论文解读(DGI)《DEEP GRAPH INFOMAX》
论文标题:DEEP GRAPH INFOMAX
论文方向:图像领域
论文来源:2019 ICLR
论文链接:https://arxiv.org/abs/1809.10341
论文代码:https://github.com/PetarV-/DGI
摘要
DGI,一种以无监督的方式学习图结构数据中节点表示的一般方法。DGI 依赖于最大限度地扩大图增强表示和目前提取到的图信息之间的互信息——两者都是使用已建立的图卷积网络体系结构导出的。对于图增强表示,是根据目标节点所生成的子图,因此可以用于下游节点的表示学习任务。与大多数以前使用 GCN 进行无监督学习的方法相比,DGI不依赖于随机游走目标,并且很容易适用于直推式学习和归纳式学习。我们在各种节点分类基准上展示了竞争性能,有时甚至超过了监督学习的性能。
1 介绍
将神经网络推广到图形结构输入是当前机器学习的主要挑战之一。虽然最近取得了重大进展,特别是图卷积网络,但大多数成功的方法使用监督学习,这往往是不可能的,因为大多数图表数据是未标记的。 此外,从大规模图中发现新颖或有趣的结构往往是可取的,因此,无监督的图学习对于许多重要的任务是必不可少的。
目前,具有图结构数据的无监督表示学习的主要算法依赖于基于随机游走的目标,有时进一步简化以重建邻接信息。基本的直觉是训练编码器网络,使输入图中的“接近”节点在表示空间中也“接近”。虽然功能强大,而且与传统的衡量标准(如个性化PageRank评分)相关,但随机游走方法受到已知的限制。最突出的是,随机游走目标以牺牲结构信息为代价过分强调邻近信息,并且性能高度依赖于超参数的选择。此外,随着基于图卷积的更强的编码器模型的引入,目前还不清楚随机游走目标是否真的提供了任何有用的信号,因为这些编码器已经强制产生了一种归纳式偏差,即相邻节点具有类似的表示。
在这项工作中,我们提出了一种用于无监督图学习的替代目标,这种目标是基于互信息,而不是随机游走。在概率论和信息论中,两个随机变量的互信息(Mutual Information,简称MI)是指变量间相互依赖性的量度。近年来基于互信息的代表性工作是 Mutual Information Neural Estimation (MINE),其中提出了一种 Deep InfoMax (DMI) 方法来学习高维数据的表示。具体来说 DMI 训练一个编码模型来最大化高阶全局表示和输入的局部部分的互信息(如果从 cv 的角度理解就是一张图片中的 patches)。这鼓励编码器携带出现在所有位置的信息类型(因此是全局相关的),例如类标签的情况。
2 相关工作
2.1 对比方法
对于无监督学习一类重要的方法就是对比学习,通过训练编码器使它在特征表示中更具判别性来捕获感兴趣的和不感兴趣的统计依赖性。例如,对比方法可以使用评分函数,训练编码器来增加“真实”输入的分数,并减少“假”输入的分数,以此判别真实数据和假数据。有很多方法可以对一个表示进行打分,但在图形文献中,最常见的技术是使用分类,尽管也会使用其他的打分函数。DGI在这方面也是对比性的,因为DGI目标是基于对局部-全局对和负抽样配对的分类。
2.2 抽样战略
对比方法的一个关键实现细节是如何绘制正负样本。关于无监督图表示学习的先前工作依赖于局部对比损失(强制近端节点具有相似的嵌入)。从语言建模的角度来看,正样本通常对应于在图中短时间的随机游走中一起出现的节点对,有效地将节点视为单词,将随机游走视为句子。最近有的方法提出使用节点锚定采样作为替代。这些方法的负采样主要是基于随机对的抽样。
2.3 预测编码
对比预测编码 Contrastive predictive coding (CPC) 是另一种基于互信息最大化的深度表示的学习方法。CPC 也是一种对比学习方法,它使用条件密度的估计(以噪声对比估计的形式)作为评分函数。然而,与 DGI 不同的是,CPC是预测性的:对比目标有效地训练了输入的结构指定部分(例如,相邻节点对之间或节点与其邻居之间)之间的预测器。DGI 不同之处在于同时对比一个图的全局/局部部分,其中全局变量是从所有的局部变量计算出来的。
3 DGI Methodology
在本节中,我们将以自上而下的方式介绍DGI方法:首先是对我们特定的无监督学习设置的抽象概述,然后是对我们的方法优化的目标函数的阐述,最后是在单图设置中枚举我们过程的所有步骤。
3.1 基于图的无监督学习
我们假设一个通用的基于图的无监督机器学习设置:
首先给出一组节点特征, $X=\left\{\vec{x}_{1}, \overrightarrow{x_{2}}, \ldots, \overrightarrow{x_{N}}\right\}$ , 其中 $ N$ 是图中的节点数, $ \vec{x}_{i} \in \mathbb{R}^{F}$ 代表节点 $i$ 的特征表示。邻接矩阵 $ A \in \mathbb{R}^{N \times N}$ , 在本文中默认所有处理的图是无权图, 同时邻接矩阵存储的值为 $0$ 或 $1$。
模型的目的是学习一个编码器,$ \varepsilon: \mathbb{R}^{N \times F} \times \mathbb{R}^{N \times N} \rightarrow \mathbb{R}^{N \times F^{\prime}} $,可以形式化的表示为 $ \mathcal{E}(\boldsymbol{X}, \boldsymbol{A})=\boldsymbol{H}=\left\{\overrightarrow{h_{1}}, \overrightarrow{h_{2}}, \ldots, \overrightarrow{h_{N}}\right\}$ ,其中 $ H$ 代表高阶表示, 并且每个节点 $i$ 满足 $ \overrightarrow{h_{i}} \in \mathbb{R}^{F^{\prime}} $ 。所得到的节点特征的高阶表示可以用于各种下游任务,例如节点分类任务。
在这里,我们将重点讨论图卷积编码器,它通过不断聚合目标节点周边的邻居来完成特征学习。它所产生的 $ \vec{h}_{i}$ 总结了以节点为中心的图的一个 patch,而不仅仅是节点本身。在接下来的内容中,我们通常将 $ \vec{h}_{i}$ 称为 patch representations 来强调这一点。
3.2 局部-全局互信息最大化
DGI 的核心思想在于通过最大化局部互信息来训练编码器——即 DGI 寻求获得节点(即局部)表示,以捕获整个图的全局信息(表示为summary vector,$\vec{s}$)。
为了得到 图级别的 summary vector $ \vec{s} $,作者提出了一种 readout 函数,$ \mathcal{R}: \mathbb{R}^{N \times F} \rightarrow \mathbb{R}^{F}$ ,利用它将获得的 patch representations 总结为图级别的表示。上述过程可以总结为 $ \vec{s}=\mathcal{R}(\mathcal{E}(\boldsymbol{X}, \boldsymbol{A}))$ 。
作为最大化局部互信息的指标,我们使用了一个 discriminator,$ \mathcal{D}: \mathbb{R}^{F} \times \mathbb{R}^{F} \rightarrow \mathbb{R}$, 这样 $\mathcal{D}\left(\vec{h}_{i}, \vec{s}\right) $ 表示分配给这个 patch-summary 对的概率分数(对于包含在 summary 中的 patch 应该更高) 。
$\mathcal{D}$ 的负样本由 $ (\boldsymbol{X}, \boldsymbol{A})$ 的 summary vector $ \vec{s}$ 与一个可选择的图 $ (\widetilde{\boldsymbol{X}}, \widetilde{\boldsymbol{A}}) $ 的 patch representations $ \vec{h}_{j}$ 提供。在多图的数据集中,$ (\widetilde{\boldsymbol{X}}, \widetilde{\boldsymbol{A}}) $ 可以通过训练集的其他元素获得。但是,对于单个图,需要一个显式(随机 ) corruption function,$ \mathcal{C}: \mathbb{R}^{N \times F} \times \mathbb{R}^{N \times N} \rightarrow \mathbb{R}^{M \times F} \times \mathbb{R}^{M \times M} $ 来生成负样本的图 $(\widetilde{\boldsymbol{X}}$,$\widetilde{\boldsymbol{A}}) $ 。 上述过程可以表述为 $ (\widetilde{\boldsymbol{X}}, \widetilde{\boldsymbol{A}})=\mathcal{C}(\boldsymbol{X}, \boldsymbol{A}) $
负样本抽样程序的选择将决定着作为这种最大化的副产品所希望捕获的具体结构信息的种类。
对于目标,我们遵循 Deep InfoMax,使用带有标准二值交叉熵 (BCE) 损失的橾声对比型目标函数(正样本和负样本之间):
$\mathcal{L}=\frac{1}{N+M}\left(\sum \limits _{i=1}^{N} \mathbb{E}_{(\mathbf{X}, \mathbf{A})}\left[\log \mathcal{D}\left(\vec{h}_{i}, \vec{s}\right)\right]+\sum \limits_{j=1}^{M} \mathbb{E}_{(\tilde{\mathbf{X}}, \tilde{\mathbf{A}})}\left[\log \left(1-\mathcal{D}\left(\overrightarrow{\widetilde{h}}_{j}, \vec{s}\right)\right)\right]\right)$
3.3 DGI概述
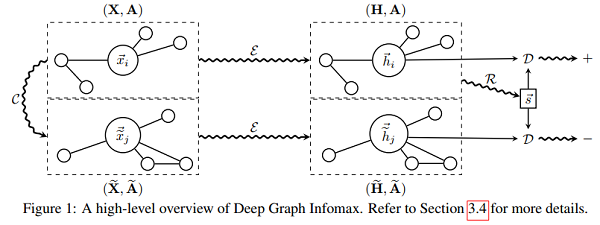
假设单图设置(即 $(\boldsymbol{X}, \boldsymbol{A}) $ 作为输入, DGI 的步骤:
1. 通过 corruption function 得到负样本实例: $ (\widetilde{X}, \widetilde{\boldsymbol{A}}) \sim \mathcal{C}(\boldsymbol{X}, \boldsymbol{A}) $ 。
2. 通过编码器获得输入图的 patch representations $\overrightarrow{h_{i}}: \boldsymbol{H}=\mathcal{E}(\boldsymbol{X}, \boldsymbol{A})=\left\{\overrightarrow{h_{1}}, \overrightarrow{h_{2}}, \ldots, \overrightarrow{h_{N}}\right\} $
3. 通过编码器获得负样本的 patch representations $\vec{h}_{j}: \widetilde{H}=\mathcal{E}(\widetilde{X}, \widetilde{A})=\left\{\vec{h}_{1}, \vec{h}_{2}, \ldots, \widetilde{h}_{M}\right\} $
4. 通过 Readout 函数传递输入图的 patch representations 来得到图级别的 summary vector: $ \vec{s}=\mathcal{R}(\boldsymbol{H})$ 。
5. 通过梯度下降法最小化目标函数式 (1),更新参数 $\mathcal{E}, \mathcal{R}, \mathcal{D}$。
4 实验
4.1 数据集
我们评估了 DGI 编码器在各种节点分类任务(直推式学习 [ transductive ] 和归纳式学习 [ inductive ])上学习的表示的好处,获得了有竞争力的结果。在每种情况下,DGI都被用来以完全无监督的方式学习 patch representations,然后评估这些表示的节点级分类效用。这是通过直接使用这些表示来训练和测试一个简单的线性(逻辑回归)分类器来实现的。

- 在 Cora、Citeseer 和 Pubmed 引文网络上对研究论文进行主题分类。
- 以Reddit帖子为模型预测社交网络的社区结构。
- 对蛋白质-蛋白质相互作用(PPI)网络中的蛋白质作用进行分类,需要对未见网络进行归纳。
4.2 实验设置
对于三个实验设置(直推式学习、大图上的归纳式学习和多图上的归纳式学习)中的每一个,我们使用了与该设置相适应的不同编码器和 corruption function。
4.2.1 直推式学习
直推式学习 Transductive learning
编码器是一层图卷积网络(GCN)模型,具有以下传播规则:
$\mathcal{E}(\mathbf{X}, \mathbf{A})=\sigma\left(\hat{\mathbf{D}}^{-\frac{1}{2}} \hat{\mathbf{A}} \hat{\mathbf{D}}^{-\frac{1}{2}} \mathbf{X} \boldsymbol{\Theta}\right)$
其中, $\hat{A}=A+I_{N} $ 代表加上自环的邻接矩阵, $\hat{D}$ 代表相应的度矩阵,满足 $\hat{D}_{i i}=\sum_{j} \hat{A}_{i j}$ 对于非线性激活函数 $\sigma$ ,选择 PReLU(parametric ReLU)。$\Theta \in R^{F \times F^{\prime}} $ 是应用于每个节点的可学习线性变换。
对于 corruption function C ,直接采用 $ \widetilde{A}=A$,但是 $ \widetilde{X}$ 是由原本的特征矩阵 $X$ 经过随机变换得到的。也就是说,损坏的图(corrupted graph)由与原始图完全相同的节点组成,但它们位于图中的不同位置,因此将得到不同的邻近表示。
4.2.2 大图上的归纳式学习
归纳式学习 Inductive learning
对于归纳学习,不再在编码器中使用 GCN 更新规则(因为学习的滤波器依赖于固定的和已知的邻接矩阵);相反,我们应用平均池( mean-pooling)传播规则,GraphSAGE-GCN:
$\operatorname{MP}(\mathbf{X}, \mathbf{A})=\hat{\mathbf{D}}^{-1} \hat{\mathbf{A}} \mathbf{X} \Theta$
$\widehat{D} ^{-1}$ 实际上执行的是标准化的和(因此是 mean-pooling)。尽管上式明确指定了邻接矩阵和度矩阵,但并不需要它们:因为 Const-GAT 模型中使用的持续关注机制可以观察到相同的归纳行为。
对于 Reddit 数据库,DGI 的编码器是一个带有跳跃连接的三层均值池模型:
$\widetilde{\mathrm{MP}}(\mathbf{X}, \mathbf{A})=\sigma\left(\mathbf{X} \Theta^{\prime} \| \operatorname{MP}(\mathbf{X}, \mathbf{A})\right) \quad \mathcal{E}(\mathbf{X}, \mathbf{A})=\widetilde{\mathrm{MP}}_{3}\left(\widetilde{\mathrm{MP}}_{2}\left(\widetilde{\mathrm{MP}}_{1}(\mathbf{X}, \mathbf{A}), \mathbf{A}\right), \mathbf{A}\right)$
这里 || 是 featurewise concatenation 。由于数据集的规模很大,它将不能完全适合 GPU内存。因此,采用 子抽样(subsampling)方法,首先选择小批量的节点,然后,通过对具有替换的节点邻域进行抽样,得到以每个节点为中心的子图。具体来说,DGI 在第一层、第二层和第三层分别采样 10、10 和 25 个邻居,这样每次采样的 patch 有 1 + 10 + 100 + 2500 = 2611 个节点。只进行了推导中心节点 i 的 patch 表示 $h_I$ 所必需的计算。这些表示然后被用来为 minibatch(图2)导出总结向量 $\overrightarrow{s} $ 。在整个训练过程中使用了 256 个节点的 minibatch 。
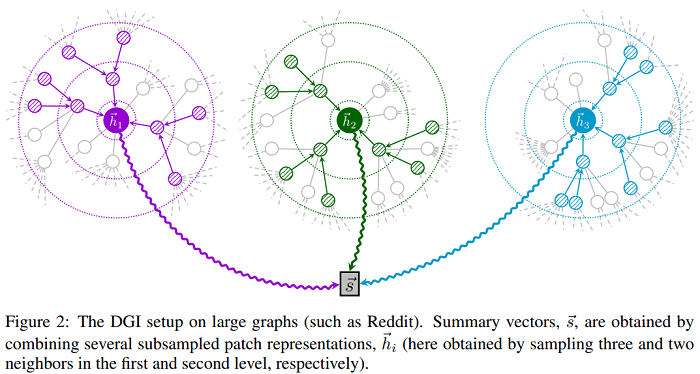
图2中,摘要向量 $\vec{s} $ 是通过组合几个子采样的邻近表示 $\vec{h}_{i} $ 得到的。
4.2.3 多图上的归纳式学习
例如 PPI 数据集,编码器是一个带有密集跳过连接的三层均值池模型
$\mathbf{H}_{1}=\sigma\left(\operatorname{MP}_{1}(\mathbf{X}, \mathbf{A})\right)$
$\mathbf{H}_{2}=\sigma\left(\mathbf{M P}_{2}\left(\mathbf{H}_{1}+\mathbf{X} \mathbf{W}_{\text {skip }}, \mathbf{A}\right)\right)$
$\mathcal{E}(\mathbf{X}, \mathbf{A})=\sigma\left(\mathbf{M P}_{3}\left(\mathbf{H}_{2}+\mathbf{H}_{1}+\mathbf{X} \mathbf{W}_{\text {skip }}, \mathbf{A}\right)\right)$
其中,$W_{skip}$ 是一个可学习的投影矩阵。
在这个多图设置中,DGI 选择使用随机抽样的训练图作为负样本(即,DGI 的破坏函数只是从训练集中抽样一个不同的图)。作者发现该方法是最稳定的,因为该数据集中超过 40% 的节点具有全零特征(all-zero features)。为了进一步扩大负样本池,作者还将 dropout 应用于采样图的输入特征。作者发现,在将学习到的嵌入信息提供给逻辑回归模型之前,将其标准化是有益的。
4.2.4 Readout,discriminator 的细节
在所有三个实验设置中,作者使用了相同的readout函数和discriminator体系结构。
对于 Readout Function,作者使用所有节点特征的简单平均值:
$\mathcal{R}(\mathbf{H})=\sigma\left(\frac{1}{N} \sum \limits _{i=1}^{N} \vec{h}_{i}\right)$
作者通过应用一个简单的双线性评分函数对图级别的 summarize-patch representation 对进行评分:
$\mathcal{D}\left(\vec{h}_{i}, \vec{s}\right)=\sigma\left(\vec{h}_{i}^{T} \mathbf{W} \vec{s}\right)$
其中, $W$ 是一个可学习的评分权重参数, $\sigma$ 是逻辑 Sigmoid 非线性, 用于将分数转换为 $(\vec{h}_{i}, \vec{s})$ 为正对的概率。
4.3 结果
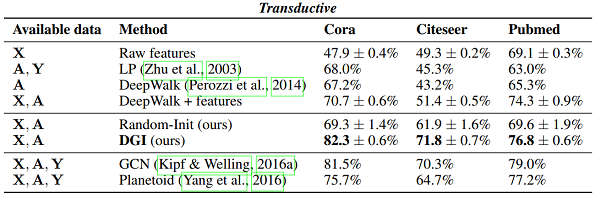
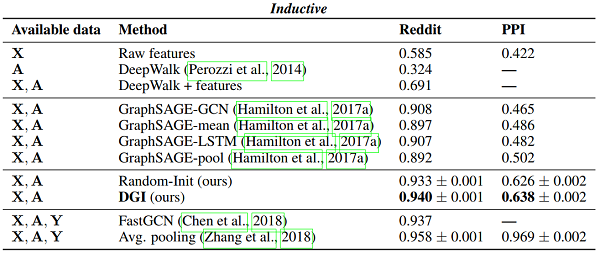
根据分类准确性(在 transductive tasks)或 micro-averaged $F_1$ score(在归纳任务)的结果总结。在第一列中,我们突出显示了训练期间每个方法可用的数据类型(X:特征,A:邻接矩阵,Y:标签)。"GCN" 对应于以监督方式训练的两层 DGI 编码器。

知识点:
Q:互信息(Mutual Information)
互信息(Mutual Information)是度量两个事件集合之间的相关性(mutual dependence),它是信息论里一种有用的信息度量,它可以看成是一个随机变量中包含的关于另一个随机变量的信息量,或者说是一个随机变量由于已知另一个随机变量而减少的不肯定性。互信息最常用的单位是bit。互信息指的是两个随机变量之间的关联程度,即给定一个随机变量后,另一个随机变量不确定性的削弱程度,因而互信息取值最小为0,意味着给定一个随机变量对确定一另一个随机变量没有关系,最大取值为随机变量的熵,意味着给定一个随机变量,能完全消除另一个随机变量的不确定性。
直观上,互信息度量 X 和 Y 共享的信息:它度量知道这两个变量其中一个,对另一个不确定度减少的程度。例如,如果 X 和 Y 相互独立,则知道 X 不对 Y 提供任何信息,反之亦然,所以它们的互信息为零。在另一个极端,如果 X 是 Y 的一个确定性函数,且 Y 也是 X 的一个确定性函数,那么传递的所有信息被 X 和 Y 共享:知道 X 决定 Y 的值,反之亦然。因此,在此情形互信息与 Y(或 X)单独包含的不确定度相同,称作 Y(或 X)的熵。而且,这个互信息与 X 的熵和 Y 的熵相同。
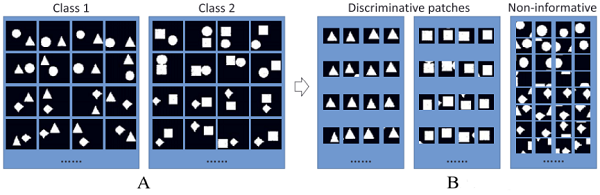
Q:什么是 patch?
在 CNN 学习训练过程中,不是一次来处理一整张图片,而是先将图片划分为多个小的块,内核/过滤器 kernel 每次只查看图像的一个块,这一个小块就称为 patch,然后过滤器移动到图像的另一个patch,以此类推。
当将 CNN 过滤器应用到图像时,它会一次查看一个 patch 。
CNN 内核/过滤器 一次只处理一个 patch,而不是整个图像。这是因为我们希望过滤器处理图像的小块以便检测特征(边缘等)。这也有一个很好的正则化属性,因为我们估计的参数数量较少,而且这些参数必须在每个图像的许多区域以及所有其他训练图像的许多区域都是“好”的。
所以 patch 就是内核 kernel 的输入。这时内核的大小便是 patch 的大小。
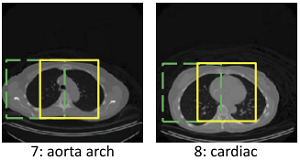
如图,主动脉弓和心脏,绿色部分相同,而黄色部分不同。传统的CNN算法,区分效果不佳。在 Multi-Instance Multi-Stage Deep Learning for Medical Image Recognition 这篇文章中,作者针对这种场景提出了解决方法。
$\begin{array}{l} L_{1}(\mathbf{W})=\sum_{\mathbf{x}_{m} \in \mathcal{T}}-\log \left(\mathbf{P}\left(l_{m} \mid \mathbf{X}_{m} ; \mathbf{W}\right)\right) \\ L_{2}(\mathbf{W})=\sum_{\mathbf{X}_{m} \in \mathcal{T}}-\log \left(\max _{\mathbf{x}_{m n} \in \mathcal{L}\left(\mathbf{X}_{m}\right)} \mathbf{P}\left(l_{m} \mid \mathbf{x}_{m n} ; \mathbf{W}\right)\right) \end{array}$
这样训练出的网络,就会对有区分度的patch敏感,而对无区分度的无感。
一个CNN层生成一个中间表示。该表示被传递到下一层。如果下一层是CNN,则应用完全相同的“patch”概念,并以完全相同的方式进行计算,即使中间表示不是您或我可以识别为“图像”的东西。
Q:什么是 macro-F1,micro-F1
macro-F1 和 micro-F1,宏观F1值和微观F1值,考虑的是在多标签(Multi-label)情况下,分类效果的评估方式。
比如 Multi-label 性别男或女(0/1)以及是否是学生(0/1);当然 Multi-class也可以通过一定的编码方式转化为 Multi-label,如原始类别 1,2,3,4,独热编码后可用四元向量表示 [0,1,0,0] 即表示类标 2。
macro-F1 和 micro-F1 正是基于分类目的的多样性,将只适用于 Binary 分类的 F1 值推广了:
论文解读(DGI)《DEEP GRAPH INFOMAX》的更多相关文章
- 论文解读《Deep Attention-guided Graph Clustering with Dual Self-supervision》
论文信息 论文标题:Deep Attention-guided Graph Clustering with Dual Self-supervision论文作者:Zhihao Peng, Hui Liu ...
- 论文解读《Bilinear Graph Neural Network with Neighbor Interactions》
论文信息 论文标题:Bilinear Graph Neural Network with Neighbor Interactions论文作者:Hongmin Zhu, Fuli Feng, Xiang ...
- 论文解读《Deep Resdual Learning for Image Recognition》
总的来说这篇论文提出了ResNet架构,让训练非常深的神经网络(NN)成为了可能. 什么是残差? "残差在数理统计中是指实际观察值与估计值(拟合值)之间的差."如果回归模型正确的话 ...
- 论文解读《Deep Plug-and-Play Super-Resolution for Arbitrary Blur Kernel》
Deep Plug-and-Play Super-Resolution for Arbitrary Blur Kernels: 一旦退化模型被定义,下一步就是使用公式表示能量函数(energy fun ...
- 论文解读《Cauchy Graph Embedding》
Paper Information Title:Cauchy Graph EmbeddingAuthors:Dijun Luo, C. Ding, F. Nie, Heng HuangSources: ...
- 论文解读(SUGRL)《Simple Unsupervised Graph Representation Learning》
Paper Information Title:Simple Unsupervised Graph Representation LearningAuthors: Yujie Mo.Liang Pen ...
- 论文解读(MPNN)Neural Message Passing for Quantum Chemistry
论文标题:DEEP GRAPH INFOMAX 论文方向: 论文来源:ICML 2017 论文链接:https://arxiv.org/abs/1704.01212 论文代码: 1 介绍 本文的目标 ...
- 论文解读(GRACE)《Deep Graph Contrastive Representation Learning》
Paper Information 论文标题:Deep Graph Contrastive Representation Learning论文作者:Yanqiao Zhu, Yichen Xu, Fe ...
- 论文解读(DCRN)《Deep Graph Clustering via Dual Correlation Reduction》
论文信息 论文标题:Deep Graph Clustering via Dual Correlation Reduction论文作者:Yue Liu, Wenxuan Tu, Sihang Zhou, ...
随机推荐
- SpringBoot开发九-生成验证码
需求介绍-生成验证码 先生成随机字符串然后利用Kaptcha API生成验证图片 代码实现 先在pom.xml引入 <dependency> <groupId>com.gith ...
- java8-stream常用操作(1)
前言 java8的Stream 流式操作,用于对集合进行投影.转换.过滤.排序.去重等,更进一步地说,这些操作能链式串联在一起使用,类似于 SQL 语句,可以大大简化代码.下面我就将平时常用的一些st ...
- 关于phpmyadmin getshell
思考一个问题:如何在获得一个PHP MySQL 搭建网站的phpmyadmin界面后(无论用什么办法,进到phpmyadmin里),进行一个getshell的操作? ...... 0x01山重水复 当 ...
- NOIP 模拟 $36\; \rm Cicada 与排序$
题解 \(by\;zj\varphi\) 设 \(rk_{i,j}\) 表示第 \(i\) 个数最后在相同的数里排第 \(j\) 位的概率. 转移时用一个 \(dp\),\(dp_{i,j,0/1}\ ...
- NOIP 模拟 $25\; \rm random$
题解 \(by\;zj\varphi\) 期望好题. 通过推规律可以发现每个逆序对的贡献都是 \(1\),那么在所有排列中有多少逆序对,贡献就是多少. \[\rm num_i=(i-1)!\sum_{ ...
- 【硬件模块】RFIDSetting
The Octane SDK includes the core library by acting as a wrapper for extraction, modifying, and the a ...
- PS与CSS字间距转换
字间距: 实际像素大小 real_letter_spacing,(单位为px) 文字字号 font,(单位为px) 文字间距 spacing, 它们的换算关系为: real_letter_spacin ...
- C++ com 组件的使用
// CommonTest.cpp : This file contains the 'main' function. Program execution begins and ends there. ...
- echatrts 各参数快速了解(+实例)
实例:https://www.jianshu.com/p/8cac22daca98 参数详解:https://echarts.baidu.com/option.html#title.textStyle ...
- jQuery中ajax请求的六种方法(三、六):load()方法
6.load()方法 load的html页面 <!DOCTYPE html> <html> <head> <meta charset="UTF-8& ...