深度剖析数仓CN增量备份技术
摘要:为了解决Roach的性能问题,提出了CN增量备份手段,从而达到进一步优化RPO目的。
本文分享自华为云社区《GaussDB(DWS)备份容灾之CN增量备份》,作者: zxy_db 。
1. 摘要
在数据量增大时,如果CN每次都做全量备份,则会导致每次的备份数据量很大,不仅会降低备份的性能,也从造成备份集恢复性能的降低。如果改成CN增量备份,则备份集只会备份差异数据,这样不仅会使得备份数据量变小,而且也会提升备份集恢复的性能。
2. CN备份原理
对于主备集群CN备份与恢复的过程,如下图所示:
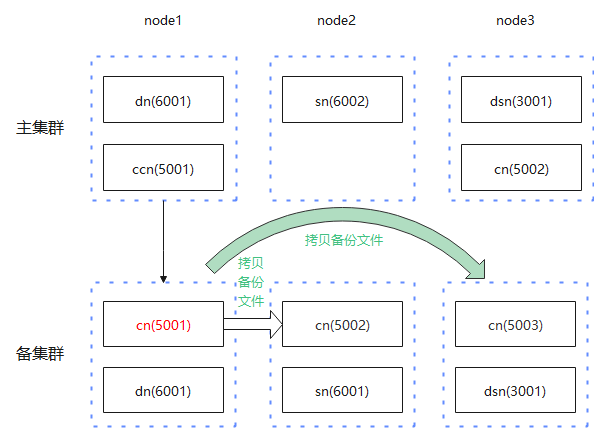
- 在备份过程中,只备份主CN的数据,且只发送到备集群对应的主CN所在的节点上。
- 在恢复过程中,非主CN节点从主CN节点上拷贝rch文件,然后再将备份数据的rch文件恢复到实例目录。
- CN备份同集群备份一样,先进行行存备份,后进行列存备份。
对于行存备份过程,首先是准备列表,然后备份文件。
准备列表主要分为3个步骤:第一步是获取CN备份类型,第二步是根据备份类型,决定LSN区间,第三步是根据LSN区间,准备备份列表(全量备份列表和增量备份列表)。
对于列存备份过程,同上述行存。
行存和列存区别在于增量备份LSN区间的取法:
行存文件来说,增量是上次startLSN到本次startLSN之间
列存文件来说,增量是上次barrierLSN到本次barrierLSN之间
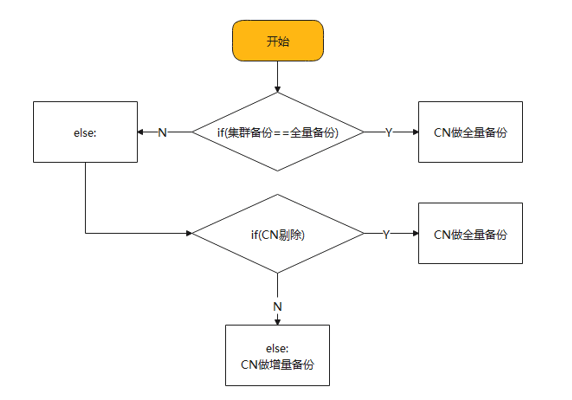
3. CN备份判断逻辑
- 首先,CN增量需要有一个基础备份,因此,集群在做全量备份时,CN仍然做全量备份。
- 其次,集群在两次增量备份过程中,CN发生删除和加回后,新增的CN需要做全量备份。
对于支持异构的情况下,如果ID最小的CN发生变化,同样需要对CN做一次全量备份。
整体的备份逻辑如下图所示。
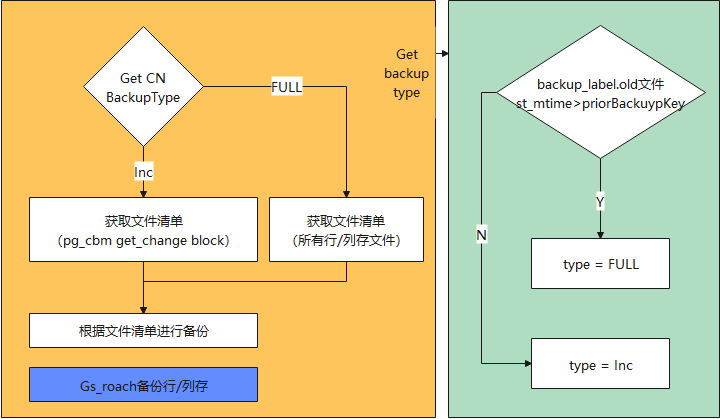
3.为了实现上述判断逻辑,通过创建标志文件backup_label.old来控制CN做全量备份还是增量备份。backup_label.old在Python侧创建。即在Python侧,调用gs_roach备份前,在最小的CN上,即要进行备份的CN上,创建backup_label.old文件。根据backup_label.old的修改时间和priorBackupKey转化的时间,判断CN做增量备份还是全量备份。流程图如下图所示。如右半部分所示,如果backup_label.old文件的修改时间比prriorBackupKey转换获得的时间大,则进行全量备份。否则,进行增量备份。
4. CN备份技术应用实测
4.1 CN删除和加回后做全量备份
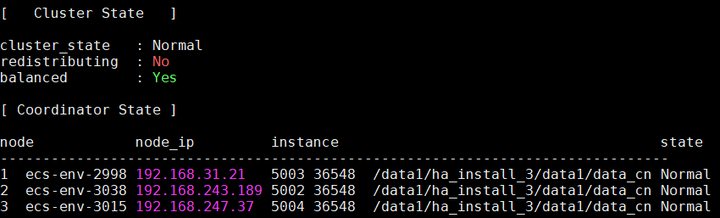
初始状态,ecs-env-3038节点上的CN实例是最小CN编号,即主CN
第一步:修改XML配置文件xml,将主CN对应主机上的cooNum值从1改为0

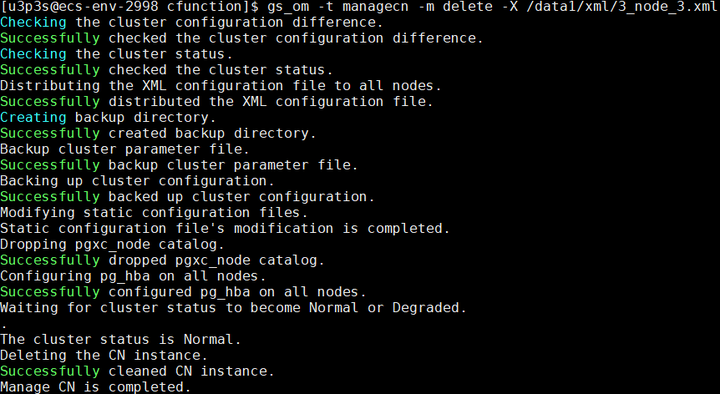
第二步:使用gs_om工具执行删除CN操作
gs_om -t managecn -m delete -X /data1/xml/3_node_3.xml
第三步:将要加回CN对应主机上的cooNum值从0改为1
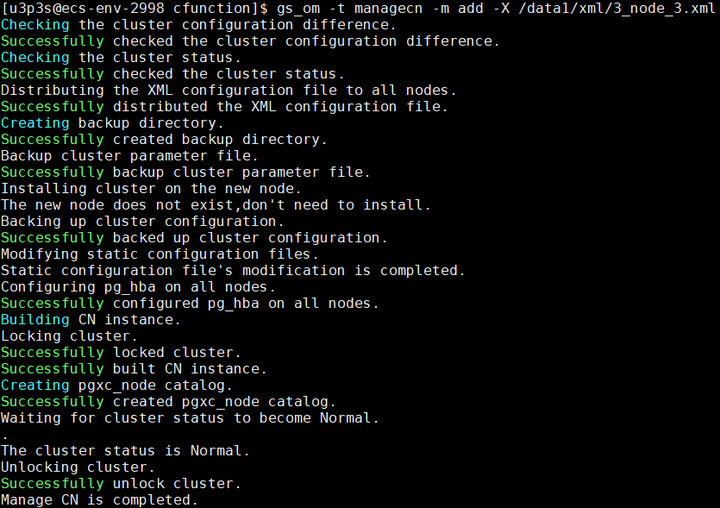
第四步:使用gs_om工具执行加回CN操作
gs_om -t managecn -m add -X /data1/xml/3_node_3.xml
删除和加回后,主CN的变化情况:
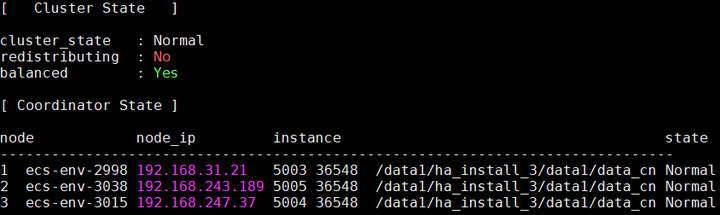
主CN由节点ecs-env-3038变为节点ecs-env-2998.
此时查看日志可以发现,由于CN发生了增删,集群做增量备份时,CN做全量备份。

4.2 备份集大小变化
第一步:拉起容灾,CN增量备份阶段停止容灾;
第二步:创建大量数据库和空表;
第三步:连续执行增量备份,增量备份中途不插入任何数据。
如下图所示,不增加数据,增量备份集大小小于全量备份集大小

5. 技术总结
本文主要从技术价值、应用场景、技术原理、技术实测展示几个维度对GaussDB(DWS) CN增量备份技术进行了剖析,可以看到增量备份是对已有全量备份恢复的一个有效的增强,可以节省宝贵的备份存储空间和cpu资源,同时达到进一步优化RPO目的,因此该技术拥有较为广阔的前景和深远的意义。
深度剖析数仓CN增量备份技术的更多相关文章
- 深度剖析:CDN内容分发网络技术原理--转载
1.前言 Internet的高速发展,给人们的工作和生活带来了极大的便利,对Internet的服务品质和访问速度要求越来越高,虽然带宽不断增加,用户数量也在不断增加,受Web服务器的负荷和传输距离等因 ...
- 【云+社区极客说】新一代大数据技术:构建PB级云端数仓实践
本文来自腾讯云技术沙龙,本次沙龙主题为构建PB级云端数仓实践 在现代社会中,随着4G和光纤网络的普及.智能终端更清晰的摄像头和更灵敏的传感器.物联网设备入网等等而产生的数据,导致了PB级储存的需求加大 ...
- 示例说明Oracle RMAN两种库增量备份的差别
1差异增量实验示例 1.1差异增量备份 为了演示增量备份的效果,我们在执行一次0级别的备份后,对数据库进行一些改变. 再执行一次1级别的差异增量备份: 执行完1级别的备份后再次对数据库进行更改: 再执 ...
- libevent源码深度剖析十
libevent源码深度剖析十 ——支持I/O多路复用技术 张亮 Libevent的核心是事件驱动.同步非阻塞,为了达到这一目标,必须采用系统提供的I/O多路复用技术,而这些在Windows.Linu ...
- 【Oracle】增量备份和全库备份怎么恢复数据库
1差异增量实验示例 1.1差异增量备份 为了演示增量备份的效果,我们在执行一次0级别的备份后,对数据库进行一些改变. 再执行一次1级别的差异增量备份: 执行完1级别的备份后再次对数据库进行更改: 再执 ...
- [转帖]首颗国产DRAM芯片的技术与专利,合肥长鑫存储的全面深度剖析
首颗国产DRAM芯片的技术与专利,合肥长鑫存储的全面深度剖析 https://mp.weixin.qq.com/s/g_gnr804q8ix4b9d81CZ1Q 2019.11 存储芯片已经成为全球珍 ...
- WCF技术剖析之十九:深度剖析消息编码(Encoding)实现(下篇)
原文:WCF技术剖析之十九:深度剖析消息编码(Encoding)实现(下篇) [爱心链接:拯救一个25岁身患急性白血病的女孩[内有苏州电视台经济频道<天天山海经>为此录制的节目视频(苏州话 ...
- HAWQ取代传统数仓实践(十六)——事实表技术之迟到的事实
一.迟到的事实简介 数据仓库通常建立于一种理想的假设情况下,这就是数据仓库的度量(事实记录)与度量的环境(维度记录)同时出现在数据仓库中.当同时拥有事实记录和正确的当前维度行时,就能够从容地首先维护维 ...
- MySQL系列详解五: xtrabackup实现完全备份及增量备份详解-技术流ken
xtrabackup简介 xtrabackup是一个用来对mysql做备份的工具,它可以对innodb引擎的数据库做热备.xtrabackup备份和还原速度快,备份操作不会中断正在执行的事务,备份完成 ...
随机推荐
- 集合框架-工具类-Arrays方法介绍
1 package cn.itcast.p3.toolclass.arrays.demo; 2 3 import java.util.Arrays; 4 5 public class ArraysDe ...
- X000001
一些相互无关联的题目的集合 都是码量不大,略有思维难度的题 做起来还是很舒适的 P6312 [PA2018]Palindrom 空间限制很小,不足以存下整个字符串,故暴力判断不可行. 考虑使用字符串哈 ...
- 洛谷 P4708 画画(无标号欧拉子图计数)
首先还是类似于无标号无向图计数那样,考虑点的置换带动边的置换,一定构成单射,根据 Burnside 引理: \[|X / G| = \frac{1}{|G|}\sum\limits_{g \in G} ...
- Java中的UIManager简单实用(皮肤包)
感谢大佬:https://blog.csdn.net/u010022051/article/details/52671860 注:具体详情请查阅Java API文档 /** * 设置图形界面外观 * ...
- NSArray文件读写
1.NSArray数据写入到文件中 NSArray *arr = @[@"lnj", @"lmj", @"jjj", @"xcq& ...
- nginx启动失败:Redirecting to /bin/systemctl start nginx.service Failed to start nginx.service: Unit not found.
解决方法: 是因为nginx没有有添加到系统服务,手动手动添加一个即可. 在 /etc/init.d/下创建名为nginx的启动脚本即可,内容如下: #!/bin/bash # # chkconfig ...
- play的action链(一个action跳转到另一个action,类似于重定向)
在play中没有Servlet API forward 的等价物.每一个HTTP request只能调用一个action.如果我们需要调用另一个,必须通过重定向,让浏览器访问另一个URL来访问它.这样 ...
- MySQL MHA 高可用集群部署及故障切换
MySQL MHA 高可用集群部署及故障切换 1.概念 2.搭建MySQL + MHA 1.概念: a)MHA概念 : MHA(MasterHigh Availability)是一套优秀的MySQL高 ...
- Python中set集合常用操作
功能 Python符号 Python方法 备注 交集 & intersection, intersection_update &:取两者交集>>> set3 = se ...
- Vue 子组件更新父组件的值
今天在使用Vue中遇到了一个新的需求:子组件需要修改由父组件传递过来的值,由于子组件的值是由父组件传递过来的,不能直接修改属性的值, 我们想改变传递过来的值只能通过自定义事件的形式修改父组件的值达到修 ...