Spark(十六)【SparkStreaming基本使用】
一. SparkStreaming简介
1. 相关术语
流式数据: 指数据源源不断。
实时数据: 当前正在产生的数据。
离线数据: 过去(不是当下产生的)已经产生的数据。
实时计算: 理想上,实时计算一定是对实时数据的计算,理想期望立刻当前计算出结果(要在公司规定的时效范围内)。
离线计算: 计算通常需要划分一段时间。
总结:离线计算和实时计算主要通过计算的时效性进行区分,实时在不同的公司,有相对参考的标准。
2. SparkStreaming概念
SparkStreaming可以用来进行实时计算,Spark Streaming用于流式数据的处理,但是SparkStreaming是一个准(接近)实时计算的框架。
SparkStreaming在进行实时计算时,采用的是微批次(区别于流式)计算。
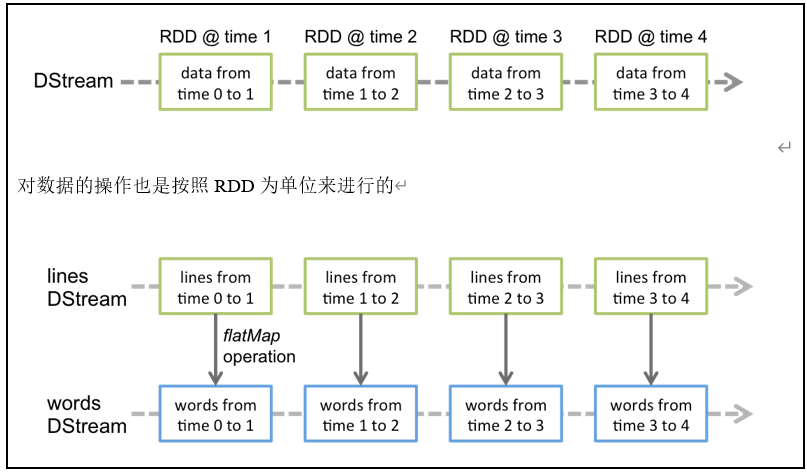
使用DStream作为最基本的数据抽象。DStream会将一段时间采集到的数据,封装为一个RDD进行计算处理。
3. SparkStreaming架构
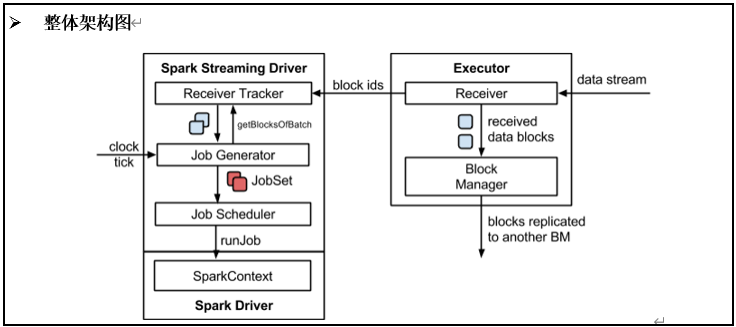
SparkStreaming程序在架构上整体分为两块
数据接受模块: 启动一个Excutor运行Reciever程序,Reciever程序会将指定时间间隔收到的一批数据,进行存储,存储后,将这批数据的id,发送给Driver。
数据处理模块(Driver): Driver端有RecieverTracer,不断接受 Reciever发送的已经收到的一批数据的ID,之后,通过JobGenerator,将这批数据,提交为一个Job,提交Job后,会启动Excutor运算这批数据。这批数据在运算时,会有Reciever所在的Excutor发送过来,运行结束后将结果返回给Driver。
4. 背压机制
Spark Streaming可以动态控制数据接收速率来适配集群数据处理能力。
背压机制(即Spark Streaming Backpressure): 根据JobScheduler反馈作业的执行信息来动态调整Receiver数据接收率。
把spark.streaming.backpressure.enabled 参数设置为ture,开启背压机制后Spark Streaming会根据延迟动态去kafka消费数据,上限由spark.streaming.kafka.maxRatePerPartition参数控制,所以两个参数一般会一起使用。
二. Dstream入门
1. WordCount案例实操
需求:使用netcat工具向9999端口不断的发送数据,通过SparkStreaming读取端口数据并统计不同单词出现的次数。
① 添加pom依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<version>3.0.0</version>
</dependency>
② 代码实现
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* @description: WordCount入门案例
* @author: HaoWu
* @create: 2020年08月10日
*/
object WordCountTest {
def main(args: Array[String]): Unit = {
//1.初始化Spark配置信息
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("StreamWordCount")
//2.初始化SparkStreamingContext,3秒统计一次,可以设置多个级别:Milliseconds,Seconds,Minutes
val ssc = new StreamingContext(sparkConf, Seconds(3))
//3.通过监控端口创建DStream,读进来的数据为一行行
val lineStreams = ssc.socketTextStream("hadoop102", 9999)
//4.处理DStream
//将每一行数据做切分,形成一个个单词
val wordStreams = lineStreams.flatMap(_.split(" "))
//将单词映射成元组(word,1)
val wordAndOneStreams = wordStreams.map((_, 1))
//将相同的单词次数做统计
val wordAndCountStreams = wordAndOneStreams.reduceByKey(_+_)
//打印
wordAndCountStreams.print()
//5.启动SparkStreamingContext
ssc.start()
ssc.awaitTermination()
}
}
③在hadoop102节点启动nc工具发送数据,同时启动SparkStreaming程序
nc -lk hadoop102 9999
结果
-------------------------------------------
Time: 1597053684000 ms
-------------------------------------------
(,1)
(as,1)
(fdaf,1)
(sa,1)
-------------------------------------------
Time: 1597053686000 ms
-------------------------------------------
-------------------------------------------
Time: 1597053688000 ms
-------------------------------------------
2. WordCount解析
Discretized Stream是Spark Streaming的基础抽象,代表持续性的数据流和经过各种Spark原语操作后的结果数据流。在内部实现上,DStream是一系列连续的RDD来表示。每个RDD含有一段时间间隔内的数据。
3. web UI
注意
SparkStream程序运行要启动两个线程,最少需要2个CPU,不然程序无法启动。
Receiver、Driver各启动一个excupu。本地测试的设置为“local[*]”
三. Dstream创建
1. RDD队列(测试使用)
测试过程中,可以通过使用ssc.queueStream(queueOfRDDs)来创建DStream,每一个推送到这个队列中的RDD,都会作为一个DStream处理,测试使用验证数据处理的逻辑
需求:循环创建几个RDD,将RDD放入队列。通过SparkStream创建Dstream,计算WordCount。
queueStream函数签名
def queueStream[T: ClassTag](
queue: Queue[RDD[T]], // 传入的队列
oneAtATime: Boolean, // 在一个周期内,是否只允许采集一个RDD
defaultRDD: RDD[T] // 队列空了时,是否返回一个默认的RDD,可以设置为null,不返回
): InputDStream[T] = {
new QueueInputDStream(this, queue, oneAtATime, defaultRDD)
}
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import scala.collection.mutable
/**
* @description: RDD队列创建DStream
* @author: HaoWu
* @create: 2020年08月10日
*/
object WordCountSeqTest {
def main(args: Array[String]): Unit = {
//1.创建SparkStreamingContext
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("RDDSeqApp")
val ssc: StreamingContext = new StreamingContext(conf, Seconds(2))
//2.创建可变RDD队列
val que: mutable.Queue[RDD[String]] = new mutable.Queue[RDD[String]]()
//3.创建DStream
val dStream: InputDStream[String] = ssc.queueStream(que, oneAtATime = false)
//4.DStream的逻辑处理
val result: DStream[(String, Int)] = dStream.flatMap(_.split(",")).map((_, 1)).reduceByKey(_ + _)
//5.打印
result.print(100)
//6.运行程序
ssc.start()
val rdd = ssc.sparkContext.makeRDD(List("sada", "dafa", "adfafa", "fafda"))
//7.往队列中每一秒添加一个RDD
println("Start启动.....")
for (i <- 1 to 10) {
que.+=(rdd)
Thread.sleep(1000)
}
ssc.awaitTermination()
}
}
结果
Start启动
-------------------------------------------
Time: 1597055400000 ms
-------------------------------------------
(dafa,1)
(fafda,1)
(adfafa,1)
(sada,1)
-------------------------------------------
Time: 1597055402000 ms
-------------------------------------------
(dafa,2)
(fafda,2)
(adfafa,2)
(sada,2)
2. 自定义数据源
使用:需要继承Receiver,并实现onStart、onStop方法来自定义数据源采集。
继承Receiver
/*
StorageLevel: 数据存储的级别!存内存,还是存磁盘等!
T: 每次收的数据的类型
*/
abstract class Receiver[T](val storageLevel: StorageLevel) extends Serializable
实现onStart方法
在收数据之前,运行一些指定的安装操作
def onStart() {
//1.在收数据时,onStart()不能被阻塞!
//2.必须新开启一个线程收数据!
//3.收到数据后,可以调用store()来存储数据!
}
实现Onstop方法
在停止接收数据之前,清理组件
注意:在发生异常时,可以调用restart()重启接收器,还可以调用stop()彻底停止收数据
需求:自定义数据源,实现监控某个端口号,获取该端口号内容。
代码
import java.io.{BufferedInputStream, BufferedReader, InputStreamReader}
import java.net.Socket
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.receiver.Receiver
class MyCustomReceiver(var hostname: String, var port: Int) extends Receiver[String](StorageLevel.MEMORY_ONLY) {
var socket: Socket = null
var reader: BufferedReader = null
/**
* 重写onStart方法
*/
override def onStart(): Unit = {
//异常处理
try {
socket = new Socket(hostname, port)
} catch {
case e: ConnectException => {
restart("重试~~~~");
return
}
}
println("Socket已经连接上~~~~~")
//获取reader
reader = new BufferedReader(new InputStreamReader(socket.getInputStream))
//开始接收数据
recevie()
}
/**
* 新建一个线程接收数据
*/
def recevie(): Unit = {
new Thread("Socket Receiver ThreadName") {
//设置当前线程为守护线程 当前线程依附于 Receiver所在的main线程!
// 如果一个JVM中,只有守护线程,JVM就会关闭!
setDaemon(true)
override def run(): Unit = {
//异常处理
try {
println("开始接收:" + hostname + ":" + port + " 的数据")
var line = reader.readLine()
while (socket != null && line != null) {
//存储数据
store(line)
line = reader.readLine()
}
} catch {
case e: Exception => e.getMessage
} finally {
onStop();
restart("重启Receiver~~~")
}
}
}.start()
}
/**
* 关闭资源
*/
override def onStop(): Unit = {
if (socket != null) {
socket.close()
socket = null
}
if (reader != null) {
reader.close()
reader = null
}
}
}
测试
object CostumReceiver extends {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("CostumReceive")
val ssc: StreamingContext = new StreamingContext(conf,Seconds(2))
//创建自定义Receiver
val receiver: CostumeReceiver = new CostumeReceiver("hadoop102",9999)
//创建DStream
val dStream: ReceiverInputDStream[String] = ssc.receiverStream(receiver)
val result = dStream.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
result.print(100)
ssc.start()
ssc.awaitTermination()
}
}
3. Kafka直连
好处
由Excutor直接去Kafka读取数据,减少数据的网络IO传输!
Reciver只需要将一个采集周期采集的数据的元数据信息,发送给Excutor即可!
案例
pom依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>2.10.1</version>
</dependency>
代码
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* @description: SparkStreaming直连消费Kafka数据
* @author: HaoWu
* @create: 2020年08月10日
*/
object SparkStreamingKafkaTest {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("CostumReceive")
val ssc: StreamingContext = new StreamingContext(conf, Seconds(2))
//设置消费kafka的参数,可以参考kafka.consumer.ConsumerConfig类中配置说明
val kafkaParams: Map[String, Object] = Map[String, Object](
"bootstrap.servers" -> "hadoop102:9092,hadoop103:9092,hadoop104:9092", //zookeeper的host,port
"group.id" -> "g3", //消费者组
"enable.auto.commit" -> "true", //是否自动提交
"auto.commit.interval.ms" -> "500", //500ms自动提交offset
"key.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer",
"value.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer",
"auto.offset.reset" -> "earliest"//第一次运行,从最初始偏移量开始消费数据
)
//使用工具类创建DStream,消费topic test1的数据
val ds: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
//订阅主题
ConsumerStrategies.Subscribe[String, String](List("test1"),
kafkaParams))
//逻辑处理
val result: DStream[(String, Int)] = ds.flatMap(record => record.value().split(" ")).map((_, 1)).reduceByKey(_ + _)
result.print(100)
//运行程序
ssc.start()
ssc.awaitTermination()
}
}
测试
启动zk集群,kafka集群,向test1主题添加数据
[root@hadoop102 kafka]$ bin/kafka-console-producer.sh --broker-list hadoop102:9092 --topic test1
>fasdf a
>asf as
>asf sa
实现数据零丢失
spark官网:sparkstreaming集成kafka
方法一:checkpoint实现
①取消基于时间的自动提交,改为手动提交
②在消费逻辑真正执行完后,再手动提交
Spark在手动取消offset提交后,允许设置一个checkpoint目录,在程序崩溃之前,可以将崩溃时,程序的状态(包含offset)保存到目录中!
在程序重启后,可以选择重建状态!保证从之前未消费的位置继续消费
缺点:小文件,重建会启动很多没用的任务
代码实现
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
/**
* @description: 保证数据不丢失
* @author: HaoWu
* @create: 2020年08月10日
*/
object KafkaTest {
def main(args: Array[String]): Unit = {
/**
* 程序异常重建SparkStreamingContext
*/
def rebuild(): StreamingContext = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("My app")
val ssc: StreamingContext = new StreamingContext(conf, Seconds(2))
//设置checkpoint目录
ssc.checkpoint("kafka")
//TODO 消费参数配置
val kafkaParams: Map[String, Object] = Map[String, Object](
"bootstrap.servers" -> "hadoop102:9092",
// "client.id" -> "c4",
"group.id" -> "g1",
"enable.auto.commit" -> "false",
"auto.commit.interval.ms" -> "500",
"key.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer",
"value.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer",
"auto.offset.reset" -> "earliest"
)
//TODO 消费数据穿建 DStream
val ds: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](List("test1"),
kafkaParams))
//TODO 消费逻辑
val ds1: DStream[String] = ds.flatMap(record => record.value().split(" "))
//模拟消费异常
val result: DStream[(String, Int)] = ds1.map(x => {
// if (x == "d") {
// throw new UnknownError("程序异常~~~~~~~~~")
// }
(x, 1)
}).reduceByKey(_ + _)
//打印
result.print(100)
ssc
}
// 重建context 防止进程崩溃,进程崩溃后,重建程序
val ssc: StreamingContext = StreamingContext.getActiveOrCreate("kafka", rebuild)
//运行程序
ssc.start()
ssc.awaitTermination()
}
}
方法二:手动提交offset
不丢数据,可能数据重复
四. DStream转化 (API)
无状态转化:每个批次单独处理自己批次中的的RDD。
有状态转化:跨批次之间的转化,当前批次的RDD计算需要和之前的批次的结果做累加。
无状态转化
reduceByKey:只针对单个批次的RDD做转化。
map:RDD的map操作
Transform
将当前批次的RDD[T] => RDD[U]
def transform[U: ClassTag](transformFunc: RDD[T] => RDD[U]): DStream[U] =
//转换为RDD操作
val ds1: ReceiverInputDStream[String] = ssc.socketTextStream("hadoop102", 9999)
//4.处理DStream
val ds2: DStream[(String, Int)] = ds1.transform(rdd => {
val value: RDD[(String, Int)] = rdd.flatMap(_.split(" ")).map((_, 1))
value
})
双流 join
可以实现双流join,实质就是对2个流各个批次的RDD进行join
前提:两个流的批次大小一致,DS中的元素必须是K-V结构,拉链操作
//3.通过监控端口创建DStream,读进来的数据为一行行
val ds1: ReceiverInputDStream[String] = ssc.socketTextStream("hadoop102", 9999)
val ds2: ReceiverInputDStream[String] = ssc.socketTextStream("hadoop103", 8888)
//4.处理DStream
val ds11: DStream[(String, Int)] = ds1.flatMap(_.split(" ")).map((_, 1))
val ds22: DStream[(String, String)] = ds2.flatMap(_.split(" ")).map((_, "aa"))
//5.双流join
val result: DStream[(String, (Int, String))] = ds11.join(ds22)
//打印
result.print(100)
有状态转化(重要)
UpdateStateByKey
流计算中累加wordcount可以使用这个算子
函数签名
//Seq[V]:当前批次的相同key的values集合
//Option[S]:之前批次的结果,可以通过
def updateStateByKey[S: ClassTag](
updateFunc: (Seq[V], Option[S]) => Option[S]
): DStream[(K, S)] =
案例:求截止到当前时间单词的个数(wordcount)
/**
* @description: **UpdateStateByKey**案例
* @author: HaoWu
* @create: 2020年08月10日
*/
object NoStatusTest {
def main(args: Array[String]): Unit = {
//1.初始化Spark配置信息
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("StreamWordCount")
//2.初始化SparkStreamingContext,3秒统计一次,可以设置多个级别:Milliseconds,Seconds,Minutes
val ssc = new StreamingContext(sparkConf, Seconds(3))
//设置checkpoint,保存状态
ssc.checkpoint("./updatestate")
//通过监控端口创建DStream,读进来的数据为一行
val ds: ReceiverInputDStream[String] = ssc.socketTextStream("hadoop102", 9999)
//转化为K-V类型
val ds1: DStream[(String, Int)] = ds.flatMap(_.split(" ")).map((_, 1))
val result: DStream[(String, Int)] = ds1.updateStateByKey((seq: Seq[Int], option: Option[Int]) => {
var sum: Int = seq.sum
val value: Int = option.getOrElse(0)
sum += value
Some(sum)
})
//打印
result.print(100)
//5.启动SparkStreamingContext
ssc.start()
ssc.awaitTermination()
}
}
结果
-------------------------------------------
Time: 1597142208000 ms
-------------------------------------------
(a,7)
(b,3)
-------------------------------------------
Time: 1597142211000 ms
-------------------------------------------
(a,9)
(ab,1)
(b,4)
-------------------------------------------
Time: 1597142214000 ms
-------------------------------------------
(a,10)
(ab,2)
(b,5)
注意:
①RDD是K-V
②updateFunc参数里面参数声明泛型[],返回结果用Some包装
③设置checkpoint
WindowOperations 窗口
Window Operations可以设置窗口的大小和滑动窗口的间隔来动态的获取当前Steaming的允许状态。所有基于窗口的操作都需要两个参数,分别为窗口时长以及滑动步长。
窗口时长:计算内容的时间范围。
滑动步长:隔多久触发一次计算。
注意:这两者都必须为采集周期大小的整数倍。
两种实现
①每个窗口单独统计窗口内部数据,每次滑动,重新计算(无状态)
def reduceByWindow(
//窗口内的归约计算
reduceFunc: (T, T) => T,
//窗口大小
windowDuration: Duration,
//步长
slideDuration: Duration
): DStream[T] = ssc.withScope {
this.reduce(reduceFunc).window(windowDuration, slideDuration).reduce(reduceFunc)
}
②当前窗口和之前窗口有重叠,会使用之前的窗口的数据和当前窗口计算(有状态)

def reduceByKeyAndWindow(
// old window 和新进入的values进行运算(上图的窗口B绿色部分)
reduceFunc: (V, V) => V,
// old window和离开的values进行运算(上图的窗口A的黄色部分)
invReduceFunc: (V, V) => V,
//窗口大小
windowDuration: Duration,
//步长
slideDuration: Duration = self.slideDuration,
numPartitions: Int = ssc.sc.defaultParallelism,
filterFunc: ((K, V)) => Boolean = null
): DStream[(K, V)] = ssc.withScope {
reduceByKeyAndWindow(
reduceFunc, invReduceFunc, windowDuration,
slideDuration, defaultPartitioner(numPartitions), filterFunc
)
}
案例:每间隔5分钟,统计最近1h所有的单词统计
实现一:无状态
//1.初始化Spark配置信息
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("StreamWordCount")
//2.初始化SparkStreamingContext,3秒统计一次,可以设置多个级别:Milliseconds,Seconds,Minutes
val ssc = new StreamingContext(sparkConf, Seconds(3))
//通过监控端口创建DStream,读进来的数据为一行
val ds: ReceiverInputDStream[String] = ssc.socketTextStream("hadoop102", 9999)
//转化为K-V类型
val ds1: DStream[(String, Int)] = ds.flatMap(_.split(" ")).map((_, 1))
val result: DStream[(String, Int)] = ds1.reduceByKeyAndWindow((_ + _), windowDuration = Seconds(4), Seconds(2))
//打印
result.print(100)
//5.启动SparkStreamingContext
ssc.start()
ssc.awaitTermination()
实现二:有状态
需要设置检查点
//1.初始化Spark配置信息
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("StreamWordCount")
//2.初始化SparkStreamingContext,3秒统计一次,可以设置多个级别:Milliseconds,Seconds,Minutes
val ssc = new StreamingContext(sparkConf, Seconds(3))
//需要上一个window计算的结果,设置检查点
ssc.checkpoint("updateStateByKey1")
// DS[String] : 输入流中的每行数据
val ds: ReceiverInputDStream[String] = context.socketTextStream("hadoop103", 3333)
val result: DStream[(String, Int)] = ds.flatMap(_.split(" ")).map((_, 1))
.reduceByKeyAndWindow((_+_),(_ - _),windowDuration=Seconds(4),filterFunc=_._2 != 0)
result.print(100)
//运行程序
context.start()
context.awaitTermination()
window窗口
定义DS的窗口,之后DS的算子都是在窗口中运算
def window(windowDuration: Duration, slideDuration: Duration): DStream[T] = ssc.withScope {
new WindowedDStream(this, windowDuration, slideDuration)
}
ds.window(窗口大小,滑动步长)
五. 程序优雅关闭
流式任务需要7*24小时执行,但是有时涉及到升级代码需要主动停止程序,但是分布式程序,没办法做到一个个进程去杀死,所有配置优雅的关闭就显得至关重要了。使用外部文件系统来控制内部程序关闭
MonitorStop类:启动一个线程检查是否停止程序
import java.net.URI
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.{FileSystem, Path}
import org.apache.spark.streaming.{StreamingContext, StreamingContextState}
class MonitorStop(ssc: StreamingContext) extends Runnable {
override def run(): Unit = {
val fs: FileSystem = FileSystem.get(new URI("hdfs://linux1:9000"), new Configuration(), "root")
while (true) {
try
Thread.sleep(5000)
catch {
case e: InterruptedException =>
e.printStackTrace()
}
val state: StreamingContextState = ssc.getState
// 读取一个标记(数据库,文件系统)/应用程序/_stop
val bool: Boolean = fs.exists(new Path("hdfs://linux1:9000/stopSpark"))
if (bool) {
if (state == StreamingContextState.ACTIVE) {
ssc.stop(stopSparkContext = true, stopGracefully = true)
System.exit(0)
}
}
}
}
}
SparkTest
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkTest {
def createSSC(): _root_.org.apache.spark.streaming.StreamingContext = {
val update: (Seq[Int], Option[Int]) => Some[Int] = (values: Seq[Int], status: Option[Int]) => {
//当前批次内容的计算
val sum: Int = values.sum
//取出状态信息中上一次状态
val lastStatu: Int = status.getOrElse(0)
Some(sum + lastStatu)
}
val sparkConf: SparkConf = new SparkConf().setMaster("local[4]").setAppName("SparkTest")
//设置优雅的关闭
sparkConf.set("spark.streaming.stopGracefullyOnShutdown", "true")
val ssc = new StreamingContext(sparkConf, Seconds(5))
ssc.checkpoint("./ck")
val line: ReceiverInputDStream[String] = ssc.socketTextStream("linux1", 9999)
val word: DStream[String] = line.flatMap(_.split(" "))
val wordAndOne: DStream[(String, Int)] = word.map((_, 1))
val wordAndCount: DStream[(String, Int)] = wordAndOne.updateStateByKey(update)
wordAndCount.print()
ssc
}
def main(args: Array[String]): Unit = {
val ssc: StreamingContext = StreamingContext.getActiveOrCreate("./ck", () => createSSC())
new Thread(new MonitorStop(ssc)).start()
ssc.start()
ssc.awaitTermination()
}
}
练手示例
/*
优雅地关闭
*/
@Test
def test5() : Unit ={
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("My app")
val context = new StreamingContext(conf, Seconds(2))
// DS[String] : 输入流中的每行数据
val ds: ReceiverInputDStream[String] = context.socketTextStream("hadoop103", 3333)
val result: DStream[(String, Int)] = ds.window(Seconds(4),Seconds(2))
.flatMap(_.split(" ")).map((_, 1))
.reduceByKey(_+_)
result.foreachRDD(rdd => println(rdd.collect().mkString(",")))
//运行程序
context.start()
//启动分线程,执行关闭
new Thread(){
//判断是否需要关闭
def ifShouldNotStop():Boolean={
// 读取一个标记(数据库,文件系统)/应用程序/_stop
true
}
//关闭
override def run(): Unit = {
while(ifShouldNotStop()){
Thread.sleep(5000)
}
// 关闭 stopGraceFully: 等收到的数据计算完成后再关闭
context.stop(true,true)
}
}.start()
// 当前线程阻塞,后续的代码都不会执行!
context.awaitTermination()
}
}
六.Dstream流写到各种库
HBase
借助Phoenix写入HBase
样例类
case class StartupLog(mid: String,
uid: String,
appId: String,
area: String,
os: String,
channel: String,
logType: String,
version: String,
ts: Long,
var logDate: String = null, // 年月日
var logHour: String = null) { // 小时
private val date = new Date(ts)
logDate = new SimpleDateFormat("yyyy-MM-dd").format(date)
logHour = new SimpleDateFormat("HH").format(date)
}
建phoenix表
create table gmall_dau(
mid varchar,
uid varchar,
appid varchar,
area varchar,
os varchar,
channel varchar,
logType varchar,
version varchar,
logDate varchar,
logHour varchar,
ts bigint
CONSTRAINT dau_pk PRIMARY KEY (mid,logDate));
pom依赖
<!--------- 使用 phoenix写入Hbase -------->
<dependency>
<groupId>org.apache.phoenix</groupId>
<artifactId>phoenix-spark</artifactId>
<version>5.0.0-HBase-2.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
</dependency>
代码实现
val startStream: DStream[StartupLog]
//写入到 Phoenix(HBase)
startStream.foreachRDD(rdd => {
// 4.1写入到 Phoenix(HBase)
import org.apache.phoenix.spark._
// 参数1: 表名 参数2: 列名组成的 seq 参数 zkUrl: zookeeper 地址
rdd.saveToPhoenix("GMALL_DAU",
Seq("MID", "UID", "APPID", "AREA", "OS", "CHANNEL", "LOGTYPE", "VERSION", "TS", "LOGDATE", "LOGHOUR"),
zkUrl = Some("hadoop102,hadoop103,hadoop104:2181"))
})
说明
1.Streaming在与外界创建连接要考虑到连接数的问题
Streaming有mapPartition,一个分区创建一个连接,也可以使用transform转为RDD,再操作。
2.利用phoenix.spark操作Phoenix,样例类的字段要和Seq()字段顺序一致,Seq()字段和建表的字段名称一致。
ES
es工具类
package com.bigdata.gmall.realtime.util
import io.searchbox.client.{JestClient, JestClientFactory}
import io.searchbox.client.config.HttpClientConfig
import io.searchbox.core.{Bulk, Index}
import scala.collection.JavaConverters._
/**
* @description: ES工具类
* @author: HaoWu
* @create: 2020年09月09日
*/
object ESUtil {
// 构建JestClientFactory
//ES服务器地址 注意:可以设置1个也可以设置1个Collection,要转为java的集合
val esServerUrl = Set("http://hadoop102:9200", "http://hadoop103:9200", "http://hadoop104:9200").asJava
private val factory = new JestClientFactory
var conf: HttpClientConfig = new HttpClientConfig.Builder(esServerUrl)
.multiThreaded(true)
.maxTotalConnection(100)
.connTimeout(10 * 1000)
.readTimeout(10 * 1000)
.build()
factory.setHttpClientConfig(conf)
/**
* 获取ES客户端
*/
def getESClient(): JestClient = {
factory.getObject
}
/**
* 插入单条数据
*
* @param index :插入的Index
* @param source :满足两种类型参数:1.source 2.(id,source) ,其中source可以是样例类对象 或 json对象字符串
*/
def insertSingle(index: String, source: Any): Unit = {
val client: JestClient = getESClient()
val action =
source match {
case (id, s: Any) => {
new Index.Builder(s)
.index(index)
.`type`("_doc")
.id(id.toString) //ES中的id为String类型,当入参的id为int类型可能插入错误。
.build()
}
case (_) => {
new Index.Builder(source)
.index(index)
.`type`("_doc")
.build()
}
}
client.execute(action)
client.close()
}
/**
* 批量插入数据
*
* @param index :插入的Index
* @param sources :满足两种类型参数:1.source 2.(id,source) ,其中source可以是样例类对象 或 Json对象字符串
* 说明:将来数据使用mapPartition批量写入,所以参数封装为Iterator类型
*/
def insertBluk(index: String, sources: Iterator[Object]) {
// 1.获取ES客户端
val client: JestClient = getESClient()
// 2.构建Builder
val builder: Bulk.Builder = new Bulk.Builder()
.defaultIndex(index)
.defaultType("_doc")
// 3.为Builder添加action
//================== 方式一 ========================================
/* sources.foreach(
source => {
val action =
source match {
case (id: String, s) => { //入参是一个元祖(id, source)
new Index.Builder(s)
.id(id)
.build()
}
case (_) => { //入参是source,样例类,或者 json对象字符串
new Index.Builder(source)
.build()
}
}
//添加action
builder.addAction(action)
}
)*/
//================== 方式二 ========================================
sources.map { //转换为action
case (id: String, s) => {
new Index.Builder(s)
.id(id)
.build()
}
case (source) => {
new Index.Builder(source)
.build()
}
} //往builder添加action
.foreach(builder.addAction)
// 4.执行插入
client.execute(builder.build())
// 5.关闭客户端
client.close()
}
/**
* 测试ES工具类
*/
def main(args: Array[String]): Unit = {
val sources = Iterator(User("www", 21), (99, User("www", 30)))
// val source = User("lisi", 20)
// insertSingle("user", source)
// insertSingle("user", (11, source))
insertBluk("user", sources)
}
case class User(name: String, age: Int)
}
样例类
case class AlertInfo(mid: String,
uids: java.util.HashSet[String],
itemIds: java.util.HashSet[String],
events: java.util.List[String],
ts: Long)
建es表
PUT gmall_coupon_alert
{
"mappings": {
"_doc":{
"properties":{
"mid":{
"type":"keyword"
},
"uids":{
"type":"keyword"
},
"itemIds":{
"type":"keyword"
},
"events":{
"type":"keyword"
},
"ts":{
"type":"date"
}
}
}
}
}
pom依赖
<!--es 相关依赖开始-->
<dependency>
<groupId>io.searchbox</groupId>
<artifactId>jest</artifactId>
<version>6.3.1</version>
</dependency>
<!-- 如果jar冲突获取jar包缺失可以添加下面的依赖,es没问题就不用添加
<dependency>
<groupId>net.java.dev.jna</groupId>
<artifactId>jna</artifactId>
<version>4.5.2</version>
</dependency>
<dependency>
<groupId>org.codehaus.janino</groupId>
<artifactId>commons-compiler</artifactId>
<version>2.7.8</version>
</dependency>-->
<!-- es 相关依赖结束 -->
代码实现
val alertInfoStream: DStream[AlertInfo]
alertInfoStream
.foreachRDD(
rdd => rdd.foreachPartition(
iter => {
//Iterator[AlertInfo] -> Iterator[(id,source)]
val iterAlertInfo: Iterator[(String, AlertInfo)] = iter.map(alertInfo => {
// id = mid+分钟数 实现每个mid每分钟只产生1条预警信息实现去重
val id: String = alertInfo.mid + ":" + alertInfo.ts / 1000 / 60
(id, alertInfo)
})
// println(iterAlertInfo.toList)
//批量写入ES
ESUtil.insertBluk("gmall_coupon_alert", iterAlertInfo)
})
)
Spark(十六)【SparkStreaming基本使用】的更多相关文章
- 十六款值得关注的NoSQL与NewSQL数据库--转载
原文地址:http://tech.it168.com/a2014/0929/1670/000001670840_all.shtml [IT168 评论]传统关系型数据库在诞生之时并未考虑到如今如火如荼 ...
- 我的MYSQL学习心得(十六) 优化
我的MYSQL学习心得(十六) 优化 我的MYSQL学习心得(一) 简单语法 我的MYSQL学习心得(二) 数据类型宽度 我的MYSQL学习心得(三) 查看字段长度 我的MYSQL学习心得(四) 数据 ...
- Bootstrap <基础二十六>进度条
Bootstrap 进度条.在本教程中,你将看到如何使用 Bootstrap 创建加载.重定向或动作状态的进度条. Bootstrap 进度条使用 CSS3 过渡和动画来获得该效果.Internet ...
- Bootstrap<基础十六> 导航元素
Bootstrap 提供的用于定义导航元素的一些选项.它们使用相同的标记和基类 .nav.Bootstrap 也提供了一个用于共享标记和状态的帮助器类.改变修饰的 class,可以在不同的样式间进行切 ...
- 解剖SQLSERVER 第十六篇 OrcaMDF RawDatabase --MDF文件的瑞士军刀(译)
解剖SQLSERVER 第十六篇 OrcaMDF RawDatabase --MDF文件的瑞士军刀(译) http://improve.dk/orcamdf-rawdatabase-a-swiss-a ...
- Senparc.Weixin.MP SDK 微信公众平台开发教程(十六):AccessToken自动管理机制
在<Senparc.Weixin.MP SDK 微信公众平台开发教程(八):通用接口说明>中,我介绍了获取AccessToken(通用接口)的方法. 在实际的开发过程中,所有的高级接口都需 ...
- JAVA-集合作业-已知有十六支男子足球队参加2008 北京奥运会。写一个程序,把这16 支球队随机分为4 个组。采用List集合和随机数
第二题 已知有十六支男子足球队参加2008 北京奥运会.写一个程序,把这16 支球队随机分为4 个组.采用List集合和随机数 2008 北京奥运会男足参赛国家: 科特迪瓦,阿根廷,澳大利亚,塞尔维亚 ...
- Web 前端开发人员和设计师必读精华文章【系列二十六】
<Web 前端开发精华文章推荐>2014年第5期(总第26期)和大家见面了.梦想天空博客关注 前端开发 技术,分享各类能够提升网站用户体验的优秀 jQuery 插件,展示前沿的 HTML5 ...
- linux基础-第十六单元 yum管理RPM包
第十六单元 yum管理RPM包 yum的功能 本地yum配置 光盘挂载和镜像挂载 本地yum配置 网络yum配置 网络yum配置 Yum命令的使用 使用yum安装软件 使用yum删除软件 安装组件 删 ...
随机推荐
- linux下使用shell命令通过wpa_cli控制wpa_supplicant连接wifi
最近在调试wifi,已经把wpa_supplicant 工具编译打包好了,为了测试wif驱动及wifi模块是否ok,需要用shell命令临时启动wifi服务连接wifi热点测试. 首先板子启动用ifc ...
- 当src获取不到图片,onerror可指定一张默认的图片
<img src="img/789.png" onerror="javascript:this.src='img/123.png';" alt=" ...
- SpringCloud 2020.0.4 系列之 Bus
1. 概述 老话说的好:会休息的人才更会工作,身体是革命的本钱,身体垮了,就无法再工作了. 言归正传,之前我们聊了 SpringCloud 的 分布式配置中心 Config,文章里我们聊了config ...
- 这些年我@yangbodong22011参与的开源
2020年第一天,水一篇博客,对新年起码的尊重.这里记录下我参与的开源项目情况. Talk is cheap. Show me the code Linus Torvalds Jedis PR:htt ...
- Windows 常用配置
安装IIS服务器 在服务器管理器中,选择"角色"添加角色 进入添加角色向导,在安装界面,选择服务器角色为:" Web服务器(IIS) " 角色服务勾选:应用程序 ...
- CSS 海盗船加载特效
CSS 海盗船加载特效 <!DOCTYPE html> <html lang="en"> <head> <meta charset=
- Bootstrap-2栅格系统
栅格系统(使用最新版本bootstrap) Grid options(网格配置) Responsive classes(响应式class) Gutters(间距) Alignment(对齐方式) Re ...
- SQL告警,执行时间长?教你写一手好 SQL !
博主(编码砖家)负责的项目主要采用阿里云数据库MySQL,最近频繁出现慢SQL告警,执行时间最长的竟然高达5分钟.导出日志后分析,主要原因竟然是没有命中索引和没有分页处理 . 其实这是非常低级的错误, ...
- Linux Mem (目录)
1.用户态相关: 1.1.用户态进程空间的创建 - execve() 详解 1.2.用户态进程空间的映射 - mmap()详解 1.3.分页寻址(Paging/MMU)机制详解 2.内核态相关: 2. ...
- 【CVE-2020-1948】Apache Dubbo Provider反序列化漏洞复现
一.实验简介 实验所属系列: 系统安全 实验对象:本科/专科信息安全专业 相关课程及专业: 计算机网络 实验时数(学分):2 学时 实验类别: 实践实验类 二.实验目的 Apache Dubbo是一款 ...