Redis-01-基础
基本概念
1 基本概念
redis是一个开源的、使用C语言编写的、支持网络交互的、可基于内存也可持久化的Key-Value数据库(非关系性数据库)
redis运维的责任
1.保证服务不挂
2.备份数据
3.协助开发查询数据 get k2
redis必做的事情
限制使用内存大小,建议设置为操作系统内存的50%
2 redis的优势
速度快,因为数据存在内存中
支持丰富数据类型,支持string、list、set、hash
支持事务,操作都是原子性,所谓的原子性就是对数据的更改要么全部执行,要么全部不执行
丰富的特性:可用于缓存,消息,按key设置过期时间,过期后将会自动删除
3 redis的应用场景
键过期功能:
缓存、session会话保存、优惠券过期
列表:
排行榜
天然计数器:
帖子浏览数、视频播放数、评论留言数
集合:
兴趣标签、广告投放
消息队列:
ELK缓存
缓存
对于一些要返回给前端数据的缓存,当有大量数据库sql操作时候,为了避免每次接口请求都要去查询数据库,
可以把一些数据缓存到redis中,这样是直接从内存中获取数据,速度会增快很多
web端用户,用于登陆缓存session数据,登陆的一些信息存到session中,缓存到redis中
队列
redis中提供了list接口,这个list提供了lpush和rpop,这两个方法具有原子性,可以插入队列元素和弹出队列元素
数据存储
redis是非关系型数据库,可以把redis直接用于数据存储,提供了增删改查等操作,
因为redis有良好的硬盘持久化机制,redis数据就可以定期持久化到硬盘中,保证了redis数据的完整性和安全性
redis锁实现防刷机制
redis锁可以处理并发问题,redis数据类型中有一个set类型,set类型在存储数据的时候是无序的,
而且每个值是不一样的,不能重复,这样就可以快速的查找元素中某个值是否存在,精确的进行增加删除操作
安装
1 目录规划
服务器IP和主机名称
10.0.0.51 db01
10.0.0.52 db02
10.0.0.53 db03
下载目录,存放redis安装包
/data/soft/
安装目录、软件目录、配置文件
/opt/redis_cluster/redis_{PORT}/{conf,logs,pid}
数据目录
/data/redis_cluster/redis_{PROT}/redis_{PROT}.rdb
运维脚本
/root/scripts/redis_shell.sh
2 编辑hosts文件
# 三台都需要
tail -3 /etc/hosts
10.0.0.51 db01
10.0.0.52 db02
10.0.0.53 db03
3 创建相应目录
mkdir -p /data/soft
mkdir -p /data/redis_cluster/redis_6379
mkdir -p /opt/redis_cluster/redis_6379/{conf,pid,logs}
4 下载redis二进制包
cd /data/soft/
wget http://download.redis.io/releases/redis-3.2.9.tar.gz
5 解压redis安装包,创建软链接
tar -xzvf redis-3.2.9.tar.gz -C /opt/redis_cluster/
ln -s /opt/redis_cluster/redis-3.2.9/ /opt/redis_cluster/redis
6 安装redis
cd /opt/redis_cluster/redis
make && make install
一般的编译安装
./config 生成makefile文件
make 生成二进制命令文件
make install 把二进制命令文件移动到/usr/local/bin/下面,相当于设置环境变量
7 配置文件
本次使用的配置文件,建议使用这个配置文件,后面可能还会加入一些参数配置
[root@db01 conf]# cat redis_6379.conf
# 以守护进程模式启动
daemonize yes
# 绑定主机地址
bind 10.0.0.51
# 监听端口
port 6379
# pid文件和log文件的保存地址
pidfile /opt/redis_cluster/redis_6379/pid/redis_6379.pid
logfile /opt/redis_cluster/redis_6379/logs/redis_6379.log
# 设置数据库的数量,默认数据库为0
databases 16
# 指定本地持久化的文件名,默认是dump.rdb
dbfilename redis_6379.rdb
# 本地数据库目录
dir /data/redis_cluster/redis_6379
在redis解压后的安装包里有个能生成一个大而全的配置文件,这个会默认启动一个redis进程。一般不用这个配置文件,我们自己定义
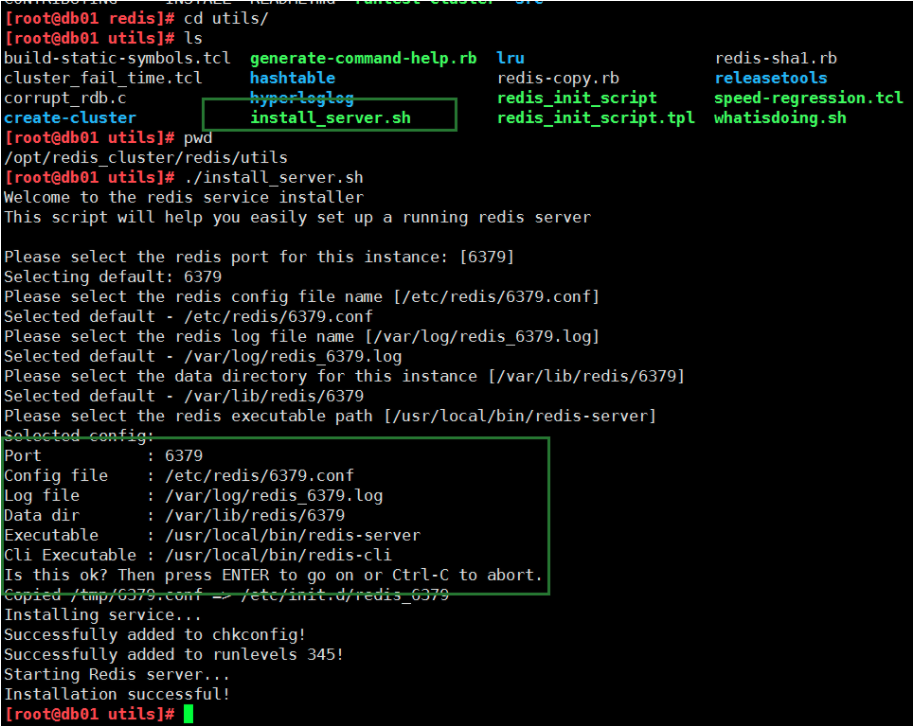
8 redis管理
启动
[root@db01 conf]# redis-server /opt/redis_cluster/redis_6379/conf/redis_6379.conf
[root@db01 conf]# ps -ef|grep redis
root 12989 1 0 12:00 ? 00:00:00 redis-server 10.0.0.51:6379
root 12993 9465 0 12:00 pts/0 00:00:00 grep --color=auto redis
登录
[root@db01 conf]# redis-cli -h 10.0.0.51
10.0.0.51:6379>
关闭
方式1
root@db01 conf]# redis-cli -h 10.0.0.51
10.0.0.51:6379> SHUTDOWN
[root@db01 conf]# ps -ef|grep redis
root 13020 9465 0 12:02 pts/0 00:00:00 grep --color=auto redis
方式2
[root@db01 conf]# redis-server /opt/redis_cluster/redis_6379/conf/redis_6379.conf
[root@db01 conf]# redis-cli -h 10.0.0.51 shutdown
[root@db01 conf]# ps -ef|grep redis
root 13032 9465 0 12:02 pts/0 00:00:00 grep --color=auto redis
日志
tail -f /opt/redis_cluster/redis_6379/redis_6379.log
常用命令
字符串常用命令
1 插入查看key值,如果key不存在则会返回nil
192.168.3.104:6379> set k1 v1
OK
192.168.3.104:6379> get k1
"v1"
192.168.3.104:6379> get k2
(nil)
2 查看key值类型
192.168.3.104:6379> TYPE k1
string
3 插入多个key 查看多个key
192.168.3.104:6379> mset k1 v1 k2 v3 k3 v3
OK
192.168.3.104:6379> mget k1 k2 k3
1) "v1"
2) "v3"
3) "v3"
4 重复插入的值会被覆盖
192.168.3.104:6379> set k1 1
OK
192.168.3.104:6379> get k1
"1"
192.168.3.104:6379> set k1 2
OK
192.168.3.104:6379> get k1
"2"
5 判断key是否存在,存在返回1,不存在返回0
192.168.3.104:6379> exists k1
(integer) 1
192.168.3.104:6379> exists k0
(integer) 0
6 删除一个key
192.168.3.104:6379> del k1
(integer) 1
192.168.3.104:6379> get k1
(nil)
7 计数功能
192.168.3.104:6379> incr k2
(integer) 2
192.168.3.104:6379> incr k2
(integer) 3
192.168.3.104:6379> incr k2
(integer) 4
192.168.3.104:6379> incr k2
(integer) 5
192.168.3.104:6379> incrby k2 100
(integer) 105
8 EXPIRE 设置key过期时间 默认秒
已经设置了过期时间的key,再重新给这个key重新赋值,那么这个key会永远不过期
过期之后,会删除这个key
TTL 查看key过期时间
-1 永不过期 默认秒
-2 没有这个key
192.168.3.104:6379> expire k1 30
(integer) 1
192.168.3.104:6379> ttl k1
(integer) 28
192.168.3.104:6379> ttl k1
(integer) 26
192.168.3.104:6379> ttl k1
(integer) 24
192.168.3.104:6379> ttl k1
(integer) 18
192.168.3.104:6379> ttl k1
(integer) 1
192.168.3.104:6379> ttl k1
(integer) -2
192.168.3.104:6379> ttl k1
(integer) -2
9 删除key过期时间,key永不过期
192.168.3.104:6379> set k1 v1
OK
192.168.3.104:6379> expire k1 30
(integer) 1
192.168.3.104:6379> ttl k1
(integer) 27
192.168.3.104:6379> ttl k1
(integer) 25
192.168.3.104:6379> persist k1
(integer) 1
192.168.3.104:6379> ttl k1
(integer) -1
10 keys * 这个命令不要在生产环境中使用,可能会导致redis挂掉
192.168.3.104:6379> KEYS *
1) "MK_SITE_UID|77e5525b676784be|0|5018"
2) "MK_SITE_UID|3713ac62058ebefac65ebec7d7863a2892694c71112|0|5006"
3) "RK_LUKCYWHEEL_FREE_SPIN"
4) "RK_MDS_SESSIONKEY_oK_ek5EVfYv5KZEDO5y7hcqMNKlc"
5) "RK_CONTINUOUSLY_PLAY_DAILY_OUTPUT_20190729_18"
6) "RK_CONTINUOUSLY_PLAY_
.......
列表常用命令
1 向列表左边添加一个元素
192.168.3.104:6379> lpush list1 A
(integer) 1
2 向列表右边添加一个元素
192.168.3.104:6379> rpush list1 1
(integer) 2
3 查看列表元素,这个和python中的列表索引相似
192.168.3.104:6379> lrange list1 0 -1
1) "A"
2) "1"
4 一次添加多个元素
192.168.3.104:6379> rpush list1 2 3 4 5 6
(integer) 7
192.168.3.104:6379> lpush list1 b c d
(integer) 10
192.168.3.104:6379> lrange list1 0 -1
1) "d"
2) "c"
3) "b"
4) "A"
5) "1"
6) "2"
7) "3"
8) "4"
9) "5"
10) "6"
5 删除,这个和python中列表的pop相似
192.168.3.104:6379> lpop list1
"d"
192.168.3.104:6379>
192.168.3.104:6379> rpop list1
"6"
192.168.3.104:6379> lrange list1 0 -1
1) "c"
2) "b"
3) "A"
4) "1"
5) "2"
6) "3"
7) "4"
8) "5"
哈希常用命令
可以把mysql数据库中的记录,缓存到redis当中来
例如mysql有一条这样的记录
uid name age job
1000 zhang 28 it
添加到redis中
192.168.3.104:6379> hmset uid:1000 name zhang age 28 job it
OK
192.168.3.104:6379> hget uid:1000 name
"zhang"
192.168.3.104:6379> hget uid:1000 age
"28"
192.168.3.104:6379> hgetall uid:1000
1) "name"
2) "zhang"
3) "age"
4) "28"
5) "job"
6) "it"
集合常用命令
集合: 不允许出现重复的元素
1 创建一个集合,查看一个集合
192.168.3.104:6379> sadd set1 1 2 3 4
(integer) 4
192.168.3.104:6379> smembers set1
1) "1"
2) "2"
3) "3"
4) "4"
2 集合差集(set1 - set2)
192.168.3.104:6379> sadd set1 1 2 3 4
(integer) 0
192.168.3.104:6379> sadd set2 3 4 5 6
(integer) 4
192.168.3.104:6379> sdiff set1 set2
1) "1"
2) "2"
3 集合并集
192.168.3.104:6379> sunion set1 set2
1) "1"
2) "2"
3) "3"
4) "4"
5) "5"
6) "6"
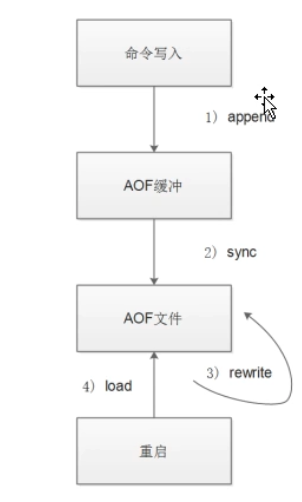
数据持久化*****
redis持久化提供了两种方式,分别是 RDB持久化方式 和 AOF持久化方式
RDB持久化方式
能够在指定的时间间隔,对你的数据进行快照存储
AOF持久化方式
记录每次对服务器写的操作,当服务器重启的时候会重新执行这些命令来恢复原始的数据
AOF命令以redis协议追加保存每次写的操作到文件末尾
Redis还能对AOF文件进行后台重写,使得AOF文件的体积不至于过大
可以同时开启两种持久化方式, 在这种情况下, 当redis重启的时候会优先载入AOF文件来恢复原始的数据
因为在通常情况下AOF文件保存的数据集要比RDB文件保存的数据集要完整
RDB持久化
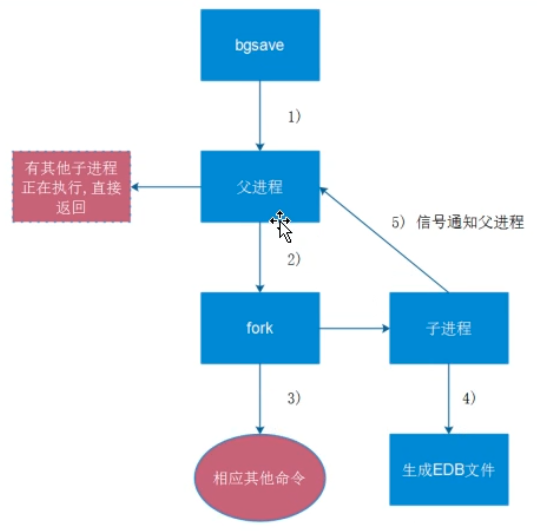
RDB在保存RDB文件时父进程唯一需要做的就是fork出一个子进程,接下来的工作全部由子进程来做,
父进程不需要再做其他IO操作,所以RDB持久化方式可以最大化redis的性能
优点
可以在指定时间内生成
速度快,适合用于做备份,主从复制也是基于RDB持久功能实现的
缺点
会丢失一段时间的数据
配置参数
[root@db01 conf]# cat redis_6379.conf
# 以守护进程模式启动
daemonize yes
# 绑定主机地址
bind 10.0.0.51
# 监听端口
port 6379
# pid文件和log文件的保存地址
pidfile /opt/redis_cluster/redis_6379/pid/redis_6379.pid
logfile /opt/redis_cluster/redis_6379/logs/redis_6379.log
# 设置数据库的数量,默认数据库为0
databases 16
# 指定本地持久化的文件名,默认是dump.rdb
# 900s有1一条数据,bgsave保存数据一次
save 900 1
# 300s 有10条数据,bgsave保存数据一次
save 300 10
# 60s 有1w条数据,bgsave保存数据一次
save 60 10000
dbfilename redis_6379.rdb
# 本地数据库目录
dir /data/redis_cluster/redis_6379
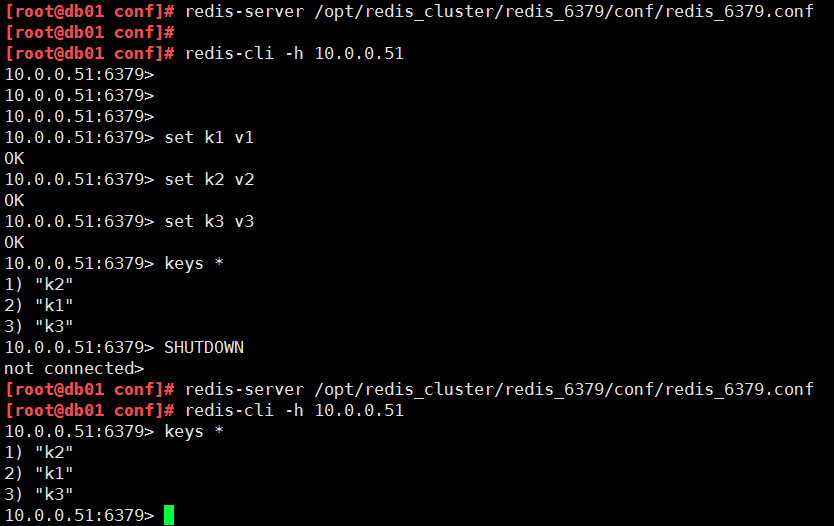
现在命令行执行bgsave保存一下数据。把内存中的数据保存到磁盘上

重启redis后,在插入数据,数据不丢失
RDB文件
题:
1. 没有满足bgsave条件,执行redis shutdown以后,redis的数据会不会丢?为什么?
不会丢,原因是当执行shutdown的时候,实际上是执行了2条命令。bgsave+关闭的命令
2. 当kill -9 redis的进程,会丢失数据,普通 kill redis的进程,数据不会丢失,为什么?
普通的 kill、kill -15、pkill 优雅的退出,活干完就退出,正常的退出流程,和shutdown一个意思
kill -9 直接中断程序运行了。工作中不要用 kill -9
3.AOF和ROB文件同时存在,redis重启会先加载哪个文件?
当redis重启的时候会优先载入AOF文件来恢复原始的数据,
因为在通常情况下AOF文件保存的数据集要比RDB文件保存的数据集要完整
AOF持久化
以追加的方式记录redis操作日志的文件,可以最大程度的保证redis数据安全。类似于mysql的binlog模式
优点
AOF文件是一个只进行追加的日志文件,所以不需要写入seek,即使由于某些原因(磁盘空间已满,写的过程中宕机等等)未执行完整的写入命令,你也也可使用redis-check-aof工具修复这些问题.
使用AOF会让你的Redis更加耐久: 你可以使用不同的fsync策略:无fsync,每秒fsync,每次写的时候fsync.
使用默认的每秒fsync策略,Redis的性能依然很好(fsync是由后台线程进行处理的,主线程会尽力处理客户端请求),一旦出现故障,你最多丢失1秒的数据
Redis 可以在 AOF 文件体积变得过大时,自动地在后台对 AOF 进行重写
AOF文件有序地保存了对数据库执行的所有写入操作, 这些写入操作以 Redis 协议的格式保存, 因此 AOF文件的内容非常容易被人读懂, 对文件进行分析(parse)也很轻松。 导出(export) AOF 文件也非常简单
缺点
据所使用的 fsync 策略,AOF 的速度可能会慢于 RDB 。 在一般情况下, 每秒 fsync 的性能依然非常高, 而关闭 fsync 可以让 AOF 的速度和 RDB 一样快, 即使在高负荷之下也是如此。 不过在处理巨大的写入载入时,RDB 可以提供更有保证的最大延迟时间(latency)
配置文件
[root@db01 redis_6379]# cat /opt/redis_cluster/redis_6379/conf/redis_6379.conf
# 以守护进程模式启动
daemonize yes
# 绑定主机地址
bind 10.0.0.51
# 监听端口
port 6379
# pid文件和log文件的保存地址
pidfile /opt/redis_cluster/redis_6379/pid/redis_6379.pid
logfile /opt/redis_cluster/redis_6379/logs/redis_6379.log
# 设置数据库的数量,默认数据库为0
databases 16
# 指定本地持久化的文件名,默认是dump.rdb
save 900 1
save 300 10
save 60 10000
dbfilename redis_6379.rdb
# 本地数据库目录
dir /data/redis_cluster/redis_6379
# 是否打开aof日志功能
appendonly yes
# 每一个命令都立即同步到aof
appendfsync always
# 每秒写1次
appendfsync everysec
# 写入工作交给操作系统,由操作系统判断缓冲区大小,统一写入到aof文件
appendfsync no
appendfilename "appendonly.aof"
===========================================================================================
官方文档:http://www.redis.cn/topics/persistence.html
Redis-01-基础的更多相关文章
- Java 之 I/O 系列 01 ——基础
Java 之 I/O 系列 目录 Java 之 I/O 系列 01 ——基础 Java 之 I/O 系列 02 ——序列化(一) Java 之 I/O 系列 02 ——序列化(二) 整理<疯狂j ...
- Redis学习---基础学习[all]
什么是NoSQL型数据库 NoSQL数据库---NoSQL数据库的分类 Redis学习---NoSQL和SQL的区别及使用场景 Redis学习---负载均衡的原理.分类.实现架构,以及使用场景 什么是 ...
- linux 01 基础命令
linux 01 基础命令 对于Linux要记住一个概念,一切皆文件,哪怕是目录,也是一个文件 1.修改用户密码 sudo passwd pyvip@Vip:~$ #pyvip表示用户名, Vip表示 ...
- Redis 宝典 | 基础、高级特性与性能调优
转载:Redis 宝典 | 基础.高级特性与性能调优 本文由 DevOpsDays 本文由简书作者kelgon供稿,高效运维社区致力于陪伴您的职业生涯,与您一起愉快的成长. 作者:kelgon ...
- redis最基础的入门教程
Redis最基础入门教程 简介 Redis 简介 Redis 优势 Redis与其他key-value存储有什么不同? 字符串(Strings) 哈希(Hash) 列表(List) 集合(Sets ...
- 01.基础架构:一条SQL查询语句是如何执行的?学习记录
01.基础架构:一条SQL查询语句是如何执行的?学习记录http://naotu.baidu.com/file/1c8fb5a0f2497c3a2655fed89099cb96?token=ff25d ...
- 探索Redis设计与实现1:Redis 的基础数据结构概览
本文转自互联网 本系列文章将整理到我在GitHub上的<Java面试指南>仓库,更多精彩内容请到我的仓库里查看 https://github.com/h2pl/Java-Tutorial ...
- 01 基础版web框架
01 基础版web框架 服务器server端python程序(基础版): import socket server=socket.socket() server.bind(("127.0.0 ...
- 小白也能看懂的Redis教学基础篇——朋友面试被Skiplist跳跃表拦住了
各位看官大大们,双节快乐 !!! 这是本系列博客的第二篇,主要讲的是Redis基础数据结构中ZSet(有序集合)底层实现之一的Skiplist跳跃表. 不知道那些是Redis基础数据结构的看官们,可以 ...
- 小白也能看懂的Redis教学基础篇——做一个时间窗限流就是这么简单
不知道ZSet(有序集合)的看官们,可以翻阅我的上一篇文章: 小白也能看懂的REDIS教学基础篇--朋友面试被SKIPLIST跳跃表拦住了 书接上回,话说我朋友小A童鞋,终于面世通过加入了一家公司.这 ...
随机推荐
- 导入项目发现没得右边没得maven
使用ctrl + shift+A点Add Maven Project 就行了 参考:https://www.cnblogs.com/Juff-code/p/13390356.html
- java实现遍历文件目录,根据文件最后的修改时间排序,并将文件全路径存入List集合
package com.ultra.aliyun.control.main; import java.io.File; import java.util.ArrayList; import java. ...
- 2013年第四届蓝桥杯C/C++程序设计本科B组省赛 第39级台阶
题目描述: 第39级台阶 小明刚刚看完电影<第39级台阶>,离开电影院的时候,他数了数礼堂前的台阶数,恰好是39级! 站在台阶前,他突然又想着一个问题: 如果我每一步只能迈上1个或2个台阶 ...
- 第一章python 简介
python语言是目前最流行的编程语言之一,在笔者写这篇文章的前一周,2018年的IEEE的编程语言排行出来了,python又雄踞第一. Python 强势霸榜第一名!排名第二的 C++ 得分是 98 ...
- C# 8.0和.NET Core 3.0高级编程 分享笔记一:C#8.0与NET Core 3.0入门
在学习C#相关知识的过程中,我们使用Visual Studio Code来入门整个C#. 一.安装Visual Studio Core环境 通过https://code.visualstudio.co ...
- STM32F103学习进程
软硬件下载程序和程序运行的相关问题和解决方案,以我自身买的STM32F103C8T6为例 (1) 硬件需要 1. 购买一个STM32F103XXX的板子.这是一个操作实践性非常强的一个学习过程,如果没 ...
- STM32笔记一
1.脉冲宽度调制是(PWM):用微处理器的数字输出来对模拟电路进行控制的一种非常有效的技术,广泛应用在从测量.通信到功率控制与变换的许多领域中.一般用于直流电机调速. 2.外部中断:外部中断是单片机实 ...
- CF1444D Rectangular Polyline[题解]
Rectangular Polyline 题目大意 给定 \(h\) 条长度分别为 \(l_1,l_2,--,l_h\) 的水平线段以及 \(v\) 条长度分别为 \(p_1,p_2,--.p_v\) ...
- 5.Java流程控制
所有的流程控制语句都可以相互嵌套.互不影响 一.用户交互Scanner Scanner对象 之前我们学的基本语法中我们并没有实现程序和人的交互,但是Java给我们提供了这样一个工具类,我们可以获取用户 ...
- 公钥-私钥 白名单-黑名单 Linux 远程访问及控制(SSH)
远程访问及控制一.SSH远程管理二.OpenSSH服务器① SSH (Secure Shell)协议② OpenSSH三.配置OpenSSH服务器举例四.sshd 服务支持两种验证方式五.使用SSH客 ...