分库分表利器之Sharding Sphere(深度好文,看过的人都说好)
Sharding-Sphere
Sharding-JDBC 最早是当当网内部使用的一款分库分表框架,到2017年的时候才开始对外开源,这几年在大量社区贡献者的不断迭代下,功能也逐渐完善,现已更名为 ShardingSphere,2020年4⽉16⽇正式成为 Apache 软件基⾦会的顶级项⽬。
随着版本的不断更迭 ShardingSphere 的核心功能也变得多元化起来。如图7-1,ShardingSphere生态包含三款开源分布式数据库中间件解决方案,Sharding-JDBC、Sharding-Proxy、Sharding-Sidecar。
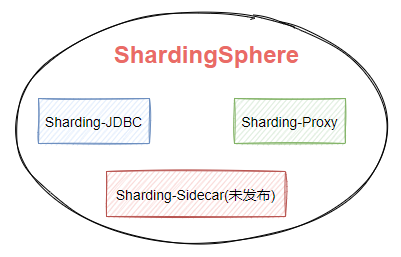
图7-1
Apache ShardingSphere 5.x 版本开始致力于提供可插拔架构,项目的功能组件能够灵活的以可插拔的方式进行扩展。 目前,数据分片、读写分离、数据加密、影子库压测等功能,以及对 MySQL、PostgreSQL、SQLServer、Oracle 等 SQL 与协议的支持,均通过插件的方式织入项目。 开发者能够像使用积木一样定制属于自己的独特系统。Apache ShardingSphere 目前已提供数十个 SPI 作为系统的扩展点,而且仍在不断增加中。
如图7-2,是Sharding-Sphere的整体架构。
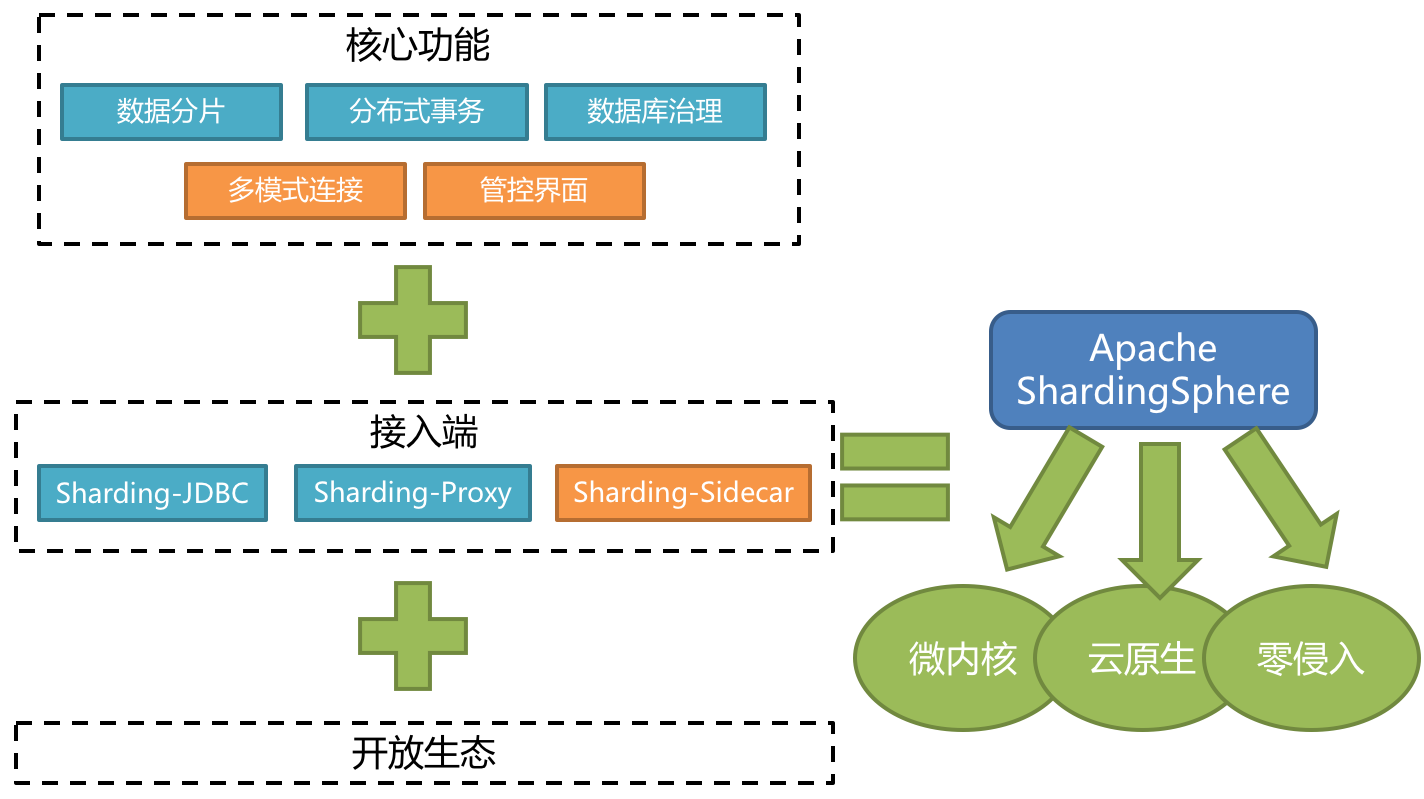
图7-2
Sharding-JDBC
Sharding-JDBC是比较常用的一个组件,它定位的是一个增强版的JDBC驱动,简单来说就是在应用端来完成数据库分库分表相关的路由和分片操作,也是我们本阶段重点去分析的组件。
我们在项目内引入Sharding-JDBC的依赖,我们的业务代码在操作数据库的时候,就会通过Sharding-JDBC的代码连接到数据库。也就是分库分表的一些核心动作,比如SQL解析,路由,执行,结果处理,都是由它来完成的,它工作在客户端。
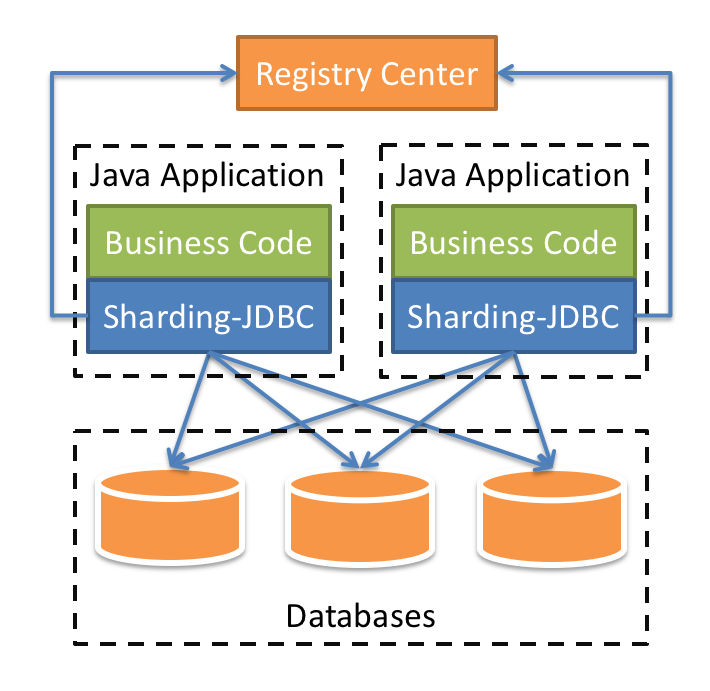
图7-3
Sharding-Proxy
Sharding-Proxy有点类似于Mycat,它是提供了数据库层面的代理,什么意思呢?简单来说,以前我们的应用是直连数据库,引入了Sharding-Proxy之后,我们的应用是直连Sharding-Proxy,然后Sharding-Proxy通过处理之后再转发到mysql中。
这种方式的好处在于,用户不需要感知到分库分表的存在,相当于正常访问mysql。目前Sharding-Proxy支持Mysql和PostgreSQL两种数据库协议,如图7-4所示。
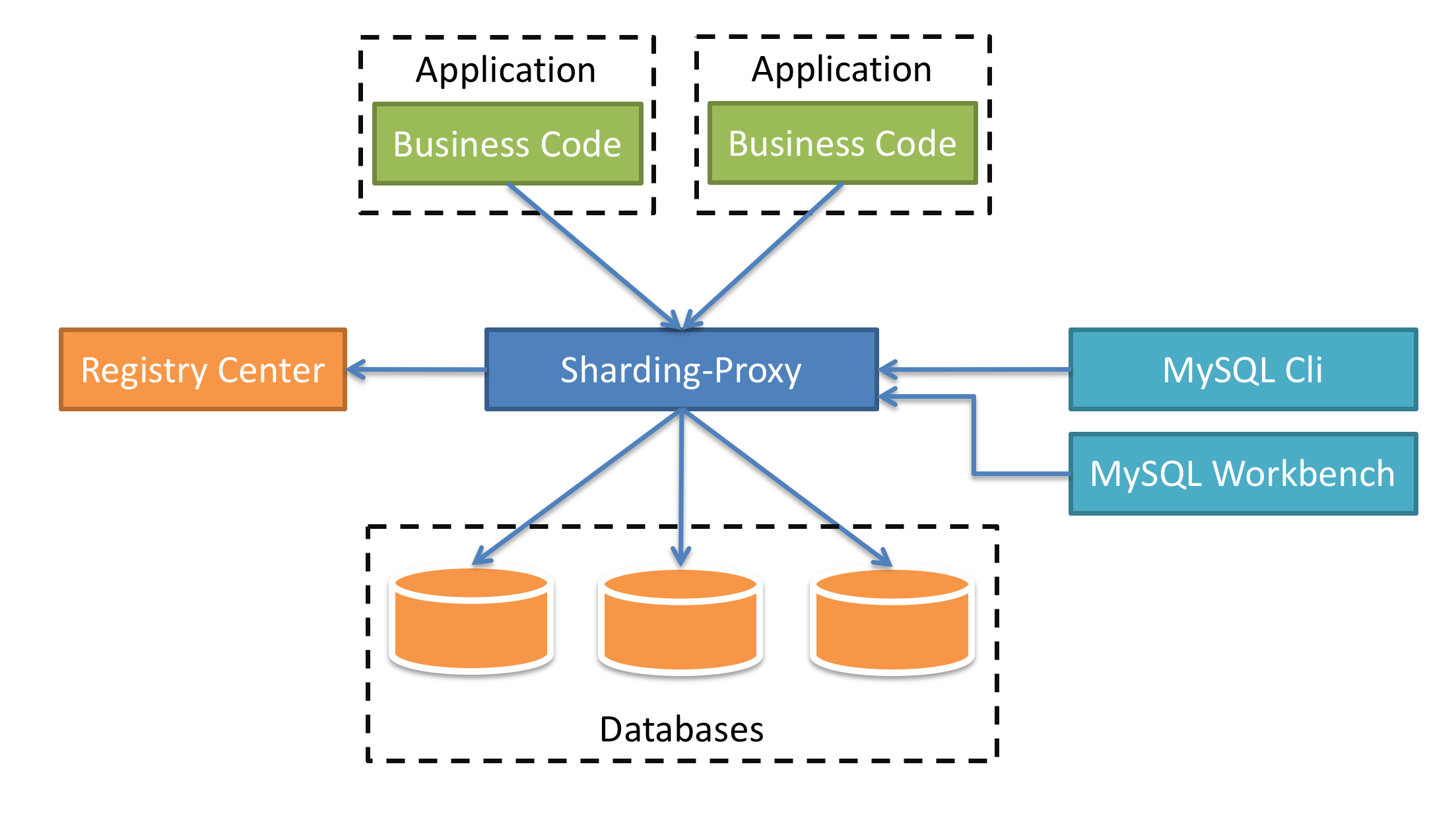
图7-4
Sharding-Sidecar(TODO)
看到Sidecar,大家应该就能想到服务网格架构,它主要定位于 Kubernetes 的云原生数据库代理,以 Sidecar 的形式代理所有对数据库的访问。目前Sharding-Sidecar还处于开发阶段未发布。
Sharding-JDBC
Sharding-JDBC是对原有JDBC驱动的增强,在分库分表的场景中,为应用提供了如图7-5所示的功能。

图7-5
Sharding-JDBC的整体架构
如图7-6所示,Java应用程序通过Sharding-JDBC驱动访问数据库,而在Sharding-JDBC中,它会根据相关配置完成分库分表路由、分布式事务等功能,所以我们可以认为它是对JDBC驱动的增强。
Registry Center表示注册中心,用来实现集中化分片配置规则管理、动态配置、以及数据源等信息。

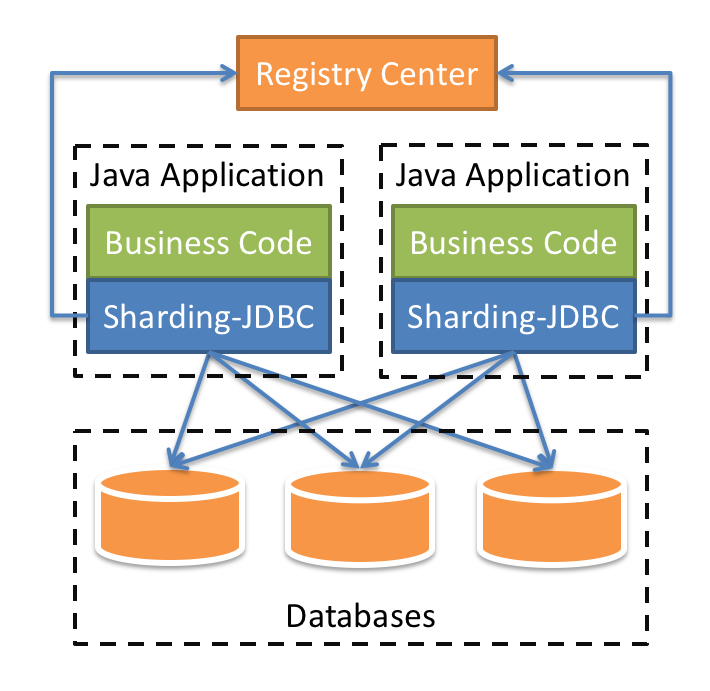{kind=link}
图7-6
Sharding-JDBC的基本使用
为了让大家更好的理解Shading-JDBC,我们通过一个案例来简单认识一下Sharding-JDBC。‘
https://shardingsphere.apache.org/document/current/cn/quick-start/shardingsphere-jdbc-quick-start/
为了更直观的理解Sharding-JDBC,下面通过一个原生的案例进行演示。
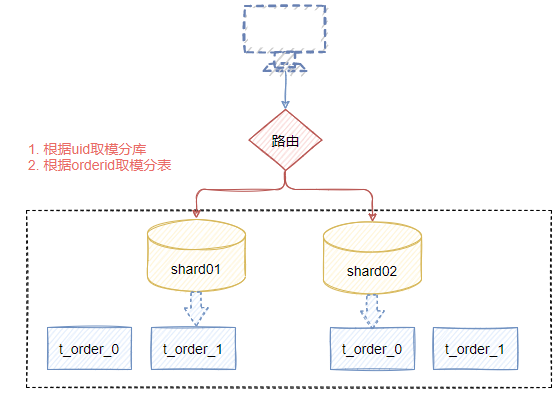
图7-7
图7-8表示整体项目结构。

引入Maven依赖
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core</artifactId>
<version>5.0.0-alpha</version>
</dependency>
<dependency>
<groupId>com.zaxxer</groupId>
<artifactId>HikariCP</artifactId>
<version>3.4.1</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
Order
定义Order表的实体对象。
@Data
public class Order implements Serializable {
private static final long serialVersionUID = 661434701950670670L;
private long orderId;
private int userId;
private long addressId;
private String status;
}
OrderReporitoryImpl
定义数据库操作层
public interface OrderRepository {
void createTableIfNotExists() throws SQLException;
Long insert(final Order order) throws SQLException;
}
public class OrderRepositoryImpl implements OrderRepository {
private final DataSource dataSource;
public OrderRepositoryImpl(final DataSource dataSource) {
this.dataSource = dataSource;
}
@Override
public void createTableIfNotExists() throws SQLException {
String sql = "CREATE TABLE IF NOT EXISTS t_order (order_id BIGINT NOT NULL AUTO_INCREMENT, user_id INT NOT NULL, address_id BIGINT NOT NULL, status VARCHAR(50), PRIMARY KEY (order_id))";
try (Connection connection = dataSource.getConnection();
Statement statement = connection.createStatement()) {
statement.executeUpdate(sql);
}
}
@Override
public Long insert(final Order order) throws SQLException {
String sql = "INSERT INTO t_order (user_id, address_id, status) VALUES (?, ?, ?)";
try (Connection connection = dataSource.getConnection();
PreparedStatement preparedStatement = connection.prepareStatement(sql, Statement.RETURN_GENERATED_KEYS)) {
preparedStatement.setInt(1, order.getUserId());
preparedStatement.setLong(2, order.getAddressId());
preparedStatement.setString(3, order.getStatus());
preparedStatement.executeUpdate();
try (ResultSet resultSet = preparedStatement.getGeneratedKeys()) {
if (resultSet.next()) {
order.setOrderId(resultSet.getLong(1));
}
}
}
return order.getOrderId();
}
}
OrderServiceImpl
定义数据库访问层
public interface ExampleService {
/**
* 初始化表结构
*
* @throws SQLException SQL exception
*/
void initEnvironment() throws SQLException;
/**
* 执行成功
*
* @throws SQLException SQL exception
*/
void processSuccess() throws SQLException;
}
public class OrderServiceImpl implements ExampleService {
private final OrderRepository orderRepository;
Random random=new Random();
public OrderServiceImpl(final DataSource dataSource) {
orderRepository=new OrderRepositoryImpl(dataSource);
}
@Override
public void initEnvironment() throws SQLException {
orderRepository.createTableIfNotExists();
}
@Override
public void processSuccess() throws SQLException {
System.out.println("-------------- Process Success Begin ---------------");
List<Long> orderIds = insertData();
System.out.println("-------------- Process Success Finish --------------");
}
private List<Long> insertData() throws SQLException {
System.out.println("---------------------------- Insert Data ----------------------------");
List<Long> result = new ArrayList<>(10);
for (int i = 1; i <= 10; i++) {
Order order = insertOrder(i);
result.add(order.getOrderId());
}
return result;
}
private Order insertOrder(final int i) throws SQLException {
Order order = new Order();
order.setUserId(random.nextInt(10000));
order.setAddressId(i);
order.setStatus("INSERT_TEST");
orderRepository.insert(order);
return order;
}
}
DataSourceUtil
public class DataSourceUtil {
private static final String HOST = "192.168.221.128";
private static final int PORT = 3306;
private static final String USER_NAME = "root";
private static final String PASSWORD = "123456";
public static DataSource createDataSource(final String dataSourceName) {
HikariDataSource result = new HikariDataSource();
result.setDriverClassName("com.mysql.jdbc.Driver");
result.setJdbcUrl(String.format("jdbc:mysql://%s:%s/%s?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8", HOST, PORT, dataSourceName));
result.setUsername(USER_NAME);
result.setPassword(PASSWORD);
return result;
}
}
Sharding-JDBC分片规则配置
public class ShardingDatabasesAndTableConfiguration {
//创建两个数据源
private static Map<String,DataSource> createDataSourceMap(){
Map<String, DataSource> dataSourceMap=new HashMap<>();
dataSourceMap.put("ds0",DataSourceUtil.createDataSource("shard01"));
dataSourceMap.put("ds1",DataSourceUtil.createDataSource("shard02"));
return dataSourceMap;
}
private static ShardingRuleConfiguration createShardingRuleConfiguration(){
ShardingRuleConfiguration configuration=new ShardingRuleConfiguration();
configuration.getTables().add(getOrderTableRuleConfiguration());
// configuration.getBindingTableGroups().add("t_order,t_order_item");
//
//
/**
* 设置数据库的分片规则
* inline表示行表达式分片算法,它使用groovy的表达式,支持单分片键,比如 t_user_$->{uid%8} 表示t_user表根据u_id%8分成8张表
*/
configuration.setDefaultDatabaseShardingStrategy(
new StandardShardingStrategyConfiguration("user_id","inline"));
/**
* 设置表的分片规则
*/
configuration.setDefaultTableShardingStrategy(new StandardShardingStrategyConfiguration("order_id","order_inline"));
Properties props=new Properties();
props.setProperty("algorithm-expression","ds${user_id%2}"); //表示根据user_id取模得到目标表
/**
* 定义具体的分片规则算法,用于提供分库分表的算法规则
*/
configuration.getShardingAlgorithms().put("inline",new ShardingSphereAlgorithmConfiguration("INLINE",props));
Properties properties=new Properties();
properties.setProperty("algorithm-expression","t_order_${order_id%2}");
configuration.getShardingAlgorithms().put("order_inline",new ShardingSphereAlgorithmConfiguration("INLINE",properties));
configuration.getKeyGenerators().put("snowflake",new ShardingSphereAlgorithmConfiguration("SNOWFLAKE",getProperties()));
return configuration;
}
private static Properties getProperties(){
Properties properties=new Properties();
properties.setProperty("worker-id","123");
return properties;
}
//创建订单表的分片规则
private static ShardingTableRuleConfiguration getOrderTableRuleConfiguration(){
ShardingTableRuleConfiguration tableRule=new ShardingTableRuleConfiguration("t_order","ds${0..1}.t_order_${0..1}");
tableRule.setKeyGenerateStrategy(new KeyGenerateStrategyConfiguration("order_id","snowflake"));
return tableRule;
}
public static DataSource getDataSource() throws SQLException {
return ShardingSphereDataSourceFactory.createDataSource(createDataSourceMap(), Collections.singleton(createShardingRuleConfiguration()),new Properties());
}
}
Main方法测试
public class ExampleMain {
public static void main(String[] args) throws SQLException {
DataSource dataSource=ShardingDatabasesAndTableConfiguration.getDataSource();
ExampleService exampleService=new OrderServiceImpl(dataSource);
exampleService.initEnvironment();
exampleService.processSuccess();
}
}
Sharding-JDBC使用总结
从上述的案例来看,Sharding-JDBC相当于通过配置化的方式帮我们提供了分片规则的配置,但是基于原生的使用方式,配置起来比较复杂,我们可以直接集成到Spring-Boot中,使用起来会比较简洁。
Spring Boot集成Sharding-JDBC分片实战
下面给大家演示一下在springboot应用中集成mybatis的情况下,如何实现分库分表的配置。
项目代码参考: sharding-jdbc-spring-boot-example,项目结构如图7-8所示。
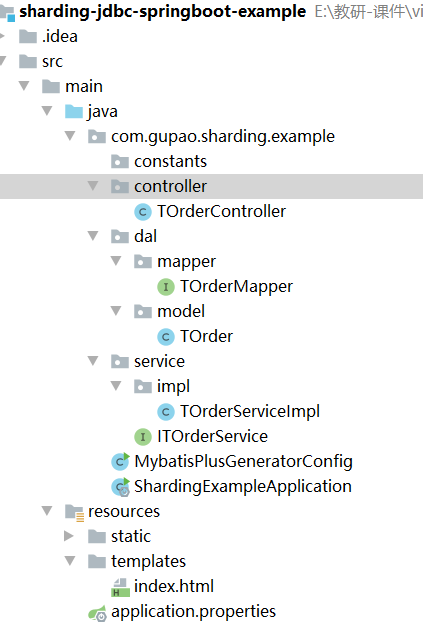
图7-8
其中,MybatisPlusGeneratorConfig,用来生成t_order表的dal、service、controller代码,由于代码是基于mybatis-plus生成,这里就不做过多描述了
引入pom依赖
<dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <scope>runtime</scope> </dependency> <dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus-boot-starter</artifactId> <version>3.4.3</version> </dependency> <dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus-generator</artifactId> <version>3.4.1</version> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>1.18.12</version> </dependency> <dependency> <groupId>org.apache.shardingsphere</groupId> <artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId> <version>5.0.0-alpha</version> </dependency> <dependency> <groupId>com.zaxxer</groupId> <artifactId>HikariCP</artifactId> <version>3.4.2</version> </dependency></dependencies>
application.properties配置
#配置数据源名称spring.shardingsphere.datasource.names=ds-0,ds-1spring.shardingsphere.datasource.common.type=com.zaxxer.hikari.HikariDataSourcespring.shardingsphere.datasource.common.driver-class-name=com.mysql.jdbc.Driver# 分别配置多个数据源的详细信息spring.shardingsphere.datasource.ds-0.username=rootspring.shardingsphere.datasource.ds-0.password=123456spring.shardingsphere.datasource.ds-0.jdbc-url=jdbc:mysql://192.168.221.128:3306/shard01?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8spring.shardingsphere.datasource.ds-1.username=rootspring.shardingsphere.datasource.ds-1.password=123456spring.shardingsphere.datasource.ds-1.jdbc-url=jdbc:mysql://192.168.221.128:3306/shard02?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8# 配置数据库的分库策略,其中database-inline会在后面声明spring.shardingsphere.rules.sharding.default-database-strategy.standard.sharding-column=user_idspring.shardingsphere.rules.sharding.default-database-strategy.standard.sharding-algorithm-name=database-inline# 配置t_order表的分表策略,其中t-order-inline会在后面声明# 行表达式标识符可以使用 ${...} 或 $->{...},但前者与 Spring 本身的属性文件占位符冲突,因此在 Spring 环境中使用行表达式标识符建议使用 $->{...}spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=ds-$->{0..1}.t_order_$->{0..1}spring.shardingsphere.rules.sharding.tables.t_order.table-strategy.standard.sharding-column=order_idspring.shardingsphere.rules.sharding.tables.t_order.table-strategy.standard.sharding-algorithm-name=t-order-inline# 配置order_id采用雪花算法生成全局id策略spring.shardingsphere.rules.sharding.tables.t_order.key-generate-strategy.column=order_idspring.shardingsphere.rules.sharding.tables.t_order.key-generate-strategy.key-generator-name=snowflake# 配置具体的分库分表规则spring.shardingsphere.rules.sharding.sharding-algorithms.database-inline.type=INLINEspring.shardingsphere.rules.sharding.sharding-algorithms.database-inline.props.algorithm-expression=ds-$->{user_id % 2}spring.shardingsphere.rules.sharding.sharding-algorithms.t-order-inline.type=INLINEspring.shardingsphere.rules.sharding.sharding-algorithms.t-order-inline.props.algorithm-expression=t_order_$->{order_id % 2}spring.shardingsphere.rules.sharding.sharding-algorithms.t-order-item-inline.type=INLINEspring.shardingsphere.rules.sharding.sharding-algorithms.t-order-item-inline.props.algorithm-expression=t_order_item_$->{order_id % 2}# 配置雪花算法spring.shardingsphere.rules.sharding.key-generators.snowflake.type=SNOWFLAKEspring.shardingsphere.rules.sharding.key-generators.snowflake.props.worker-id=123
增加逻辑代码
TOrderMapper
@Update("CREATE TABLE IF NOT EXISTS t_order (order_id BIGINT AUTO_INCREMENT, user_id INT NOT NULL, address_id BIGINT NOT NULL, status VARCHAR(50), PRIMARY KEY (order_id))")void createTableIfNotExists();
TOrderServiceImpl
@Servicepublic class TOrderServiceImpl extends ServiceImpl<TOrderMapper, TOrder> implements ITOrderService { @Autowired TOrderMapper orderMapper; Random random=new Random(); @Override public void initEnvironment() throws SQLException { orderMapper.createTableIfNotExists(); } @Override public void processSuccess() throws SQLException { System.out.println("-------------- Process Success Begin ---------------"); List<Long> orderIds = insertData(); System.out.println("-------------- Process Success Finish --------------"); } private List<Long> insertData() throws SQLException { System.out.println("---------------------------- Insert Data ----------------------------"); List<Long> result = new ArrayList<>(10); for (int i = 1; i <= 10; i++) { TOrder order = new TOrder(); order.setUserId(random.nextInt(10000)); order.setAddressId(i); order.setStatus("INSERT_TEST"); orderMapper.insert(order); result.add(order.getOrderId()); } return result; }}
TOrderController
提供测试接口。
@RestController@RequestMapping("/t-order")public class TOrderController { @Autowired ITOrderService orderService; @GetMapping public void init() throws SQLException { orderService.initEnvironment(); orderService.processSuccess(); }}
Sharding-JDBC的相关概念说明
前面我们通过两种方式演示了Sharding-JDBC的分库分表功能的用法,其实,从这个层面来说,Sharding-JDBC相当于增强了JDBC驱动的功能,使得开发者只需要通过配置就可以轻松完成分库分表功能的实现。
在Sharding-JDBC中,有一些表的概念,需要给大家普及一下,逻辑表、真实表、分片键、数据节点、动态表、广播表、绑定表。
逻辑表
逻辑表可以理解为数据库中的视图,是一张虚拟表。可以映射到一张物理表,也可以由多张物理表组成,这些物理表可以来自于不同的数据源。对于mysql, Hbase和ES,要组成一张逻辑表,只需要他们有相同含义的key即可。这个key在mysql中是主键,Hbase中是生成rowkey用的值,是ES中的key。
在前面的分库分表规则配置中,就有用到t_order这个逻辑表的定义,当我们针对t_order表操作时,会根据分片规则映射到实际的物理表进行相关事务操作,如图7-9所示,逻辑表会在SQL解析和路由时被替换成真实的表名。
spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=ds-$->{0..1}.t_order_$->{0..1}
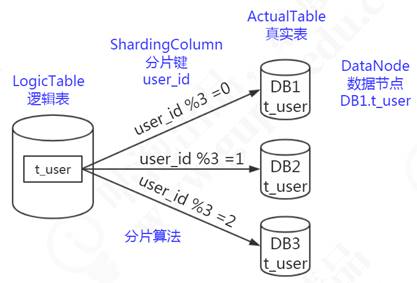
图7-9
广播表
广播表也叫全局表,也就是它会存在于多个库中冗余,避免跨库查询问题。
比如省份、字典等一些基础数据,为了避免分库分表后关联表查询这些基础数据存在跨库问题,所以可以把这些数据同步给每一个数据库节点,这个就叫广播表,如图7-10所示。
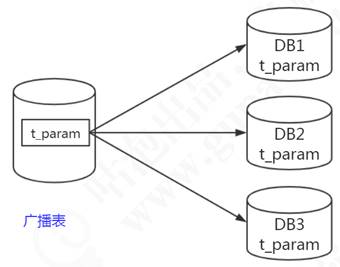
图7-10
在Sharding-JDBC中,配置方式如下
# 广播表, 其主节点是ds0spring.shardingsphere.sharding.broadcast-tables=t_configspring.shardingsphere.sharding.tables.t_config.actual-data-nodes=ds$->{0}.t_config
绑定表
我们有些表的数据是存在逻辑的主外键关系的,比如订单表order_info,存的是汇总的商品数,商品金额;订单明细表order_detail,是每个商品的价格,个数等等。或者叫做从属关系,父表和子表的关系。他们之间会经常有关联查询的操作,如果父表的数据和子表的数据分别存储在不同的数据库,跨库关联查询也比较麻烦。所以我们能不能把父表和数据和从属于父表的数据落到一个节点上呢?
比如order_id=1001的数据在node1,它所有的明细数据也放到node1;order_id=1002的数据在node2,它所有的明细数据都放到node2,这样在关联查询的时候依然是在一个数据库,如图7-11所示
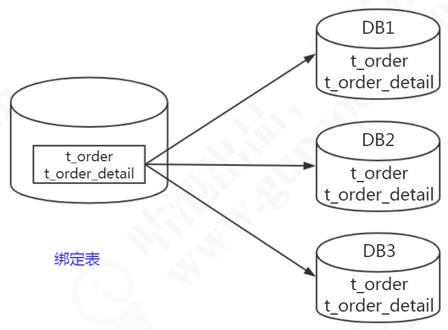
图7-11
# 绑定表规则,多组绑定规则使用数组形式配置spring.shardingsphere.rules.sharding.binding-tables=t_order,t_order_item
如果存在多个绑定表规则,可以用数组的方式声明
spring.shardingsphere.rules.sharding.binding-tables[0]= # 绑定表规则列表spring.shardingsphere.rules.sharding.binding-tables[1]= # 绑定表规则列表spring.shardingsphere.rules.sharding.binding-tables[x]= # 绑定表规则列表
Sharding-JDBC中的分片策略
Sharding-JDBC内置了很多常用的分片策略,这些算法主要针对两个维度
- 数据源分片
- 数据表分片
Sharding-JDBC的分片策略包含了分片键和分片算法;
- 分片键,用于分片的数据库字段,是将数据库(表)水平拆分的关键字段。例:将订单表中的订单主键的尾数取模分片,则订单主键为分片字段。 SQL中如果无分片字段,将执行全路由,性能较差。 除了对单分片字段的支持,ShardingSphere也支持根据多个字段进行分片。
- 分片算法,就是用来实现分片的计算规则。
Sharding-JDBC提供内置了多种分片算法,包含四种类型分别是
- 自动分片算法
- 标准分片算法
- 复合分片算法
- Hinit分片算法
自动分片算法
自动分片算法,就是根据我们配置的算法表达式完成数据的自动分发功能,在Sharding-JDBC中提供了五种自动分片算法
- 取模分片算法
- 哈希取模分片算法
- 基于分片容量的范围分片算法
- 基于分片边界的范围分片算法
- 自动时间段分片算法
取模分片算法
最基础的取模算法,它会根据分片字段的值和sharding-count进行取模运算,得到一个结果。
ModShardingAlgorithm
# database-mod是自定义字符串名字spring.shardingsphere.rules.sharding.default-database-strategy.standard.sharding-algorithm-name=database-mod# MOD表示取模算法类型spring.shardingsphere.rules.sharding.sharding-algorithms.database-mod.type=MOD# 表示分片数量spring.shardingsphere.rules.sharding.sharding-algorithms.database-mod.props.sharding-count=2
哈希取模分片算法
和取模算法相同,唯一的区别是针对分片键得到哈希值之后再取模
HashModShardingAlgorithm
# database-mod是自定义字符串名字spring.shardingsphere.rules.sharding.default-database-strategy.standard.sharding-algorithm-name=database-hash-modspring.shardingsphere.rules.sharding.sharding-algorithms.database-hash-mod.type=HASH_MODspring.shardingsphere.rules.sharding.sharding-algorithms.database-hash-mod.props.sharding-count=2
分片容量范围
分片容量范围,简单理解就是按照某个字段的数值范围进行分片,比如存在下面这样一个需求,怎么配置呢?
(0~199)保存到表0[200~399]保存到表1[400~599)保存到表2
参考7.2.3章节中的方式,构建一个t_order_colume_range表,使用mybatis-plus生成相关代码,如图7-12所示
图7-12
添加如下配置,通过spring.profiles.active=volumn-range来激活不同的配置信息。
server.port=8080spring.mvc.view.prefix=classpath:/templates/spring.mvc.view.suffix=.htmlspring.shardingsphere.datasource.names=ds-0spring.shardingsphere.datasource.common.type=com.zaxxer.hikari.HikariDataSourcespring.shardingsphere.datasource.common.driver-class-name=com.mysql.jdbc.Driverspring.shardingsphere.datasource.ds-0.username=rootspring.shardingsphere.datasource.ds-0.password=123456spring.shardingsphere.datasource.ds-0.jdbc-url=jdbc:mysql://192.168.221.128:3306/shard01?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8spring.shardingsphere.rules.sharding.tables.t_order_volume_range.actual-data-nodes=ds-0.t_order_volume_range_$->{0..2}spring.shardingsphere.rules.sharding.tables.t_order_volume_range.table-strategy.standard.sharding-column=user_idspring.shardingsphere.rules.sharding.tables.t_order_volume_range.table-strategy.standard.sharding-algorithm-name=t-order-volume-rangespring.shardingsphere.rules.sharding.tables.t_order_volume_range.key-generate-strategy.column=order_idspring.shardingsphere.rules.sharding.tables.t_order_volume_range.key-generate-strategy.key-generator-name=snowflakespring.shardingsphere.rules.sharding.sharding-algorithms.t-order-volume-range.type=VOLUME_RANGE#最小的范围,0-200spring.shardingsphere.rules.sharding.sharding-algorithms.t-order-volume-range.props.range-lower=200#最大的范围,600 ,如果超过600,会报错spring.shardingsphere.rules.sharding.sharding-algorithms.t-order-volume-range.props.range-upper=600# 表示每张表的容量为200spring.shardingsphere.rules.sharding.sharding-algorithms.t-order-volume-range.props.sharding-volume=200spring.shardingsphere.rules.sharding.key-generators.snowflake.type=SNOWFLAKEspring.shardingsphere.rules.sharding.key-generators.snowflake.props.worker-id=123
基于分片边界的范围分片算法
前面讲的分片容量范围分片,是一个均衡的分片方法,如果存在不均衡的场景,比如下面这种情况
(0~1000)保存到表0[1000~20000]保存到表1[20000~300000)保存到表2[300000~无穷大)保存到表3
我们就可以用到基于分片边界的范围分片算法来完成,配置方法如下
BoundaryBasedRangeShardingAlgorithm
# BOUNDARY_RANGE 表示分片算法类型spring.shardingsphere.rules.sharding.sharding-algorithms.t-order-boundary-range.type=BOUNDARY_RANGE# 分片的范围边界,多个范围边界以逗号分隔spring.shardingsphere.rules.sharding.sharding-algorithms.t-order-boundary-range.props.sharding-ranges=1000,20000,300000
自动时间段分片算法
IntervalShardingAlgorithm
根据时间段进行分片,如果想实现如下功能
(1970-01-01 23:59:59 ~ 2020-01-01 23:59:59) 表0[2020-01-01 23:59:59 ~ 2021-01-01 23:59:59) 表1[2021-01-01 23:59:59 ~ 2021-02-01 23:59:59) 表2[2022-01-01 23:59:59 ~ 2024-01-01 23:59:59) 表3
配置方法如下,表示从2010-01-01到2021-01-01这个时间区间内的数据,按照每一年划分一个表
spring.shardingsphere.rules.sharding.tables.t_order_volume_range.actual-data-nodes=ds-0.t_order_volume_range_$->{0..2}spring.shardingsphere.rules.sharding.tables.t_order_volume_range.table-strategy.standard.sharding-column=create_datespring.shardingsphere.rules.sharding.tables.t_order_volume_range.table-strategy.standard.sharding-algorithm-name=t-order-auto-intervalspring.shardingsphere.rules.sharding.tables.t_order_volume_range.key-generate-strategy.column=order_idspring.shardingsphere.rules.sharding.tables.t_order_volume_range.key-generate-strategy.key-generator-name=snowflakespring.shardingsphere.rules.sharding.sharding-algorithms.t-order-auto-interval.type=AUTO_INTERVAL# 分片的起始时间范围,时间戳格式:yyyy-MM-dd HH:mm:ssspring.shardingsphere.rules.sharding.sharding-algorithms.t-order-auto-interval.props.datetime-lower=2010-01-01 23:59:59# 分片的结束时间范围,时间戳格式:yyyy-MM-dd HH:mm:ssspring.shardingsphere.rules.sharding.sharding-algorithms.t-order-auto-interval.props.datetime-upper=2021-01-01 23:59:59# 单一分片所能承载的最大时间,单位:秒,下面的数字表示1年spring.shardingsphere.rules.sharding.sharding-algorithms.t-order-auto-interval.props.sharding-seconds='31536000'
需要注意,如果是基于时间段来分片,那么在查询的时候不能使用函数查询,否则会导致全路由。
select * from t_order where to_date(create,'yyyy-mm-dd')=''
标准分片算法
标准分片策略(StandardShardingStrategy),它只支持对单个分片健(字段)为依据的分库分表,Sharding-JDBC提供了两种算法实现
行表达式分片算法
类型:INLINE
使用 Groovy 的表达式,提供对 SQL 语句中的 = 和 IN 的分片操作支持,只支持单分片键。 对于简单的分片算法,可以通过简单的配置使用,从而避免繁琐的 Java 代码开发,如: t_user_$->{u_id % 8} 表示 t_user 表根据 u_id 模 8,而分成 8 张表,表名称为 t_user_0 到 t_user_7
配置方法如下。
spring.shardingsphere.rules.sharding.sharding-algorithms.database-inline.type=INLINEspring.shardingsphere.rules.sharding.sharding-algorithms.database-inline.props.algorithm-expression=ds-$->{user_id % 2}spring.shardingsphere.rules.sharding.sharding-algorithms.t-order-inline.type=INLINEspring.shardingsphere.rules.sharding.sharding-algorithms.t-order-inline.props.algorithm-expression=t_order_$->{order_id % 2}
时间范围分片算法
和前面自动分片算法的自动时间段分片算法类似。
类型:INTERVAL
可配置属性:
| 属性名称 | 数据类型 | 说明 | 默认值 |
|---|---|---|---|
| datetime-pattern | String | 分片键的时间戳格式,必须遵循 Java DateTimeFormatter 的格式。例如:yyyy-MM-dd HH:mm:ss | - |
| datetime-lower | String | 时间分片下界值,格式与 datetime-pattern 定义的时间戳格式一致 |
- |
| datetime-upper (?) | String | 时间分片上界值,格式与 datetime-pattern 定义的时间戳格式一致 |
当前时间 |
| sharding-suffix-pattern | String | 分片数据源或真实表的后缀格式,必须遵循 Java DateTimeFormatter 的格式,必须和 datetime-interval-unit 保持一致。例如:yyyyMM |
- |
| datetime-interval-amount (?) | int | 分片键时间间隔,超过该时间间隔将进入下一分片 | 1 |
| datetime-interval-unit (?) | String | 分片键时间间隔单位,必须遵循 Java ChronoUnit 的枚举值。例如:MONTHS |
复合分片算法
使用场景:SQL 语句中有>,>=, <=,<,=,IN 和 BETWEEN AND 等操作符,不同的是复合分片策略支持对多个分片健操作。
Sharding-JDBC内置了一种复合分片算法的实现。
类型: COMPLEX_INLINE,实现类:ComplexInlineShardingAlgorithm
| 属性名称 | 数据类型 | 说明 | 默认值 |
|---|---|---|---|
| sharding-columns (?) | String | 分片列名称,多个列用逗号分隔。如不配置无法则不能校验 | - |
| algorithm-expression | String | 分片算法的行表达式 | - |
| allow-range-query-with-inline-sharding (?) | boolean | 是否允许范围查询。注意:范围查询会无视分片策略,进行全路由 |
目前版本还未发布(在github仓库中已经提供了实现),如果要实现符合分片算法,需要自己手动实现。
自定义分片算法
除了默认提供了分片算法之外,我们可以根据实际需求自定义分片算法,Sharding-JDBC同样提供了几种类型的扩展实现
- 标准分片算法
- 复合分片算法
- Hinit分片策略
- 不分片策略
分片策略的接口定义如下,它有四个子类,分别对应上面四种分片策略,我们可以通过继承不同的分片策略完成自定义分片策略的扩展。
public interface ShardingStrategy { Collection<String> getShardingColumns(); ShardingAlgorithm getShardingAlgorithm(); Collection<String> doSharding(Collection<String> var1, Collection<ShardingConditionValue> var2, ConfigurationProperties var3);}

图7-13
自定义标准分片算法
public class StandardModTableShardAlgorithm implements StandardShardingAlgorithm<Long> { private Properties props=new Properties(); /** * 用于处理=和IN的分片。 * @param collection 表示目标分片的集合 * @param preciseShardingValue 逻辑表相关信息 * @return */ @Override public String doSharding(Collection<String> collection, PreciseShardingValue<Long> preciseShardingValue) { for(String name:collection){ //根据order_id的值进行取模,得到一个目标值 if(name.endsWith(String.valueOf(preciseShardingValue.getValue()%4))){ return name; } } throw new UnsupportedOperationException(); } /** * 用于处理BETWEEN AND分片,如果不配置RangeShardingAlgorithm,SQL中的BETWEEN AND将按照全库路由处理 * @param collection * @param rangeShardingValue * @return */ @Override public Collection<String> doSharding(Collection<String> collection, RangeShardingValue<Long> rangeShardingValue) { Collection<String> result=new LinkedHashSet<>(collection.size()); for(Long i=rangeShardingValue.getValueRange().lowerEndpoint();i<=rangeShardingValue.getValueRange().upperEndpoint();i++){ for(String name:collection){ if(name.endsWith(String.valueOf(i%4))){ result.add(name); } } } return result; } /** * 初始化对象的时候调用的方法 */ @Override public void init() { } /** * 对应分片算法(sharding-algorithms)的类型 * @return */ @Override public String getType() { return "STANDARD_MOD"; } @Override public Properties getProps() { return this.props; } /** * 获取分片相关属性 * @param properties */ @Override public void setProps(Properties properties) { this.props=properties; }}
通过SPI机制进行扩展
在resource目录下创建META-INF/service/org.apache.shardingsphere.sharding.spi.ShardingAlgorithm文件
把自定义标准分片算法的全路径写如到上述文件中
com.gupao.sharding.example.StandardModTableShardAlgorithm
增加application-custom-standard.properties文件
spring.shardingsphere.rules.sharding.tables.t_order_standard.actual-data-nodes=ds-0.t_order_standard_$->{0..3}spring.shardingsphere.rules.sharding.tables.t_order_standard.table-strategy.standard.sharding-column=order_idspring.shardingsphere.rules.sharding.tables.t_order_standard.table-strategy.standard.sharding-algorithm-name=standard-modspring.shardingsphere.rules.sharding.tables.t_order_standard.key-generate-strategy.column=order_idspring.shardingsphere.rules.sharding.tables.t_order_standard.key-generate-strategy.key-generator-name=snowflakespring.shardingsphere.rules.sharding.sharding-algorithms.standard-mod.type=STANDARD_MODspring.shardingsphere.rules.sharding.sharding-algorithms.standard-mod.props.algorithm-class-name=com.gupao.sharding.example.StandardModTableShardAlgorithm
其中,STANDARD_MOD是我们自定义的取模分片算法的类型。
表以及代码生成
把t_order表复制一张t_order_standard,通过mybatis-plus生成业务代码。
代码工程详见: sharding-jdbc-springboot-example
关于Java中的SPI机制
SPI 的全名为 Service Provider Interface,它的核心思想是中间件中定义标准,然后使用者可以在这个标准上实现自定义扩展,举个比较常见的例子,就是JDBC驱动。 Java官方只提供了JDBC驱动的接口
java.sql.Driver
然后各大数据库厂商,如Mysql、Oracle都会基于这个接口定义不同数据库的连接实现,然后使用java语言的开发者不需要关心不同数据库的具体配置,只需要集成相关的依赖包以及配置相关驱动,Java程序就能自动匹配到相关的实现完成数据库连接。
这种思想在很多地方都有使用,比如Spring中的SpringFactoriesLoader、Dubbo中的SPI思想、Sentinel中的SPI思想等等。很多中间件中使用的SPI都不是Java原生的SPI,而是基于这种思想优化过后的,后续我们会再讲到。
下面来看一下SPI如何使用
SPI的使用规则
SPI的使用如图7-14所示,必须遵循以下约定。
1、在工程的META-INF/services/目录下,以接口的全限定名作为文件名,文件内容为实现接口的服务类;
2、使用ServiceLoader动态加载META-INF/services下的实现类;
3、接口的实现类需含无参构造函数;(因为类默认包含无参构造函数,如果我们没有重载构造函数所以此处可忽略)
\07 ShardingSphere分库分表应用实战\07 ShardingSphere分库分表应用实战.assets\20180329110040213)
图7-14
SPI的使用实战
首先创建一个普通的maven项目,目录结构如下。

图7-15
Parser
public interface Parser { //解析文件方法 String parse(File file) throws Exception; //文件类型 String getType();}
定义如下两个实现类
public class JsonParser implements Parser { @Override public String parse(File file) throws Exception { return "我是Json格式解析"; } @Override public String getType() { return ParserConstant.JSON_PARSER; }}
public class XmlParser implements Parser { @Override public String parse(File file) throws Exception { return "我是XML格式解析"; } @Override public String getType() { return ParserConstant.XML_PARSER; }}
ParserConstant
public class ParserConstant { public final static String XML_PARSER="xml"; public final static String JSON_PARSER="json";}
ParserManager
定义一个解析管理器
public class ParserManager { private final static ConcurrentHashMap<String,Parser> registeredParsers = new ConcurrentHashMap<>(); static{ loadInitialParser(); //加载扩展实现 initDefaultStrategy(); //加载默认实现 } private static void loadInitialParser(){ ServiceLoader<Parser> parserServiceLoader=ServiceLoader.load(Parser.class); Iterator<Parser> iterator=parserServiceLoader.iterator(); while(iterator.hasNext()){ Parser parser=iterator.next(); registeredParsers.put(parser.getType(),parser); } } private static void initDefaultStrategy(){ Parser jsonParser=new JsonParser(); Parser xmlParser=new XmlParser(); registeredParsers.put(jsonParser.getType(),jsonParser); registeredParsers.put(xmlParser.getType(),xmlParser); } public static Parser getParser(String key){ return registeredParsers.get(key); }}
把上述项目打包 maven install到本地。
其他项目依赖Parser
上述项目打包之后安装到本地,在其他项目中,依赖上述项目
演示项目是: sharding-jdbc-springboot-example
- 依赖pom
<dependency> <groupId>org.example</groupId> <artifactId>file-parse-processor</artifactId> <version>1.0-SNAPSHOT</version></dependency>
- 定义扩展实现
public class TxtParser implements Parser { @Override public String parse(File file) throws Exception { return "txt文件解析结果"; } @Override public String getType() { return "txt"; }}
配置SPI扩展点
在resource目录下创建 META-INF/services/org.example.Parser
把自定义实现类写的全路径写入该文件中
com.gupao.sharding.example.TxtParser
定义controller进行测试
@RestControllerpublic class SPIController { @GetMapping("/spi") public String parser(){ try { return ParserManager.getParser("txt").parse(new File("")); } catch (Exception e) { return "异常"; } }}
通过url访问测试,可以发现ParserManager可以调用到我们自己扩展实现的解析器。
分布式序列算法
Sharding-JDBC中默认提供了两种分布式序列算法
- UUID
- 雪花算法
这两种在前面都说过,就不在重复说明。
分布式序列算法是为了保证水平分表之后,保证全局唯一性,关于雪花算法的定义如下。
类型:SNOWFLAKE
可配置属性:
| 属性名称 | 数据类型 | 说明 | 默认值 |
|---|---|---|---|
| worker-id (?) | long | 工作机器唯一标识 | 0 |
| max-vibration-offset (?) | int | 最大抖动上限值,范围[0, 4096)。注:若使用此算法生成值作分片值,建议配置此属性。此算法在不同毫秒内所生成的 key 取模 2^n (2^n一般为分库或分表数) 之后结果总为 0 或 1。为防止上述分片问题,建议将此属性值配置为 (2^n)-1 | 1 |
| max-tolerate-time-difference-milliseconds (?) | long | 最大容忍时钟回退时间,单位:毫秒 |
关注[跟着Mic学架构]公众号,获取更多精品原创

分库分表利器之Sharding Sphere(深度好文,看过的人都说好)的更多相关文章
- 分库分表后跨分片查询与Elastic Search
携程酒店订单Elastic Search实战:http://www.lvesu.com/blog/main/cms-610.html 为什么分库分表后不建议跨分片查询:https://www.jian ...
- 【大数据和云计算技术社区】分库分表技术演进&最佳实践笔记
1.需求背景 移动互联网时代,海量的用户每天产生海量的数量,这些海量数据远不是一张表能Hold住的.比如 用户表:支付宝8亿,微信10亿.CITIC对公140万,对私8700万. 订单表:美团每天几千 ...
- 分库分表技术演进&最佳实践
每个优秀的程序员和架构师都应该掌握分库分表,这是我的观点. 移动互联网时代,海量的用户每天产生海量的数量,比如: 用户表 订单表 交易流水表 以支付宝用户为例,8亿:微信用户更是10亿.订单表更夸张, ...
- (二)基于shard-jdbc中间件,实现数据分库分表
基于shard-jdbc中间件,实现数据分库分表 Sharding-JDBC简介 Sharding配置示意图 1.水平分割 1.1 水平分库 1.2 水平分表 2.Shard-jdbc中间件 2.1 ...
- 分库分表真的适合你的系统吗?聊聊分库分表和NewSQL如何选择
曾几何时,"并发高就分库,数据大就分表"已经成了处理 MySQL 数据增长问题的圣经. 面试官喜欢问,博主喜欢写,候选人也喜欢背,似乎已经形成了一个闭环. 但你有没有思考过,分库分 ...
- OneProxy分库分表演示--楼方鑫
OneProxy分库分表演示 (杭州平民软件有限公司) OneProxy是为MySQL精心设计的数据访问层,可以为任何开发语言提供对MySQL数据库的智能数据路由功能,比如单点切换.读写分离.分库分表 ...
- 使用TiDB把自己写分库分表方案推翻了
背景 在日益数据量增长的情况下,影响数据库的读写性能,我们一般会有分库分表的方案和使用newSql方案,newSql如TIDB.那么为什么需要使用TiDB呢?有什么情况下才用TiDB呢?解决传统分库分 ...
- Sharding Sphere的分库分表
什么是 ShardingSphere? 1.一套开源的分布式数据库中间件解决方案 2.有三个产品:Sharding-JDBC 和 Sharding-Proxy 3.定位为关系型数据库中间件,合理在分布 ...
- 数据库分库分表(sharding)系列(一) 拆分规则
第一部分:实施策略 数据库分库分表(sharding)实施策略图解 1. 垂直切分垂直切分的依据原则是:将业务紧密,表间关联密切的表划分在一起,例如同一模块的表.结合已经准备好的数据库ER图或领域模型 ...
随机推荐
- JDBC管理事务
一.事务概念:打包一起的多个步骤的业务操作,要么同事成功,要么同时失败,则需要用事务管理: 二.代码实现
- TCL、华星光电和中环股份,如何在一条生态链上领跑?
聚众智.汇众力.采众长. "我们决心用五年时间,将TCL科技和TCL实业做到真正的世界500强,将智能终端.半导体显示.半导体光伏三大核心产业力争做到全球领先,将半导体材料等其他产业做到中国 ...
- Django学习day04随堂笔记
每日测验 """ 今日考题 1.列举你知道的orm数据的增删改查方法 2.表关系如何判定,django orm中如何建立表关系,有什么特点和注意事项 3.请画出完整的dj ...
- PHP中比较数组的时候发生了什么?
首先还是从代码来看,我们通过比较运算符号来对两个数组进行比较: var_dump([1, 2] == [2, 1]); // false var_dump([1, 2, 3] > [3, 2, ...
- centos7.6,nginx1.18,php-7.4.6,mysql-5.7.30 安装
#1.下载,来自各官网 nginx-1.18.0.tar.gz php-7.4.6.tar.gz mysql-5.7.30-linux-glibc2.12-x86_64.tar.gz #下载到本地再传 ...
- 关于ModuleNotFoundError: No module named 'xxx' 模块导入失败问题
我在执行数据库迁移命令的时候pycharm报错,提示ModuleNotFoundError: No module named 'ckeditor',但是我确实是导进来了,而且这个包也从settings ...
- iNeuOS工业互联网操作系统部署在华为欧拉(openEuler)国产系统,vmware、openEuler、postgresql、netcore、nginx、ineuos一站式部署
目 录 1. 概述... 3 2. 创建虚拟机&安装华为欧拉(openEuler)系统... 4 2.1 创建新的虚拟机... 4 2.2 ...
- P4929-[模板]舞蹈链(DLX)
正题 题目链接:https://www.luogu.com.cn/problem/P4929 题目大意 \(n*m\)的矩形有\(0/1\),要求选出若干行使得每一列有且仅有一个\(1\). 解题思路 ...
- P6097-[模板]子集卷积
正题 题目链接:https://www.luogu.com.cn/problem/P6097 题目大意 长度为\(2^n\)的序列\(a,b\)求一个\(c\)满足 \[c_k=\sum_{i|j=k ...
- Python+selenium自动化生成测试报告
批量执行完用例后,生成的测试报告是文本形式的,不够直观,为了更好的展示测试报告,最好是生成HTML格式的. unittest里面是不能生成html格式报告的,需要导入一个第三方的模块:HTMLTest ...