| | cherry_20180712 | | US |
+-----------------+-------------------+-----------------+----------------------+--+
rows selected (0.191 seconds)
: jdbc:hive2://mini01:10000> show partitions t_sz03_part; # 查看分区表的分区信息
+-------------------------+--+
| partition |
+-------------------------+--+
| dt=/country=CN |
| dt=/country=US |
| dt=/country=CN |
| dt=/country=US |
+-------------------------+--+
rows selected (0.164 seconds)
2.1.4. Create Table As Select (CTAS)
表还可以由一个create-table-as-select (CTAS)语句中的查询结果创建和填充。CTAS创建的表是原子的,这意味着在填充所有查询结果之前,其他用户看不到该表。因此,其他用户要么看到表的完整结果,要么根本看不到表。
CTAS限制:
目标表不能是分区表
目标表不能是外部表
目标表不能是分桶表
这里的目标表指的是要创建的表。
# 示例:
CREATE TABLE new_key_value_store
ROW FORMAT SERDE "org.apache.hadoop.hive.serde2.columnar.ColumnarSerDe"
STORED AS RCFile
AS
SELECT (key % ) new_key, concat(key, value) key_value_pair
FROM key_value_store
SORT BY new_key, key_value_pair;
实例
hive (test_db)> create table t_sz02_ext_new
row format delimited fields terminated by '#'
AS
SELECT id , concat(name, '_', id) name2
FROM t_sz02_ext
SORT BY name2; : jdbc:hive2://mini01:10000> show tables;
+-----------------+--+
| tab_name |
+-----------------+--+
| t_sz01 |
| t_sz02_ext |
| t_sz02_ext_new |
| t_sz03_part |
| t_sz100_ext |
| t_sz101_ext |
+-----------------+--+
rows selected (0.069 seconds)
: jdbc:hive2://mini01:10000> select * from t_sz02_ext_new;
+--------------------+-----------------------+--+
| t_sz02_ext_new.id | t_sz02_ext_new.name2 |
+--------------------+-----------------------+--+
| NULL | NULL |
| | 刘刚_4 |
| | 刘晨_1 |
| | 孙庆_5 |
| | 张立_3 |
| | 易思玲_6 |
| | 李娜_7 |
| | 梦圆圆_8 |
| | 王敏_2 |
+--------------------+-----------------------+--+
rows selected (0.094 seconds) # 其中路径location可以通过desc formatted t_sz02_ext_new; 获取
hive (test_db)> dfs -ls /user/hive/warehouse/test_db.db/t_sz02_ext_new/;
Found items
-rwxr-xr-x yun supergroup -- : /user/hive/warehouse/test_db.db/t_sz02_ext_new/000000_0
hive (test_db)> dfs -cat /user/hive/warehouse/test_db.db/t_sz02_ext_new/000000_0;
\N#\N
#刘刚_4
#刘晨_1
#孙庆_5
#张立_3
#易思玲_6
#李娜_7
#梦圆圆_8
#王敏_2
hdfs查看
# 其中路径location可以通过desc formatted t_sz02_ext_new; 获取
[yun@mini01 hive]$ hadoop fs -ls /user/hive/warehouse/test_db.db/t_sz02_ext_new;
Found items
-rwxr-xr-x yun supergroup -- : /user/hive/warehouse/test_db.db/t_sz02_ext_new/000000_0
[yun@mini01 hive]$ hadoop fs -cat /user/hive/warehouse/test_db.db/t_sz02_ext_new/000000_0
\N#\N
#刘刚_4
#刘晨_1
#孙庆_5
#张立_3
#易思玲_6
#李娜_7
#梦圆圆_8
#王敏_2
2.1.5. Create Table Like
拷贝一个已存在的表结构作为一个新表
CREATE TABLE empty_key_value_store
LIKE key_value_store [TBLPROPERTIES (property_name=property_value, ...)];
实例
hive (test_db)> create table t_sz03_part_new
like t_sz03_part tblproperties ('proper1'='value1', 'proper2'='value2');
OK
Time taken: 0.083 seconds
: jdbc:hive2://mini01:10000> select * from t_sz03_part_new; # 只复制表结构,不复制内容
+---------------------+-----------------------+---------------------+--------------------------+--+
| t_sz03_part_new.id | t_sz03_part_new.name | t_sz03_part_new.dt | t_sz03_part_new.country |
+---------------------+-----------------------+---------------------+--------------------------+--+
+---------------------+-----------------------+---------------------+--------------------------+--+
No rows selected (0.087 seconds)
hive (test_db)> create table t_sz04_like
like t_sz02_ext tblproperties ('proper1'='value1', 'proper2'='value2');
No rows affected (0.153 seconds) : jdbc:hive2://mini01:10000> select * from t_sz04_like;
+-----------------+-------------------+--+
| t_sz04_like.id | t_sz04_like.name |
+-----------------+-------------------+--+
+-----------------+-------------------+--+
通过desc formatted tab_name; 可以看到,t_sz03_part 和 t_sz03_part_new 的表结构是一样的。 只是tblproperties 不一样而已。
如果like对象即使是一个外部表,那么生成的表也是MANAGED_TABLE,。
2.1.6. Bucketed Sorted Tables
CREATE TABLE page_view(viewTime INT, userid BIGINT,
page_url STRING, referrer_url STRING,
ip STRING COMMENT 'IP Address of the User')
COMMENT 'This is the page view table'
PARTITIONED BY(dt STRING, country STRING)
CLUSTERED BY(userid) SORTED BY(viewTime) INTO BUCKETS
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\001'
COLLECTION ITEMS TERMINATED BY '\002'
MAP KEYS TERMINATED BY '\003'
STORED AS SEQUENCEFILE;
CLUSTERED BY
对于每一个表(table)或者分区, Hive可以进一步组织成桶,也就是说桶是更为细粒度的数据范围划分。Hive也是 针对某一列进行桶的组织。Hive采用对列值哈希,然后除以桶的个数求余的方式决定该条记录存放在哪个桶当中。
把表(或者分区)组织成桶(Bucket)有两个理由:
(1)获得更高的查询处理效率。桶为表加上了额外的结构,Hive 在处理有些查询时能利用这个结构。具体而言,连接两个在(包含连接列的)相同列上划分了桶的表,可以使用 Map 端连接 (Map-side join)高效的实现。比如JOIN操作。对于JOIN操作两个表有一个相同的列,如果对这两个表都进行了桶操作。那么将保存相同列值的桶进行JOIN操作就可以,可以大大较少JOIN的数据量。
(2)使取样(sampling)更高效。在处理大规模数据集时,在开发和修改查询的阶段,如果能在数据集的一小部分数据上试运行查询,会带来很多方便。
注意点
1、order by 会对输入做全局排序,因此只有一个reducer,会导致当输入规模较大时,需要较长的计算时间。
2、sort by不是全局排序,其在数据进入reducer前完成排序。因此,如果用sort by进行排序,并且设置mapred.reduce.tasks>1,则sort by只保证每个reducer的输出有序,不保证全局有序。
3、distribute by(字段)根据指定的字段将数据分到不同的reducer,且分发算法是hash散列。
4、Cluster by(字段)除了具有Distribute by的功能外,还会对该字段进行排序。
因此,如果分桶和sort字段是同一个时,此时,cluster by = distribute by + sort by
说明:是根据表查询数据结果向分桶表中插入数据。
分桶表的作用:最大的作用是用来提高join操作的效率;
(思考这个问题:
select a.id,a.name,b.addr from a join b on a.id = b.id;
如果a表和b表已经是分桶表,而且分桶的字段是id字段
做这个join操作时,还需要全表做笛卡尔积吗?)
实例
# 创建分桶表
hive (test_db)> create table t_sz05_buck (id int, name string)
clustered by(id) sorted by(id) into buckets
row format delimited fields terminated by ',';
OK
Time taken: 0.267 seconds
: jdbc:hive2://mini01:10000> select * from t_sz05_buck;
+-----------------+-------------------+--+
| t_sz05_buck.id | t_sz05_buck.name |
+-----------------+-------------------+--+
+-----------------+-------------------+--+
No rows selected (0.095 seconds)
准备数据
[yun@mini01 hive]$ pwd
/app/software/hive
[yun@mini01 hive]$ cat t_sz05_buck.dat
,mechanics
,mechanical engineering
,Instrument Science and technology
,Material science and Engineering
,Dynamic engineering and Engineering Thermophysics
,Electrical engineering
,Control science and Engineering
,Computer science and technology
,Architecture
,irrigation works
,Nuclear science and technology
,Environmental Science and Engineering
,Urban and rural planning
,Landscape architecture
,Electronic Science and technology
,Information and Communication Engineering
,Civil Engineering
,Chemical engineering and technology
,software engineering
,biomedical engineering
,Safety science and Engineering
,Aeronautical and Astronautical Science and Technology
,Transportation Engineering
,Optical engineering
############## 将数据导入hive中的一个普通表
hive (test_db)> create table t_sz05 (id int, name string)
row format delimited fields terminated by ',';
OK
Time taken: 0.091 seconds
hive (test_db)> load data local inpath '/app/software/hive/t_sz05_buck.dat' into table t_sz05; # 导入数据
Loading data to table test_db.t_sz05
Table test_db.t_sz05 stats: [numFiles=, totalSize=]
OK
Time taken: 0.276 seconds
hive (test_db)> select * from t_sz05; # 查询结果数据正常
……………………
指定分桶信息
# 原参数 在Hive命令行或者 : jdbc:hive2 命令行
hive (test_db)> set hive.enforce.bucketing;
hive.enforce.bucketing=false
hive (test_db)> set mapreduce.job.reduces;
mapreduce.job.reduces=-
# 指定参数
hive (test_db)> set hive.enforce.bucketing = true;
hive (test_db)> set mapreduce.job.reduces = ;
hive (test_db)> set hive.enforce.bucketing;
hive.enforce.bucketing=true
hive (test_db)> set mapreduce.job.reduces;
mapreduce.job.reduces=
######### 在查询 t_sz05 ###############################
: jdbc:hive2://mini01:10000> select id, name from t_sz05 cluster by (id);
INFO : Number of reduce tasks not specified. Defaulting to jobconf value of:
INFO : In order to change the average load for a reducer (in bytes):
INFO : set hive.exec.reducers.bytes.per.reducer=<number>
INFO : In order to limit the maximum number of reducers:
INFO : set hive.exec.reducers.max=<number>
INFO : In order to set a constant number of reducers:
INFO : set mapreduce.job.reduces=<number>
INFO : number of splits:
INFO : Submitting tokens for job: job_1531531561184_0009
INFO : The url to track the job: http://mini02:8088/proxy/application_1531531561184_0009/
INFO : Starting Job = job_1531531561184_0009, Tracking URL = http://mini02:8088/proxy/application_1531531561184_0009/
INFO : Kill Command = /app/hadoop/bin/hadoop job -kill job_1531531561184_0009
INFO : Hadoop job information for Stage-: number of mappers: ; number of reducers:
INFO : -- ::, Stage- map = %, reduce = %
INFO : -- ::, Stage- map = %, reduce = %, Cumulative CPU 1.42 sec
INFO : -- ::, Stage- map = %, reduce = %, Cumulative CPU 4.94 sec
INFO : -- ::, Stage- map = %, reduce = %, Cumulative CPU 11.03 sec
INFO : -- ::, Stage- map = %, reduce = %, Cumulative CPU 22.46 sec
INFO : MapReduce Total cumulative CPU time: seconds msec
INFO : Ended Job = job_1531531561184_0009
+-----+--------------------------------------------------------+--+
| id | name |
+-----+--------------------------------------------------------+--+
| | Material science and Engineering |
| | Computer science and technology |
| | Environmental Science and Engineering |
| | Information and Communication Engineering |
| | biomedical engineering |
| | Optical engineering |
| | mechanics |
| | Dynamic engineering and Engineering Thermophysics |
| | Architecture |
| | Urban and rural planning |
| | Civil Engineering |
| | Safety science and Engineering |
| | mechanical engineering |
| | Electrical engineering |
| | irrigation works |
| | Landscape architecture |
| | Chemical engineering and technology |
| | Aeronautical and Astronautical Science and Technology |
| | Instrument Science and technology |
| | Control science and Engineering |
| | Nuclear science and technology |
| | Electronic Science and technology |
| | software engineering |
| | Transportation Engineering |
+-----+--------------------------------------------------------+--+
rows selected (33.214 seconds)
向分桶表导入数据★★★★★
# 其中 select id, name from t_sz05 cluster by (id);
# 等价于 select id, name from t_sz05 distribute by (id) sort by (id);
# 因此,如果分桶和sort字段是同一个时,此时,cluster by = distribute by + sort by
# 当根据一个字段分桶,另一个字段排序时就可以使用后面的语句
: jdbc:hive2://mini01:10000> insert into table t_sz05_buck
select id, name from t_sz05 cluster by (id);
INFO : Number of reduce tasks determined at compile time:
INFO : In order to change the average load for a reducer (in bytes):
INFO : set hive.exec.reducers.bytes.per.reducer=<number>
INFO : In order to limit the maximum number of reducers:
INFO : set hive.exec.reducers.max=<number>
INFO : In order to set a constant number of reducers:
INFO : set mapreduce.job.reduces=<number>
INFO : number of splits:
INFO : Submitting tokens for job: job_1531531561184_0010
INFO : The url to track the job: http://mini02:8088/proxy/application_1531531561184_0010/
INFO : Starting Job = job_1531531561184_0010, Tracking URL = http://mini02:8088/proxy/application_1531531561184_0010/
INFO : Kill Command = /app/hadoop/bin/hadoop job -kill job_1531531561184_0010
INFO : Hadoop job information for Stage-: number of mappers: ; number of reducers:
INFO : -- ::, Stage- map = %, reduce = %
INFO : -- ::, Stage- map = %, reduce = %, Cumulative CPU 1.49 sec
INFO : -- ::, Stage- map = %, reduce = %, Cumulative CPU 10.35 sec
INFO : -- ::, Stage- map = %, reduce = %, Cumulative CPU 25.76 sec
INFO : -- ::, Stage- map = %, reduce = %, Cumulative CPU 32.36 sec
INFO : MapReduce Total cumulative CPU time: seconds msec
INFO : Ended Job = job_1531531561184_0010
INFO : Loading data to table test_db.t_sz05_buck from hdfs://mini01:9000/user/hive/warehouse/test_db.db/t_sz05_buck/.hive-staging_hive_2018-07-14_11-01-34_616_4744571023046037741-1/-ext-10000
INFO : Table test_db.t_sz05_buck stats: [numFiles=, numRows=, totalSize=, rawDataSize=]
No rows affected (33.762 seconds)
: jdbc:hive2://mini01:10000> select * from t_sz05_buck;
+-----------------+--------------------------------------------------------+--+
| t_sz05_buck.id | t_sz05_buck.name |
+-----------------+--------------------------------------------------------+--+
| | Material science and Engineering |
| | Computer science and technology |
| | Environmental Science and Engineering |
| | Information and Communication Engineering |
| | biomedical engineering |
| | Optical engineering |
| | mechanics |
| | Dynamic engineering and Engineering Thermophysics |
| | Architecture |
| | Urban and rural planning |
| | Civil Engineering |
| | Safety science and Engineering |
| | mechanical engineering |
| | Electrical engineering |
| | irrigation works |
| | Landscape architecture |
| | Chemical engineering and technology |
| | Aeronautical and Astronautical Science and Technology |
| | Instrument Science and technology |
| | Control science and Engineering |
| | Nuclear science and technology |
| | Electronic Science and technology |
| | software engineering |
| | Transportation Engineering |
+-----------------+--------------------------------------------------------+--+
rows selected (0.097 seconds)
浏览器访问
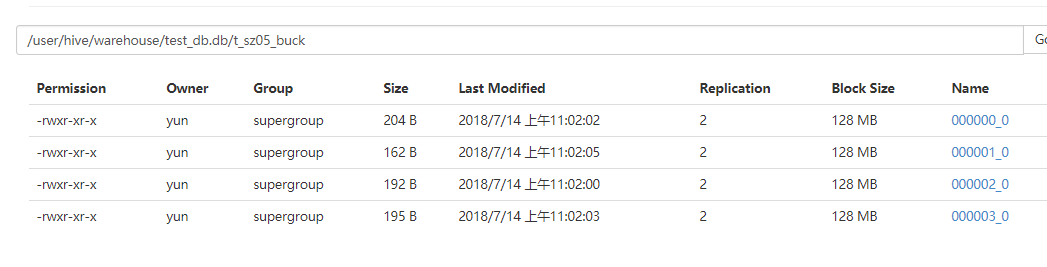
: jdbc:hive2://mini01:10000> dfs -cat /user/hive/warehouse/test_db.db/t_sz05_buck/000000_0;
+-----------------------------------------------+--+
| DFS Output |
+-----------------------------------------------+--+
| ,Material science and Engineering |
| ,Computer science and technology |
| ,Environmental Science and Engineering |
| ,Information and Communication Engineering |
| ,biomedical engineering |
| ,Optical engineering |
+-----------------------------------------------+--+
rows selected (0.016 seconds)
: jdbc:hive2://mini01:10000> dfs -cat /user/hive/warehouse/test_db.db/t_sz05_buck/000001_0;
+------------------------------------------------------+--+
| DFS Output |
+------------------------------------------------------+--+
| ,mechanics |
| ,Dynamic engineering and Engineering Thermophysics |
| ,Architecture |
| ,Urban and rural planning |
| ,Civil Engineering |
| ,Safety science and Engineering |
+------------------------------------------------------+--+
rows selected (0.015 seconds)
: jdbc:hive2://mini01:10000> dfs -cat /user/hive/warehouse/test_db.db/t_sz05_buck/000002_0;
+-----------------------------------------------------------+--+
| DFS Output |
+-----------------------------------------------------------+--+
| ,mechanical engineering |
| ,Electrical engineering |
| ,irrigation works |
| ,Landscape architecture |
| ,Chemical engineering and technology |
| ,Aeronautical and Astronautical Science and Technology |
+-----------------------------------------------------------+--+
rows selected (0.014 seconds)
: jdbc:hive2://mini01:10000> dfs -cat /user/hive/warehouse/test_db.db/t_sz05_buck/000003_0;
+---------------------------------------+--+
| DFS Output |
+---------------------------------------+--+
| ,Instrument Science and technology |
| ,Control science and Engineering |
| ,Nuclear science and technology |
| ,Electronic Science and technology |
| ,software engineering |
| ,Transportation Engineering |
+---------------------------------------+--+
rows selected (0.016 seconds)
2.1.7. Temporary Tables
一个表创建为一个临时表那么只对当前会话看见。数据将存储在用户的scratch目录中,并在会话结束时删除。
如果使用数据库中已经存在的永久表的数据库/表名创建临时表,那么在该会话中对该表的任何引用都将解析为临时表,而不是永久表。如果不删除临时表或将其重命名为不冲突的名称,用户将无法访问会话中的原始表。
临时表有以下限制:
分区列不支持
不支持创建索引
实例
: jdbc:hive2://mini01:10000> create temporary table t_sz06_temp (id int, name string)
: jdbc:hive2://mini01:10000> row format delimited fields terminated by ',';
No rows affected (0.062 seconds)
: jdbc:hive2://mini01:10000> select * from t_sz06_temp ;
+-----------------+-------------------+--+
| t_sz06_temp.id | t_sz06_temp.name |
+-----------------+-------------------+--+
+-----------------+-------------------+--+
No rows selected (0.042 seconds)
: jdbc:hive2://mini01:10000> load data local inpath '/app/software/hive/t_sz01.dat' into table t_sz06_temp ; # 导入数据
INFO : Loading data to table test_db.t_sz06_temp from file:/app/software/hive/t_sz01.dat
INFO : Table test_db.t_sz06_temp stats: [numFiles=, totalSize=]
No rows affected (0.09 seconds)
: jdbc:hive2://mini01:10000> select * from t_sz06_temp ;
+-----------------+-------------------+--+
| t_sz06_temp.id | t_sz06_temp.name |
+-----------------+-------------------+--+
| | zhnagsan |
| | 李四 |
| | wangwu |
| | 赵六 |
| | sunqi |
| | 周八 |
| | kkkkk |
| | zzzzz |
+-----------------+-------------------+--+
rows selected (0.062 seconds)
# 其中 Location为 hdfs://mini01:9000/tmp/hive/yun/4bf7c650-56ed-4f93-8a73-23420c7292a1/_tmp_space.db/158ad837-ee43-4870-9e34-6ad5cd4b292a
: jdbc:hive2://mini01:10000> desc formatted t_sz06_temp;
+-------------------------------+------------------------------------------------------------+-----------------------+--+
| col_name | data_type | comment |
+-------------------------------+------------------------------------------------------------+-----------------------+--+
| # col_name | data_type | comment |
| | NULL | NULL |
| id | int | |
| name | string | |
| | NULL | NULL |
| # Detailed Table Information | NULL | NULL |
| Database: | test_db | NULL |
| Owner: | yun | NULL |
| CreateTime: | Sat Jul :: CST | NULL |
| LastAccessTime: | UNKNOWN | NULL |
| Protect Mode: | None | NULL |
| Retention: | | NULL |
| Location: | hdfs://mini01:9000/tmp/hive/yun/UUID/_tmp_space.db/UUID | NULL |
| Table Type: | MANAGED_TABLE | NULL |
| Table Parameters: | NULL | NULL |
| | COLUMN_STATS_ACCURATE | true |
| | numFiles | |
| | totalSize | |
| | NULL | NULL |
| # Storage Information | NULL | NULL |
| SerDe Library: | org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe | NULL |
| InputFormat: | org.apache.hadoop.mapred.TextInputFormat | NULL |
| OutputFormat: | org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat | NULL |
| Compressed: | No | NULL |
| Num Buckets: | - | NULL |
| Bucket Columns: | [] | NULL |
| Sort Columns: | [] | NULL |
| Storage Desc Params: | NULL | NULL |
| | field.delim | , |
| | serialization.format | , |
+-------------------------------+------------------------------------------------------------+-----------------------+--+
rows selected (0.024 seconds)
2.1.8. Constraints【约束条件】
Hive包含对未验证的 主键和外键约束的支持。一些SQL工具在出现约束时生成更有效的查询。由于这些约束没有经过验证,所以上游系统需要在将数据加载到Hive之前确保数据的真实性。
# Example:
create table pk(id1 integer, id2 integer,
primary key(id1, id2) disable novalidate); create table fk(id1 integer, id2 integer,
constraint c1 foreign key(id1, id2) references pk(id2, id1) disable novalidate);
2.2. Drop Table
DROP TABLE [IF EXISTS] table_name [PURGE];
DROP TABLE 删除该表的元数据和数据。如果配置了 Trash那么数据实际移到了 .Trash/Current 目录(并且PURGE没有指定)。元数据完全丢失。
当删除一个 EXTERNAL表时,表的数据将不会从文件系统删除。
当删除视图引用的表时,不会给出任何警告。
表信息从元存储中被删除并且行数据也会被删除就像通过“hadoop dfs -rm”。多数情况下,这会导致表数据被移动到用户家目录中的.Trash文件夹中; 因此,错误地删除表的用户可以通过使用相同的模式重新创建表,重新创建任何必要的分区,然后使用Hadoop手动将数据移回原位,从而恢复丢失的数据。由于该解决方案依赖于底层实现,因此可能会随时间或跨安装设备进行更改;强烈建议用户不要随意删除表。
如果PURGE被指定,那么表数据不会移到.Trash/Current目录,因此如果是错误的DROP那么不能被恢复。purge 选项也可以使用表属性auto. cleanup指定
2.3. Truncate Table
TRUNCATE TABLE table_name [PARTITION partition_spec]; partition_spec:
: (partition_column = partition_col_value, partition_column = partition_col_value, ...)
从表或分区表删除所有的行。如果文件系统垃圾(Trash)可用那么行数据将进入垃圾站,否则将被删除。当前,目标表应该是本机/托管表,否则将抛出异常。用户可以指定部分partition_spec来一次截断多个分区,而省略partition_spec将截断表中的所有分区。
3. Alter Table/Partition/Column
Alter Table
Rename Table
Alter Table Properties
Alter Table Comment
Add SerDe Properties
Alter Table Storage Properties
Alter Table Skewed or Stored as Directories
Alter Table Skewed
Alter Table Not Skewed
Alter Table Not Stored as Directories
Alter Table Set Skewed Location
Alter Table Constraints
Additional Alter Table Statements
Alter Partition
Add Partitions
Dynamic Partitions
Rename Partition
Exchange Partition
Recover Partitions (MSCK REPAIR TABLE)
Drop Partitions
(Un)Archive Partition
Alter Either Table or Partition
Alter Table/Partition File Format
Alter Table/Partition Location
Alter Table/Partition Touch
Alter Table/Partition Protections
Alter Table/Partition Compact
Alter Table/Partition Concatenate
Alter Table/Partition Update columns
Alter Column
Rules for Column Names
Change Column Name/Type/Position/Comment
Add/Replace Columns
Partial Partition Specification
参见:Alter Table/Partition/Column
4. Show
Show Databases
Show Tables/Views/Partitions/Indexes
Show Tables
Show Views
Show Partitions
Show Table/Partition Extended
Show Table Properties
Show Create Table
Show Indexes
Show Columns
Show Functions
Show Granted Roles and Privileges
Show Locks
Show Conf
Show Transactions
Show Compactions
参见:Show
5. Describe
Describe Database
Describe Table/View/Column
Display Column Statistics
Describe Partition
参见:Describe
Hive-1.2.1_03_DDL操作的更多相关文章
- hive执行结果moveTask操作失败
hive执行结果moveTask操作失败 Apache Hive 2.1.0 ,在执行"INSERT OVERWRITE TABLE ...... select "或者 " ...
- Hive学习(三)Hive的Java客户端操作
Hive的Java客户端操作分为JDBC和Thrifit Client,首先启动Hive远程服务: hive --service hiveserver 一.JDBC 在MyEclipse中首先创建连接 ...
- Hive DDL、DML操作
• 一.DDL操作(数据定义语言)包括:Create.Alter.Show.Drop等. • create database- 创建新数据库 • alter database - 修改数据库 • dr ...
- Hive[5] HiveQL 数据操作
5.1 向管理表中装载数据 Hive 没有行级别的数据插入更新和删除操作,那么往表中装载数据的唯一途径就是使用一种“大量”的数据装载操作,或者通过其他方式仅仅将文件写入到正确的目录下: LOA ...
- Hive DDL及DML操作
一.修改表 增加/删除分区 语法结构 ALTER TABLE table_name ADD [IF NOT EXISTS] partition_spec [ LOCATION 'location1' ...
- HIVE的sql语句操作
Hive 是基于Hadoop 构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在hadoop 分布式文件系统中的数据,可以将结构 化的数据文件映射为一张数据库表,并提供完整的SQL查 ...
- hive表分区相关操作
Hive 表分区 Hive表的分区就是一个目录,分区字段不和表的字段重复 创建分区表: create table tb_partition(id string, name string) PARTIT ...
- Hive的两种操作模式
Hive的客户端操作 Hive的客户端操作 通过JDBC操作Hive 通过Thrift操作Hive 通过JDBC操作Hive 首先 Hive 启动远程服务 hive --service hiveser ...
- HDFS文件和HIVE表的一些操作
1. hadoop fs -ls 可以查看HDFS文件 后面不加目录参数的话,默认当前用户的目录./user/当前用户 $ hadoop fs -ls 16/05/19 10:40:10 WARN ...
随机推荐
- Spring Data Redis示例
说明 关于Redis:一个基于键值对存储的NoSQL内存数据库,可存储复杂的数据结构,如List, Set, Hashes. 关于Spring Data Redis:简称SDR, 能让Spring应用 ...
- Shell脚本 | 健壮性测试之空指针检查
通过 "adb shell am start" 遍历安卓应用所有的 Activity,可以检查是否存在空指针的情况. 以下为梳理后的测试流程: 通过 apktool 反编译 apk ...
- 深入理解kafka设计原理
最近开研究kafka,下面分享一下kafka的设计原理.kafka的设计初衷是希望作为一个统一的信息收集平台,能够实时的收集反馈信息,并需要能够支撑较大的数据量,且具备良好的容错能力. 1.持久性 k ...
- VS中C#的快捷键
Ctrl+E,D: 格式化全部代码 Ctrl+E,C / Ctrl+K,C: 注释选定内容 Ctrl+E,U / Ctrl+K,U: 取消选定注释内容 Ctrl+E,S: 查看空白 Ctrl+E,W: ...
- sealed关键字
1. sealed关键字 当对一个类应用 sealed 修饰符时,此修饰符会阻止其他类从该类继承.类似于Java中final关键字. 在下面的示例中,类 B 从类 A 继承,但是任何类都不 ...
- c# 生成自定义图片
using System.Drawing; using System.IO; using System.Drawing.Imaging; using System; namespace treads ...
- SqlServer--用代码创建和删除数据库和表
创建数据库,创建表,设置主键数据库的分离和附加MS SQLServer的每个数据库包含:1个主数据文件(.mdf)必须.1个事务日志文件(.ldf)必须.可以包含:任意多个次要数据文件(.ndf)多个 ...
- [android] 手机卫士读取联系人
获取ContentResolver内容解析器对象,通过getContentResolver()方法 调用ContentResolver对象的query()方法,得到raw_contacts表里面的数据 ...
- [Laravel] Laravel的基本数据库操作部分
[laravel] laravel的数据库配置 找到程序目录结构下.env文件 配置基本的数据库连接信息 DB_HOST=127.0.0.1 DB_PORT=3306 DB_DATABASE=blog ...
- Java8的lambda表达式和Stream API
一直在用JDK8 ,却从未用过Stream,为了对数组或集合进行一些排序.过滤或数据处理,只会写for循环或者foreach,这就是我曾经的一个写照. 刚开始写写是打基础,但写的多了,各种乏味,非过来 ...