mysql 数据库 分表后 怎么进行分页查询?Mysql分库分表方案?
Mysql分库分表方案
1.为什么要分表:
当一张表的数据达到几千万时,你查询一次所花的时间会变多,如果有联合查询的话,我想有可能会死在那儿了。分表的目的就在于此,减小数据库的负担,缩短查询时间。
mysql中有一种机制是表锁定和行锁定,是为了保证数据的完整性。表锁定表示你们都不能对这张表进行操作,必须等我对表操作完才行。行锁定也一样,别的sql必须等我对这条数据操作完了,才能对这条数据进行操作。
2. mysql proxy:amoeba
做mysql集群,利用amoeba。
从上层的java程序来讲,不需要知道主服务器和从服务器的来源,即主从数据库服务器对于上层来讲是透明的。可以通过amoeba来配置。
3.大数据量并且访问频繁的表,将其分为若干个表。
比如对于某网站平台的数据库表-公司表,数据量很大,这种能预估出来的大数据量表,我们就事先分出个N个表,这个N是多少,根据实际情况而定。
某网站现在的数据量至多是5000万条,可以设计每张表容纳的数据量是500万条,也就是拆分成10张表。
那么如何判断某张表的数据是否容量已满呢?可以在程序段对于要新增数据的表,在插入前先做统计表记录数量的操作,当<>
4. 利用merge存储引擎来实现分表
如果要把已有的大数据量表分开比较痛苦,最痛苦的事就是改代码,因为程序里面的sql语句已经写好了。用merge存储引擎来实现分表, 这种方法比较适合.
举例子:
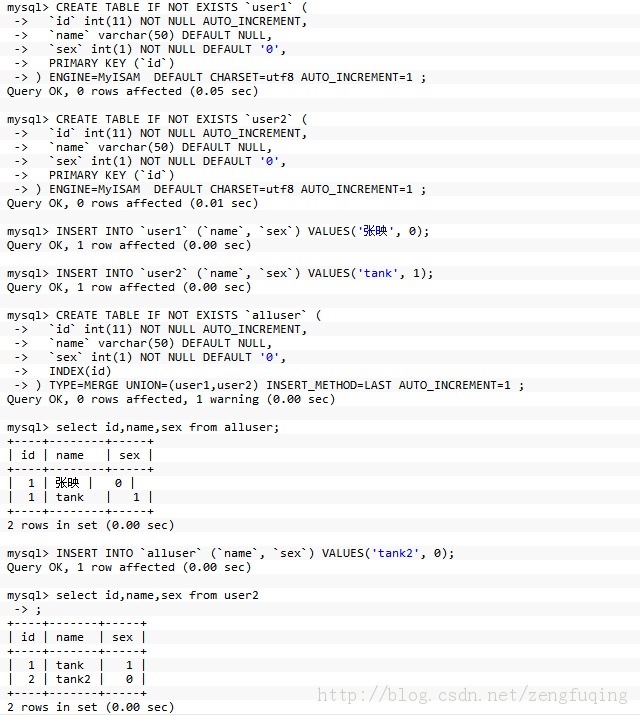
------------------- ----------华丽的分割线--------------------------------------
数据库架构
1、简单的MySQL主从复制:
数据库架构
1、简单的MySQL主从复制:
MySQL的主从复制解决了数据库的读写分离,并很好的提升了读的性能,其图如下:

其主从复制的过程如下图所示:

但是,主从复制也带来其他一系列性能瓶颈问题:
- 写入无法扩展
- 写入无法缓存
- 复制延时
- 锁表率上升
- 表变大,缓存率下降
那问题产生总得解决的,这就产生下面的优化方案,一起来看看。
2、MySQL垂直分区
如果把业务切割得足够独立,那把不同业务的数据放到不同的数据库服务器将是一个不错的方案,而且万一其中一个业务崩溃了也不会影响其他业务的正常进行,并且也起到了负载分流的作用,大大提升了数据库的吞吐能力。经过垂直分区后的数据库架构图如下:

然而,尽管业务之间已经足够独立了,但是有些业务之间或多或少总会有点联系,如用户,基本上都会和每个业务相关联,况且这种分区方式,也不能解决单张表数据量暴涨的问题,因此为何不试试水平分割呢?
3、MySQL水平分片(Sharding)
这是一个非常好的思路,将用户按一定规则(按id哈希)分组,并把该组用户的数据存储到一个数据库分片中,即一个sharding,这样随着用户数量的增加,只要简单地配置一台服务器即可,原理图如下:

如何来确定某个用户所在的shard呢,可以建一张用户和shard对应的数据表,每次请求先从这张表找用户的shard id,再从对应shard中查询相关数据,如下图所示:

单库单表
单库单表是最常见的数据库设计,例如,有一张用户(user)表放在数据库db中,所有的用户都可以在db库中的user表中查到。
单库多表
随着用户数量的增加,user表的数据量会越来越大,当数据量达到一定程度的时候对user表的查询会渐渐的变慢,从而影响整个DB的性能。如果使用mysql, 还有一个更严重的问题是,当需要添加一列的时候,mysql会锁表,期间所有的读写操作只能等待。
可以通过某种方式将user进行水平的切分,产生两个表结构完全一样的user_0000,user_0001等表,user_0000 + user_0001 + …的数据刚好是一份完整的数据。
多库多表
随着数据量增加也许单台DB的存储空间不够,随着查询量的增加单台数据库服务器已经没办法支撑。这个时候可以再对数据库进行水平区分。
分库分表规则
设计表的时候需要确定此表按照什么样的规则进行分库分表。例如,当有新用户时,程序得确定将此用户信息添加到哪个表中;同理,当登录的时候我们得通过用户的账号找到数据库中对应的记录,所有的这些都需要按照某一规则进行。
路由
通过分库分表规则查找到对应的表和库的过程。如分库分表的规则是user_id mod 4的方式,当用户新注册了一个账号,账号id的123,我们可以通过id mod 4的方式确定此账号应该保存到User_0003表中。当用户123登录的时候,我们通过123 mod 4后确定记录在User_0003中。
分库分表产生的问题,及注意事项
1.分库分表维度的问题
假如用户购买了商品,需要将交易记录保存取来,如果按照用户的纬度分表,则每个用户的交易记录都保存在同一表中,所以很快很方便的查找到某用户的 购买情况,但是某商品被购买的情况则很有可能分布在多张表中,查找起来比较麻烦。反之,按照商品维度分表,可以很方便的查找到此商品的购买情况,但要查找 到买人的交易记录比较麻烦。
所以常见的解决方式有:
- 通过扫表的方式解决,此方法基本不可能,效率太低了。
- 记录两份数据,一份按照用户纬度分表,一份按照商品维度分表。
通过搜索引擎解决,但如果实时性要求很高,又得关系到实时搜索。
2.联合查询的问题
联合查询基本不可能,因为关联的表有可能不在同一数据库中。
3.避免跨库事务
避免在一个事务中修改db0中的表的时候同时修改db1中的表,一个是操作起来更复杂,效率也会有一定影响。
4.尽量把同一组数据放到同一DB服务器上
例如将卖家a的商品和交易信息都放到db0中,当db1挂了的时候,卖家a相关的东西可以正常使用。也就是说避免数据库中的数据依赖另一数据库中的数据。
一主多备
在实际的应用中,绝大部分情况都是读远大于写。Mysql提供了读写分离的机制,所有的写操作都必须对应到Master,读操作可以在 Master和Slave机器上进行,Slave与Master的结构完全一样,一个Master可以有多个Slave,甚至Slave下还可以挂 Slave,通过此方式可以有效的提高DB集群的 QPS.
所有的写操作都是先在Master上操作,然后同步更新到Slave上,所以从Master同步到Slave机器有一定的延迟,当系统很繁忙的时候,延迟问题会更加严重,Slave机器数量的增加也会使这个问题更加严重。
此外,可以看出Master是集群的瓶颈,当写操作过多,会严重影响到Master的稳定性,如果Master挂掉,整个集群都将不能正常工作。
所以
1. 当读压力很大的时候,可以考虑添加Slave机器的分式解决,但是当Slave机器达到一定的数量就得考虑分库了。
2. 当写压力很大的时候,就必须得进行分库操作。
MySQL使用为什么要分库分表
可以用说用到MySQL的地方,只要数据量一大, 马上就会遇到一个问题,要分库分表。
这里引用一个问题为什么要分库分表呢?MySQL处理不了大的表吗?
其实是可以处理的大表的。我所经历的项目中单表物理上文件大小在80G多,单表记录数在5亿以上,而且这个表 属于一个非常核用的表:朋友关系表。
但这种方式可以说不是一个最佳方式。因为面临文件系统如Ext3文件系统对大于大文件处理上也有许多问题。
这个层面可以用xfs文件系统进行替换。但MySQL单表太大后有一个问题是不好解决: 表结构调整相关的操作基本不在可能。所以大项在使用中都会面监着分库分表的应用。
从Innodb本身来讲数据文件的Btree上只有两个锁, 叶子节点锁和子节点锁,可以想而知道,当发生页拆分或是添加新叶时都会造成表里不能写入数据。
所以分库分表还就是一个比较好的选择了。
那么分库分表多少合适呢?
经测试在单表1000万条记录一下,写入读取性能是比较好的. 这样在留点buffer,那么单表全是数据字型的保持在800万条记录以下, 有字符型的单表保持在500万以下。
如果按 100库100表来规划,如用户业务:
500万*100*100 = 50000000万 = 5000亿记录。
心里有一个数了

mysql 数据库 分表后 怎么进行分页查询?Mysql分库分表方案?的更多相关文章
- MySQL、SqlServer、Oracle三大主流数据库分页查询 (MySQL分页不能用top,因为不支持)
一. MySQL 数据库 分页查询MySQL数据库实现分页比较简单,提供了 LIMIT函数.一般只需要直接写到sql语句后面就行了.LIMIT子 句可以用来限制由SELECT语句返回过来的数据数量,它 ...
- CentOS6.7下使用非root用户(普通用户)编译安装与配置mysql数据库并使用shell脚本定时任务方式实现mysql数据库服务随机自动启动
CentOS6.7下使用非root用户(普通用户)编译安装与配置mysql数据库并使用shell脚本定时任务方式实现mysql数据库服务随机自动启动1.关于mysql?MySQL是一个关系型数据库管理 ...
- SpringBoot-(8)-配置MySQL数据库链接,配置数据坚挺拦截,创建默认数据表
一,链接mysql数据库 # 数据源基本配置 spring.datasource.username=root spring.datasource.password=123456 spring.data ...
- mysql数据库从删库到跑路之mysql表操作
表介绍 表相当于文件,表中的一条记录就相当于文件的一行内容,不同的是,表中的一条记录有对应的标题,称为表的字段 id,name,qq,age称为字段,其余的,一行内容称为一条记录 内容: 1 创建表 ...
- mysql数据库从删库到跑路之mysql多表查询
一 介绍 本节主题 多表连接查询 复合条件连接查询 子查询 准备表 company.employeecompany.department #建表 create table department( id ...
- mysql数据库从删库到跑路之mysql基础
一 数据库是什么 之前所学,数据要永久保存,比如用户注册的用户信息,都是保存于文件中,而文件只能存在于某一台机器上. 如果我们不考虑从文件中读取数据的效率问题,并且假设我们的程序所有的组件都运行在一台 ...
- MySQL、Oracle和SQL Server的分页查询语句
假设当前是第PageNo页,每页有PageSize条记录,现在分别用Mysql.Oracle和SQL Server分页查询student表. 1.Mysql的分页查询: SELECT * FROM s ...
- MySQL数据库自带备份与恢复工具:MySQLdump.exe与mysql.exe
数据库的备份工作是保护数据库正常运行的关键,以下的文章主要讲述的是MySQL数据库备份的一些小妙招,我们大家都知道使用MySQL dump备份数据库的用户所需要的权限相对而言还是比较小的,只需要sel ...
- MySQL数据库优化技术之SQL语句慢查询定位
通过show status命令了解各种SQL的执行频率 MySQL客户端连接成功后,通过使用show [session|global] status 命令可以提供服务器状态信息: 其中的session ...
随机推荐
- xmind8 Mac序列号
1.首先去官网下载xmind8的安装包:XMind for Mac 也可以去我的百度网盘下载: 链接:https://pan.baidu.com/s/1eY52YsSaPmr-YFhB62Cli ...
- height设置100%不起作用
详细讲解了原因:http://www.webhek.com/post/css-100-percent-height.html
- org.apache.maven.archiver.mavenarchiver.getmanifest怎么解决——原因就是你的maven的配置文件不是最新的
转载:https://www.cnblogs.com/flytop/p/8933728.html原因就是你的maven的配置文件不是最新的 1.help ->Install New Softwa ...
- ssh保持长连接的方式
方法有以下三种:1.修改server端的etc/ssh/sshd_configClientAliveInterval 60 #server每隔60秒发送一次请求给client,然后client响应,从 ...
- 【转载】PHP 程序员进阶之路
原文:没有Nginx,你还能做什么? PHP程序员的未来不是Java,Java拯救不了你. 已经1368年了,你扪胸自问,没有了Nginx的你,还能用PHP做什么.有一些高端的刁民会愤怒地说:&quo ...
- P7362 [eJOI 2020 Day2] XOR Sort
P7362 [eJOI 2020 Day2] XOR Sort 题意 给你一个长度为 \(n\) 的序列,每次操作可以将一个数异或上相邻的一个数,求将序列改为严格单调递增序列或严格单调不降序列的操作次 ...
- Mysql的登录
一.mysql申请连接的四种方式 1 . TCP/IP TCP/IP套接字连接方式是MySQL在任何平台都提供的一种连接方式,也是网络中使用最多的一种方式.这种方式在TCP/IP连接上建立一个基于网络 ...
- CMS垃圾收集器——重新标记和浮动垃圾的思考
<深入理解java虚拟机 第二版 JVM高级特性与最佳实践>里面提到 CMS 垃圾收集器. CMS 垃圾收集器的垃圾回收分4个步骤: 初始标记(initial mark) 有 STW 并发 ...
- Go通关03:控制结构,if、for、switch逻辑语句
if 条件语句 func main() { i:=6 if i >10 { fmt.Println("i>10") } else if i>5 && ...
- Apereo CAS 4.1 反序列化命令执行漏洞
命令执行 java -jar apereo-cas-attack-1.0-SNAPSHOT-all.jar CommonsCollections4 "touch /tmp/success&q ...