Python3.6 的字典为什么会快
链接:https://zhuanlan.zhihu.com/p/73426505
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
在Python 3.5(含)以前,字典是不能保证顺序的,键值对A先插入字典,键值对B后插入字典,但是当你打印字典的Keys列表时,你会发现B可能在A的前面。
但是从Python 3.6开始,字典是变成有顺序的了。你先插入键值对A,后插入键值对B,那么当你打印Keys列表的时候,你就会发现B在A的后面。
不仅如此,从Python 3.6开始,下面的三种遍历操作,效率要高于Python 3.5之前:
for key in 字典
for value in 字典.values()
for key, value in 字典.items()从Python 3.6开始,字典占用内存空间的大小,视字典里面键值对的个数,只有原来的30%~95%。
Python 3.6到底对字典做了什么优化呢?为了说明这个问题,我们需要先来说一说,在Python 3.5(含)之前,字典的底层原理。
当我们初始化一个空字典的时候,CPython的底层会初始化一个二维数组,这个数组有8行,3列,如下面的示意图所示:
my_dict = {}
'''
此时的内存示意图
[[---, ---, ---],
[---, ---, ---],
[---, ---, ---],
[---, ---, ---],
[---, ---, ---],
[---, ---, ---],
[---, ---, ---],
[---, ---, ---]]
'''现在,我们往字典里面添加一个数据:
my_dict['name'] = 'kingname'
'''
此时的内存示意图
[[---, ---, ---],
[---, ---, ---],
[---, ---, ---],
[---, ---, ---],
[---, ---, ---],
[1278649844881305901, 指向name的指针, 指向kingname的指针],
[---, ---, ---],
[---, ---, ---]]
'''这里解释一下,为什么添加了一个键值对以后,内存变成了这个样子:
首先我们调用Python 的hash函数,计算name这个字符串在当前运行时的hash值:
>>> hash('name')
1278649844881305901特别注意,我这里强调了『当前运行时』,这是因为,Python自带的这个hash函数,和我们传统上认为的Hash函数是不一样的。Python自带的这个hash函数计算出来的值,只能保证在每一个运行时的时候不变,但是当你关闭Python再重新打开,那么它的值就可能会改变,如下图所示:
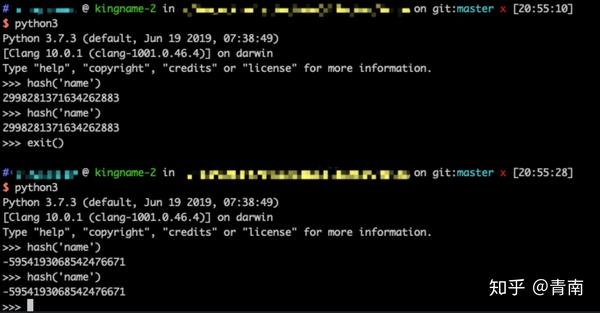
假设在某一个运行时里面,hash('name')的值为1278649844881305901。现在我们要把这个数对8取余数:
>>> 1278649844881305901 % 8
5余数为5,那么就把它放在刚刚初始化的二维数组中,下标为5的这一行。由于name和kingname是两个字符串,所以底层C语言会使用两个字符串变量存放这两个值,然后得到他们对应的指针。于是,我们这个二维数组下标为5的这一行,第一个值为name的hash值,第二个值为name这个字符串所在的内存的地址(指针就是内存地址),第三个值为kingname这个字符串所在的内存的地址。
现在,我们再来插入两个键值对:
my_dict['age'] = 26
my_dict['salary'] = 999999
'''
此时的内存示意图
[[-4234469173262486640, 指向salary的指针, 指向999999的指针],
[1545085610920597121, 执行age的指针, 指向26的指针],
[---, ---, ---],
[---, ---, ---],
[---, ---, ---],
[1278649844881305901, 指向name的指针, 指向kingname的指针],
[---, ---, ---],
[---, ---, ---]]
'''那么字典怎么读取数据呢?首先假设我们要读取age对应的值。
此时,Python先计算在当前运行时下面,age对应的Hash值是多少:
>>> hash('age')
1545085610920597121现在这个hash值对8取余数:
>>> 1545085610920597121 % 8
1余数为1,那么二维数组里面,下标为1的这一行就是需要的键值对。直接返回这一行第三个指针对应的内存中的值,就是age对应的值26。
当你要循环遍历字典的Key的时候,Python底层会遍历这个二维数组,如果当前行有数据,那么就返回Key指针对应的内存里面的值。如果当前行没有数据,那么就跳过。所以总是会遍历整个二位数组的每一行。
每一行有三列,每一列占用8byte的内存空间,所以每一行会占用24byte的内存空间。
由于Hash值取余数以后,余数可大可小,所以字典的Key并不是按照插入的顺序存放的。
注意,这里我省略了与本文没有太大关系的两个点: 1. 开放寻址,当两个不同的Key,经过Hash以后,再对8取余数,可能余数会相同。此时Python为了不覆盖之前已有的值,就会使用
开放寻址技术重新寻找一个新的位置存放这个新的键值对。 2. 当字典的键值对数量超过当前数组长度的2/3时,数组会进行扩容,8行变成16行,16行变成32行。长度变了以后,原来的余数位置也会发生变化,此时就需要移动原来位置的数据,导致插入效率变低。
在Python 3.6以后,字典的底层数据结构发生了变化,现在当你初始化一个空的字典以后,它在底层是这样的:
my_dict = {}
'''
此时的内存示意图
indices = [None, None, None, None, None, None, None, None]
entries = []
'''当你初始化一个字典以后,Python单独生成了一个长度为8的一维数组。然后又生成了一个空的二维数组。
现在,我们往字典里面添加一个键值对:
my_dict['name'] = 'kingname'
'''
此时的内存示意图
indices = [None, 0, None, None, None, None, None, None]
entries = [[-5954193068542476671, 指向name的指针, 执行kingname的指针]]
'''为什么内存会变成这个样子呢?我们来一步一步地看:
在当前运行时,name这个字符串的hash值为-5954193068542476671,这个值对8取余数是1:
>>> hash('name')
-5954193068542476671
>>> hash('name') % 8
1所以,我们把indices这个一维数组里面,下标为1的位置修改为0。
这里的0是什么意思呢?0是二位数组entries的索引。现在entries里面只有一行,就是我们刚刚添加的这个键值对的三个数据:name的hash值、指向name的指针和指向kinganme的指针。所以indices里面填写的数字0,就是刚刚我们插入的这个键值对的数据在二位数组里面的行索引。
好,现在我们再来插入两条数据:
my_dict['address'] = 'xxx'
my_dict['salary'] = 999999
'''
此时的内存示意图
indices = [1, 0, None, None, None, None, 2, None]
entries = [[-5954193068542476671, 指向name的指针, 执行kingname的指针],
[9043074951938101872, 指向address的指针,指向xxx的指针],
[7324055671294268046, 指向salary的指针, 指向999999的指针]
]
'''现在如果我要读取数据怎么办呢?假如我要读取salary的值,那么首先计算salary的hash值,以及这个值对8的余数:
>>> hash('salary')
7324055671294268046
>>> hash('salary') % 8
6那么我就去读indices下标为6的这个值。这个值为2.
然后再去读entries里面,下标为2的这一行的数据,也就是salary对应的数据了。
新的这种方式,当我要插入新的数据的时候,始终只是往entries的后面添加数据,这样就能保证插入的顺序。当我们要遍历字典的Keys和Values的时候,直接遍历entries即可,里面每一行都是有用的数据,不存在跳过的情况,减少了遍历的个数。
老的方式,当二维数组有8行的时候,即使有效数据只有3行,但它占用的内存空间还是 8 * 24 = 192 byte。但使用新的方式,如果只有三行有效数据,那么entries也就只有3行,占用的空间为3 * 24 =72 byte,而indices由于只是一个一维的数组,只占用8 byte,所以一共占用 80 byte。内存占用只有原来的41%
青南公众号

Python3.6 的字典为什么会快的更多相关文章
- python3入门之字典
获得更多资料欢迎进入我的网站或者 csdn或者博客园 本节主要介绍字典,字典也成映射,时python中唯一内建的映射类型.更多详细请点击readmore.下面附有之前的文章: python入门之字符串 ...
- POJ 2503 Babelfish(map,字典树,快排+二分,hash)
题意:先构造一个词典,然后输入外文单词,输出相应的英语单词. 这道题有4种方法可以做: 1.map 2.字典树 3.快排+二分 4.hash表 参考博客:[解题报告]POJ_2503 字典树,MAP ...
- python3两个字典的合并
两个字典的合并其实很简单,直接用dict的update即可,代码如下: # /usr/bin/python3 # -*- encoding: utf-8 -*- ", "" ...
- python3中返回字典的键
我在看<父与子的编程之旅>的时候,有段代码是随机画100个矩形,矩形的大小,线条的粗细,颜色都是随机的,代码如下, import pygame,sys,random from pygame ...
- python3 dict(字典)
clear(清空字典内容) stu = { 'num1':'Tom', 'num2':'Lucy', 'num3':'Sam', } print(stu.clear()) #输出:None copy( ...
- Python3基础之字典
Python数据类型之字典(Dictionary) 字典特征 特征 可变.无序.映射.键值对 形式 {key0:value0, key1:value1, key2:value3, ..., } key ...
- python3之利用字典和列表实现城市多级菜单
利用字典和列表实现城市多级菜单 #coding:utf-8 #利用字典和列表实现城市多级菜单 addrIndex = {":"福建"} addrDict = {" ...
- python3.6 创建字典三法
这里献丑给出 python 3.6 创建字典变量的三法 其一:阳春白雪法:直接声明 mydic = {"name":"徐晓冬","age" ...
- python3.6中 字典类型和字符串类型互相转换的方法
mydic = {"俄罗斯": {"1":"圣彼得堡", "2":"叶卡捷琳堡", "3& ...
随机推荐
- ASP调用SDK微信分享好友、朋友圈
ASP调用SDK微信分享好友.朋友圈需要用到sha1.asp,我先来上主代码,然后再附加sha1.asp,方便大家直接复制过去即可使用. 页面:shara.asp 1 <%@LANGUAGE=& ...
- PHP学员分享:126个常用的正则表达式分享
PHP学员分享:126个常用的正则表达式分享 电子邮件:/\w+([-+.']\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*/变量:/[a-zA-Z_\x7f-\xff][a-z ...
- 【Jwt】JSON Web Token
一.什么是JSON Web Token: 首先要明确的是JSON Web Token:是一个开放标准,这个标准定义了一种用于简洁,自包含的用于通信双方之间以JSON对象的形式安全传递信息的方法 而我们 ...
- ARM详细指令集
算术和逻辑指令 ADC : 带进位的加法 (Addition with Carry) ADC{条件}{S} <dest>, <op 1>, <op 2> dest ...
- SSH后门万能密码
当我们在获得一台Linux服务器的 root 权限后,我们第一想做的就是如何维持这个权限,维持权限肯定想到的就是在目标服务器留下一个后门.但是留普通后门,肯定很容易被发现.我们今天要讲的就是留一个SS ...
- C++ Log日志系统
闲得无聊,瞎写的一个东西. 好多地方能够优化甚至可能重写,也没写,就记下了个思路在这里. 主要熟练一下C++17的内容. version = 0.1 lc_log .h 1 #pragma once ...
- HashSet添加操作底层判读(Object类型)
Object类型添加操作判读 第一步:程序首先创建一个Object泛型的Set数组,这里用到了上转型: 第二步:执行object里面的add添加方法,传进的值为"JAVA": 首先 ...
- 认识WPF
新开一节WPF桌面开发的讲解,这节先初步认识一下什么是WPF. 1.简介 WPF是 Windows Presentation Foundation 的英文缩写,意为"窗体呈现基础" ...
- Smss.exe加载win32k.sys过程总结
windows操作系统初始化 windows操作系统再初始化的过程中,当内核完全初始化而且各个组件也已经准备好后会加载一个个用户进程smss.exe(会话管理器),此进程会接着调用NtSetSyste ...
- SE_Work4_软件案例分析
项目 内容 课程:北航-2020-春-软件工程 博客园班级博客 要求:分析软件案例 个人博客作业-软件案例分析 班级 005 这个作业在哪个具体方面帮助我实现目标 分析对比一类软件,学会规划分析软件的 ...