MySQL之InnoDB存储引擎 - 读书笔记
1. MySQL 的存储引擎
MySQL 数据库的一大特色是有插件式存储引擎概念。日常使用频率最高的两种存储引擎:
InnoDB 存储引擎支持事务,其特点是行锁设计、支持外键、非锁定读(默认读取操作不会产生锁)。1.2.x 开始支持全文索引。数据存储方面,InnoDB (即指 InnoDB 存储引擎) 采用了聚集 (clustered)的方式,每张表的存储都是按逐渐的顺序进行存放。(如果没有显式定义主键, InnoDB 会为每行生成一个6字节的 ROWID,并以此作为主键)
MyISAM存储引擎不支持事务、表锁设计,支持全文索引。MyISAM另一个与众不同的地方是它的缓冲池只缓存索引文件,而不缓存数据文件。数据存储方面,MyISAM表由 MYD 和 MYI 组成,分别用来存放数据文件和索引文件。
2. InnoDB 存储引擎
InnoDB 存储引擎是 Mysql 数据库 OLTP ( Online Transaction Processing 在线事务处理 ) 应用中使用最广泛的存储引擎。特点前面已经提过,现在来看看 InnoDB 的体系架构。
2.1 InnoDB 体系架构
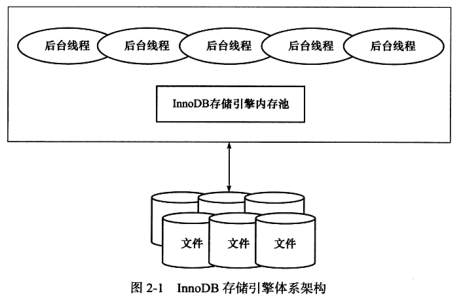
2.2.1 后台线程
后台线程的主要作用是刷新内存池中的数据(保持最新)。此外,还将已修改的文件同步到磁盘文件,同时保证在数据库发生异常情况时 InnoDB 能恢复到正常运行状态。
InnoDB是多线程的模型,所以有不同的后台线程,用来处理不同的任务。包含如下线程:
- Master Thread 是一个非常核心的后台线程,主要负责将缓冲池的数据异步刷新到磁盘,以保证数据的一致性。
- IO Thread 的主要工作主要是负责IO请求的回调处理,因为InnoDB 中大量使用了AIO(Async IO)来处理写请求。有四类 IO Thread, 分别是 write、read、insert buffer 和 log。
- Purge Thread 用来回收已经使用并分配的 Undo 页(事务提交后可能不再需要的 undolog)。
- 1.2.x 版本新引入的 Page Cleaner Thread 用来将脏页的刷新操作都放到新线程进行。
2.2.2 内存
内存池负责如下工作:1. 维护所有进程/线程所需(访问)的内部数据结构;2. 缓存磁盘上的数据,以便快速地读取;3. 重做日志缓冲;……
具体如下:
缓冲池
InnoDB存储引擎是基于磁盘存储的,记录按照页的方式进行管理。可将其视为基于磁盘的数据库系统。
缓冲池就是一块内存区域,通过内存的速度来弥补磁盘速度较慢对数据库性能的影响。缓冲池的设计目的是为了协调CPU速度与磁盘速度的鸿沟。
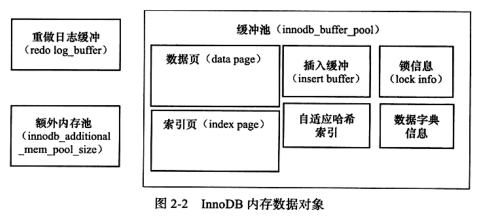
缓冲池缓存的数据页类型有:数据页、索引页、undo页、插入缓冲、自适应哈希索引、锁信息、数据字典信息等,如下图:
LRU List、Free List 和 Flush List
数据库的缓冲池是用 LRU (Latest Recent Used, 最近最少使用)算法来管理的。LRU是一种缓存置换算法,即在缓存有限的情况下,如果有新的数据需要加载进缓存,则需要将最不可能被继续访问的缓存剔除掉 。InnoDB 存储引擎的缓冲池管理算法是用优化过的LRU管理的。(题外话:Redis达到maxmemory后的回收策略中的LRU算法也不是朴素的算法,采用近似LRU算法,只取出一小部分数据并根据访问时间丢掉老数据)。
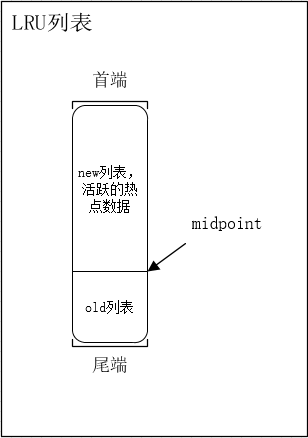
如上草图所示,InnoDB在 LRU List (LRU 列表) 中加入了 midpoint 位置(百分比, 通过innodb_old_blocks_pct 设置,默认37),将缓冲池 LRU 列表分为new&old 列表,new 列表存放热点数据(也称new列表这端为热端),新读取的页放入尾端的 old 列表(过多久会加入到热端,通过一个 innodb_old_blocks_time 时间来管理 , 默认0)。可使用
show variables like 'innodb_old_blocks_%';查看 innodb_old_blocks_pct 和 innodb_old_blocks_time 值: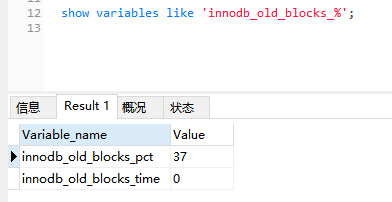
以上是LRU List 的概念,在数据刚刚启动时,没有任何的页,LRU List 是空的。页都放在 Free List 中,当需要在缓冲池分页时,才将Free List 中的页放入 LRU List。
可以运行命令
show engine innodb status;查看缓冲池大小、LRU列表大小、Free列表大小、页移动到热端的次数。忍不住贴出原文
下面为笔者查看时的数据
之前设置了缓冲池大小700M set global innodb_buffer_pool_size=734003200;
查看时:show variables like 'innodb_buffer_pool_size'; 结果缓冲池大小是 738197504 多了4M数据(这4M应该是表的空间暂时不深究)。
=====================================
2019-11-13 14:10:58 0x174b0 INNODB MONITOR OUTPUT
=====================================
Per second averages calculated from the last 32 seconds
......
----------------------
BUFFER POOL AND MEMORY
----------------------
Total large memory allocated 755499008
Dictionary memory allocated 361836
Buffer pool size 45056 # 缓冲池大小(页为单位) 45056*16k=738197504 bytes 与上面的缓冲池大小一致
Free buffers 0
Database pages 37689 # LRU LIST 页大小
Old database pages 13892
Modified db pages 0 # 脏页大小
Pending reads 0
Pending writes: LRU 0, flush list 0, single page 0
Pages made young 26230, not young 0
0.00 youngs/s, 0.00 non-youngs/s
Pages read 8525, created 43072, written 49077
0.00 reads/s, 0.00 creates/s, 0.00 writes/s
Buffer pool hit rate 1000 / 1000, young-making rate 0 / 1000 not 0 / 1000
如果在记录周期(当前为32秒)内,没有使用到缓存,则上面 BUFFER POOL HIT RATE 这一行会是:No buffer pool page gets since the last printout
Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s
LRU len: 37689, unzip_LRU len: 0
I/O sum[0]:cur[0], unzip sum[0]:cur[0]
在LRU List 需要中的页被修改后,称该页为脏页(dirty page)(缓存和磁盘数据不一致)。这时数个据库通过CHECKPOINT 机制将脏页刷新回磁盘,此时Flush List中的页为脏页列表。脏页存在于LRU 列表和Flush 列表,LRU 列表用来管理缓冲池中页的可用性,Flush 列表用来将页刷新回磁盘。
重做日志缓冲 (redo log buffer)
重做日志的作用是确保事务的持久性。防止在故障发生时,有脏页未写入磁盘(重启MySQL服务时,根据redo log文件恢复数据)。重做日志缓冲区是放重做日志信息的地方,下面三种情况会将重做日志缓冲中的内容刷新到磁盘的重做文件中:
Master Thread 每秒将重做日志缓冲刷新到重做日志文件;
每个事务提交时会将重做日志缓冲刷新到重做日志文件;
当重做日志缓冲剩余空间小于1/2时,重做日志缓冲刷新到重做日志文件。
额外的内存池
不应该被忽略。就像指针指向的内容需要内存,但是指针本身也需要内存一样。缓冲池的帧缓冲和缓冲控制对象等都需要内存,就存在额外的内存池中。
2.2 Checkpoint(检查点)技术
页的操作首先都是在缓冲池中完成的。如果一条 DML 语句(如 Update 或 Delete )改变了页中的记录,那么此时页是脏页(即缓冲池中的页的版本要比磁盘的新),数据库需要将新版本的页从缓冲池刷新到磁盘。
Checkpoint 技术的目的:
- 缩短数据库的恢复时间
- 缓冲池不够用时,将脏页刷新到磁盘
- 重做日志不可用时,刷新脏页
具体的 Checkpoint 有几种类型还有触发 Fuzzy Checkpoint 的几种情况,作者都总结的清晰且简洁,需要的可以去查书。
2.3 命令
-- MySQL 版本
select version();
-- InnoDB 版本
show variables like 'innodb_version';
-- IO Thread
show variables like 'innodb_%io_threads';
-- InnoDB status, 可以看到 IO thread 信息
show engine innodb status;
-- purge thread, 回收已经使用并分配的Undo页
show variables like 'innodb_purge%';
-- 缓冲池配置大小
show variables like 'innodb_buffer_pool_size';
-- 缓冲区实例个数
show variables like 'innodb_buffer_pool_instances';
-- midpoint和加入热端的时间
show variables like 'innodb_old_blocks_%';
关于存储引擎这章,还讲了 InnoDB 关键特性(插入缓冲、两次写、自适应哈希索引、异步IO 和 刷新邻接页),以及启动和关闭 MySQL 时的一些配置参数对 InnoDB(full purge、数据恢复、插入缓冲合并等) 的影响。
3. 表
关系型数据库模型的核心是:表是关于特定实体的数据集合。本章从InnoDB的表的逻辑存储开始介绍,然后重点分析表的物理存储特征(即数据在表中是如何组织和存储的)。
3.1 索引组织表
存储方式是根据主键顺序组织存放的表称为索引组织表(index organized table)。
在 InnoDB 表中,每张表都有个主键 (Primary Key),如果在创建表时没有显式的定义主键,首先会判断表中是否有非空的唯一索引 (Unique NOT NULL),如果有则该列为主键,否则,InnoDB 会自动创建一个6字节大小的指针(并以此为主键)。
当表中有多个非空唯一索引时,InnoDB 将选择建表时第一个定义的非空唯一索引为主键。(这里需要注意,主键的选择是根据定义索引的顺序而不是建表字段的顺序)。看例子:
create table z(
a int not null,
b int null,
c int not null,
d int not null,
unique key(b), unique key(d), unique key(c)
)ENGINE=InnoDB;
insert into z select 1,2,3,4;
select *, _rowid from z;
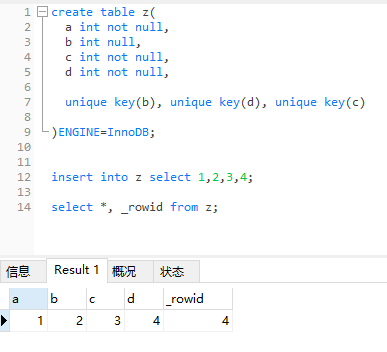
请看上面例子。唯一索引有三个,b、d 和 c,因为b不是非空的,所以跳过,选择 d 做主键。可以通过查询 _rowid 来观察隐藏主键。
显示创建表的语句:
show create table table_name;
3.2 InnoDB 逻辑存储结构
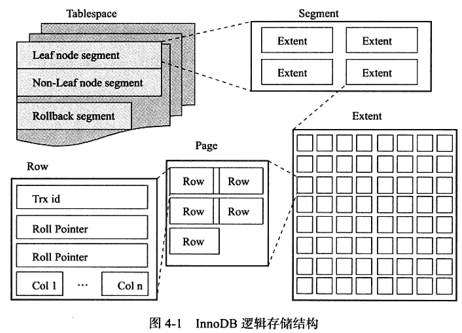
上图是 InnoDB 的逻辑存储结构,所有数据都放在表空间中,表空间(tablespace)由段(segment)、区(extent)、页(page)/块(block)组成。图中可看到页中有行(row)记录。
InnoDB 中常见的段有数据、索引、回滚段等。
页是 InnoDB 磁盘管理的最小单位,默认每个页大小是 16KB(从1.2.xa版本开始,可以通过参数 innodb_page_size 设置页大小为4、8、16K)。区是由连续页组成的空间,在任何时候每个区的大小都为1MB(所以当页大小为64、16、8、4K时,每个区对应页的数量是64、128、256、512)。常见的页类型有:数据页、Undo页、系统页、事务数据页等。
InnoDB 是面向行的,即数据是按行进行存放的。每页存放数据有硬性规定,最多允许 16KB/2-200=7922 行记录。
3.3 InnoDB 行记录格式
InnoDB 提供了 Compact 和 Redundant 两种格式来存放行记录数据(Redundant 是为了兼容之前版本而保留的)。可以通过行记录的组织规则来读取其中的记录。
3.3.1 行溢出数据
首先考虑一个问题:MySQL 数据库的 VARCHAR 类型最多可以存放 65535 字节数据吗?做个试验发现只可以存储 65532 字节数据
create table z2(
vc_1 varchar(10) null
)ENGINE=InnoDB CHARSET=utf8mb4 ROW_FORMAT=COMPACT;
alter table z2 modify column `vc_1` varchar(16383);
create table z3(
vc_1 varchar(10) null
)ENGINE=InnoDB CHARSET=latin1 ROW_FORMAT=COMPACT;
alter table z3 modify column `vc_1` varchar(65532);
-- show table status;
新建两个表,只有一个 varchar 字段(varchar后指定的是存储字符串长度而不是字节长度),因为 charset 不同,存储的字符长度不同(但总字节长度一样,都为65532)。z2 表中,utf8mb4每个字符占用4个字节,16383*4=65532。再设置的大一点就会报错了,所以 varchar 最多存储 65532 字节数据。
针对 65532 字节的数据,InnoDB 的页仅为 16KB(16384 字节),溢出的数据会怎么存储呢?答案是表空间文件只存储了字符串的部分前缀,然后是一个偏移地址,指向一些 BLOB页(实际存放数据的地方)。原作者在这里演示的时候,前缀存放了768字节的数据,还有其他四个BLOB页。
3.3.2 Compact 行记录格式
Compact 行记录是在 MySQL5.0 中引入的。
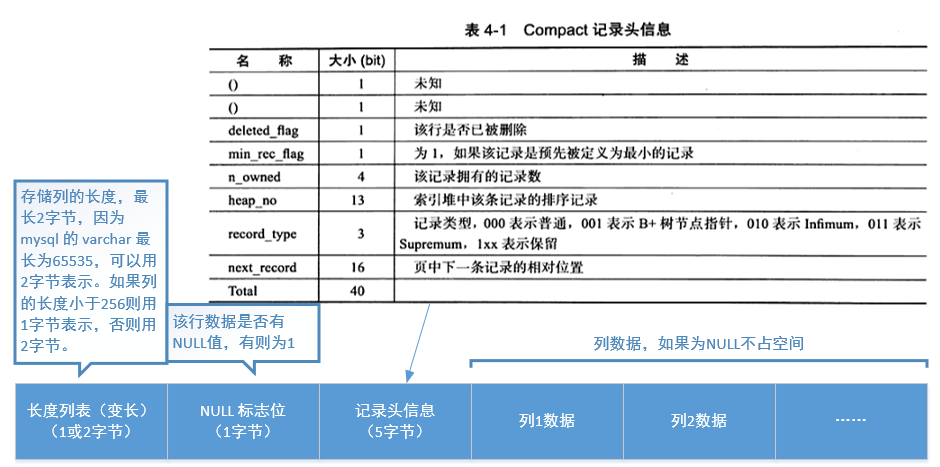
Redundant 行记录格式略。主要为了兼容MySQL5.0版本之前的页格式。
InnoDB 1.0.x 版本开始引入新的文件格式(即页格式)。以前的 Compact 和 Redundant 格式称为 Anteelope 文件格式,新的文件格式称为 Barracuda 文件格式(拥有两种新的行记录格式:Compressed 和 Dynamic)。新的格式采用了完全的行溢出方式,在数据页只存放 20 字节指针,实际的数据都存放在 Off Page 中。之前的两种格式则会存放 768 个前缀字节。
3.4 约束
3.4.1 数据完整性
关系型数据库系统本身能保证存储数据的完整性(相对的,文件系统需要在程序端进行控制),一般来说,数据完整性有以下三种形式:
- 实体完整性保证表中有一个主键
- InnoDB 中可以通过定义 Primary Key 或 Unique Key 约束来保证实体的完整性
- 用户编写触发器来保证数据完整性
InnoDB 提供了以下几种约束:
- Primary Key
- Unique Key
- Foreign Key
- Default
- NOT NULL
3.4.2 约束的创建和查找
约束创建可以在建表时定义约束,或者利用 ALTER TABLE 命令来创建约束。对 Unique Key 的约束,用户还可以通过命令 CREATE UNIQUE INDEX 来建立约束。
对于主键约束而言,其默认约束名为PRIMARY;而对于 Unique Key 约束而言,默认约束名和列名一样,当然也可以指定 Unique Key 约束的名字;Foreign Key 约束有一个系统生成的默认名称。
Primary Key & Unique Key
创建一个表,含有一个主键(Primary Key)约束和一个唯一键(Unique Key)约束。并查询约束信息:
CREATE TABLE `constraint_test` (
id INT,
username VARCHAR (20),
id_card CHAR (10),
PRIMARY KEY (id),
UNIQUE KEY (username)
);
SELECT
constraint_name, constraint_type
FROM
information_schema.TABLE_CONSTRAINTS
WHERE
table_schema = "test_innodb" AND table_name = "constraint_test";
-- 结果
+-----------------+-----------------+
| constraint_name | constraint_type |
+-----------------+-----------------+
| PRIMARY | PRIMARY KEY |
| username | UNIQUE |
+-----------------+-----------------+
-- 也可以使用 ALTER TABLE 来新增唯一约束:
ALTER TABLE `constraint_test` ADD UNIQUE KEY uk_id_card(id_card);
Foreign Key
为了建立外键约束,需要另一张表:
-- px 表的 u_id 字段关联 constraint_test 表的 id 字段
CREATE TABLE `px` (
id INT,
u_id INT,
PRIMARY KEY (id),
FOREIGN KEY (u_id) REFERENCES constraint_test(id)
)ENGINE=InnoDB;
-- 查看约束信息
SELECT
constraint_name, constraint_type
FROM
information_schema.TABLE_CONSTRAINTS
WHERE
table_schema = "test_innodb" AND table_name = "px";
+-----------------+-----------------+
| constraint_name | constraint_type |
+-----------------+-----------------+
| PRIMARY | PRIMARY KEY |
| px_ibfk_1 | FOREIGN KEY |
+-----------------+-----------------+
可以看到约束名是 pk_ibfk_1,系统自动生成的,如果需要手动指定名称,创建外键时可以用
CREATE TABLE `px` (
id INT,
u_id INT,
PRIMARY KEY (id),
CONSTRAINT fk_uid FOREIGN KEY (u_id) REFERENCES constraint_test(id)
)ENGINE=InnoDB;
-- 再次查看约束信息
+-----------------+-----------------+
| constraint_name | constraint_type |
+-----------------+-----------------+
| PRIMARY | PRIMARY KEY |
| fk_uid | FOREIGN KEY |
+-----------------+-----------------+
-- 还可以通过 REFERENTIAL_CONSTRAINTS 表查看外键的详细信息
select * from information_schema.REFERENTIAL_CONSTRAINTS where constraint_schema='test_innodb'\G;
-- 输出
*************************** 1. row ***************************
CONSTRAINT_CATALOG: def
CONSTRAINT_SCHEMA: test_innodb
CONSTRAINT_NAME: fk_uid
UNIQUE_CONSTRAINT_CATALOG: def
UNIQUE_CONSTRAINT_SCHEMA: test_innodb
UNIQUE_CONSTRAINT_NAME: PRIMARY
MATCH_OPTION: NONE
UPDATE_RULE: RESTRICT
DELETE_RULE: RESTRICT
TABLE_NAME: px
REFERENCED_TABLE_NAME: constraint_test
疑惑
原书作者在这节创建外键的时候,把主键外键放到了一张表上,也是可以创建成功的:
CREATE TABLE `p` (
id INT,
u_id INT,
PRIMARY KEY (id),
FOREIGN KEY (u_id) REFERENCES p(id)
)ENGINE=InnoDB;
笔者之前一直没有想过把外键放到一张表上(真是不爱思考),说起建立外键约束只是想到关联另外一张表的字段,所以这里一张表本身的字段也可以做外键,那这种特性可以干什么呢?
就具体到上面这个表,id是唯一主键,u_id是外键,关联到主键id上。它们的取值范围是下面这样:
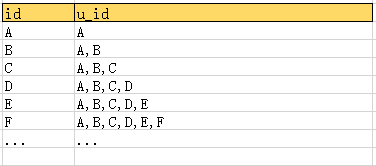
第一行的元素id和u_id都是一样,不然都存不进去。然后第二行对于id是个新元素,对于uid是所有的id集合都可以取。我好像看到了造物主的清单。
3.4.3 约束和索引的区别
当用户创建了一个唯一索引就创建了一个唯一的约束。但是约束和索引的概念不同,约束是一个逻辑概念,用来保证数据的完整性;而索引是一个数据结构,即有逻辑的概念,在数据库中还代表着物理存储的方式。
3.4.4 对错误数据的约束
MySQL数据库允许非法的或不正确的插入或更新,又或者可以在数据库内部转换为一个合法的值。如向 NOT NULL 的字段插入一个 NULL 值,MySQL 数据库会将其转为0再插入;向Date格式插入一个非法值,会转为默认值 0000-00-00。
这时,可以设置 sql_mode 包含 STRICT_TRANS_TABLES开启严格模式,用来对输入值进行约束。
# 创建表
create table error_data_district(
id int NOT NULL,
data Date NOT NULL
);
# 添加数据
insert into error_data_district select NULL,'2019-02-30';
# 查看模式
select @@sql_mode;
# 删除严格模式
set sql_mode = (select replace(@@sql_mode, 'STRICT_TRANS_TABLES', ''))
# 添加严格模式
set sql_mode = (select concat(@@sql_mode, ',STRICT_TRANS_TABLES'))
3.4.5 ENUM和SET约束
通过 ENUM 和 SET 类型可以约束数据值。ENUM(枚举) 存储取值范围内的单选值,SET 存储多选值。
3.4.6 触发器和约束
完整性约束通常也可以使用触发器来实现。触发器的作用是在执行 INSERT、DELETE 和 UPDATE 命令 之前(BEFORE) 或 之后(AFTER) 自动调用SQL命令或存储过程。通过触发器,用户可以实现 MySQL 数据库本身并不支持的一些特性。
创建触发器的语法如下:
CREATE
[DEFINER = {user | CURRENT_USER }]
TRIGER trigger_name BEFORE|AFTER INSERT|UPDATE|DELETE
ON tbl_name FOR EACH ROW trigger_stmt(程序体)
3.4.7 外键约束
之前约束创建小节例子中用过外键,这里补充其他知识点。
外键用来保证参照完整性。MySQL 数据库的 MyISAM 存储引擎本身并不支持外键,而 InnoDB 则完整支持外键约束。
外键定义如下:
[CONSTRAINT [symbol]] FOREIGN KEY
[index_name] (index_col_name, ...)
REFERENCES tbl_name (index_col_name, ...)
[ON DELETE reference_option]
[ON UPDATE reference_option]
--------------------------------------
refrence_option:
RESTRICT | CASCADE | SET NULL | NO ACTION
一般地,称被引用的表为父表,引用的表称为子表。外键定义时的 ON DELETE 和 ON UPDATE 表示在对父表进行 DELETE 或 UPDATE 操作时,对子表所做的操作。可定义的子表操作有上面 refrence_option 的四种:
CASCADE 表示当主表发生 DELETE 或 UPDATE 操作时,对相应子表中的数据也进行 DELETE 或 UPDATE 操作
SET NULL 时,对应子表的数据被更新为 NULL 值
RESTRICT 时,不允许主表 DELETE 或 UPDATE 操作,否则抛出错误。如果没指定 ON DELEE 或者 ON UPDATE,默认 RESTRICT
NO ACTION,在 MySQL 中同 RESTRICT 一样
A keyword from standard SQL. In MySQL, equivalent to RESTRICT. The MySQL Server rejects the delete or update operation for the parent table if there is a related foreign key value in the referenced table. Some database systems have deferred checks, and NO ACTION is a deferred check. In MySQL, foreign key constraints are checked immediately, so NO ACTION is the same as RESTRICT.
by https://dev.mysql.com/doc/refman/8.0/en/create-table-foreign-keys.html
3.5 视图(VIEW)
在 MySQL 中,视图是一个命令的虚拟表,它由一个 SQL 查询来定义,可以当做表使用。与持久表不同的是,视图中的数据没有实际的物理存储。
未完待续...
MySQL之InnoDB存储引擎 - 读书笔记的更多相关文章
- MySQL数据库InnoDB存储引擎多版本控制(MVCC)实现原理分析
文/何登成 导读: 来自网易研究院的MySQL内核技术研究人何登成,把MySQL数据库InnoDB存储引擎的多版本控制(简称:MVCC)实现原理,做了深入的研究与详细的文字图表分析,方便大家理解I ...
- MySQL数据库InnoDB存储引擎中的锁机制
MySQL数据库InnoDB存储引擎中的锁机制 http://www.uml.org.cn/sjjm/201205302.asp 00 – 基本概念 当并发事务同时访问一个资源的时候,有可能 ...
- MySql中innodb存储引擎事务日志详解
分析下MySql中innodb存储引擎是如何通过日志来实现事务的? Mysql会最大程度的使用缓存机制来提高数据库的访问效率,但是万一数据库发生断电,因为缓存的数据没有写入磁盘,导致缓存在内存中的数据 ...
- MySQL数据库InnoDB存储引擎
MySQL数据库InnoDB存储引擎Log漫游 http://blog.163.com/zihuan_xuan/blog/static/1287942432012366293667/
- mysql中InnoDB存储引擎的行锁和表锁
Mysql的InnoDB存储引擎支持事务,默认是行锁.因为这个特性,所以数据库支持高并发,但是如果InnoDB更新数据的时候不是行锁,而是表锁的话,那么其并发性会大打折扣,而且也可能导致你的程序出错. ...
- mysql之innodb存储引擎
mysql之innodb存储引擎 innodb和myisam区别 1>.InnoDB支持事物,而MyISAM不支持事物 2>.InnoDB支持行级锁,而MyISAM支持表级锁 3>. ...
- mysql技术内幕InnoDB存储引擎-阅读笔记
mysql技术内幕InnoDB存储引擎这本书断断续续看了近10天左右,应该说作者有比较丰富的开发水平,在源码级别上分析的比较透彻.如果结合高可用mysql和高性能mysql来看或许效果会更好,可惜书太 ...
- MySQL:InnoDB存储引擎的B+树索引算法
很早之前,就从学校的图书馆借了MySQL技术内幕,InnoDB存储引擎这本书,但一直草草阅读,做的笔记也有些凌乱,趁着现在大四了,课程稍微少了一点,整理一下笔记,按照专题写一些,加深一下印象,不枉读了 ...
- MySQL中InnoDB存储引擎的实现和运行原理
InnoDB 存储引擎作为我们最常用到的存储引擎之一,充分熟悉它的的实现和运行原理,有助于我们更好地创建和维护数据库表. InnoDB 体系架构 InnoDB 主要包括了: 内存池.后台线程以及存储文 ...
随机推荐
- 集合框架-Map集合-TreeMap存储自定义对象
1 package cn.itcast.p8.treemap.demo; 2 3 4 import java.util.Iterator; 5 import java.util.Map; 6 impo ...
- 【webpack4.0】---webpack的基本使用(二)
一.什么是plugins plugins可以使webpack在运行到某个时刻的时候,帮你做一些事情,类似于生命周期一样 plugins,它就是一个扩展器,它丰富了wepack本身,针对是loader结 ...
- python网络爬虫-python基础(三)
python安装 Anaconda的python科学计算环境,只需要想普通软件一样安装就可以把python的环境变量.解释器.开发环境都安装到计算机中 除此之外anaconda还提供众多的科学计算的包 ...
- Codeforces Round #738 (Div. 2)
Codeforces Round #738 (Div. 2) 跳转链接 A. Mocha and Math 题目大意 有一个长度为\(n\)的数组 可以进行无数次下面的操作,问操作后数组中的最大值的最 ...
- ApacheCN Golang 译文集 20211025 更新
Go 云原生编程 零.前言 一.现代微服务架构 二.使用 RESTAPI 构建微服务 三.保护微服务 四.使用消息队列的异步微服务架构 五.使用 React 构建前端 六.在容器中部署应用 七.AWS ...
- Func<>用法
Func是一个委托,委托里面可以存方法,Func<string,string>或Func<string,string,int,string>等 前几个是输入参数,最后一个是返回 ...
- Swift可选类型
可选类型 可选类型的介绍 注意: 可选类型时swift中较理解的一个知识点 暂时先了解,多利用Xcode的提示来使用 随着学习的深入,慢慢理解其中的原理和好处 概念: 在OC开发中,如果一个变量暂停不 ...
- 物理CPU,物理核,逻辑CPU,虚拟CPU(vCPU)区别 (转)
在做虚拟化时候,遇到划分CPU的问题,因此考虑到CPU不知道具体怎么划分,查询一些资料后就写成本文. a. 物理CPU:物理CPU是相对于虚拟CPU而言的概念,指实际存在的处理器,就是我们可以看的见, ...
- 浅谈VPC (转)
来源于知乎:https://zhuanlan.zhihu.com/p/33658624 VPC全称是Virtual Private Cloud,翻译成中文是虚拟私有云.但是在有些场合也被翻译成私有网络 ...
- argc 和 argv
转载请注明来源:https://www.cnblogs.com/hookjc/ 如果用C寫一般的命令列工具,常透過main函式的argc,argv來取得使用者所輸入的命令參數.int main(int ...