进程池与线程池基本使用、协程理论与实操、IO模型、前端、BS架构、HTTP协议与HTML前戏
昨日内容回顾
- GIL全局解释器锁
1.在python解释器中 才有GIL的存在(只与解释器有关)
2.GIL本质上其实也是一把互斥锁(并发变串行 牺牲效率保证安全)
3.GIL的存在 是由于Cpython解释器中的内存管理不是线程安全的
内存管理》》》垃圾回收机制
4.在python中 同一个进程下的多个线程无法实现并行的(可以并发)
- 验证GIL中的各种特性
1.python代码要想被运行 必须先获取到解释器 但是解释器的获取需要抢夺和释放GIL全局解释器锁
剥夺CPU权限的两种情况:
01 执行时间过长
02 进入IO操作
2.互斥锁最好不要多次使用 尤其是存在多把锁的情况下
3.验证python多线程无法利用多核优势的情况下是否还有用
01 要先区分 任务类型是 计算密集型还是IO密集型
02 如果是计算密集型 那么开设多进程有优势
03 如果是IO密集型 那么开设多线程有优势
04 可以多进程多线程结合使用(效率更高)
- 进程池与线程池
1.池:
为了保证计算机硬件安全的情况下 提升程序的运行效率(硬件的发展远远跟不上软件的发展速度)
2.进程池:
提前开设好一堆进程 只需要朝池子中提交任务 任务会自动分配给空闲的进程处理 并且池子中的进程创建好了之后就不会更替
3.线程池:
提前开设好一堆线程 只需要朝池子中提交任务 任务会自动分配给空闲的线程处理 并且池子中的线程创建好了之后就不会更替
'''进程池线程池封装程度更高 不需要我们自己编写复杂的代码'''
今日内容概要
- 进程池与线程池的基本使用
- 协程理论与实操
- IO模型
- 前端介绍
内容详细
1、进程池与线程池基本使用
01 向进程池提交任务 异步获取结果
import time
import os
from concurrent.futures import ProcessPoolExecutor, ThreadPoolExecutor
# 创建进程池
pool = ProcessPoolExecutor(5) # 可以自定义进程数 也可以采用默认的策略
# 定义一个任务
def task(n):
print(n, os.getpid())
time.sleep(2)
return '>>%s'% n**2
# 往进程池提交任务
l = []
if __name__ == '__main__':
for i in range(20):
res = pool.submit(task, i) # pool.submit(task, i) 属于异步提交任务
l.append(res)
# 等待进程池中所有任务执行完毕之后 再获取各自任务的结果
pool.shutdown()
for i in l:
print(i.result()) # 获取任务执行结果 同步
02 向线程池提交任务 异步获取结果
import time
import os
from concurrent.futures import ProcessPoolExecutor, ThreadPoolExecutor
# 创建线程池
pool = ThreadPoolExecutor(5) # 可以自定义线程数 也可以采用默认的策略
# 定义一个任务
def task(n):
print(n, os.getpid())
time.sleep(2)
return '>>%s'% n**2
# 往线程池提交任务
l = []
for i in range(20):
res = pool.submit(task, i) # pool.submit(task, i) 属于异步提交任务
l.append(res)
# 等待进程池中所有任务执行完毕之后 再获取各自任务的结果
pool.shutdown()
for i in l:
print(i.result()) # 获取任务执行结果 同步
03 异步回调机制
import time
import os
from concurrent.futures import ProcessPoolExecutor, ThreadPoolExecutor
# 创建进程池与线程池
# pool = ThreadPoolExecutor(5) # 可以自定义线程数 也可以采用默认的策略
pool = ProcessPoolExecutor(5) # 可以自定义进程数 也可以采用默认的策略
# 定义一个任务
def task(n):
print(n, os.getpid())
time.sleep(2)
return '>>%s'% n**2
# 定义一个回调函数:异步提交完之后有结果自动调用该函数
def call_back(a):
print('异步回调函数 %s'% a.result()) # a task任务的返回值
if __name__ == '__main__':
for i in range(20):
res = pool.submit(task, i).add_done_callback(call_back) # pool.submit(task, i) 属于异步提交任务
"""
同步:提交完任务之后原地等待任务的返回结果 期间不做任何事
异步:提交完任务之后不愿地等待任务的返回结果 结果由异步回调机制自动反馈
在windows电脑中 如果是进程池的使用 需要在__main__方法下面
"""
2、协程理论与实操
# 1.进程
资源单位
# 2.线程
工作单位
# 3.协程
是程序员单方面意淫出来的名词>>>:单线程下实现并发
# 4.CPU被剥夺的条件
1.程序长时间占用
2.程序进入IO操作
# 5.并发
切换+保存状态
'''以往学习的是:多个任务(进程、线程)来回切换'''
# 6.欺骗CPU的行为
单线程下我们如果能够自己检测IO操作并且自己实现代码层面的切换
那么对于CPU而言我们这个程序就没有IO操作,CPU会尽可能的被占用
# 7.从代码层面实现 协程
第三方gevent模块:能够自主监测IO行为并切换
'''01 普通执行代码所需时间'''
from gevent import monkey;monkey.patch_all() # 固定代码格式加上之后才能检测所有的IO行为
import time
def play(name):
print('%s play 1' % name)
time.sleep(5)
print('%s play 2' % name)
def eat(name):
print('%s eat 1' % name)
time.sleep(3)
print('%s eat 2' % name)
start = time.time()
play('jason') # 正常的同步调用
eat('jason') # 正常的同步调用
print('主', time.time() - start) # 单线程下实现并发,提升效率
结果:
jason play 1
jason play 2
jason eat 1
jason eat 2
主 8.0690336227417
"""02 实现协程效果:单线程下实现并发"""
from gevent import monkey;monkey.patch_all() # 固定代码格式加上之后才能检测所有的IO行为
from gevent import spawn
import time
def play(name):
print('%s play 1' % name)
time.sleep(5)
print('%s play 2' % name)
def eat(name):
print('%s eat 1' % name)
time.sleep(3)
print('%s eat 2' % name)
start = time.time()
g1 = spawn(play, 'jason') # 异步提交 不加 .join() 主进程不会等待子进程结束
g2 = spawn(eat, 'jason') # 异步提交 不加 .join() 主进程不会等待子进程结束
g1.join() # 等待被监测的任务运行完毕
g2.join() # 等待被监测的任务运行完毕
print('主', time.time() - start) # 单线程下实现并发,提升效率
结果: # 并没有开设多线程或者多进程
jason play 1
jason eat 1
jason eat 2
jason play 2
主 5.033665418624878
3、协程实现TCP服务端并发的效果
# 客户端开设几百个线程发消息即可
import socket
from threading import Thread, current_thread
from socket import *
def client():
client = socket(AF_INET, SOCK_STREAM)
client.connect(('127.0.0.1', 8080))
n = 0
while True:
msg = '%s say hello %s' % (current_thread().name, n)
n += 1
client.send(msg.encode('utf8'))
data = client.recv(1024)
print(data.decode('utf8'))
# if __name__ == '__main__': 要不要都可以
for i in range(500):
t = Thread(target=client)
t.start()
# 服务端
import socket
from gevent import spawn
from gevent import monkey;monkey.patch_all()
def talk(sock):
while True:
try:
data = sock.recv(1024)
print(data)
sock.send(data + b'hello big baby')
except ConnectionError as e:
print(e)
sock.close()
break
def servers():
server = socket.socket()
server.bind(('127.0.0.1', 8080))
server.listen()
while True:
sock, addr = server.accept()
spawn(talk, sock)
g1 = spawn(servers)
g1.join()
"""
最牛逼的情况:多进程下开设多线程 多线程下开设协程
我们以后可能自己动手写的不多 一般都是使用别人封装好的模块或框架
"""
4、IO模型
"""理论为主 代码实现大部分为伪代码(没有实际含义 仅为验证参考)"""
# 1.基本关键字
同步(synchronous) 大部分情况下会采用缩写的形式 sync
异步(asynchronous) async
阻塞(blocking)
非阻塞(non-blocking)
# 2.研究的方向
Stevens在文章中一共比较了五种IO Model:
* blocking IO 阻塞IO
* nonblocking IO 非阻塞IO
* IO multiplexing IO多路复用
* signal driven IO 信号驱动IO
* asynchronous IO 异步IO
由于signal driven IO(信号驱动IO)在实际中并不常用,所以主要介绍其余四种 IO Model
4.1、四种IO模型简介
1.阻塞IO
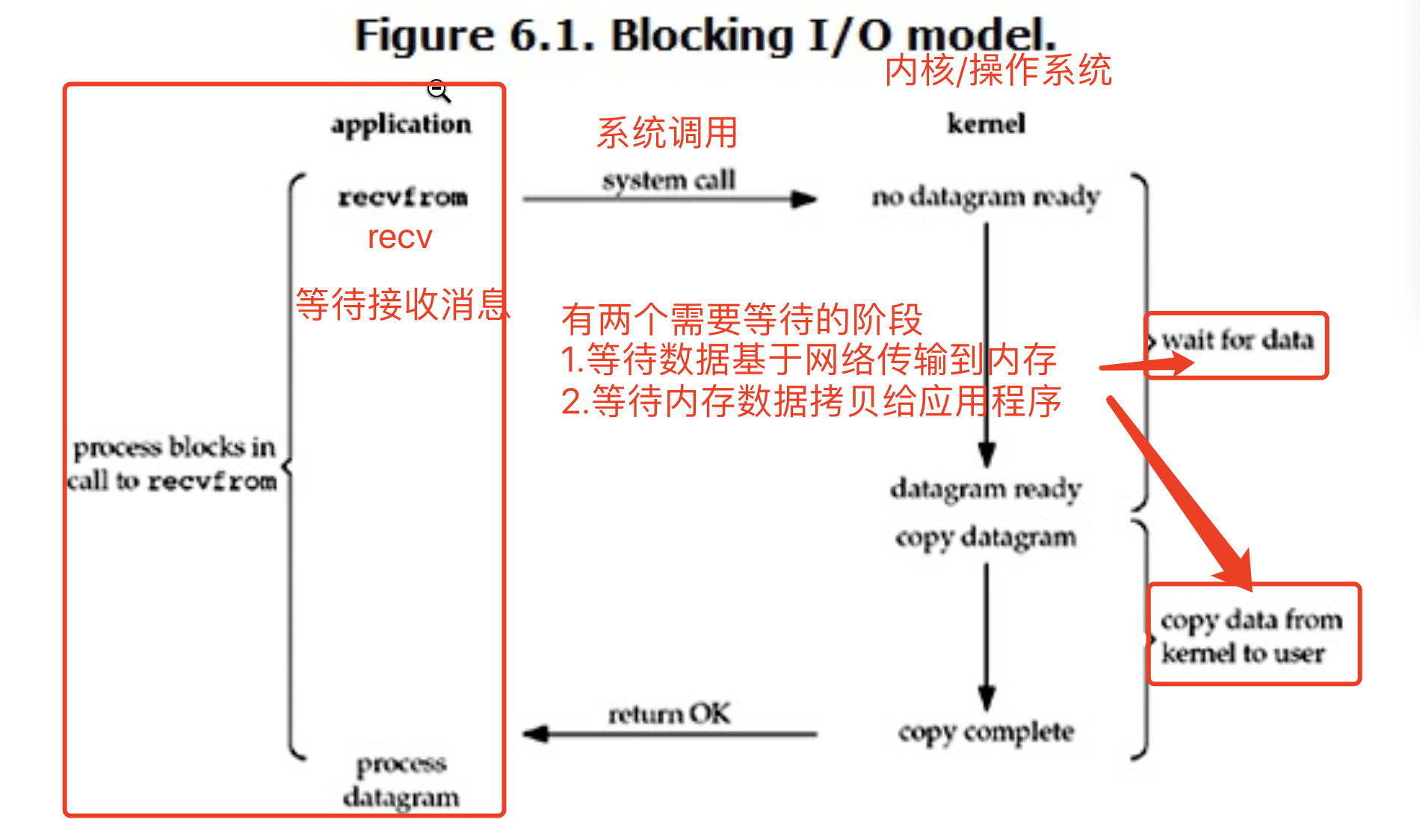
在linux中,默认情况下所有的socket都是blocking,一个典型的读操作流程大概是下图:6.1
当用户进程调用了recvfrom这个系统调用,kernel就开始了IO的第一个阶段:准备数据。对于network io来说,很多时候数据在一开始还没有到达(比如,还没有收到一个完整的UDP包),这个时候kernel就要等待足够的数据到来。
而在用户进程这边,整个进程会被阻塞。当kernel一直等到数据准备好了,它就会将数据从kernel中拷贝到用户内存,然后kernel返回结果,用户进程才解除block的状态,重新运行起来。
所以,blocking IO的特点就是在IO执行的两个阶段(等待数据和拷贝数据两个阶段)都被block了。
'''
最为常见的一种IO模型 有两个等待的阶段(wait for data、copy data)
'''
2.非阻塞IO
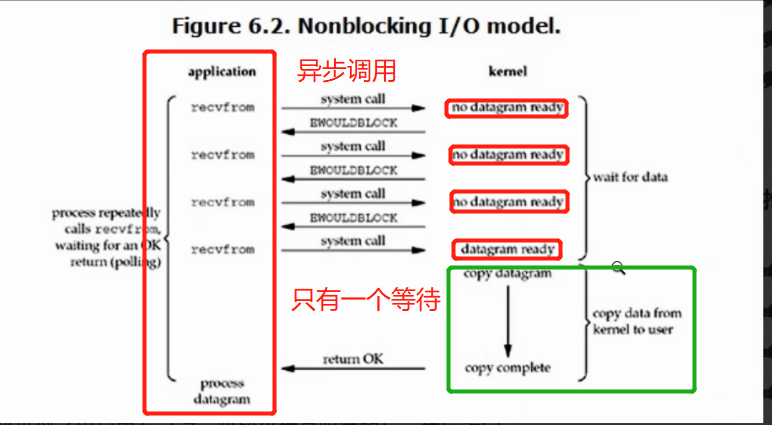
Linux下,可以通过设置socket使其变为non-blocking。当对一个non-blocking socket执行读操作时,流程是下图:6.2
从图中可以看出,当用户进程发出read操作时,如果kernel中的数据还没有准备好,那么它并不会block用户进程,而是立刻返回一个error。从用户进程角度讲 ,它发起一个read操作后,并不需要等待,而是马上就得到了一个结果。用户进程判断结果是一个error时,它就知道数据还没有准备好,于是用户就可以在本次到下次再发起read询问的时间间隔内做其他事情,或者直接再次发送read操作。一旦kernel中的数据准备好了,并且又再次收到了用户进程的system call,那么它马上就将数据拷贝到了用户内存(这一阶段仍然是阻塞的),然后返回。
也就是说非阻塞的recvform系统调用调用之后,进程并没有被阻塞,内核马上返回给进程,如果数据还没准备好,此时会返回一个error。进程在返回之后,可以干点别的事情,然后再发起recvform系统调用。重复上面的过程,循环往复的进行recvform系统调用。这个过程通常被称之为轮询。轮询检查内核数据,直到数据准备好,再拷贝数据到进程,进行数据处理。需要注意,拷贝数据整个过程,进程仍然是属于阻塞的状态。
所以,在非阻塞式IO中,用户进程其实是需要不断的主动询问kernel数据准备好了没有。
'''
系统调用阶段变为了非阻塞(轮询) 有一个等待的阶段(copy data)
轮询的阶段是比较消耗资源的
'''
3.多路复用IO
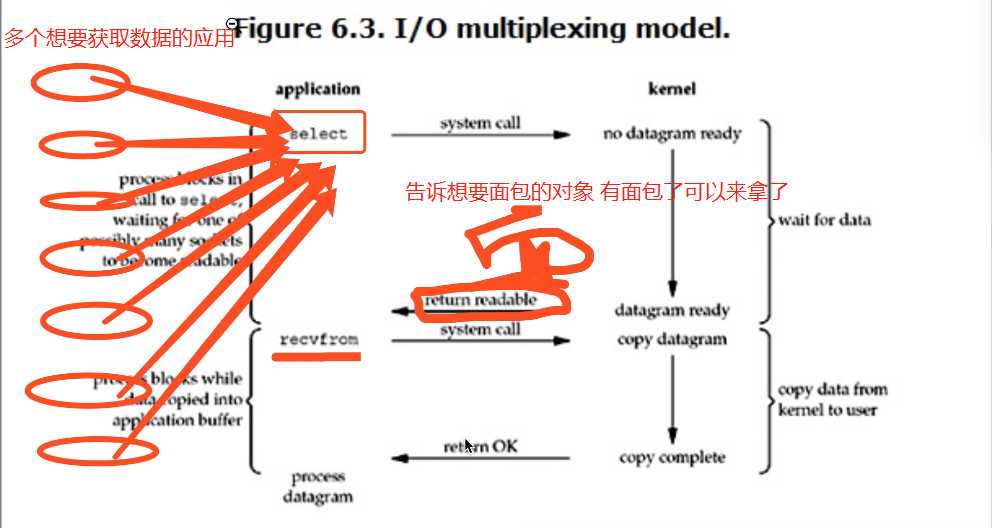
IO multiplexing这个词可能有点陌生,但是如果我说select/epoll,大概就都能明白了。有些地方也称这种IO方式为事件驱动IO(event driven IO)。我们都知道,select/epoll的好处就在于单个process就可以同时处理多个网络连接的IO。它的基本原理就是select/epoll这个function会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程。它的流程如图:6.3
当用户进程调用了select,那么整个进程会被block,而同时,kernel会“监视”所有select负责的socket,当任何一个socket中的数据准备好了,select就会返回。这个时候用户进程再调用read操作,将数据从kernel拷贝到用户进程。
这个图和blocking IO的图其实并没有太大的不同,事实上还更差一些。因为这里需要使用两个系统调用(select和recvfrom),而blocking IO只调用了一个系统调用(recvfrom)。但是,用select的优势在于它可以同时处理多个connection。
# 强调:
1. 如果处理的连接数不是很高的话,使用select/epoll的web server不一定比使用multi-threading + blocking IO的web server性能更好,可能延迟还更大。select/epoll的优势并不是对于单个连接能处理得更快,而是在于能处理更多的连接。
2. 在多路复用模型中,对于每一个socket,一般都设置成为non-blocking,但是,如上图所示,整个用户的process其实是一直被block的。只不过process是被select这个函数block,而不是被socket IO给block。
结论: select的优势在于可以处理多个连接,不适用于单个连接
'''
利用select或者epoll来监管多个程序 一旦某个程序需要的数据存在于内存中了 那么立刻通知该程序去取即可
'''
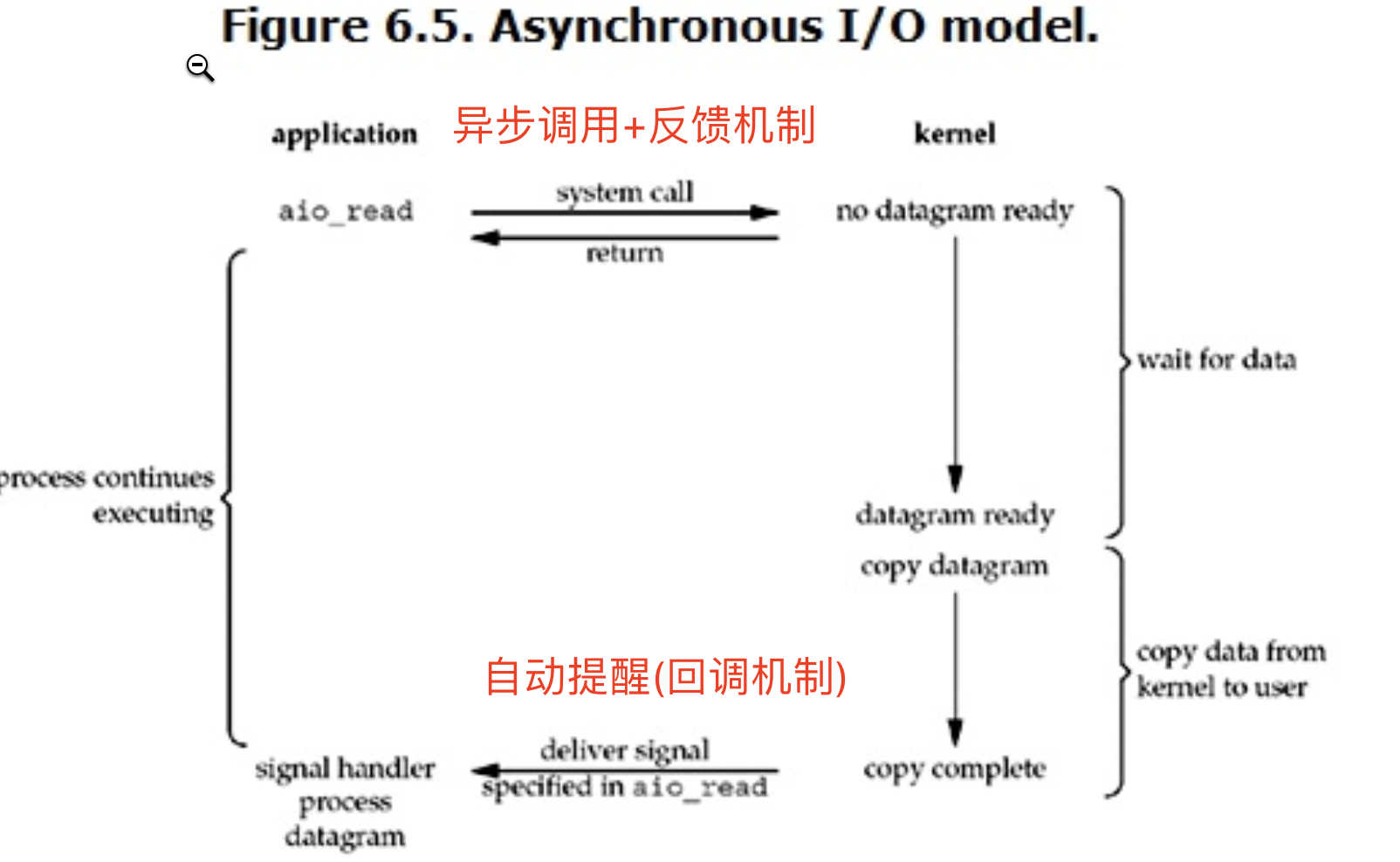
4.异步IO
Linux下的asynchronous IO其实用得不多,从内核2.6版本才开始引入。流程如下图:6.5
用户进程发起read操作之后,立刻就可以开始去做其它的事。而另一方面,从kernel的角度,当它受到一个asynchronous read之后,首先它会立刻返回,所以不会对用户进程产生任何block。然后,kernel会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都完成之后,kernel会给用户进程发送一个signal,告诉它read操作完成了。
'''
只需要发起一次系统调用 之后无需频繁发送 有结果并准备好之后会通过异步回调机制反馈给调用者
'''
5、前端
# 1.什么是前端:
任何与操作系统打交道的界面都可以称之为"前端"
手机界面(app) 电脑界面(软件) 平板界面(软件)
# 2.什么是后端:
不直接与用户打交道,而是控制核心逻辑的运行
各种编程语言编写的代码(python代码、java代码、c++代码)
# 3.前端的学习思路
声明:前端也是一门独立的学科 市面上也有前端工程师岗位,所以前端完整的课程内容也有解决六个半月,我们不可能全部学习,只学习最为核心最为基础的部门
程度:掌握基本前端页面搭建 掌握前端后续内容的学习思路 看得懂前端工程师所编写的代码
# 4.前端的学习流程
前端三剑客:
HTML 网页的骨架(没有样式很丑)
CSS 网页的样式(给骨架美化)
JS 网页的动态效果(丰富用户体验)


5.1、BS架构
'''
我们在编写TCP服务端的时候 针对客户端的选择可以是自己写的客户端代码也可以是浏览器充当客户端(bs架构本质也是cs架构)
'''
# 本地自己搭建一个简易服务端
import socket
server = socket.socket()
server.bind(('127.0.0.1', 8080))
server.listen(5)
while True:
sock, addr = server.accept()
while True:
data = sock.recv(1024)
print(data)
sock.send(b'big baby')
# 让浏览器充当客户端访问
127.0.0.1:8080
无法识别
原因是:
我们自己编写的服务端发送的数据浏览器不识别 原因在于
每个人服务端数据的格式千差万别 浏览器无法自动识别 没有按照浏览器固定的格式发送
"""
浏览器可以访问很多服务端 如何做到无障碍的与这么多不同程序员开发的软件 实现数据的交互?
1.浏览器自身功能强大 自动识别并切换(太过消耗资源)
2.大家统一一个与浏览器交互的数据方式(统一思想)
"""
5.2、HTTP协议(重点)
'''
协议:大家商量好的一个共同认可的结果
HTTP协议:
规定了浏览器与服务端之间数据交互的方式及其他事项 如果我们开发的时候不遵循该协议 那么浏览器就无法识别我们的网站 网站就需要自己编写一个客户端(可以不遵循)
'''
# 1.四大特性
01 基于请求响应
服务端永远不会主动给客户端发消息 必须是客户端先发请求
如果想让服务端主动给客户端发送消息可以采用其他网络协议
02 基于TCP、IP作用于应用层之上的协议
应用层(HTTP)、传输层、网络层、数据链路层、物理链接层
03 无状态
不保存客户端的状态信息(早期的网站不需要用户注册 所有人访问的网页数据都是一样的)
"""鸡哥语录:纵使见她千百遍 我都当她如初见"""
04 无连接/短连接
两者请求响应之后立刻断绝关系
# 2.数据格式
01 请求格式
请求首行(网络请求的方法)
请求头(一堆K:V键值对)
(换行符 不能省略)
请求体(并不是所有的请求方法都有)
02 响应格式
响应首行(相应状态码)
响应头(一堆K:V键值对)
(换行符 不能省略)
响应体(即将交给浏览器的数据)
# 3.响应体代码
用数字来表示一串中文意思
1XX:服务端已经接受到了数据正在处理 你可以继续发送数据也可以等待
2XX:200 OK 请求成功 服务端返回了相应的数据
3XX:重定向(原本想访问A页面 但是自动跳转到了B页面)
4XX:403没有权限访问 404请求资源不存在
5XX:服务器内部错误
"""
公司还会自定义状态码 一般以10000开头
参考:聚合数据
"""
5.3、HTML前戏
import socket
server = socket.socket()
server.bind(('127.0.0.1', 8080))
server.listen(5)
"""
请求首行
b'GET / HTTP/1.1\r\n
请求头
Host: 127.0.0.1:8080\r\n
Connection: keep-alive\r\n
sec-ch-ua: " Not;A Brand";v="99", "Google Chrome";v="97", "Chromium";v="97"\r\n
sec-ch-ua-mobile: ?0\r\n
sec-ch-ua-platform: "macOS"\r\n
Upgrade-Insecure-Requests: 1\r\n
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36\r\n
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9\r\n
Sec-Fetch-Site: none\r\n
Sec-Fetch-Mode: navigate\r\n
Sec-Fetch-User: ?1\r\n
Sec-Fetch-Dest: document\r\n
Accept-Encoding: gzip, deflate, br\r\n
Accept-Language: zh-CN,zh;q=0.9\r\n
\r\n
请求体(当前为空)
'
"""
while True:
sock, addr = server.accept()
while True:
data = sock.recv(1024)
if len(data) == 0: break
print(data)
sock.send(b'HTTP/1.1 200 OK\r\n\r\n')
# 遵循HTTP响应格式
sock.send(b'<h1>hello big baby<h1>')
sock.send(b'<a href="https://www.jd.com">good see<a>')
sock.send(b'<img src="https://imgcps.jd.com/ling4/100013209930/54iG5qy-55u06ZmN/6YOo5YiG5q-P5ruhMTk55YePMTAw/p-5bd8253082acdd181d02fa06/a677079b/cr/s/q.jpg"/>')
# 直接相应
# sock.send(b'hello big baby')
# 用文本内容相应
# with open(r'a.txt', 'rb') as f:
# data = f.read()
# sock.send(data)
进程池与线程池基本使用、协程理论与实操、IO模型、前端、BS架构、HTTP协议与HTML前戏的更多相关文章
- 协程,事件驱动,异步io模型,异步网络框架
协程是一种用户态的轻量级线程,内核不知道它的存在.协程运行于一个线程中,协程的切换是由用户控制的.线程的切换是由cpu来控制的,而协程的切换是由用户控制的.协程的执行时串行的. select/poll ...
- 05网络并发 ( GIL+进程池与线程池+协程+IO模型 )
目录 05 网络并发 05 网络并发
- python系列之 - 并发编程(进程池,线程池,协程)
需要注意一下不能无限的开进程,不能无限的开线程最常用的就是开进程池,开线程池.其中回调函数非常重要回调函数其实可以作为一种编程思想,谁好了谁就去掉 只要你用并发,就会有锁的问题,但是你不能一直去自己加 ...
- python并发编程之进程池,线程池,协程
需要注意一下不能无限的开进程,不能无限的开线程最常用的就是开进程池,开线程池.其中回调函数非常重要回调函数其实可以作为一种编程思想,谁好了谁就去掉 只要你用并发,就会有锁的问题,但是你不能一直去自己加 ...
- Python 37 进程池与线程池 、 协程
一:进程池与线程池 提交任务的两种方式: 1.同步调用:提交完一个任务之后,就在原地等待,等任务完完整整地运行完毕拿到结果后,再执行下一行代码,会导致任务是串行执行 2.异步调用:提交完一个任务之后, ...
- 8.15 day33 进程池与线程池_协程_IO模型(了解)
进程池和线程池 开进程开线程都需要消耗资源,只不过两者比较的情况线程消耗的资源比较少 在计算机能够承受范围之内最大限度的利用计算机 什么是池? 在保证计算机硬件安全的情况下最大限度地利用计算机 ...
- Event事件、进程池与线程池、协程
目录 Event事件 进程池与线程池 多线程爬取梨视频 协程 协程目的 gevent TCP服务端socket套接字实现协程 Event事件 用来控制线程的执行 出现e.wait(),就会把这个线程设 ...
- 进程池和线程池、协程、TCP单线程实现并发
一.进程池和线程池 当被操作对象数目不大时,我们可以手动创建几个进程和线程,十几个几十个还好,但是如果有上百个上千个.手动操作麻烦而且电脑硬件跟不上,可以会崩溃,此时进程池.线程池的功效就能发挥了.我 ...
- Python Django 协程报错,进程池、线程池与异步调用、回调机制
一.问题描述 在Django视图函数中,导入 gevent 模块 import gevent from gevent import monkey; monkey.patch_all() from ge ...
随机推荐
- MemoryCache 如何清除全部缓存?
最近有个需求需要定时清理服务器上所有的缓存.本来以为很简单的调用一下 MemoryCache.Clear 方法就完事了.谁知道 MemoryCache 类以及 IMemoryCache 扩展方法都没有 ...
- CF424A Squats 题解
Content 给定一个长度为 \(n\) 的仅由 x 和 X 组成的字符串,求使得字符串中 x 和 X 的数量相等需要修改的次数,并输出修改后的字符串. 数据范围:\(2\leqslant n\le ...
- sqlalchemy-orm学生签到 成绩记录查询系统
#!/usr/bin/env python # Author:zhangmingda '''''' from sqlalchemy import create_engine,ForeignKey,DA ...
- Open-UI序言
Open_UI-----序言 在单片机开发的时候,我们时常需要一个足够开放的,体积足够小巧,且移植性较高的UI库来显示信息,从而做到非常优秀的人机交互效果.而我试过的UI库如下: LVGL 这是目 ...
- Mybatis一对一、一对多级联查询使用
在A对象的xml配置文件中 一对一<association property="shop" column="shop_id" select="c ...
- windows修改控制台编码
1.关于 演示环境: win10 1909 2.代码定义 编码代码 释义 65001 UTF-8代码页 950 繁体中文 936 简体中文默认的GBK 437 MS-DOS 美国英语 3.注册表修改 ...
- 【LeetCode】345. Reverse Vowels of a String 解题报告(Java & Python & C++)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 使用栈 双指针 日期 [LeetCode] 题目地址 ...
- 快速登陆linux服务器
前言 本文适用于喜欢原生终端的用户,钟爱第三方ssh客户端的可以无视....客户端可以保存用户信息和密码,比较无脑.mac可以使用终端,win可以使用git的bash. 上次分享了配置非对称秘钥免密登 ...
- 看完这篇 Linux 权限后,通透了!
我们在使用 Linux 的过程中,或多或少都会遇到一些关于使用者和群组的问题,比如最常见的你想要在某个路径下执行某个指令,会经常出现这个错误提示 . permission denied 反正我大概率见 ...
- CapstoneCS5212替代RTD2166|DP转VGA转换电路设计方法|CS5212替代方案
Capstone CS5212适用于设计DP转VGA转换电路,主要用在嵌入式单片机基于工业机或者INTEL X86主板上面,也适用于多个电子配件市场和显示器应用程序,如笔记本电脑.主板.台式机.适配器 ...