【Python机器学习实战】决策树与集成学习(四)——集成学习(2)GBDT
本打算将GBDT和XGBoost放在一起,但由于涉及内容较多,且两个都是比较重要的算法,这里主要先看GBDT算法,XGBoost是GBDT算法的优化和变种,等熟悉GBDT后再去理解XGBoost就会容易的多
GBDT算法原理
GBDT(Gradient Boosting Decision Tree)算法
前面说到,提升树是每次训练将上一次训练的残差作为本次训练的样本,找出最优的决策树的过程,然后将所有模型进行叠加的过程。同样,GBDT也是一种前向加法算法模型,不同于提升树的是,GBDT每次将残差的负梯度(后边具体解释)作为当前一轮的训练样本。GBDT中的树都是回归树,即使GBDT经过处理可以用于分类算法,每棵树依然是回归树。那么为什么选择残差的负梯度作为训练样本呢?这是因为在提升树中计算损失的时候:
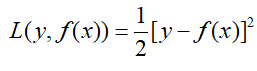
当使得L最小时,我们采用梯度下降的方法,求取L的梯度:
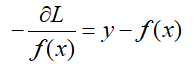
当f(x)为上一轮所得的强分类器,那么:
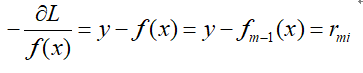
因此我们只要沿着残差值不断减小的方向优化就可以了。也正因为损失函数使用了平方损失,在进行优化的时候才可以将残差的值作为新的树的训练集。
而在实际中,存在很多损失函数,比如在分类时使用的cros_entropy或者绝对值损失等,当对这些损失损失函数进行求导时,求得的导数将不再是残差,因此,针对这一个问题,Freidman提出了梯度提升的方法,即用损失函数的负梯度在当前模型的值,作为回归问题中提升树的残差的近似值,意思也就是用这个负梯度去代替残差,只有当损失函数是平方损失的时候,GBDT算法就等同于提升树(我是这么理解的)。到这里,GBDT的算法就很清晰了,只需要将提升树中的残差替换为损失函数的负梯度就可以了,算法流程如下:
“”“
输入:训练数据集{(x1,y1),(x2,y2),...,(xN,yN)},损失函数L,迭代次数M
输出:回归树
- 初始化弱分类器(不同于提升树中,因为提升树中是直接求均值即可,直接进入迭代获得残差):
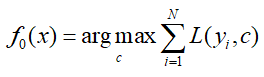
- 对于迭代次数1~M:
- 计算样本的负梯度:
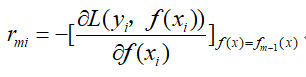
- 然后根据样本的负梯度的值,训练出一个新的决策树,对于每个叶节点区域Rmj,搜索叶节点区域的值,使损失函数最小:
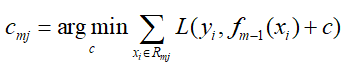
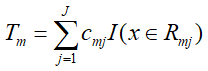
- 然后更新强分类器:
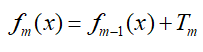
- 迭代完成,获得最终分类器。
“”“
上面就是GBDT的算法流程,当损失为平方损失时,该过程与提升树的过程一致,每个叶节点的取值取残差的均值即可,如果是其他损失,则需要具体求解,对损失进行求导,令其为0来求取。下面举个小例子对GBDT的过程进行描述:
有如下一组训练数据:
| 编号 | 年龄 | 体重 | 身高 |
| 1 | 5 | 20 | 1.1 |
| 2 | 7 | 30 | 1.3 |
| 3 | 21 | 70 | 1.7 |
| 4 | 30 | 60 | 1.8 |
特征为年龄、体重,标签(输出)为身高,那么根据这组数据建立梯度提升树,树的个数为5,每棵树的深度为3,我们依然先采用平方损失去建立每一棵树:
首先初始化分类器:
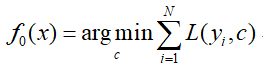
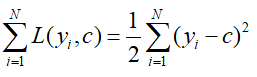
对其进行求导,并令其等于0.即可求得c值即为均值:
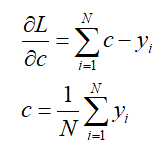
那么可得初始化的弱分类器f0(x)=c=1.475。
接下来进入第一次迭代,以损失的负梯度(这里负梯度就是残差)作为训练数据,开始训练回归树, 训练数据变为:
| 编号 | 年龄 | 体重 | 负梯度 |
| 1 | 5 | 20 | -0.375 |
| 2 | 7 | 30 | -0.175 |
| 3 | 21 | 70 | 0.225 |
| 4 | 30 | 60 | 0.325 |
开始对这个数据训练决策树,根据特征取值,年龄取值分别为5、7、21、30,体重取值为20、30、60、70,分别计算按每个值划分后叶子节点平方损失和(这里就只是CART决策树建立时的平方损失的和,每个节点的输出就是平均值,与损失函数是什么无关,我是这么理解的不知道对不对)最小的,比如当取年龄6时,树被划分为:
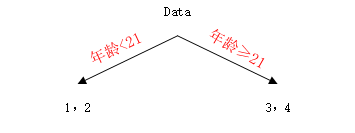
那么损失为(0.375-0.375)2+(0.375+0.175)2+(0.375-0.225)2+(0.375-0.325)2=0.140,依次类推,得到如下一张表:
| 划分点 | 左节点 | 右节点 | SEL | SER | SE(sum) |
| 年龄5 | 0 | 1,2,3,4 | 0 | 0.327 | 0.327 |
| 年龄7 | 1 | 2,3,4 | 0 | 0.14 | 0.14 |
| 年龄14 | 1,2 | 3,4 | 0.02 | 0.005 | 0.025 |
| 年龄15.5 | 1,2,3 | 4 | 0.187 | 0 | 0.187 |
| 体重20 | 0 | 1,2,3,4 | 0 | 0.327 | 0.327 |
| 体重30 | 1 | 2,3,4 | 0 |
0.14 |
0.14 |
| 体重60 | 1,2 | 3,4 | 0.02 | 0.005 | 0.025 |
| 体重70 | 1,2,4 | 3 | 0.26 | 0 | 0.26 |
从上面的损失可以看出,选择年龄21或体重60是最好的划分值,因此选取一个特征进行划分,这里选取年龄,得到划分后的树为:
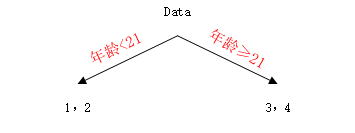
这里设定的树的最大深度是3,那么需要再进行一次划分,按照上面的方法,分别对左右节点进行划分,最终得到最优的决策树如下:
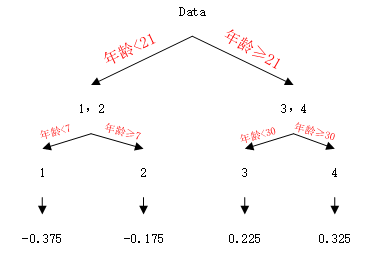
这时我们需要获得这一轮决策树每个叶子节点输出值,即最佳的负梯度(这里是残差),给每个节点赋予一个参数γ:
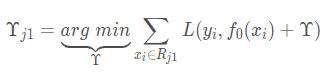
由于选取的是平方损失,这个输出就是每个叶子节点的均值,如果损失函数不是平方损失,那么就需要对L进行求导,求出对应的γ,本次迭代算是完成,得到的树如下:
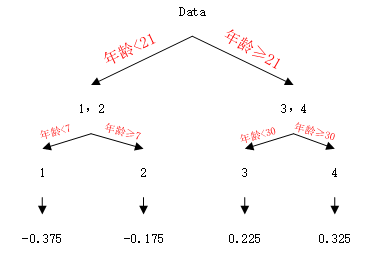
此时更新强学习器,需要用到参数的学习率(后边会叙述为什么要用学习率),learning_rate=0.1,用lr表示:
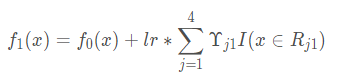
接下来重复上述步骤,进行第二轮迭代,依次得到接下来的四棵树:
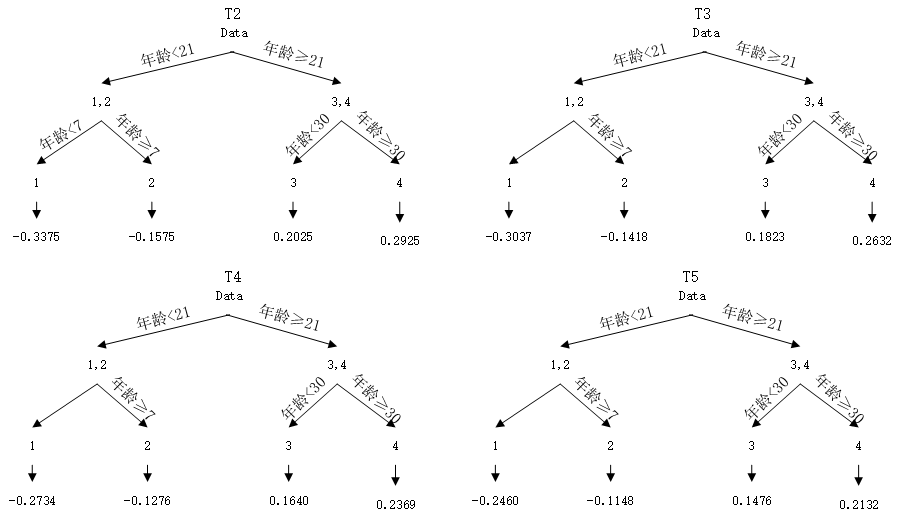
最终得到强学习器:
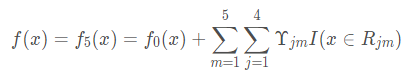
上述过程可以看出,每棵树的残差是在想着不断减小的方向进行的。此外,上面提到了在进行叠加弱分类器的时候用到了learning_rate,就是利用了Shrinkage(缩减)的思想,其可以认为是梯度下降中的学习率的意思,这样每次增加一个衰减可以避免一次走很大步导致过拟合,通过衰减每次走一小步逐步逼近结果,即它不完全信任每一个棵残差树,它认为每棵树只学到了真理的一小部分,累加的时候只累加一小部分,通过多学几棵树弥补不足。本质上,Shrinkage为每棵树设置了一个weight,累加时要乘以这个weight,但和Gradient并没有关系。这个weight就是step。就像Adaboost一样,Shrinkage能减少过拟合发生也是经验证明的,目前还没有看到从理论的证明。
GBDT处理分类问题
那么为什么GBDT不采用分类树,而是采用回归树呢,对于分类问题又是如何处理呢?
首先之所以不采用分类树,主要是GBDT本质上是通过拟合残差逐步逼近最优模型的,对于离散数据在叠加就会变得没有意义,比如猫和狗叠加就不知道是什么了,那么对于分类问题,GBDT又是怎么做的呢,通常处理分类问题有两种方式:
- 采用指数函数作为损失函数,此时GBDT又退回到AdaBoost的算法了,因为AdaBoost所采用的实际上就是对数损失
- 另一种就是类似于LogisticRegression的思想,通过预测类别的概率与真实值之间的差值来拟合残差。
首先看一下GBDT对于二元分类的处理:
逻辑回归中的对数似然损失函数(这里y的取值为{-1,1}损失函数是这样的形式):
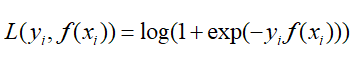
那么这是负梯度的误差为:
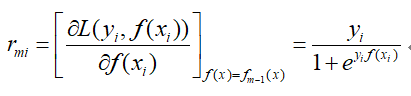
对于生成决策树时,对于各叶子节点最佳的负梯度拟合值为:
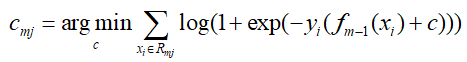
由于该式子比较难优化,一般采用近似值代替:
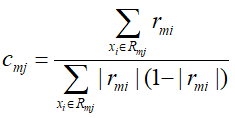
除了上面两个在求解负梯度的值和叶子节点最佳负梯度拟合的线性搜索中,二元分类的GBDT与GBDT回归算法一致。
GBDT的多分类
对于多分类情况,情况要比二元分类复杂一些,假设类别为K,则此时我们的对数似然损失函数为:
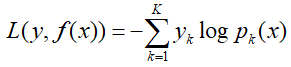
其中如果样本输出类别为k,则yk=1。第k类的概率pk(x)的表达式为:
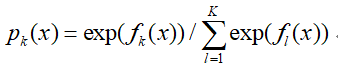
集合上面两个式子,我们可以计算出第t轮的第i个样本对应类别l的负梯度误差为:
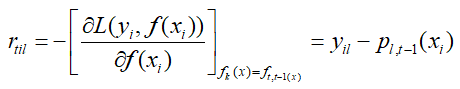
从上式可以看出,这里的负梯度误差就是样本所属类别的真是概率(也就是1)与第t-1轮的预测概率的差值。
然后就是生成决策树后,线性搜索对应的叶子结点的负梯度最佳拟合值:
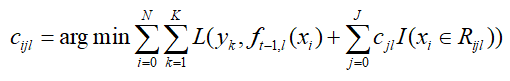
同样,上式的优化求解比较困难,我们采用近似值代替:
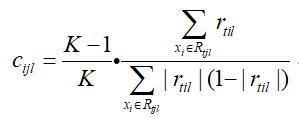
其他步骤与二元分类和GBDT回归算法的步骤一致。
GBDT中的损失函数
这里我们总结几种GBDT中的常用的损失函数

关于正则化
关于GBDT的正则化,上面提到了一种方法使用learning_rate的方法,还有一种是不放回抽样,也就是通过子采样比例,比例在(0,1]之间,这里采样不同于Bagging中采样,这里是不放回的抽样,当取值为1时,相当于不采样,当小于1时,选择一部分样本建立GBDT决策树,这样可以减小方差,防止过拟合,但同时会增大偏差,因此不能取值太小,推荐为0.5~0.8。
有关GBDT的算法就先到这里了,因为这是机器学习中一个比较重要的方法,其本身其实并不复杂,主要涉及内容较多,其中原理和推导还是比较繁琐的,这里卡的时间比较久,后面会再对这一部进行回顾并反复查看,每一次对同一个算法进行回顾都会有不同的见解和问题,到后边会对这里的内容进一步补充,接下来通过数据集来对GBDT的Python实现和调参进行学习。
【Python机器学习实战】决策树与集成学习(四)——集成学习(2)GBDT的更多相关文章
- 【Python机器学习实战】决策树和集成学习(一)
摘要:本部分对决策树几种算法的原理及算法过程进行简要介绍,然后编写程序实现决策树算法,再根据Python自带机器学习包实现决策树算法,最后从决策树引申至集成学习相关内容. 1.决策树 决策树作为一种常 ...
- python机器学习实战(四)
python机器学习实战(三) 版权声明:本文为博主原创文章,转载请指明转载地址 www.cnblogs.com/fydeblog/p/7364317.html 前言 这篇notebook是关于机器学 ...
- 机器学习实战(Machine Learning in Action)学习笔记————03.决策树原理、源码解析及测试
机器学习实战(Machine Learning in Action)学习笔记————03.决策树原理.源码解析及测试 关键字:决策树.python.源码解析.测试作者:米仓山下时间:2018-10-2 ...
- Python 机器学习实战 —— 监督学习(下)
前言 近年来AI人工智能成为社会发展趋势,在IT行业引起一波热潮,有关机器学习.深度学习.神经网络等文章多不胜数.从智能家居.自动驾驶.无人机.智能机器人到人造卫星.安防军备,无论是国家级军事设备还是 ...
- Python 机器学习实战 —— 无监督学习(上)
前言 在上篇<Python 机器学习实战 -- 监督学习>介绍了 支持向量机.k近邻.朴素贝叶斯分类 .决策树.决策树集成等多种模型,这篇文章将为大家介绍一下无监督学习的使用.无监督学习顾 ...
- Python 机器学习实战 —— 监督学习(上)
前言 近年来AI人工智能成为社会发展趋势,在IT行业引起一波热潮,有关机器学习.深度学习.神经网络等文章多不胜数.从智能家居.自动驾驶.无人机.智能机器人到人造卫星.安防军备,无论是国家级军事设备还是 ...
- python机器学习实战(一)
python机器学习实战(一) 版权声明:本文为博主原创文章,转载请指明转载地址 www.cnblogs.com/fydeblog/p/7140974.html 前言 这篇notebook是关于机器 ...
- 机器学习实战(Machine Learning in Action)学习笔记————02.k-邻近算法(KNN)
机器学习实战(Machine Learning in Action)学习笔记————02.k-邻近算法(KNN) 关键字:邻近算法(kNN: k Nearest Neighbors).python.源 ...
- Python 机器学习实战 —— 无监督学习(下)
前言 在上篇< Python 机器学习实战 -- 无监督学习(上)>介绍了数据集变换中最常见的 PCA 主成分分析.NMF 非负矩阵分解等无监督模型,举例说明使用使用非监督模型对多维度特征 ...
- python机器学习实战(二)
python机器学习实战(二) 版权声明:本文为博主原创文章,转载请指明转载地址 http://www.cnblogs.com/fydeblog/p/7159775.html 前言 这篇noteboo ...
随机推荐
- (python函数03)zip()函数
(python函数03)zip()函数 zip是用来压缩的,它接受一系列可迭代的对象作为参数,将对象中对应的元素打包成一个个元组(tuple),然后返回有这些tuples组成的对象,可强制转化为列表和 ...
- dragover event 翻译
当选择的元素或文本被拖拽到一个有效的放置目标上时(每几百毫秒),dragover事件就会被触发. 该事件在放置目标上被触发. Property Type Description target Read ...
- 🔥 LeetCode 热题 HOT 100(51-60)
142. 环形链表 II 思路:快慢指针,快慢指针相遇后,慢指针回到头,快慢指针步伐一致一起移动,相遇点即为入环点 /** * Definition for singly-linked list. * ...
- Jupyter Kernel Error 解决办法
首先在pycharm的terminal中输入 python -m ipykernel install --user 之后会如下图显示: 这就是kernel的安装路径. 然后输入: jupyter ke ...
- java小程序之随机任务发布器
需求 自定义任务 随机定时 随机排序 集合输出 搭建 简单项目,所以我使用java 的maven来搭建一个控制台程序,并且使用excel来记录任务 创建任务类(sub) package com.mic ...
- MIPS Pwn赛题学习
MIPS Pwn writeup Mplogin 静态分析 mips pwn入门题. mips pwn查找gadget使用IDA mipsrop这个插件,兼容IDA 6.x和IDA 7.x,在ID ...
- Vulhub-Mysql 身份认证绕过漏洞(CVE-2012-2122)
前言 当连接MariaDB/MySQL时,输入的密码会与期望的正确密码比较,由于不正确的处理,会导致即便是memcmp()返回一个非零值,也会使MySQL认为两个密码是相同的.也就是说只要知道用户名, ...
- BUUCTF-[网鼎杯 2018]Fakebook(SSRF+联合注入绕Waf)
记一道SSRF配合SQL注入的题. 喜欢在做题之前扫一下网站的目录,扫到了robots.txt文件可以访问,拿到user.php.bak的源码.同时还有flag.php. <?php class ...
- C++ 1 (只在源文件)//点和圆的关系 //设计一个圆形类 和一个点类 计算点和圆的关系 //点到圆心的距离 == 半径 点在圆上 //点到圆心的距离 > 半径 点在圆外 //点到圆心的距离 < 半径 点在圆内 //点到圆心的距离 获取 ....... (x1 -x2)^2 + (y1-y2)^2 开根号 和半径对比 // 计算 可以 两边同时 平方
1 //点和圆的关系 2 //设计一个圆形类 和一个点类 计算点和圆的关系 3 //点到圆心的距离 == 半径 点在圆上 4 //点到圆心的距离 > 半径 点在圆外 5 //点到圆心的距离 &l ...
- 以命令行方式使用Desktop版Ubuntu
方法1:安装Ubuntu Server版,好处是默认不安装GUI,且可以自动安装ssh服务和其他很多服务,且消耗系统资源少(约200MB内存,Desktop版启动后需要500MB左右内存),启动和关闭 ...