Coursera Deep Learning笔记 深度卷积网络
1. Why look at case studies
介绍几个典型的CNN案例:
LeNet-5
AlexNet
VGG
Residual Network(ResNet): 特点是可以构建很深的神经网络
Inception Neural Network
2. Classic Networks
典型的 LeNet-5 结构包含CONV layer,POOL layer 和 FC layer
顺序一般是
CONV layer->POOL layer->CONV layer->POOL layer->FC layer->FC layer->OUTPUT layer,即 \(\hat{y}\)。下图所示的是一个数字识别的LeNet-5的模型结构:

LeNet模型 总共包含了大约6万个参数。
Yann LeCun提出的 LeNet-5模型 池化层使用的是:average pool
各层激活函数一般是Sigmoid和tanh。现在,我们可以根据需要,做出改进,使用 max pool 和 激活函数ReLU。
AlexNet模型 其结构如下所示:
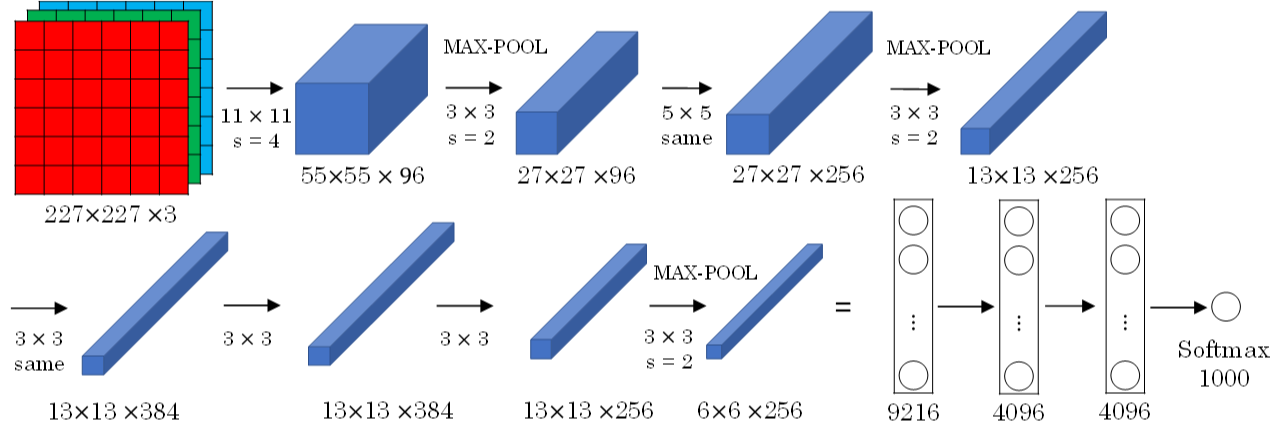
AlexNet模型与LeNet-5模型类似,更加复杂,共包含了大约6千万个参数。
同样可以根据实际情况使用 激活函数ReLU。有一个优化技巧,叫做Local Response Normalization(LRN)。 而在实际应用中,LRN的效果并不突出。
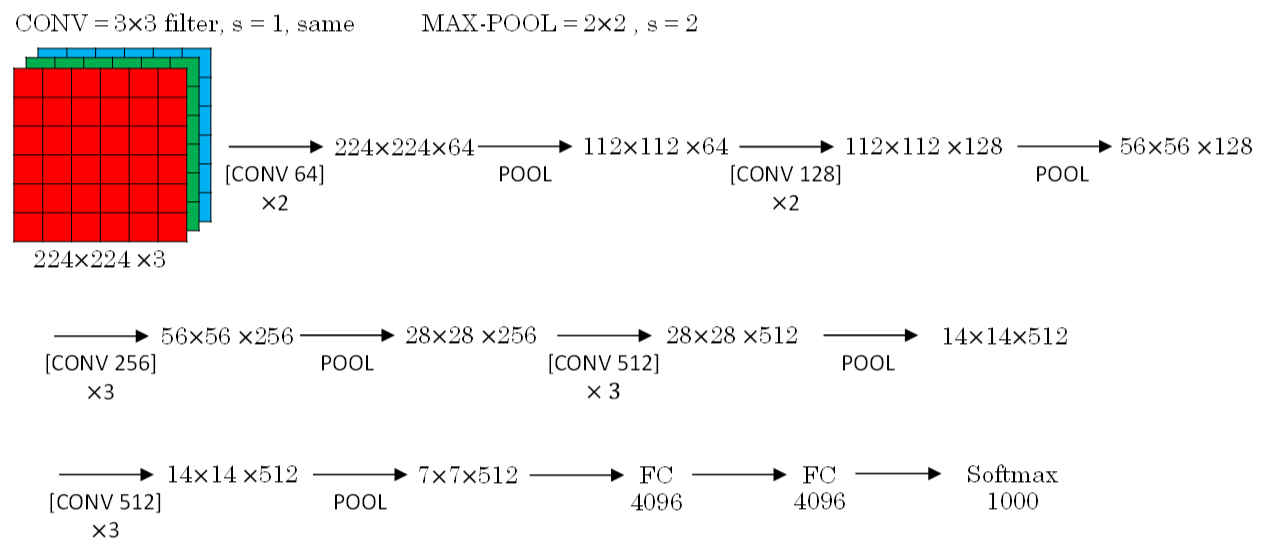
VGG-16模型 更复杂,其 CONV layer 和 POOL layer 设置如下:
CONV = 3x3 filters, s = 1, same
MAX-POOL = 2x2, s = 2
VGG-16结构如下所示,VGG-16的参数多达1亿3千万。:
3. ResNets
如果神经网络层数越多,网络越深,源于 梯度消失 和 梯度爆炸 的影响,整个模型难以训练成功。
解决的方法:
人为地让神经网络 某些层 跳过下一层神经元的连接,隔层相连,弱化每层之间的强联系。
这种神经网络被称为 Residual Networks(ResNets)。
Residual Networks由许多 隔层相连的神经元子模块 组成,称之为 Residual block。
单个Residual block的结构如下图所示:
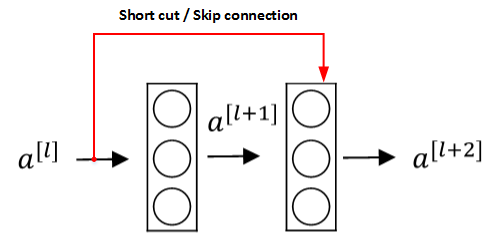
上图中红色部分就是skip connection,直接建立 \(a^{[l]}\) 与 \(a^{[l+2]}\) 之间的隔层联系。相应表达式:
\\
a^{[l+1]} = g(z^{[l+1]}) \\
\\
z^{[l+2]} = W^{[l+2]}a^{[l+1]} + b^{[l+2]} \\
\\
a^{[l+2]} = g(z^{[l+2]} + a^{[l]})
\]
\(a^{[l]}\)直接隔层 与 下一层的线性输出相连,与 \(z^{[l+2]}\)共同通过激活函数 (Relu) 输出 \(a^{[l+2]}\).
由多个Residual block组成的神经网络就是Residual Network。
实验表明,这种模型结构对于 训练非常深的神经网络,效果很好。另外,为了便于区分,我们把 非Residual Networks称为 Plain Network。
Residual Network的结构如图所示:

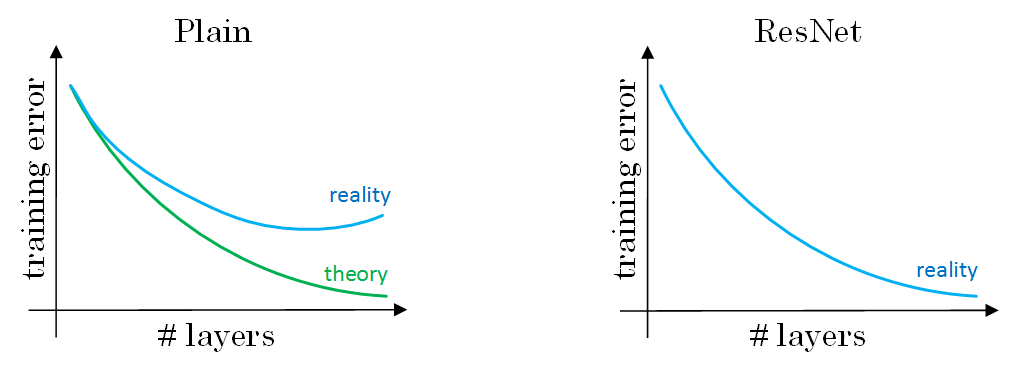
与Plain Network相比,Residual Network能够训练更深层的神经网络,有效避免发生发生梯度消失和梯度爆炸。
下图对比中可看出,随着神经网络层数增加,Plain Network实际性能会变差,training error甚至会变大。然而,Residual Network的训练效果却很好,training error一直呈下降趋势。
4. Why ResNets Work
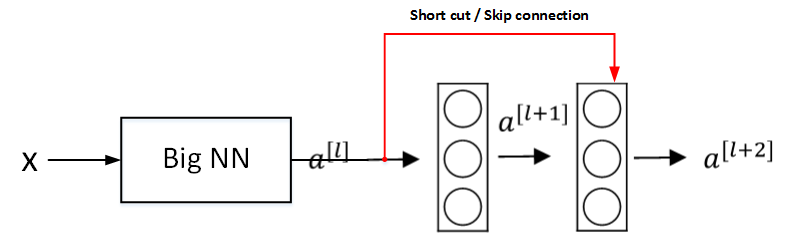
如图,输入 \(x\) 经过很多层神经网络后,输出 \(a^{[l]}\),\(a^{[l]}\)经过一个 Residual block 输出 \(a^{[l+2]}\)
\(a^{[l+2]}\) 表达式:
\]
- 输入x经过Big NN后, 若\(W^{[l+2]}\approx0\),\(b^{[l+2]}\approx0\),则有:
\]
即使发生梯度消失,\(W^{[l+2]}\approx0\),\(b^{[l+2]}\approx0\),\(a^{[l+2]}\)与\(a^{l]}\)之间也有线性关系。即:identity function
\(a^{[l]}\) 直接连到 \(a^{[l+2]}\),从效果来说,相当于直接忽略了\(a^{[l]}\) 之后的两层神经层.
看似很深的神经网络,其实由于许多Residual blocks的存在,弱化削减了某些神经层之间的联系,实现隔层线性传递,而不是一味追求非线性关系.
注意:
如果Residual blocks中 \(a^{[l]}\) 和 \(a^{[l+2]}\) 的维度不同,通常可以引入矩阵 \(W_s\),与 \(a^{[l]}\) 相乘,使得 \(W_s∗a^{[l]}\) 的维度与 \(a^{[l+2]}\)一致。
参数矩阵 \(W_s\) 有来两种方法得到:
一种是将 \(W_s\) 作为学习参数,通过模型训练得到.
一种是固定 \(W_s\) 值(类似单位矩阵),不需要训练,\(W_s\) 与 \(a^{[l]}\) 的乘积仅使得 \(a^{[l]}\) 截断或者补零。
如图,CNN中 ResNets 的结构:

ResNets同类型层之间,例如CONV layers,大多使用same类型,保持维度相同。
如果是不同类型层之间的连接,例如CONV layer与POOL layer之间,如果维度不同,则引入矩阵 \(W_s\) 。
5. Networks in Networks and 1x1 Convolutions
一种新的CNN结构,即1x1 Convolutions,也称Networks in Networks。
这种结构的特点:滤波器算子filter的维度为1x1。对于单个filter,1x1的维度,意味着卷积操作等同于乘积操作。
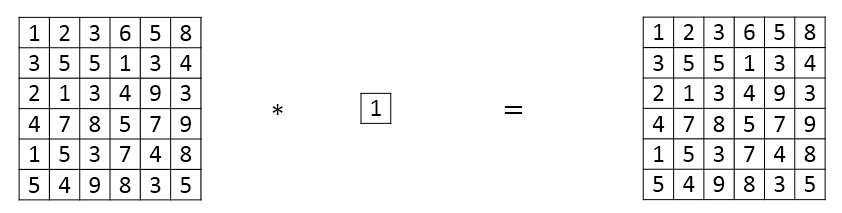
对于多个filters,1x1 Convolutions的作用类似 全连接层的神经网络结构。效果等同于Plain Network中 \(a^{[l]}\) 到 \(a^{[l+1]}\) 的过程。
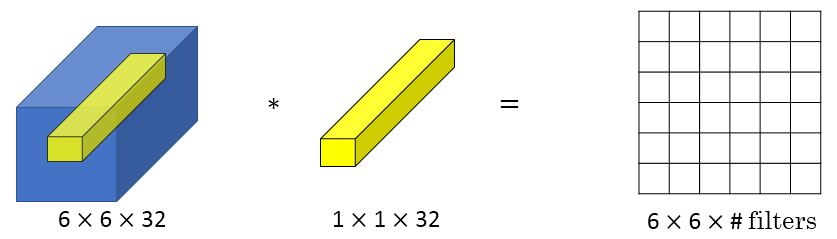
1x1 Convolutions可以用来 缩减输入图片的通道数目:
6. Inception Network Motivation
上面我们介绍的CNN单层的滤波算子filter尺寸是固定的,1x1或者3x3等。
Inception Network (初始网络)
在 单层网络 上可以 使用多个 不同尺寸的filters,进行same convolutions,把各filter下得到的输出拼接起来。
除此之外,还可以将CONV layer与POOL layer混合,同时实现各种效果。但是要注意使用same pool。
总结: Inception Network使用不同尺寸的filters,并将CONV和POOL混合起来,将所有功能输出组合拼接,再由神经网络本身去学习参数并选择最好的模块
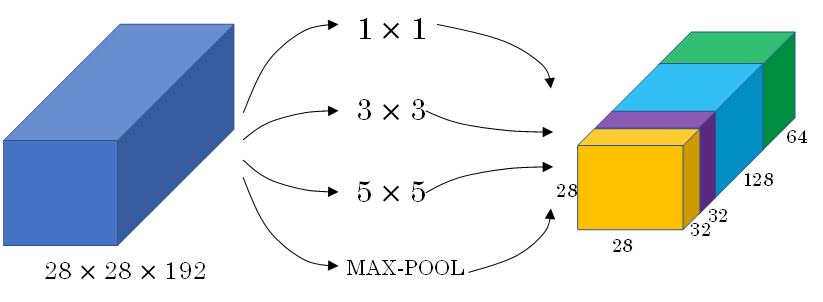
Inception Network在提升性能的同时,会带来计算量大的问题。例如:
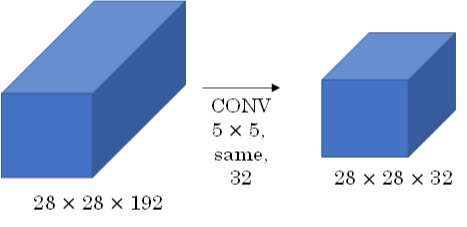
此CONV layer需要的计算量为:28x28x32x5x5x192=120m,其中m表示百万单位。
可以看出但这一层的计算量都是很大的。
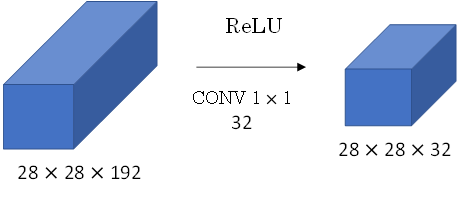
为此,我们可以引入1x1 Convolutions来减少其计算量,结构如下图所示:
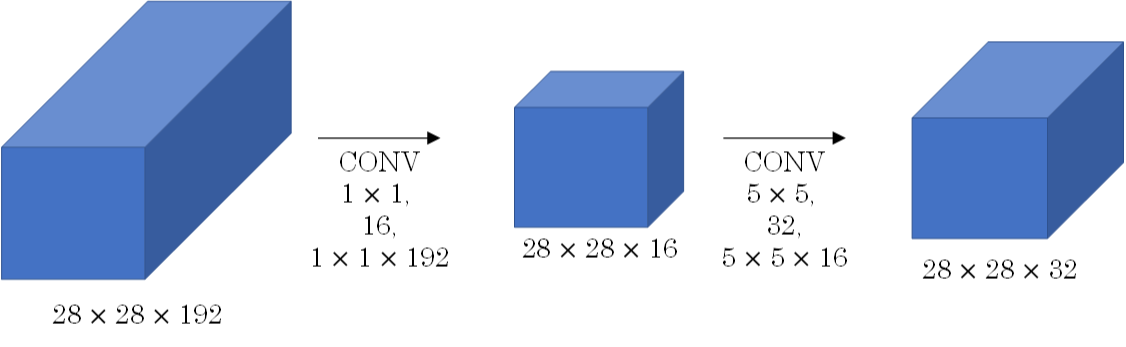
通常把该1x1 Convolution称为“瓶颈层”(bottleneck layer)。
引入bottleneck layer之后,总共需要的计算量为:28x28x16x192 + 28x28x32x5x5x16=12.4m。
明显地,虽然多引入了1x1 Convolution层,但是总共的计算量减少了近90%。由此可见,1x1 Convolutions还可以有效减少CONV layer的计算量。
7.Inception Network
引入1x1 Convolution后的Inception module如下图所示:
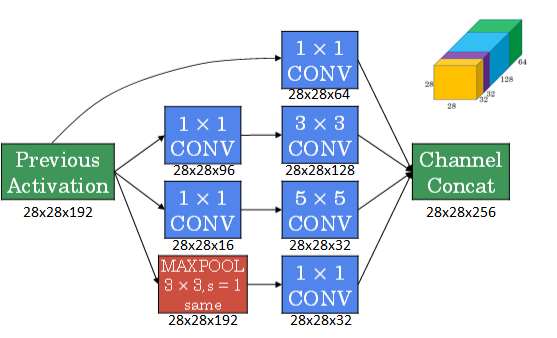
多个Inception modules组成Inception Network,效果如下图所示:
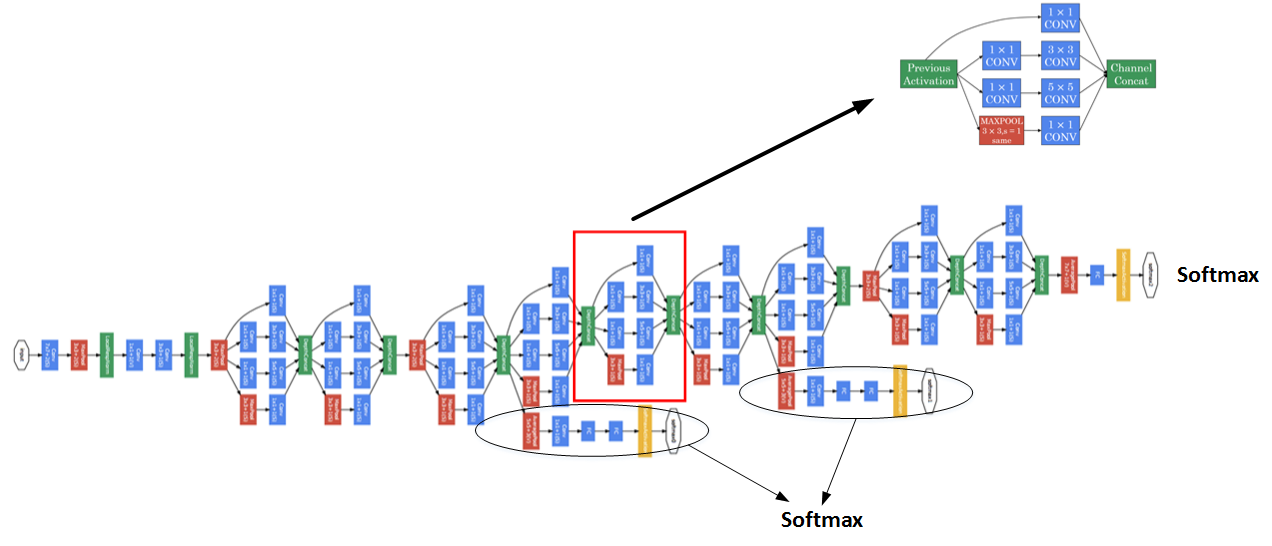
上述Inception Network除了由许多Inception modules组成之外,网络中间隐藏层也可以作为输出层Softmax,有利于防止发生过拟合。
8. Using Open-Source Implementation
略
9. Transfer Learning
略
10. Data Augmentation(数据增强)
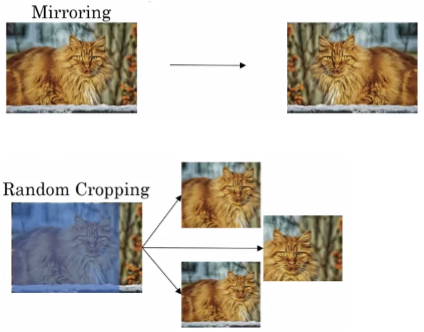
- 常用的Data Augmentation方法是对已有的样本集进行Mirroring和Random Cropping
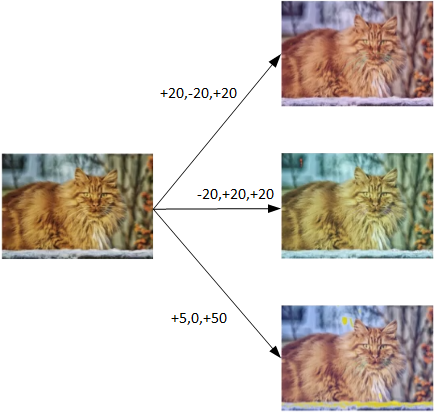
另一种Data Augmentation的方法是color shifting。
- color shifting就是对图片的RGB通道数值进行随意增加或者减少,改变图片色调。
11. State of Computer Vision
神经网络需要数据,不同的网络模型所需的数据量是不同的。
Object dection,Image recognition,Speech recognition所需的数据量依次增加。
- 如果data较少,那么就需要更多的hand-engineering,对已有data进行处理,比如上一节介绍的data augmentation

一些方法能够有助于提升神经网络模型的性能:(计算成本太大,不适用实际项目开发)
Ensembling: Train several networks independently and average their outputs.
Multi-crop at test time: Run classifier on multiple versions of test images and average results.
Coursera Deep Learning笔记 深度卷积网络的更多相关文章
- Coursera Deep Learning笔记 卷积神经网络基础
参考1 参考2 1. 计算机视觉 使用传统神经网络处理机器视觉的一个主要问题是输入层维度很大.例如一张64x64x3的图片,神经网络输入层的维度为12288. 如果图片尺寸较大,例如一张1000x10 ...
- Coursera Deep Learning笔记 逻辑回归典型的训练过程
Deep Learning 用逻辑回归训练图片的典型步骤. 笔记摘自:https://xienaoban.github.io/posts/59595.html 1. 处理数据 1.1 向量化(Vect ...
- Coursera Deep Learning笔记 改善深层神经网络:超参数调试 正则化以及梯度相关
笔记:Andrew Ng's Deeping Learning视频 参考:https://xienaoban.github.io/posts/41302.html 参考:https://blog.cs ...
- Coursera Deep Learning笔记 结构化机器学习项目 (下)
参考:https://blog.csdn.net/red_stone1/article/details/78600255https://blog.csdn.net/red_stone1/article ...
- Coursera Deep Learning笔记 改善深层神经网络:优化算法
笔记:Andrew Ng's Deeping Learning视频 摘抄:https://xienaoban.github.io/posts/58457.html 本章介绍了优化算法,让神经网络运行的 ...
- Coursera Deep Learning笔记 改善深层神经网络:超参数调试 Batch归一化 Softmax
摘抄:https://xienaoban.github.io/posts/2106.html 1. 调试(Tuning) 超参数 取值 #学习速率:\(\alpha\) Momentum:\(\bet ...
- Coursera Deep Learning笔记 序列模型(一)循环序列模型[RNN GRU LSTM]
参考1 参考2 参考3 1. 为什么选择序列模型 序列模型能够应用在许多领域,例如: 语音识别 音乐发生器 情感分类 DNA序列分析 机器翻译 视频动作识别 命名实体识别 这些序列模型都可以称作使用标 ...
- Coursera Deep Learning笔记 序列模型(二)NLP & Word Embeddings(自然语言处理与词嵌入)
参考 1. Word Representation 之前介绍用词汇表表示单词,使用one-hot 向量表示词,缺点:它使每个词孤立起来,使得算法对相关词的泛化能力不强. 从上图可以看出相似的单词分布距 ...
- Coursera Deep Learning笔记 序列模型(三)Sequence models & Attention mechanism(序列模型和注意力机制)
参考 1. 基础模型(Basic Model) Sequence to sequence模型(Seq2Seq) 从机器翻译到语音识别方面都有着广泛的应用. 举例: 该机器翻译问题,可以使用" ...
随机推荐
- MySQL(四)——
MySQL官方对索引的定义:索引(Index)是帮助MySQL高效获取数据的数据结构.因此索引的本质就是数据结构.索引的目的在于提高查询效率,可类比字典.书籍的目录等这种形式. 可简单理解为" ...
- JS_DOM操作之查找标签
1 - 直接查找标签 // 方式1:获取元素 document.getElementsByTagName("标签名") document.getElementById(" ...
- Appium自动化(5) - 如何获取android app 的Activity 和 Package
如果你还想从头学起Appium,可以看看这个系列的文章哦! https://www.cnblogs.com/poloyy/category/1693896.html 前言 在Desired Capab ...
- Git 系列教程(6)- 查看 commit 提交历史
查看提交历史 在提交了若干更新,又或者克隆了某个项目之后,如何查看提交历史 git log 官方栗子 运行下面的命令获取该项目: git clone https://github.com/scha 运 ...
- 我在组内的Nacos分享
本文已收录 https://github.com/lkxiaolou/lkxiaolou 欢迎star. Nacos简介 Nacos : Naming and Configuration Servic ...
- 批量ip段/子网转换
#coding=utf-8 import re import struct from sys import argv class CIDRHelper(object): def ipFormatChk ...
- java.lang.SecurityException: MODE_WORLD_READABLE错误解决
问题描述:运行Android项目有以下报错: 解决方法: 把 MODE_WORLD_READABLE 更换成 MODE_PRIVATE 即可,因为MODE_WORLD_READABLE 模式已经被废弃 ...
- python 小鸡飞行小游戏
python 小鸡飞行小游戏 用空格键控制小鸡飞行 代码 import pygame.freetype import sys import random pygame.init() screen = ...
- 我下载了python所有包,用以备份,有需要的自提
1.背景 我最近准备把1985年-2019年的全国30m分辨率土地利用数据按照地级市进行裁剪与归纳,这需要用到Geopandas对shp数据进行批量操作.在安装Geopandas的python包时,遇 ...
- oracle 基础SQL语句 增删改
一.SQL操作 查询已创建的数据库:SELECT datname FROM pg_database; 创建数据库:CREATE DATABASE wzxdb; 删除数据库:DROP DATABASE ...