HBASE-使用问题-split region
问题描述:
HBASE表的管理以REGION分区为核心,通常面临如下几个问题:
1) 数据如何存储到指定的region分区,即rowkey设计,region splitkey设计
2)设计的splitkey是否可以解决热点问题
3)设计的splitkey是否可以解决均匀分布,避免自动分裂的问题
4)region的创建和删除问题
对于1)问题 比如:对于按照时间存储的数据,region splitkey 可以是2019,2020 ; 201901,201902;20190101 等等类似方式,可以把指定时间段的数据存储到响应splitkey的region中,达到按照时间存储的效果。
对于2)问题,同一天的数据,可以通过对rowkey或者数据中的一个或多个字段取hash方式,解决热点问题;如果数据存在重复入库,则需要保证用于hash的字段值在两次入库时不能变更,否则会存在两个rowkey数据 即splitkey中包含hash值部分,同样要求rowkey包含hash值
对于3)问题,需要考虑数据量和region分区的关系,比如一天有150G的数据量,hbase 单个region建议10~20G大小,设计时则需要考虑一天需要划分多少的region,才能避免region在数据入库时发生频繁split,会影响hbase服务(split会涉及数据移动,数据通过网络传输和落盘,影响网络和磁盘IO)
对于4)问题,未来的region是否应该提前创建,如何创建?集群存储是否足够,历史的region是否下线或者删除?
此篇文章是在提前创建region分区时遇到的问题
一般的设计方法是,在hbase 尾部region切分新的多个region,用于新的数据存储,通常使用定时任务,提前创建
切分方式是通过调用HBASE split region方法,region尾部splitkey为 20210600 ~“” 需要切分的splitkey为20210601,20210602,20210603,20210700
采用的方法是: 先20210601切分,得到如下两个region: 20210600 ~20210601, 20210601~“” 然后等待 20210601~“” 此region上线,再使用20210602切分
以此类推
但是在实际项目中发现,只切分了一个region就任务结束了,程序本身在等待新切分region上线时,可以等待1s~60秒中,发现此问题后,可以配置等待时长,
但是实际效果不好,仍会存在上述问题
1) 观察Hbase regionServer端日志,发现如下日志,debug日志显示待切分region对应的存储文件正在被引用使用,导致region split请求切分失败

2)分析Hbase 源码:

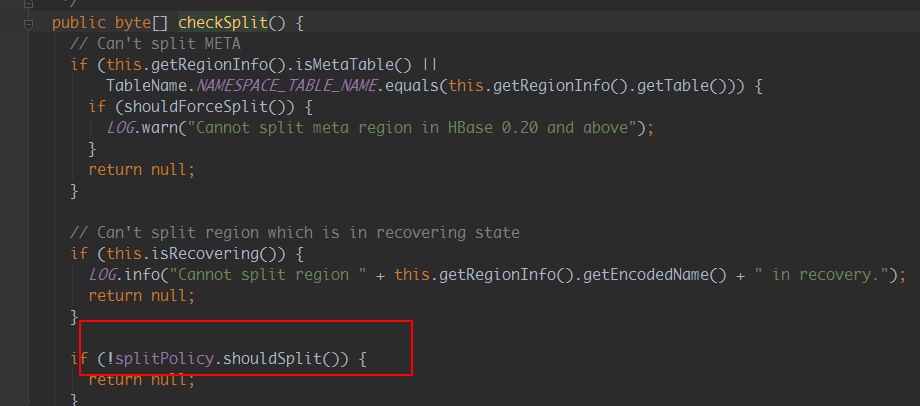
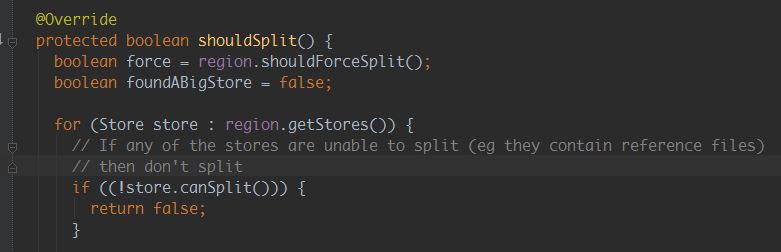
原因分析:hbase split请求调用的为异步请求,通过源码并结合hbase regionserver日志可以看出,hbase接收到split请求后,
如果发现需要被切分的region有引用文件时,就返回失败;因为时异步请求,所以程序等待新切分region上线不可行
即Hbase接收到请求后,由于存储文件被引用使用,导致请求失败,region未切分,索引新切分region不会上线,从而失败
修改后方法逻辑为:切分region,等待一段时间上线,不上线则再次切分region,以此多次,仍不成功,则等待下次定时任务触发切分
额外说明:
实际项目中被切分region如果里面有大量数据,切分速度会很快,但是对切分后的region再次切分时,文件引用有较长时间不会消失,无法再次切分
因此实际项目中考虑切分没有数据的尾部region为佳,此外重试切分的时间间隔建议可配置,以免region未及时切分,导致所有数据存入到尾部一个region中
HBASE-使用问题-split region的更多相关文章
- Spark读Hbase优化 --手动划分region提高并行数
一. Hbase的region 我们先简单介绍下Hbase的架构和Hbase的region: 从物理集群的角度看,Hbase集群中,由一个Hmaster管理多个HRegionServer,其中每个HR ...
- HBase工具之监控Region的可用和读写延时状况
1.介绍HBase集群上region数目由于业务驱动而越来越多,由于服务器本身,网络以及hbase内部的一些不确定性bug等因素使得这些region可能面临着不可用或响应延时情况.通过对region的 ...
- HBase单个RegionServer的region数目上限
前言 RegionServer维护Master分配给它的region,处理对这些region的IO请求,负责切分在运行过程中变得过大的region, 由于集群性能( 分配的内存和磁盘是有限的 )有限的 ...
- hbase总结:如何监控region的性能
转载:http://ju.outofmemory.cn/entry/50064 随着大数据表格应用的驱动,我们的HBase集群越来越大,然而由于机器.网络以及HBase内部的一些不确定性的bug,使得 ...
- HBase如何选取split point
hbase region split操作的一些细节,具体split步骤很多文档都有说明,本文主要关注regionserver如何选取split point 首先推荐web ui查看hbase regi ...
- hbase 各个概念,region,storefile
HBase中有两张特殊的Table,-ROOT-和.META. .META.:记录了用户表的Region信息,它可以有多高region(这的意思是说.META.表可以分 裂成多个region,和用户表 ...
- hbase(一)region
前言 文章不含源码,只是一些官方资料的整理和个人理解 架构总览 这张图在大街小巷里都能看到,感觉是hbase架构中最详细最清晰的一张,稍微再补充几点. 1) Hlog是低版本hbase术语,现在称为W ...
- HBase 分裂(split)
1. 为什么split 最初一个Table 只有一个region(因此只能存放在一个region server上).随着数据的不断写入,HRegion越来越大,当到达一定程度后分裂为两个,通过负载均衡 ...
- HBase Shell手动移动Region
在生产环境中很有可能有那么几个Region比较大,但是都运行在同一个Regionserver中. 这个时候就需要手动将region移动到负载低的Regionserver中. 步骤: 1.找到要移动的r ...
随机推荐
- uni-app(二)接口请求封装,全局输出api
在项目 main.js 同级创建 utils 文件夹, utils里创建 config.js文件,存储重要参数 // 获取平台信息 const { system, } = uni.getSystemI ...
- Python读写配置文件模块--Configobj
一.介绍 我们在项目的开发过程中应该会遇到这样的问题:我们的项目读取某个配置文件,然后才能按照配置的信息正常运行服务,当我们需要对修改服务的某些信息时,可以直接修改这个配置文件,重启服务即可,不用再去 ...
- 微信小程序应用开发-手动创建
基础知识: index.wxml的代码为 Html,有很多标签,如等 index.wwss相当于css 即样式 index.js中有很多函数,可自定义 操作步骤: 删除app.json文件中page/ ...
- Hadoop企业开发场景案例,虚拟机服务器调优
Hadoop企业开发场景案例 1 案例需求 (1)需求:从1G数据中,统计每个单词出现次数.服务器3台,每台配置4G内存,4核CPU,4线程. (2)需求分析: 1G/128m = 8个M ...
- docker部署nodejs项目应用
之前笔者弄了一套nestjs项目放在自己服务器上,并用pm2管理进程. 现在要把pm2停止,尝试一下用docker容器,那么首先要安装docker 一.安装docker 由于笔者服务器的系统是cent ...
- [Fundamental of Power Electronics]-PART I-6.变换器电路-6.3 变压器隔离
6.3 变压器隔离 在许多应用场合中,期望将变压器结合到开关变换器中,从而在变换器的输入输出之间形成直流隔离.例如,在离线(off-line)应用中(变换器输入连接到交流公用系统),根据监管部门要求, ...
- Day12_59_Java多线程
多线程 1. 什么是进程? * 每个进程是一个应用程序,都有独立的内存空间,一个进程对应一个应用程序. * 例如:在windows操作系统中启动了word就是启动了一个进程,一边听音乐,一边打游戏就是 ...
- aws eks上部署 ingress-nginx 加NLB
转载自https://kubernetes.github.io/ingress-nginx/deploy/#aws In AWS we use a Network load balancer (NLB ...
- SpringMVC请求参数解析
请求参数解析 客户端请求在handlerMapping中找到对应handler后,将会继续执行DispatchServlet的doPatch()方法. 首先是找到handler对应的适配器. Hand ...
- 经典论文系列| 实例分割中的新范式-SOLO
前言: 这是实例分割中的一篇经典论文,以往的实例分割模型都比较复杂,这篇论文提出了一个简单且直接的实例分割模型,如何设计这种简单直接的模型且要达到一定的精度往往会存在一些困难,论文中有很多思路或思想值 ...