ADAM : A METHOD FOR STOCHASTIC OPTIMIZATION
Kingma D P, Ba J. Adam: A Method for Stochastic Optimization[J]. arXiv: Learning, 2014.
@article{kingma2014adam:,
title={Adam: A Method for Stochastic Optimization},
author={Kingma, Diederik P and Ba, Jimmy},
journal={arXiv: Learning},
year={2014}}
概
鼎鼎大名.
主要内容
用\(f(\theta)\)表示目标函数, 随机最优通常需要最小化\(\mathbb{E}(f(\theta))\), 但是因为每一次我们都取的是一个小批次, 故实际上我们处理的是\(f_1(\theta),\ldots, f_T(\theta)\). 用\(g_t=\nabla_{\theta}f_t(\theta)\)表示第\(t\)步对应的梯度.
Adam 方法分别估计梯度\(\mathbb{E}(g_t)\)的一阶矩和二阶矩(Adam: adaptive moment estimation 名字的由来).
算法
注意: 下面的算法中关于向量的运算都是逐项(element-wise)的运算.

选择合适的参数
首先, 分析为什么会有
\hat{m}_t \leftarrow m_t / (1-\beta_2^t), \\
\hat{v}_t \leftarrow v_t / (1-\beta_2^t).
\]
可以用归纳法证明
m_t = (1-\beta_1) \sum_{i=1}^t \beta_1^{t-i} \cdot g_i \\
v_t = (1-\beta_2) \sum_{i=1}^t \beta_2^{t-i} \cdot g_i^2.
\]
倘若分布稳定: \(\mathbb{E}[g_t]=\mathbb{E}[g],\mathbb{E}[g_t^2]=\mathbb{E}[g^2]\), 则
\mathbb{E}[m_t]=\mathbb{E}[g] \cdot(1-\beta_1^t) \\
\mathbb{E}[v_t]= \mathbb{E}[g^2] \cdot (1- \beta_2^t).
\]
这就是为什么会有(A.1)这一步.
Adam提出时的一个很大的应用场景就是dropout(正对梯度是稀疏的情况), 这是往往需要我们取较大的\(\beta_2\)(可理解为抵消随机因素).
既然\(\mathbb{E}[g]/\sqrt{\mathbb{E}[g^2]}\le 1\), 我们可以把步长\(\alpha\)理解为一个信赖域(既然\(|\Delta_t| \frac{<}{\approx} a\)).
另外一个很重要的性质是, 比如函数扩大(或缩小)\(c\)倍\(cf\), 此时梯度相应为\(cg\), 我们所对应的
\]
并无变化.
一些别的优化算法
AdaGrad:
\]
RMSprop:
\theta_{t+1} = \theta_t -\alpha \cdot \frac{1}{\sqrt{v_t+\epsilon}}g_t.
\]
AdaDelta:
\theta_{t+1} = \theta_t -\alpha \cdot \frac{\sqrt{m_{t-1}+\epsilon}}{\sqrt{v_t+\epsilon}}g_t \\
m_t = \beta_1 m_{t-1}+(1-\beta_1)[\theta_{t+1}-\theta_t]^2.
\]
注: 均为逐项
AdaMax
本文还提出了另外一种算法


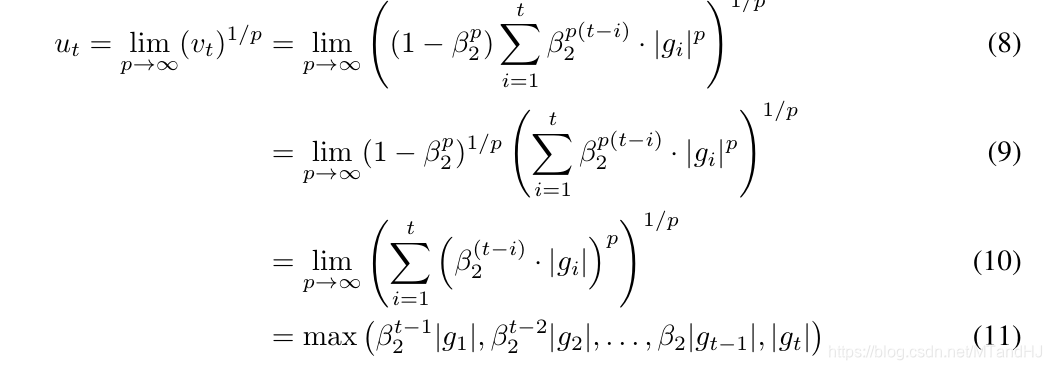

理论
不想谈了, 感觉证明有好多错误.
代码
import numpy as np
class Adam:
def __init__(self, instance, alpha=0.001, beta1=0.9, beta2=0.999,
epsilon=1e-8, beta_decay=1., alpha_decay=False):
""" the Adam using numpy
:param instance: the theta in paper, should have the grad method to call the grads
and the zero_grad method for clearing the grads
:param alpha: the same as the paper default:0.001
:param beta1: the same as the paper default:0.9
:param beta2: the same as the paper default:0.999
:param epsilon: the same as the paper default:1e-8
:param beta_decay:
:param alpha_decay: default False, if True, we will set alpha = alpha / sqrt(t)
"""
self.instance = instance
self.alpha = alpha
self.beta1 = beta1
self.beta2 = beta2
self.epsilon = epsilon
self.beta_decay = beta_decay
self.alpha_decay = alpha_decay
self.initialize_paras()
def initialize_paras(self):
self.m = 0.
self.v = 0.
self.timestep = 0
def update_paras(self):
grads = self.instance.grad
self.beta1 *= self.beta_decay
self.beta2 *= self.beta_decay
self.m = self.beta1 * self.m + (1 - self.beta1) * grads
self.v = self.beta2 * self.v + (1 - self.beta2) * grads ** 2
self.timestep += 1
if self.alpha_decay:
return self.alpha / np.sqrt(self.timestep)
return self.alpha
def zero_grad(self):
self.instance.zero_grad()
def step(self):
alpha = self.update_paras()
betat1 = 1 - self.beta1 ** self.timestep
betat2 = 1 - self.beta2 ** self.timestep
temp = alpha * np.sqrt(betat2) / betat1
self.instance.parameters -= temp * self.m / (np.sqrt(self.v) + self.epsilon)
class PPP:
def __init__(self, parameters, grad_func):
self.parameters = parameters
self.zero_grad()
self.grad_func = grad_func
def zero_grad(self):
self.grad = np.zeros_like(self.parameters)
def calc_grad(self):
self.grad += self.grad_func(self.parameters)
def f(x):
return x[0] ** 2 + 5 * x[1] ** 2
def grad(x):
return np.array([2 * x[0], 100 * x[1]])
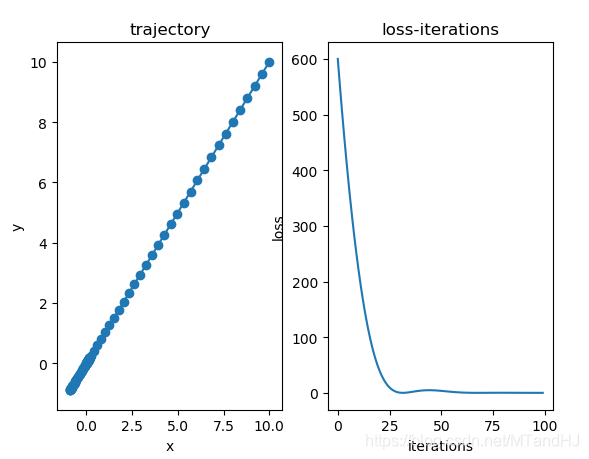
if __name__ == "__main__":
x = np.array([10., 10.])
x = PPP(x, grad)
xs = []
ys = []
optim = Adam(x, alpha=0.4)
for i in range(100):
xs.append(x.parameters.copy())
y = f(x.parameters)
ys.append(y)
optim.zero_grad()
x.calc_grad()
optim.step()
xs = np.array(xs)
ys = np.array(ys)
import matplotlib.pyplot as plt
fig, (ax0, ax1)= plt.subplots(1, 2)
ax0.plot(xs[:, 0], xs[:, 1])
ax0.scatter(xs[:, 0], xs[:, 1])
ax0.set(title="trajectory", xlabel="x", ylabel="y")
ax1.plot(np.arange(len(ys)), ys)
ax1.set(title="loss-iterations", xlabel="iterations", ylabel="loss")
plt.show()
ADAM : A METHOD FOR STOCHASTIC OPTIMIZATION的更多相关文章
- Stochastic Optimization Techniques
Stochastic Optimization Techniques Neural networks are often trained stochastically, i.e. using a me ...
- TensorFlow 深度学习笔记 Stochastic Optimization
Stochastic Optimization 转载请注明作者:梦里风林 Github工程地址:https://github.com/ahangchen/GDLnotes 欢迎star,有问题可以到I ...
- Stochastic Optimization of PCA with Capped MSG
目录 Problem Matrix Stochastic Gradient 算法(MSG) 步骤二(单次迭代) 单步SVD \(project()\)算法 \(rounding()\) 从这里回溯到此 ...
- (转) An overview of gradient descent optimization algorithms
An overview of gradient descent optimization algorithms Table of contents: Gradient descent variants ...
- PyTorch-Adam优化算法原理,公式,应用
概念:Adam 是一种可以替代传统随机梯度下降过程的一阶优化算法,它能基于训练数据迭代地更新神经网络权重.Adam 最开始是由 OpenAI 的 Diederik Kingma 和多伦多大学的 Jim ...
- An overview of gradient descent optimization algorithms
原文地址:An overview of gradient descent optimization algorithms An overview of gradient descent optimiz ...
- Adam优化算法
Question? Adam 算法是什么,它为优化深度学习模型带来了哪些优势? Adam 算法的原理机制是怎么样的,它与相关的 AdaGrad 和 RMSProp 方法有什么区别. Adam 算法应该 ...
- Adam 算法
简介 Adam 是一种可以替代传统随机梯度下降(SGD)过程的一阶优化算法,它能基于训练数据迭代地更新神经网络权重.Adam 最开始是由 OpenAI 的 Diederik Kingma 和多伦多大学 ...
- 从 SGD 到 Adam —— 深度学习优化算法概览(一) 重点
https://zhuanlan.zhihu.com/p/32626442 骆梁宸 paper插画师:poster设计师:oral slides制作人 445 人赞同了该文章 楔子 前些日在写计算数学 ...
随机推荐
- SparkStreaming消费Kafka,手动维护Offset到Mysql
目录 说明 整体逻辑 offset建表语句 代码实现 说明 当前处理只实现手动维护offset到mysql,只能保证数据不丢失,可能会重复 要想实现精准一次性,还需要将数据提交和offset提交维护在 ...
- Simulating final class in C++
Ever wondered how can you design a class in C++ which can't be inherited. Java and C# programming la ...
- Linux基础命令---ftp
ftp ftp指令可以用来登录远程ftp服务器. 此命令的适用范围:RedHat.RHEL.Ubuntu.CentOS.SUSE.openSUSE.Fedora. 1.语法 ftp [ ...
- 【Java多线程】CompletionService
什么是CompletionService? 当我们使用ExecutorService启动多个Callable时,每个Callable返回一个Future,而当我们执行Future的get方法获取结果时 ...
- Groovy获取Bean两种方式(奇淫技巧操作)
前言:请各大网友尊重本人原创知识分享,谨记本人博客:南国以南i 背景: 在Java代码中当我们需要一个Bean对象,通常会使用spring中@Autowired注解,用来自动装配对象. 在Groovy ...
- Springboot整合MongoDB(Eclipse版本)
IDEA版本其实也差不多的,大同小异 简单Demo地址: https://blog.csdn.net/shirukai/article/details/82152243 Springboot项目整合M ...
- Android: Client-Server communication
Refer to: http://osamashabrez.com/simple-client-server-communication-in-android/ I was working of an ...
- postgresql很强大,为何在中国,mysql成为主流?
你找一个能安装起来的数据库,都可以学,不管什么版本. 数据库的基本功,是那些基本概念(SQL,表,存储过程,索引,锁,连接配置等等),这些在任何一个版本中都是一样的. 目录 postgresql很强大 ...
- PMP变更流程
变更流程:
- 工期设定(Project)
<Project2016 企业项目管理实践>张会斌 董方好 编著 任务录入好以后,就得安排工期了不是,要不然每一个任务都如自动设置的从今天开始一个工作日内完成,这么简单的话,还要Proje ...