论文笔记:(2021CVPR)PAConv: Position Adaptive Convolution with Dynamic Kernel Assembling on Point Clouds
PAConv: Position Adaptive Convolution with Dynamic Kernel Assembling on Point Clouds
PAConv:基于点云动态核组装的位置自适应卷积
论文地址:https://arxiv.org/abs/2103.14635
代码:https://github.com/CVMI-Lab/PAConv
注:该文章与CVPR2020Dynamic Convolution: Attention over Convolution Kernels很像,本人认为,该文章是将2D领域的动态卷积应用到3D领域的一个实践!
摘要
我们介绍了一个用于3D点云处理的通用卷积操作——位置自适应卷积(PAConv)。PAConv的关键是通过动态组合存储在权重库中的基本权重矩阵来构建卷积核。其中这些权重矩阵的系数是通过ScoreNet从点位置自适应地学习的。 这样,以数据驱动的方式构建内核,赋予PAConv比2D卷积更大的灵活性,以更好地处理不规则和无序的点云数据。此外,通过组合权重矩阵而不是从点位置粗暴地预测内核,可以降低学习过程的复杂性。
此外,与现有的点卷积算子的网络体系结构经常被精心设计不同,我们将PAConv集成到基于MLP的经典点云管道中,而无需更改网络配置。 即使建立在简单的网络上,我们的方法仍然可以接近甚至超越最新模型,并且可以显着提高分类和细分任务的基准性能,但效率却很高。 提供了彻底的消融研究和可视化效果,以了解PAConv。代码发布在 https://github.com/CVMI-Lab/PAConv 。
1、引言
近年来,3D扫描技术的兴起促进了许多依赖3D点云数据的应用程序,例如自动驾驶,机器人操纵和虚拟现实[37,42]。 因此,迫切需要有效和高效地处理3D点云的方法。尽管通过深度学习在3D点云处理中取得了显着进步[38、39、49、26],但鉴于点云的稀疏,不规则和无序结构,这仍然是一项艰巨的任务。
为了解决这些困难,以前的研究可以粗略地分为两类。 第一行尝试对3D点云进行体素化以形成规则的网格,以便可以采用3D网格卷积[34、45、41]。但是,重要的几何信息可能由于量化而丢失,体素通常会带来额外的内存和计算成本[11,8]。
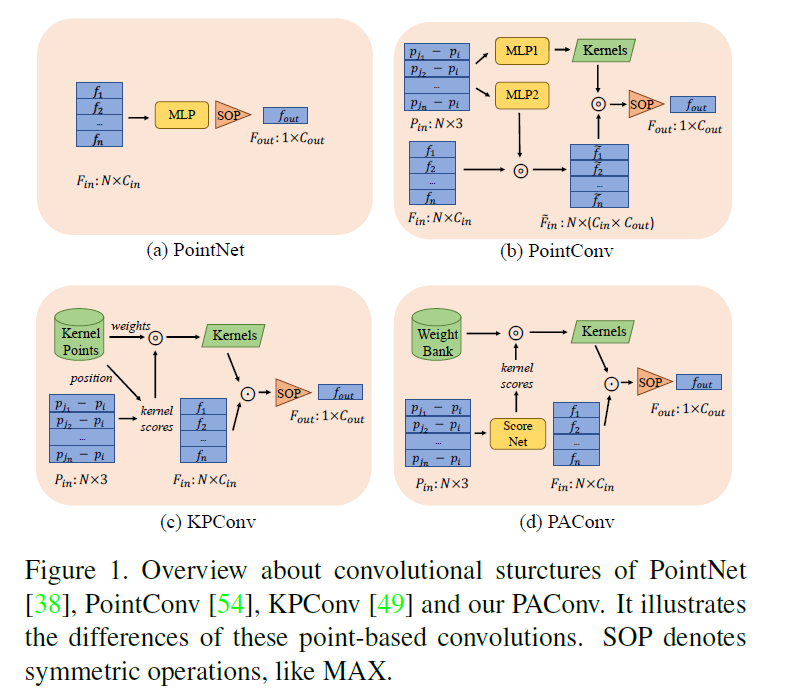
另一个流向是直接处理点云数据。首创性的工作[38]提出通过多层感知器(MLP) [14]和全局聚合来学习点的空间编码,如图1(a)所示。后续工作[39, 40, 50, 21, 53]利用局部聚合方案来改进网络。尽管如此,所有点都是由同一个MLP处理的,这限制了其代表空间变化关系的能力。
除了MLP,最近的作品大多是在点云上设计类似卷积的操作来利用空间相关性。为了处理三维点云的不规则性,一些作品[60, 52, 30]提出根据相对位置信息直接预测核的权重,并进一步用于转换特征,就像二维卷积一样。这一研究方向的一个代表性架构[54]如图1(b)所示。虽然这些方法在概念上是有效的,但在实际应用中,空间变化的核预测导致了大量的计算和内存消耗。高效的实现方式也牺牲了其设计灵活性,导致性能下降。另一组工作将核权值与固定的核点相关联[2,49,33],并在将核权值应用到处理点云时使用相关(或插值)函数来调整核权值。图1(c)说明了一个 代表性的架构[49]。然而,手工制作的的内核组合可能不是最佳的,也不足以对复杂的三维位置变化进行建模。
本文提出了一种用于三维点云深度表示学习的即插即用卷积算法PAConv。PAConv(如图1(d)所示)通过在权重库中动态组合基本权重矩阵来构造其卷积核。装配系数由MLPs(ScoreNet)从相对点位置自适应学习。我们的PAConv可以灵活地模拟三维点云的复杂空间变化和几何结构,同时效率很高。具体来说,PAConv没有用暴力的方式从点位置推断内核[54],而是通过scornet的动态内核组装策略绕过了巨大的内存和计算负担。此外,与核点方法不同[49],我们的PAConv以数据驱动的方式获得了建模空间变化的灵活性,并且更简单,不需要对核点进行复杂的设计。
我们在三个通用网络主干之上的三个具有挑战性的基准上进行了广泛的实验。具体来说,我们采用简单的基于MLP的点网络PointNet[38]、PointNet++[39]和DGCNN[53]作为主干,在不改变其他网络配置的情况下,将它们的MLP替换为PAConv。有了这些简单的主干,我们的方法在ModelNet40[55]上仍然达到了最先进的性能,并且在ShapeNet Part[63]和S3DIS[1]上分别将基线提高了2.3%和9.31%,并且模型效率相当高。另外值得注意的是,最近的点卷积方法经常使用复杂的体系结构和为其运算符定制的数据扩充[49,26,31]进行评估,这使得很难衡量卷积运算符所取得的进展。在这里,我们采用简单的基线,目的是尽量减少网络体系结构的影响,以便更好地评估来自操作符—PAConv的性能增益。
2、相关工作
将点云映射到常规二维或三维栅格(体素)
由于点云数据在三维空间具有不规则的结构,早期的工作[46,22,7]将点云投影到多视点图像上,然后利用传统的卷积进行特征学习。然而,这种从三维到二维的投影对遮挡表面或密度变化并不可靠。Tatarchenko等人[47]提出将局部曲面点映射到切面上,并进一步使用二维卷积算子,FPConv[26]将局部面片展平到具有软权重的规则二维网格上。然而,它们严重依赖于切平面的估计,投影过程不可避免地会牺牲三维几何信息。另一种技术是量化三维空间并将点映射为规则体素[41、34、4、35],其中可以应用三维卷积。然而,量化过程中不可避免地会丢失细粒度的几何细节,并且体素表示受到计算量和内存开销的限制。最近,为了解决上述问题,稀疏表示[45,11,8]被用来获得更小的网格和更好的性能。然而,它们仍然受到量化速率和计算效率之间的折衷。
基于MLPs的点表示学习
许多方法[38、39、19、29、15]直接用逐点MLP处理非结构化点云。PointNet[38]是一项开创性的工作,它使用共享的MLP分别对每个点进行编码,并使用全局池聚合所有点特征。然而,它缺乏捕捉局部三维结构的能力。一些后续工作通过采用分层多尺度或加权特征聚合方案来整合局部特征来解决这一问题[39、20、24、17、19、29、57、18、15、62、56、58]。其他方法使用图形来表示点云[40、44、53、51、59],并通过局部图形操作聚合点特征,以捕获局部点关系。然而,它们都采用共享的mlp来转换点特征,这限制了模型获取空间变化信息的能力。\
基于点卷积的点表示学习
最近,许多尝试[25,60,52,54,30,49,33,31]都集中在设计点卷积核上。PointCNN[25]学习X变换,将点与核相关联。然而,这种操作不能满足置换不变量的要求,这对于非有序点云数据的建模至关重要。另外,[43,12,60,52,54,30]提出了基于点位置直接学习局部点核的方法。然而,这些方法直接预测核,在学习过程中具有更高的复杂度(记忆和计算)。
另一种类型的点卷积将权重矩阵与三维空间中预定义的核点相关联[2,6,49,33,27,23]。然而,内核的位置对最终性能有着至关重要的影响[49],需要针对不同的数据集或主干架构进行专门的优化。此外,上述方法[49,33,23]通过使用手工规则组合预定义的核来生成核,这限制了模型的灵活性,导致性能低下[23]。与之不同的是,该方法以可学习的方式自适应地结合权重矩阵,提高了算子对不规则点云数据的拟合能力。
动态卷积和条件卷积
我们的工作也与动态卷积和条件卷积有关[9,10,61,3]。Brabandere等人[9]提出在像素输入上动态生成特定位置的滤波器。在[10]中,通过学习核坐标上的偏移量,使核空间变形以适应对象的不同尺度。最近,Bello[3]提出通过从内容和位置关系中学习lambda函数来建模查询和上下文之间的交互。CondConv[61]通过一个输出滤波器组合系数的路由函数来组合多个滤波器,从而生成卷积核,这与我们的动态核组装类似。然而,CondConv[61]中的预测核不是位置自适应的,而非结构化点云需要适应不同点位置的权值。
3、方法
在本节中,我们首先回顾点卷积的一般公式。然后我们介绍PAConv。最后,我们将PAConv与前人的相关工作进行了比较。
3.1 回顾
给定点云P={pi|i=1,...,N} ∈ RN×3中的N个点,P在卷积层中的输入和输出特征图可以表示为F = {fi|i = 1,...,N} ∈ RN×Cin 和 G = {gi|i = 1,...,N} ∈RN×Cout,,Cin 和 Cout分别是输入和输出的通道数。对于每个点 pi,可将广义的点卷积定义为:
gi = Λ({K(pi,pj)fj|pj ∈ Ni})
其中K(pi,pj)是一种根据中心点pi与其相邻点pj之间的位置关系输出卷积权重的函数。Ni表示所有邻域点,Λ是指最大值、SUM 或 AVG的聚合函数。根据这一定义,2D卷积可视为点卷积的特殊案例。例如, 对于 3×3的2D卷积,邻域Ni 位于一个 3 × 3 矩形补丁中心像素i,K是在固定集合3 × 3(图2.a)上从相对位置(pi,pj)到相应的权重矩阵K(pi,pj) ∈R Cin×Cout的一对一映射。
但是,由于点云的不规则和无序特性,图像上定义的简单一对一映射内核函数不适用于 3D 点云。具体来说,3D 点的空间位置是连续的,因此可能的相对偏移(pi,pj)的数量是无限的,无法映射成一组有限的内核权重。因此,我们重新设计了内核函数K,通过动态内核组件学习位置自适应映射。首先,我们定义了一个由几个权重矩阵组成的权重库。然后,ScoreNet旨在根据点位置学习系数向量来组合权重矩阵。最后,动态内核通过结合权重矩阵及其相关位置自适应系数生成。详细信息见图2(b)并在下面详细说明。
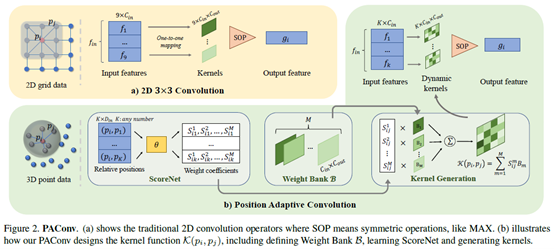
3.2 动态内核组装
Weight Bank
我们首先定义了B = {Bm|m = 1,...,M},其中每个Bm ∈ RCin×Cout是一个权重矩阵,M控制存储在权重矩阵B中的权重矩阵数量。
直觉上,较大的 M 有助于内核组装的更多样化的权重矩阵。然而,过多的权重矩阵可能会带来冗余,并导致沉重的记忆/计算开销。我们发现将 M 设置为 8 或 16 是适当的,这在第 6.2 节中讨论过。接下来是建立一个映射从离散内核到连续的3D空间。为此,我们提出ScoreNet 学习系数,以结合权重矩阵并生成适合点云输入的动态内核,详情如下。
ScoreNet.
ScoreNet的目标是将相对位置与权重库B中的不同权重矩阵关联在一起。鉴于中心点pi与其邻点pj之间的特定位置关系,ScoreNet 预测每个权重矩阵Bm的位置适应系数 Sijm。
ScoreNet的输入基于位置关系。我们探索不同的输入表示形式,如第 6.1 节所示。为了清楚起见,在这里,我们表示此输入向量为(pi,pj) ∈ RDin。ScoreNet将规范化的分数矢量输出为:
Sij = α(θ(pi,pj))
其中θ是使用多层感知器(MLP)[14]实现的非线性函数,α表示Softmax规范化。输出矢量Sij = {Sijm|m = 1,...,M},其中Sij表示 Bm 在构建内核 K(pi,pj)中的系数。M是权重矩阵的数量。Softmax 可确保输出分数在范围(0,1)。这种规范化保证每个权重矩阵将选择一个概率,较高的分数意味着位置输入和权重矩阵之间更牢固的关系,第6.1节介绍了不同规范化方案的比较。
Kernel generation
PAConv 的内核通过将权重库 B 中的权重矩阵与 ScoreNet 预测的相应系数组合而来:
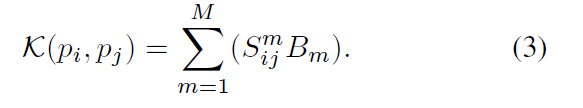
通过这样做,我们的 PAConv 以动态数据驱动的方式构建卷积内核,其中分数系数是自适应地从点位置学习的。我们的位置自适应构图在用内核组装策略模拟 3D 点云的不规则几何结构方面获得了灵活性。
3.3 权重正则化
虽然大型的权重库意味着有更多的权重矩阵可用,但权重矩阵的多样性无法保证,因为它们是随机初始化的,并且可能以相似的方式进行相互融合。为了避免这种情况,我们设计了一个权重正则化以惩罚不同权重矩阵之间的相关性,其定义如下:
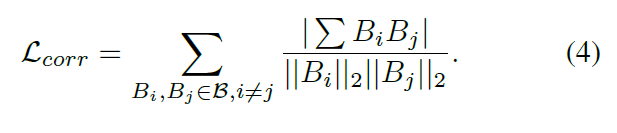
这强制权重矩阵多样化分布,进一步保证生成内核的多样性。
3.4 与前期工作的关系
略
4、骨干网体系结构
在最近的点云网络中,网络配置有很大的不同[54,19,33,49,26],但其中大多数可以被视为经典的基于点MLP的网络的不同变体[54,19,49]。为了评估PAConv的有效性和最小化复杂网络结构的影响,我们采用了三种经典的、简单的基于MLP的网络主干来处理不同的3D任务,并且在不需要进一步修改网络结构的情况下集成了PAConv。
对象级任务的网络 对象级任务处理单个的3D对象,使用轻量级网络可以有效地解决这个问题,而不需要下采样层。因此,点云的尺度/分辨率在整个网络中是固定的。PointNet[38]和DGCNN[53]是两个代表,它们被选为目标分类和形状零件分割的主干。我们直接用PAConv替换DGCNN的EdgeConv[53] 和PointNet的编码器中的mlp,而不改变原有的网络结构。
DGCNN[53]在特征空间中计算两两距离,每个点取最近的k点,这带来了巨大的计算开销和内存占用。相反,我们在三维坐标空间中搜索k近邻。
场景级任务的网络 对于大规模的场景级分割任务,需要采用带编码器(下采样)和解码器(上采样)的网络。这有效地扩大了网络的接收范围,同时实现了更快的速度和更少的内存使用。PointNet++[39]就是这样一种开创性的体系结构。
对于编码器,我们遵循PointNet++使用迭代最远点采样(FPS)对点云进行降采样。在构建邻域时,PointNet++将查找以查询点为中心的球中的所有点。球半径对性能至关重要,需要针对不同的点云尺度进行调整,因此我们直接搜索k近邻以获得灵活性。此外,我们采用了最简单的单尺度分组(SSG)方法,而不是复杂的MSG和MRG。因此,所学习的特征直接传播到下一层而不需要特征融合技巧。
与对象级任务类似,我们直接用PAConv替换PointNet++编码层中的mlp。我们的解码器与PointNet++相同。详细的网络结构见补充资料。
5、实验
我们将PAConv集成到第4节提到的不同点云网络中。在目标分类、形状分割和室内场景分割方面进行了评价。我们实现了一个CUDA层来有效地实现PAConv,这一点在补充资料中有介绍。
5.1 物体分类
数据集
首先,我们在ModelNet40 [55]对象分类中评估我们的模型。它包括来自 40 个类别的 3D 网格模型,训练集9843 个,测试集2468 个。
应用
如第4节所述,PAConv用于替换 DGCNN的EdgeConv[53] 和PointNet的编码器中的mlp。我们抽样1024个点,按照[38]进行培训和测试。按照[53],通过随机平移对象和打乱点来增强培训数据。由于任务简单,我们不添加 Lcorr(第 3 秒),同时仍实现高性能。
结果
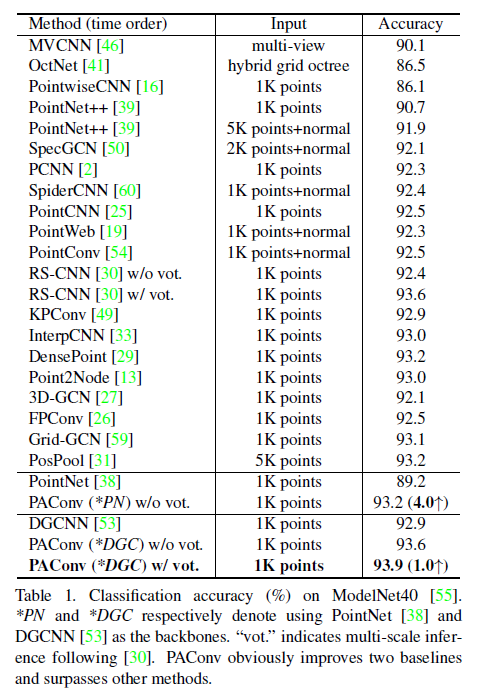
表1总结了定量比较。PAConv 显著提高了分类精度, PointNet的分类精度提高了 4.0%,DGCNN 上的分类精度提高了1.0%。特别是DGCNN+PAConv的准确率为93.9%,与近期作品相比,效果良好。在 RS-CNN [30] 之后,我们通过随机缩放执行投票测试,并在测试期间平均预测。未经投票,发布的RS-CNN模型的准确率下降到92.4%,而PAConv仍然得到93.6%。通过消除后处理因素,未经投票的结果更好地反映了纯粹从模型设计中获得的性能,并显示了我们的 PAConv 的有效性。
5.2 形状部件分割
数据集
PAConv也在用于形状部分分割的ShapeNet Parts上进行了评估[63]。它包含16类的16881的形状,被标注的50个部件中,每个形状有2-5个部件。从每个形状中取样2048个点,每个点用部件标签标注。
应用
我们用PAConv取代了DGCNN[53]中的EdgeConv,并遵循[53]的官方训练/验证/测试拆分。不使用数据增强。与分类任务类似,我们不使用 Lcorr,在测试期间应用相同的投票策略[30]。
结果
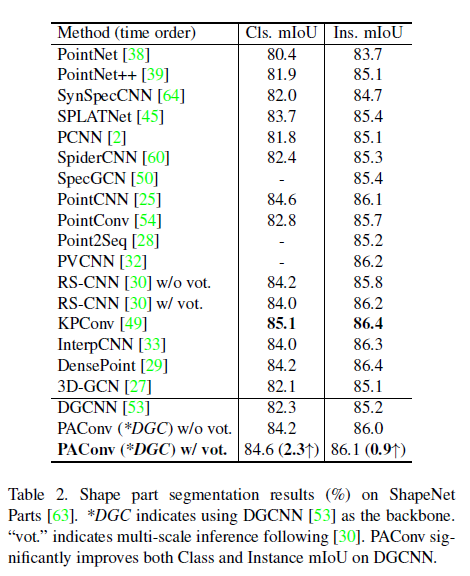
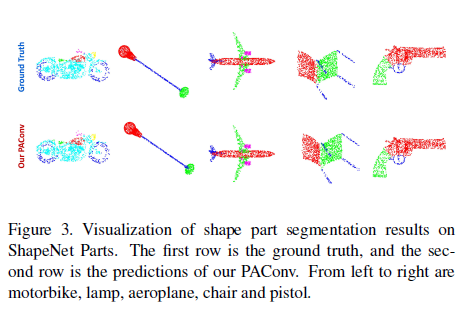
表2列出了实例平均值和类平均交并比(mIoU),其中 PAConv 显著提升了 DGCNN 在类 mIoU (2.3%+) 和实例 mIoU (0.9% +) 上的性能。PAConv在没有投票的情况下也优于 RSCNN(没有投票权)。此外,我们的方法优于或接近于其他方法。图3可视化分割结果。每个类的mIoU在补充材料中显示。
5.3 室内场景分割
数据集
大规模场景分割是一项更具挑战性的任务。为了进一步评估我们的方法,按照[19,33,31],我们采用斯坦福3D室内空间(S3DIS)[1],其中包括在6个区域的271个房间。从 3 个不同的建筑物扫描 2.73 亿个点,每个点都附有 13 个类别的一个语义标签。
应用
我们使用PAConv来替换Pointnet++[39]编码器中的 MLP。我们按照 [39] 来准备训练数据,其中点被统一采样到面积 1 米× 1 米的区域块中,每个点由 9 维矢量(XYZ、RGB和房间中的规范化位置)表示。我们从每个块中随机抽取4096个点,所有点均采用进行测试。在[48]之后,我们利用第5区域作为测试,其他所有区域用于训练。数据增强包括随机缩放、旋转和扰动点。在 [30] 之后采用与分类任务相同的投票测试方案。
注释:
与我们的块采样策略不同,KPConv [49] 和 PosPool [31] 将点云转化成网格。在训练期间,实际实施中的输入点数量非常大(≈ 10×我们的)。虽然这带来了更常规的数据结构和更多的上下文信息,以获得更好的性能,但它在训练期间受到高内存使用的影响。
结果
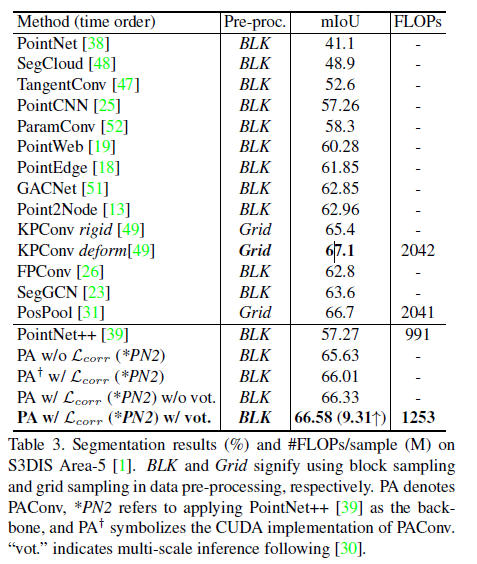
对于评价指标,我们使用类间的平均交并比(mIoU)。如表3所示,我们使用Lcorr的PAConv (w/ Lcorr)在所有使用对预处理的数据进行块采样的方法中获得了最好的mIoU。PAConv还大力提升了PointNet++ 9.31%的性能。未投票的结果(无票)也列出。分割结果可视化如图4所示。补充材料中提供了6倍交叉验证的结果和每个类别的mIoU。
时间复杂度
此外,我们取4096个点作为输入,并测试变形KPConv [49]和PosPool[31]的时间复杂度(浮点操作/样本),如表3所示。这表明我们的PAConv以较少的计算浮点操作脱颖而出(下降了38.6%)。
6、消融实验
为了更好地理解PAConv,在S3DIS[1]数据集上进行了消融研究。除非另有规定,否则无相关损失(第3.3节)添加到PAConv中。
6.1 ScoreNet
ScoreNet输入
我们首先探讨了分数网的不同输入表示。如表4所示,当ScoreNet输入携带来自所有三个轴的信息时,PAConv可以有效地利用丰富的关系来学习ScoreNet并获得最佳性能。

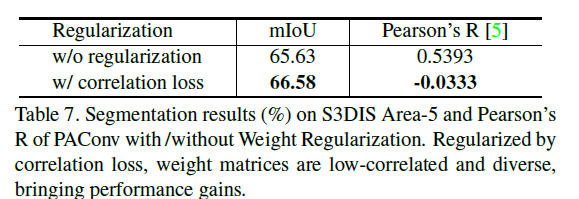
分数归一化
我们也研究了广泛使用的归一化函数,以调整得分分布。表5显示Softmax规范化优于其他方案。这表明,预测所有权重矩阵的整体得分(Softmax)优于单独考虑每个得分(Sigmoid和Tanh)。
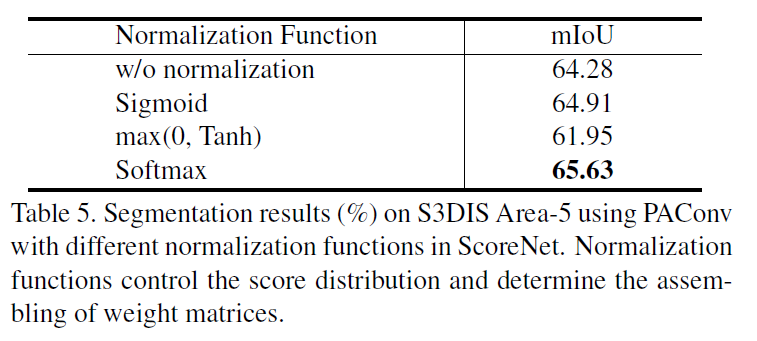
三维空间中的分数分布
更重要的是,图 5 显示了学习分数分布和不同空间平面之间的关系。值得注意的是,对于每个权重矩阵Bi、Bj、Bk,输出分数分布不同,表明不同的权重矩阵捕获不同的位置关系。补充材料中包括了 ScoreNet 上的更多探索。
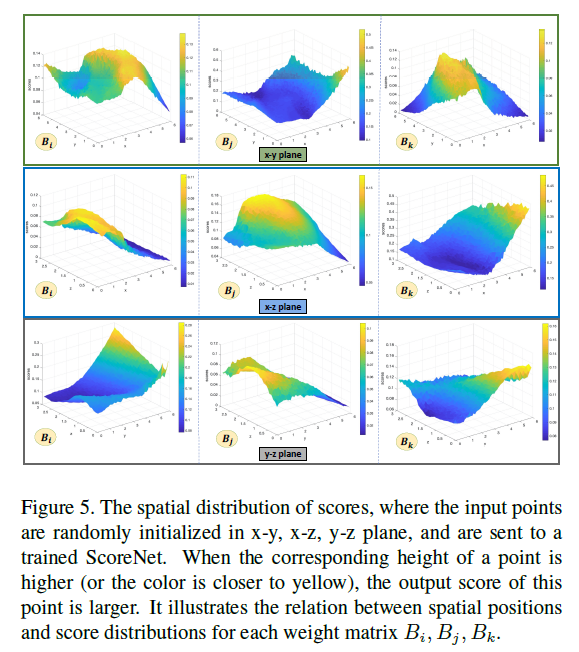
6.2权重矩阵的个数
我们进一步进行实验,以找出表6中显示的权重矩阵数量的影响。当权重矩阵数为2 时,性能为 65.05%,与16个权重矩阵相差仅 0.58%。这可以归因于我们的内核组装策略,因为即使只有 2 个重量矩阵,也会生成不同的内核。这无疑显示了我们提出的方法的力量。但是,当数字变大时,由于优化问题,相对性能提升会波动。最后,当数字为 16 时,我们实现了最佳和最稳定的性能。
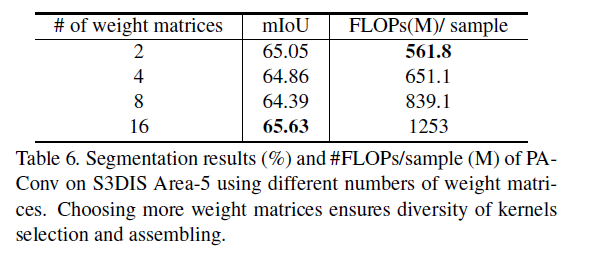
6.3 权重库归一化
正如第3.3节所述,权重归一化鼓励权重矩阵彼此关联性低,从而保证了内核组装的多样性。我们利用 Pearson 的 R [5] 来测量不同重量矩阵之间的相关性,并报告皮尔逊的平均 R(较低的皮尔逊 R 值意味着较低的相关性)。如表 7 所示,PAConv 的相关损失在场景分割任务中以 0.95 mIoU 优于基线,而 Pearson 的 R 权重矩阵之间的 R 显著下降。
6.4 鲁棒性分析
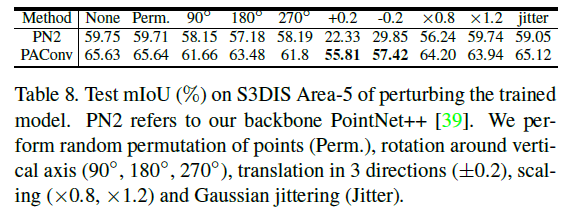
PAConv使用一个对称函数来聚合邻居特征,使其对排列具有不变性,提升它对旋转的鲁棒性。此外,通过从可能包含不同变换的局部空间关系中学习到的分数来组装核,进一步增强了鲁棒性。我们也在这方面评估我们的模型。如表8所示,PAConv在不同的变换下运行稳定。
7、总结
我们提出了一种基于动态核组装的位置自适应卷积算子PAConv。PAConv结合权重库中的基本权重矩阵构造卷积核,通过ScoreNet从点位置学习相关系数。当嵌入到简单的基于MLP的网络中而不修改网络配置时,PAConv接近甚至超过了最新技术水平,并且显著优于基线,具有良好的模型效率。大量的实验和消融研究证实了PAConv的有效性。
附录
略
论文笔记:(2021CVPR)PAConv: Position Adaptive Convolution with Dynamic Kernel Assembling on Point Clouds的更多相关文章
- 论文笔记:(2019)LDGCNN : Linked Dynamic Graph CNN-Learning on PointCloud via Linking Hierarchical Features
目录 摘要 一.引言 A.基于视图的方法 B.基于体素的方法 C.基于几何的方法 二.材料 三.方法 A.问题陈述 B.图生成 C.图特征提取 D.变换不变函数 E.LDGCNN架构 F.冻结特征提取 ...
- 论文笔记:(2019CVPR)PointConv: Deep Convolutional Networks on 3D Point Clouds
目录 摘要 一.前言 1.1直接获取3D数据的传感器 1.2为什么用3D数据 1.3目前遇到的困难 1.4现有的解决方法及存在的问题 二.本文idea 2.1 idea来源 2.2 初始思路 2.3 ...
- Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现(转)
Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文, ...
- 论文笔记系列-Neural Network Search :A Survey
论文笔记系列-Neural Network Search :A Survey 论文 笔记 NAS automl survey review reinforcement learning Bayesia ...
- 论文笔记:Mastering the game of Go with deep neural networks and tree search
Mastering the game of Go with deep neural networks and tree search Nature 2015 这是本人论文笔记系列第二篇 Nature ...
- Deep Learning论文笔记之(三)单层非监督学习网络分析
Deep Learning论文笔记之(三)单层非监督学习网络分析 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文,但老感 ...
- Self-paced Clustering Ensemble自步聚类集成论文笔记
Self-paced Clustering Ensemble自步聚类集成论文笔记 2019-06-23 22:20:40 zpainter 阅读数 174 收藏 更多 分类专栏: 论文 版权声明 ...
- 论文笔记-IGCV3:Interleaved Low-Rank Group Convolutions for Efficient Deep Neural Networks
论文笔记-IGCV3:Interleaved Low-Rank Group Convolutions for Efficient Deep Neural Networks 2018年07月11日 14 ...
- 深度学习论文笔记:Fast R-CNN
知识点 mAP:detection quality. Abstract 本文提出一种基于快速区域的卷积网络方法(快速R-CNN)用于对象检测. 快速R-CNN采用多项创新技术来提高训练和测试速度,同时 ...
随机推荐
- Redis big key处理
bigkey是指key对应的value所占的内存空间比较大,例如一个字符串类型的value 可以最大存到512MB,-个列表类型的value最多可以存储2^32-1个元素.如果按照数据结构来细分的话, ...
- Windows10 上Docker 安装运行Gitlab
准备条件 安装好Docker For Windows客户端. 配置好Docker 阿里云加速镜像地址. 检查Docker版本,大于等于v19. 拉取Gitlab镜像 docker pull gitla ...
- 11、文件比较与同步工具(FreeFileSync)
11.1.基本介绍: 1.FreeFileSync是一个用于文件同步的免费开源程序.FreeFileSync通过比较其内容,日期或文件大小上的一个或多个文件夹,然 后根据用户定义的设置同步内容.除了支 ...
- 基于uniapp自定义Navbar+Tabbar组件「兼容H5+小程序+App端Nvue」
uni-app跨端自定义navbar+tabbar组件|沉浸式导航条|仿咸鱼凸起标签栏 在跨端项目开发中,uniapp是个不错的框架.采用vue.js和小程序语法结构,使得入门开发更容易.拥有非常丰富 ...
- AcWing 1128. 信使
战争时期,前线有 n个哨所,每个哨所可能会与其他若干个哨所之间有通信联系. 信使负责在哨所之间传递信息,当然,这是要花费一定时间的(以天为单位). 指挥部设在第一个哨所.当指挥部下达一个命令后,指挥部 ...
- 初入web前端---实习(职场菜鹏)
作为一个大四的准职场新人,顺利的找到了一份自己想从事的工作---web前端开发.
- CentOS-Docker搭建Kafka(单点,含:zookeeper、kafka-manager)
Docker搭建Kafka(单点,含:zookeeper.kafka-manager) 下载相关容器 $ docker pull wurstmeister/zookeeper $ docker pul ...
- Https:Java代码设置使用证书访问Https
设置证书进行访问或被访问操作 String keyStore = "keyStore的文件路径": String KEY_STORE_PWD = "1234"; ...
- 关于easyswoole实现websocket聊天室的步骤解析
在去年,我们公司内部实现了一个聊天室系统,实现了一个即时在线聊天室功能,可以进行群组,私聊,发图片,文字,语音等功能,那么,这个聊天室是怎么实现的呢?后端又是怎么实现的呢? 后端框架 在后端框架上,我 ...
- php漏洞 strcmp漏洞
0x01: 背景:strcmp函数,参数是两个字符串,相等返回为零,大于,返回大于零,小于,返回小于零. 0x02: 如果传入的值,不是字符串的话,会报错,同时使得两个字符串直接相等,返回为零. 一般 ...