Mysql资料 数据类型
一.类型
整型
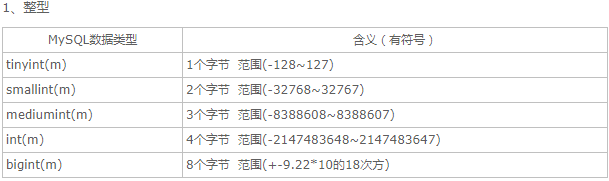
取值范围如果加了unsigned,则最大值翻倍,如tinyint unsigned的取值范围为(0~256)。
int(m)里的m是表示SELECT查询结果集中的显示宽度
浮点型

设一个字段定义为float(6,3),如果插入一个数123.45678,实际数据库里存的是123.457,但总个数还以实际为准,即6位。整数部分最大是3位,如果插入数12.123456,存储的是12.1234,如果插入12.12,存储的是12.1200.
定点数
浮点型在数据库中存放的是近似值,而定点类型在数据库中存放的是精确值。
decimal(m,d) 参数m<65 是总个数,d<30且 d<m 是小数位。
字符串
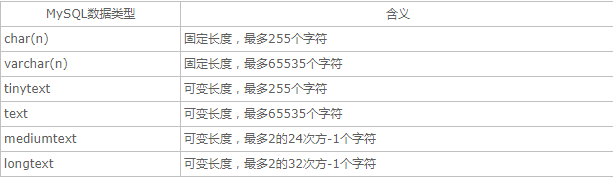
char和varchar:
1.char(n) 若存入字符数小于n,则以空格补于其后,查询之时再将空格去掉。所以char类型存储的字符串末尾不能有空格,varchar不限于此。
2.char(n) 固定长度,char(4)不管是存入几个字符,都将占用4个字节,varchar是存入的实际字符数+1个字节(n<=255)或2个字节(n>255),所以varchar(4),存入3个字符将占用4个字节。
3.char类型的字符串检索速度要比varchar类型的快。
varchar和text:
- varchar可指定n,text不能指定,内部存储varchar是存入的实际字符数+1个字节(n<=255)或2个字节(n>255),text是实际字符数+2个字节。
2,。text类型不能有默认值。
3.varchar可直接创建索引,text创建索引要指定前多少个字符。varchar查询速度快于text,在都创建索引的情况下,text的索引似乎不起作用。
二进制数据
1._BLOB和_text存储方式不同,_TEXT以文本方式存储,英文存储区分大小写,而_Blob是以二进制方式存储,不分大小写。
2._BLOB存储的数据只能整体读出。
3._TEXT可以指定字符集,_BLO不用指定字符集。
时间日期类型
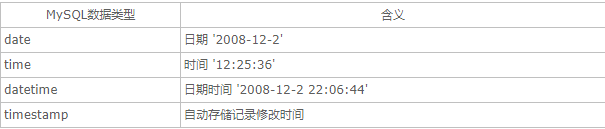
若定义一个字段为timestamp,这个字段里的时间数据会随其他字段修改的时候自动刷新,所以这个数据类型的字段可以存放这条记录最后被修改的时间。
二.长度和范围
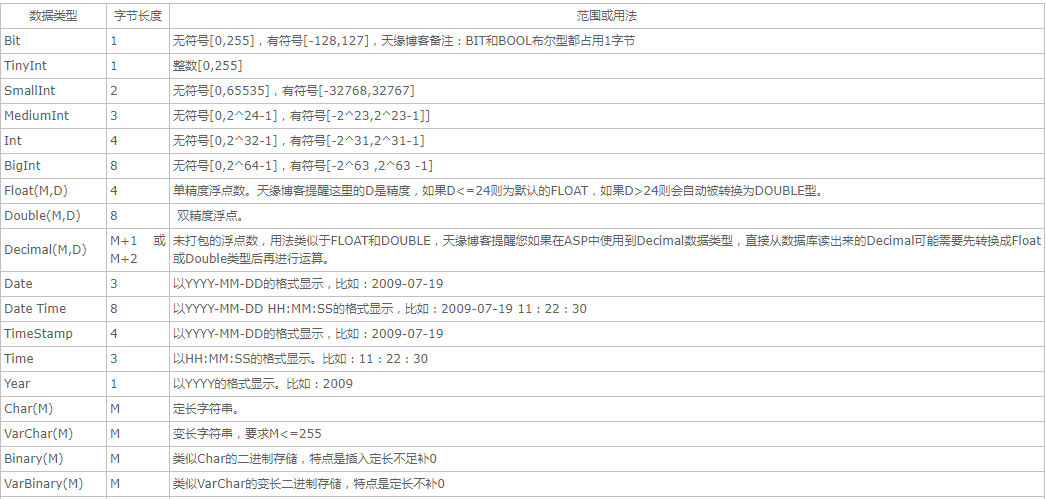

三.使用建议
原则
在指定数据类型的时候一般是采用从小原则,比如能用TINY INT的最好就不用INT,能用FLOAT类型的就不用DOUBLE类型,这样会对MYSQL在运行效率上提高很大,尤其是大数据量测试条件下。
不需要把数据表设计的太过复杂,功能模块上区分或许对于后期的维护更为方便,慎重出现大杂烩数据表
数据表和字段的起名字也是一门学问
设计数据表结构之前请先想象一下是你的房间,或许结果会更加合理、高效
数据库的最后设计结果一定是效率和可扩展性的折中,偏向任何一方都是欠妥的
存储引擎
根据选定的存储引擎,确定如何选择合适的数据类型。
- MyISAM 数据存储引擎和数据列:MyISAM数据表,最好使用固定长度(CHAR)的数据列代替可变长度(VARCHAR)的数据列。
- MEMORY存储引擎和数据列:MEMORY数据表目前都使用固定长度的数据行存储,因此无论使用CHAR或VARCHAR列都没有关系。两者都是作为CHAR类型处理的。
- InnoDB 存储引擎和数据列:建议使用 VARCHAR类型。
对于InnoDB数据表,内部的行存储格式没有区分固定长度和可变长度列(所有数据行都使用指向数据列值的头指针),因此在本质上,使用固定长度的CHAR列不一定比使用可变长度VARCHAR列简单。因而,主要的性能因素是数据行使用的存储总量。由于CHAR平均占用的空间多于VARCHAR,因 此使用VARCHAR来最小化需要处理的数据行的存储总量和磁盘I/O是比较好的。
下面说一下固定长度数据列与可变长度的数据列。
text和blob
在使用text和blob字段类型时要注意以下几点,以便更好的发挥数据库的性能。
BLOB和TEXT值也会引起自己的一些问题,特别是执行了大量的删除或更新操作的时候。删除这种值会在数据表中留下很大的"空洞",以后填入这些"空洞"的记录可能长度不同,为了提高性能,建议定期使用 OPTIMIZE TABLE 功能对这类表进行碎片整理.
使用合成的(synthetic)索引。合成的索引列在某些时候是有用的。一种办法是根据其它的列的内容建立一个散列值,并把这个值存储在单独的数据列中。接下来你就可以通过检索散列值找到数据行了。但是,我们要注意这种技术只能用于精确匹配的查询(散列值对于类似<或>=等范围搜索操作符 是没有用处的)。
我们可以使用MD5()函数生成散列值,也可以使用SHA1()或CRC32(),或者使用自己的应用程序逻辑来计算散列值。请记住数值型散列值可以很高效率地存储。同样,如果散列算法生成的字符串带有尾部空格,就不要把它们存储在CHAR或VARCHAR列中,它们会受到尾部空格去除的影响。
合成的散列索引对于那些BLOB或TEXT数据列特别有用。用散列标识符值查找的速度比搜索BLOB列本身的速度快很多。
在不必要的时候避免检索大型的BLOB或TEXT值。例如,SELECT *查询就不是很好的想法,除非你能够确定作为约束条件的WHERE子句只会找到所需要的数据行。否则,你可能毫无目的地在网络上传输大量的值。
这也是 BLOB或TEXT标识符信息存储在合成的索引列中对我们有所帮助的例子。你可以搜索索引列,决定那些需要的数据行,然后从合格的数据行中检索BLOB或 TEXT值。
把BLOB或TEXT列分离到单独的表中。在某些环境中,如果把这些数据列移动到第二张数据表中,可以让你把原数据表中 的数据列转换为固定长度的数据行格式,那么它就是有意义的。
这会减少主表中的碎片,使你得到固定长度数据行的性能优势。它还使你在主数据表上运行 SELECT *查询的时候不会通过网络传输大量的BLOB或TEXT值。
浮点数和定点数
在mysql中float、double(或real)是浮点数,decimal(或numberic)是定点数。
浮点数相对于定点数的优点是在长度一定的情况下,浮点数能够表示更大的数据范围;它的缺点是会引起精度问题。在今后关于浮点数和定点数的应用中,大家要记住以下几点:
浮点数存在误差问题;
- 对货币等对精度敏感的数据,应该用定点数表示或存储;
- 编程中,如果用到浮点数,要特别注意误差问题,并尽量避免做浮点数比较;
- 要注意浮点数中一些特殊值的处理。
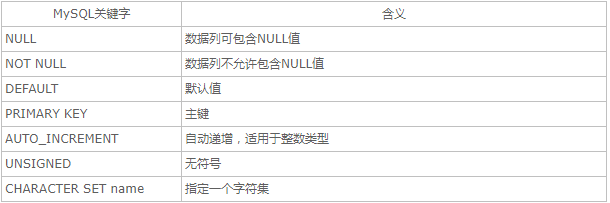
四.属性
Mysql资料 数据类型的更多相关文章
- MySQL数据库3 - MySQL常用数据类型
一. MySql常用数据类型 数据类型:整数(tinyint smailint int bigint) 定点数 decimal(p,s) ------ 小数点位置固定的 ---> 数 ...
- Mysql常用数据类型
Mysql常用数据类型 数字: 字符串: 时间:
- MySQL日期数据类型、时间类型使用总结
MySQL日期数据类型.时间类型使用总结 MySQL日期数据类型.MySQL时间类型使用总结,需要的朋友可以参考下. MySQL 日期类型:日期格式.所占存储空间.日期范围 比较. 日期类型 ...
- MySQL日期数据类型、MySQL时间类型使用总结
MySQL:MySQL日期数据类型.MySQL时间类型使用总结 MySQL 日期类型:日期格式.所占存储空间.日期范围 比较. 日期类型 存储空间 日期格式 日期范围 ------------ --- ...
- MySQL数据库数据类型之集合类型SET测试总结
MySQL数据库提供针对字符串存储的一种特殊数据类型:集合类型SET,这种数据类型可以给予我们更多提高性能.降低存储容量和降低程序代码理解的技巧,前面介绍了首先介绍了四种数据类型的特性总结,其后又分别 ...
- mysql 的数据类型
mysql 的数据类型(描述的是字段)三大类:一.整型:1.tinyint(M),其中M是显示宽度,需要配合zerofill,就是前面0填充,存储单位为1个字节(8位),无符文是最大能存储范围0000 ...
- MySQL的数据类型(转)
MySQL的数据类型 1.整数 TINYINT: 8 bit 存储空间 SMALLINT: 16 bit 存储空间 MEDIUMINT: 24 bit 存储空间 INT: 32 bit 存储空间 BI ...
- mysql之数据类型
一.概述: 所谓建表,就是声明列的过程: 数据是以文件的形式放在硬盘中(也有放在内存里的) 列:不同的列类型占的空间不一样 选列的原则:够用又不浪费: 二.mysql的数据类型: 整形:Tinyin ...
- MySQL/MariaDB数据类型
1.为什么要定义MySQL数据类型 定义MySQL数据类型其实就是为了对数据进行分类,实现对不同的分类进行不同的处理 1.使系统能够根据数据类型来操作数据. 2.预防数据运算时出错.例如,通过强大的数 ...
随机推荐
- Pycharm下载安装详细教程
目录 1.Pycharm 简介 2.Pycharm下载 3.环境变量的配置 4.Pycharm的使用 1.Pycharm 简介 PyCharm是一种Python IDE(Integrated Deve ...
- Excel 读取写入数据库
// Excel 读取写入数据库 // 3.8版本的poi 4.0 可以不用写 parseCell 这个方法,可以直接赋值 STRING 类型 import org.apache.poi.hss ...
- 常用的Dos(Win+R)命令
打开CMD的方式 开始 + 系统 + 命令提示符 win + R --> 输入CMD 管理员方式运行:开始-->windows系统-->右击命令提示符-->管理员身份运行(最高 ...
- [cf566C]Logistical Questions
记$d(x,y)$为$x$到$y$的距离,$cost_{x}=\sum_{i=1}^{n}w_{i}d(x,i)^{\frac{3}{2}}$为$x$的代价 取$C$为足够大量,对于一条边权为$w$的 ...
- 【GitHub】本地代码上传
本地代码上传GitHub 2019-11-18 20:03:45 by冲冲 1.注册GitHub https://github.com/ 2.安装Git工具 https://git-for-win ...
- Codeforces 1236F - Alice and the Cactus(期望+分类讨论)
Codeforces 题面传送门 & 洛谷题面传送门 期望好题. 首先拆方差: \[\begin{aligned} &E((x-E(x))^2)\\ =&E(x^2)-2E(x ...
- mount 挂载详解
挂接命令(mount) 首先,介绍一下挂接(mount)命令的使用方法,mount命令参数非常多,这里主要讲一下今天我们要用到的. 命令格式:mount [-t vfstype] [-o option ...
- sigma网格中水平压力梯度误差及其修正
1.水平梯度误差产生 sigma坐标系下,笛卡尔坐标内水平梯度项对应形式为 \[\begin{equation} \left. \frac{\partial }{\partial x} \right| ...
- 【宏基因组】MEGAN4,MEGAN5和MEGAN6的Linux安装和使用
MEGAN(Metagenome Analyzer)是宏基因组学进行物种和功能研究的常用软件,实际上现在的Diamond+MEGAN6已经是一套比较完整的物种和功能注释流程了. 但是由于各种原因,我们 ...
- C7的开机自启动设置
CentOS 7的服务systemctl脚本存放在:/usr/lib/systemd/,有系统(system)和用户(user)之分 系统服务放在/usr/lib/systemd/system [Un ...