freeswitch的任务引擎实现分析
概述
freeswitch核心框架中有一个定时任务系统,在开发过程中用来做一些延时操作和异步操作很方便。
我们在VOIP的呼叫流程中,经常会有一些对实时性要求没那么高的操作,或者会有阻塞流程的操作,我们都可以开启一个定时任务子流程,来达到延时和异步的目标。
下面,我们来对这个任务引擎的代码实现做一个简单的梳理和分析。
环境
centos:CentOS release 7.0 (Final)或以上版本
freeswitch:v1.8.7
GCC:4.8.5
数据结构
源码文件
src\include\switch_scheduler.h
src\switch_scheduler.c
任务数据结构
struct switch_scheduler_task {
int64_t created;
int64_t runtime;
uint32_t cmd_id;
uint32_t repeat;
char *group;
void *cmd_arg;
uint32_t task_id;
unsigned long hash;
};
struct switch_scheduler_task_container {
switch_scheduler_task_t task;
int64_t executed;
int in_thread;
int destroyed;
int running;
switch_scheduler_func_t func;
switch_memory_pool_t *pool;
uint32_t flags;
char *desc;
struct switch_scheduler_task_container *next;
};
typedef struct switch_scheduler_task_container switch_scheduler_task_container_t;
static struct {
switch_scheduler_task_container_t *task_list;
switch_mutex_t *task_mutex;
uint32_t task_id;
int task_thread_running;
switch_queue_t *event_queue;
switch_memory_pool_t *memory_pool;
} globals;
总图
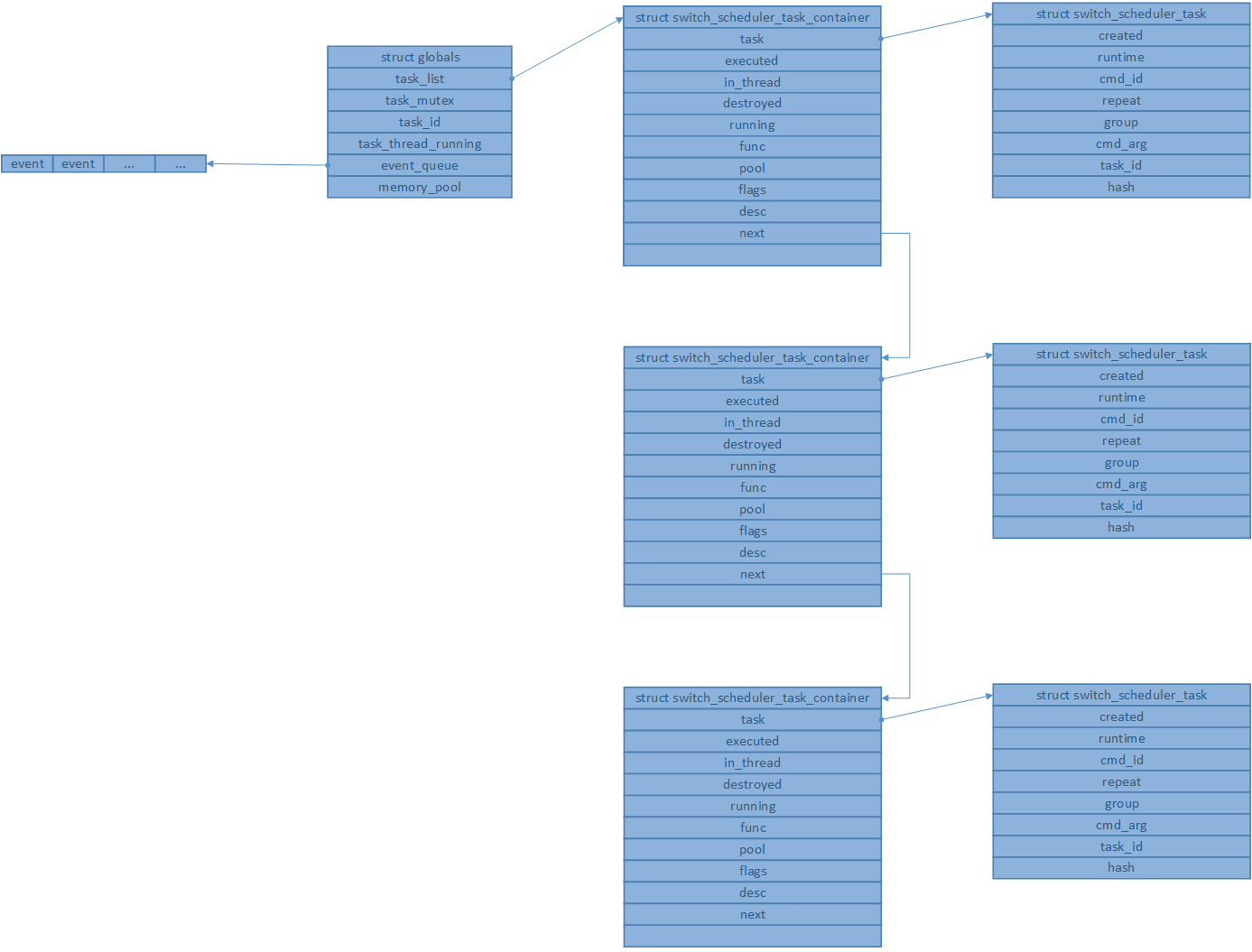
常用接口
查看src\include\switch_scheduler.h头文件,常用接口如下。
switch_scheduler_add_task //Schedule a task in the future
switch_scheduler_del_task_id //Delete a scheduled task
switch_scheduler_del_task_group //Delete a scheduled task based on the group name
switch_scheduler_task_thread_start //Start the scheduler system
switch_scheduler_task_thread_stop //Stop the scheduler system
外部接口很简单。初始化接口使用start和stop,新增任务使用add_task,删除任务使用del_task_id,另外有一个del_task_group的接口针对任务群。
引擎初始化switch_scheduler_task_thread_start
函数原型
SWITCH_DECLARE(void) switch_scheduler_task_thread_start(void);
函数逻辑:
1, 初始化内存池globals.memory_pool。
2, 初始化互斥锁globals.task_mutex。
3, 初始化消息队列globals.event_queue。
4, 创建任务执行线程,线程函数switch_scheduler_task_thread,以下是任务线程的逻辑流程。
5, 设置全局变量globals.task_thread_running = 1。
6, 任务线程循环开始,task_thread_loop(0)。
7, 加锁globals.task_mutex。
8, 遍历任务链表globals.task_list,检查任务执行时间,符合执行时间的任务检查线程标识,对于有单独线程标识SSHF_OWN_THREAD的任务启动线程task_own_thread并执行,对于没有单独线程标识的任务,在当前线程中执行。
9, 解锁globals.task_mutex。
10, 加锁globals.task_mutex。
11, 遍历任务链表globals.task_list,检查任务删除标识tp->destroyed,销毁任务,释放任务相关内存。
12, 解锁globals.task_mutex。
13, 从全局消息队列globals.event_queue中获取事件,并发布该事件。
14, 任务线程循环结束。
15, task_thread_loop(1),遍历任务链表globals.task_list,设置所有任务删除标识tp->destroyed = 1,销毁任务,释放任务相关内存。
16, 从全局消息队列globals.event_queue中获取事件并销毁。
17, 设置全局变量globals.task_thread_running = 0。
引擎初始化后的内存模型如图
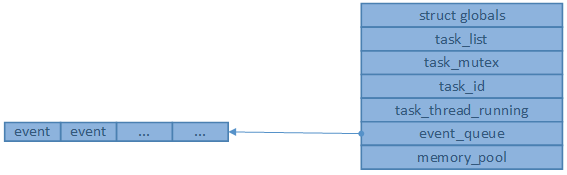
引擎停止switch_scheduler_task_thread_stop
函数原型
SWITCH_DECLARE(void) switch_scheduler_task_thread_stop(void);
函数逻辑:
1, 设置全局变量globals.task_thread_running=-1。
2, 等待任务线程退出。
3, 销毁内存池globals.memory_pool。
新增任务switch_scheduler_add_task
函数原型
SWITCH_DECLARE(uint32_t) switch_scheduler_add_task(time_t task_runtime,
switch_scheduler_func_t func,
const char *desc, const char *group, uint32_t cmd_id, void *cmd_arg, switch_scheduler_flag_t flags);
函数逻辑:
1, 加锁globals.task_mutex。
2, 分配一块内存给任务容器container,类型为switch_scheduler_task_container_t。
3, container数据初始化。包括回调函数func和任务预定运行时间等信息。
4, 将container插入任务链表globals.task_list的队尾。
5, 解锁globals.task_mutex。
6, 新建SWITCH_EVENT_ADD_SCHEDULE事件,并将事件插入消息队列globals.event_queue。
7, 结束返回任务id。
增加多个任务之后的内存模型如图
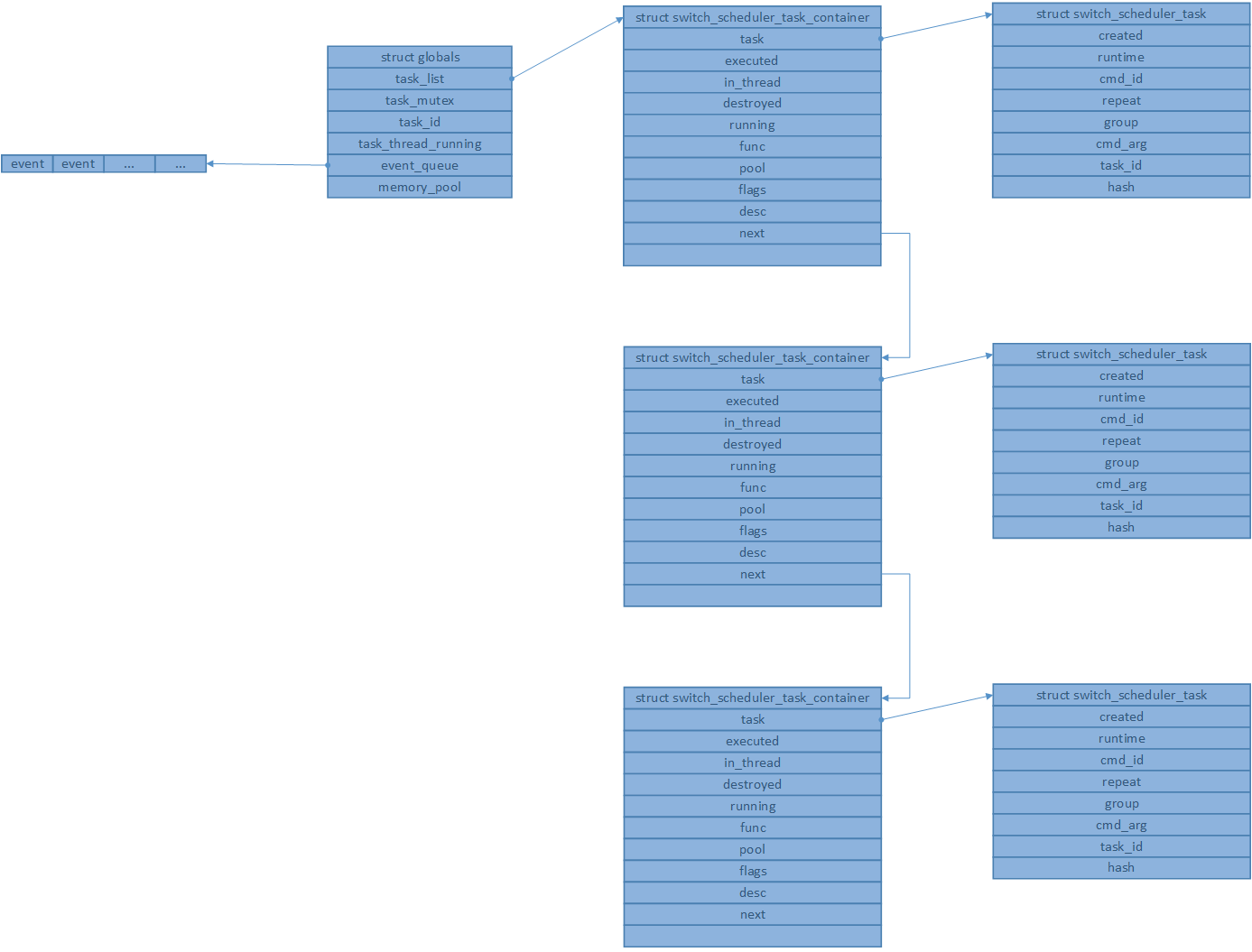
删除任务switch_scheduler_del_task_id
函数原型
SWITCH_DECLARE(uint32_t) switch_scheduler_del_task_id(uint32_t task_id);
函数逻辑:
1, 加锁globals.task_mutex。
2, 遍历任务链表globals.task_list,找到对应task_id的任务。
3, 任务标识SSHF_NO_DEL则不删除。
4, 任务正在运行则不删除。
5, 设置任务删除标识tp->destroyed++。
6, 解锁globals.task_mutex。
总结
任务引擎中的循环,在任务执行正常的情况下,每隔500ms检查1次任务链表,在实际应用中,可能会有一定的延迟,无法做到实时执行。
对于任务的执行过程,考虑到有阻塞操作的任务,一定要使用单独线程执行,否则会阻塞其他任务。
定时任务引擎,使用时间轮模式是否更好用?
空空如常
求真得真
freeswitch的任务引擎实现分析的更多相关文章
- JQuery Sizzle引擎源代码分析
最近在拜读艾伦在慕课网上写的JQuery课程,感觉在国内对JQuery代码分析透彻的人没几个能比得过艾伦.有没有吹牛?是不是我说大话了? 什么是Sizzle引擎? 我们经常使用JQuery的选择器查询 ...
- Java三大主流开源工作流引擎技术分析
首先,这个评论是我从网上,书中,搜索和整理出来的,也许有技术点上的错误点,也许理解没那么深入.但是我是秉着学习的态度加以评论,学习,希望对大家有用,进入正题! 三大主流工作流引擎:Shark,oswo ...
- Spark与Flink大数据处理引擎对比分析!
大数据技术正飞速地发展着,催生出一代又一代快速便捷的大数据处理引擎,无论是Hadoop.Storm,还是后来的Spark.Flink.然而,毕竟没有哪一个框架可以完全支持所有的应用场景,也就说明不可能 ...
- [转]JQuery - Sizzle选择器引擎原理分析
原文: https://segmentfault.com/a/1190000003933990 ---------------------------------------------------- ...
- Presto查询引擎简单分析
Hive查询流程分析 各个组件的作用 UI(user interface)(用户接口):提交数据操作的窗口Driver(引擎):负责接收数据操作,实现了会话句柄,并提供基于JDBC / ODBC的ex ...
- 005 -- Mysql数据库引擎特点分析
常用的数据库引擎的特点: ISAM: ISAM是一个定义明确且历经时间考验的数据表格管理方法,它在设计之时就考虑到数据库查询次数要远大于更新次数.因此,ISAM执行读取操作的速度很快,而且不占用大量的 ...
- Flink流式引擎技术分析--大纲
Flink简介 Flink组件栈 Flink特性 流处理特性 API支持 Libraries支持 整合支持 Flink概念 Stream.Transformation.Operator Paralle ...
- MongoDb Mmap引擎分析
版权声明:本文由孔德雨原创文章,转载请注明出处: 文章原文链接:https://www.qcloud.com/community/article/137 来源:腾云阁 https://www.qclo ...
- 开源大数据引擎:Greenplum 数据库架构分析
Greenplum 数据库是最先进的分布式开源数据库技术,主要用来处理大规模的数据分析任务,包括数据仓库.商务智能(OLAP)和数据挖掘等.自2015年10月正式开源以来,受到国内外业内人士的广泛关注 ...
随机推荐
- 【webpack4.0】---dev.config.js基本配置(六)
一.开发环境配置准备 1.创建dev.config.js文件 用来配置开发环境的代码 2.安装webpack-merge cnpm install webpack-merge -D 用来合并webpa ...
- Mysql-5.7主从部署-yum方式
一.环境准备 # rpm -qa |grep mariadb |xargs yum remove -y # setenforce 0(临时关闭),(selinux配置文件:SELINUX=disabl ...
- System.arraycopy()的用法?
1.使用方法 public void arr(Object arr1, int x, Object arr2, int y, int length) arr1 : 源数组; x: 需要从源数组要复制的 ...
- ApacheCN 数据科学译文集 20211109 更新ApacheCN 数据科学译文集 20211109 更新
计算与推断思维 一.数据科学 二.因果和实验 三.Python 编程 四.数据类型 五.表格 六.可视化 七.函数和表格 八.随机性 九.经验分布 十.假设检验 十一.估计 十二.为什么均值重要 十三 ...
- salesforce零基础学习(一百一十一)custom metadata type数据获取方式更新
本篇参考: https://developer.salesforce.com/docs/atlas.en-us.234.0.apexref.meta/apexref/apex_methods_syst ...
- SpringBoot Log4j 安全漏洞分析及解决方案
一.序言 SpringBoot作为Java基础框架大行其道,前不久爆发出Log4j安全漏洞,大众更多关心Log4j的危害是多么严重,然而鲜有关心SpringBoot这一底层框架的安全性问题,换而言之, ...
- Android WebView组件 访问部分网页崩溃问题【已解决】
最近刚接触Android,在测试WebView组件时发现总是出现崩溃现像: 提示:ERR_CLEARTEXT_NOT_PERMITTED 当时以为是权限问题,查找自己的AndroidManifest文 ...
- Spring Boot配置多个DataSource (转)
使用Spring Boot时,默认情况下,配置DataSource非常容易.Spring Boot会自动为我们配置好一个DataSource. 如果在application.yml中指定了spring ...
- cross-env 作用
是什么 运行跨平台设置和使用环境变量的脚本 出现原因 当您使用NODE_ENV =production, 来设置环境变量时,大多数Windows命令提示将会阻塞(报错). (异常是Windows上的B ...
- markdown常见问题
图片的引用问题:  为啥不显示图片?????? 解答:图片路径不支持中文 斜体跟加粗 *强调* 或者 _强调_ (示例:斜体) **加重强调** ...