solr配置相关:约束文件及引入ik分词器
schema.xml: solr约束文件
Solr中会提前对文档中的字段进行定义,并且在schema.xml中对这些字段的属性进行约束,例如:字段数据类型、字段是否索引、是否存储、是否分词等等
<!--第一种标签为 field标签: 主要是用来指定字段名称的, Lucene中是有用户在程序中指定, solr中需要提前在配置文件中指定-->
<field name="text" type="text_general" indexed="true" stored="false" multiValued="true"/>
<!--name: 字段的名称
type: 字段的类型
indexed: 是否索引
stored: 是否保存
multiValued: 是否多值, 这个字段, 类似存储一个数组
这里有两个不允许删除的: 一个是 _version__ 一个是 _root__ 这两个是solr内部需要使用的字段 有一个字段的名称必须为id,其类型都不允许进行修改 原因是id字段已经被主键使用uniqueKey
其余的是一些初始化好的字段
-->
<!--第二种标签为dynamicField, 被称为是动态域 -->
<dynamicField name="*_is" type="int" indexed="true" stored="true" multiValued="true"/>
<!--此种标签是为程序的扩展所使用的, 因为我们不可能把所有的字段全部定义好, 所以就需要动态域来进行动态扩展--> <!--第三种标签为 uniqueKey: 必要标签, 表名文档的唯一属性, 一般默认为id-->
<uniqueKey>id</uniqueKey>
<!--Lucene中是自己进行维护, solr中, 需要自己指定--> <!--第四种标签为 copyField: 被称为是复制域-->
<copyField source="cat" dest="text"/>
<!--source: 表名要复制那个字段的值
dest: 复制到那个字段上 此种标签主要是为了查询所使用的,
例如, 当查询Text字段的时候, 实质上相当于查询title和name两个字段--> <!--第五种标签: fieldType 字段类型定义标签-->
<fieldType name="managed_en" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.ManagedStopFilterFactory" managed="english" />
<filter class="solr.ManagedSynonymFilterFactory" managed="english" />
</analyzer>
</fieldType> <!--此种标签是用来定义字段的类型的,可以指定此字段使用何种分词器进行分词-->
引入ik分词器
第一步: 导入ik相关的依赖包
将三个文件放置在tomcat>webapps>solr>WEB-INF>lib下(此步骤在部署solr到tomcat中的时候, 就已经导入了)

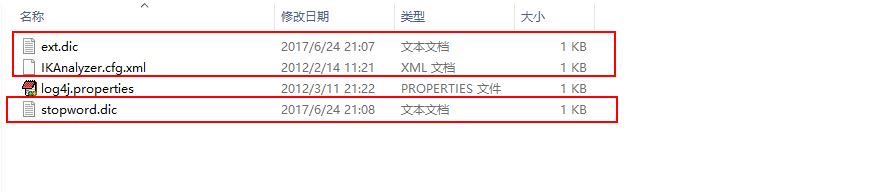
第二步: 导入ik相关的配置文件(ik配置文件, 扩展词典和停止词典)
将三个文件放置在tomcat>webapps>solr>WEB-INF>classes下(此步骤, 在部署solr到tomcat中的时候, 已经导入)
第三步, 在schema.xml配置文件中自定义一个字段类型, 引入ik分词器
<fieldType name="text_ik" class="solr.TextField">
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>

第四步: 为对应的字段设置为text_ik类型即可
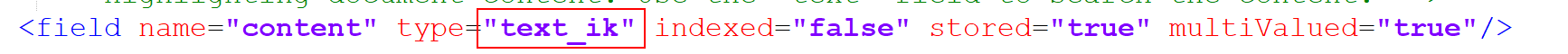
最终的配置文件:schema.xml
<?xml version="1.0" encoding="UTF-8" ?> <schema name="example" version="1.5"> <!-- 不删除
-->
<field name="_version_" type="long" indexed="true" stored="true"/>
<field name="_root_" type="string" indexed="true" stored="false"/> <!--不删除
id: 文档的唯一标识
在lucene中文档唯一的id是lucene自己维护的,, 在solr中,需要程序员自己维护
id字段了的设置内容, 尽量的不要动
-->
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<!--
field: 用来定义字段的
name: 字段的名称
type: 字段类型
indexed: 是否分词
stored: 是否保存
multiValued: 是否是多值(当前的这个字段可以是一个数组)
-->
<field name="name" type="text_ik" indexed="true" stored="true"/> <field name="title" type="text_ik" indexed="true" stored="true" /> <field name="content" type="text_ik" indexed="true" stored="true" /> <!--此字段主要用来做查询使用的-->
<field name="text" type="text_ik" indexed="true" stored="false" multiValued="true"/>
<!--
dynamicField: 动态域
为了程序的扩展使用的, 因为有时候无法在配置文件中将所以的字段全部定义了
对于solr来讲, 提供了动态域, 只需要用户在添加索引的时候字段名称的后缀名和动态域的名称一致就可以
-->
<dynamicField name="*_c" type="text_ik" indexed="true" stored="true"/> <!-- Field to use to determine and enforce document uniqueness.
Unless this field is marked with required="false", it will be a required field
-->
<!--
uniqueKey: 文档的唯一标识的字段是谁
-->
<uniqueKey>id</uniqueKey> <!--
copyField: 复制域
source: 来源字段
dest: 目标字段
复制域的作用是用来做查询的, 将其他几个字段的值全部的复制到目标字段中
当进行查询的时候, 如果查询的是text字段, 相当于查询了cat和name字段了
-->
<copyField source="content" dest="text"/>
<copyField source="name" dest="text"/> <!--
fieldType: 字段的类型
name: 类型的名称
class: 类型原生的类
在这个标签中, 可以用来规定资格字段类型的分词效果
可以通过这个标签设置新的字段类型,例如 ik分词器
-->
<fieldType name="string" class="solr.StrField" sortMissingLast="true" />
<!-- boolean type: "true" or "false" -->
<fieldType name="boolean" class="solr.BoolField" sortMissingLast="true"/> <fieldType name="int" class="solr.TrieIntField" precisionStep="0" positionIncrementGap="0"/>
<fieldType name="float" class="solr.TrieFloatField" precisionStep="0" positionIncrementGap="0"/>
<fieldType name="long" class="solr.TrieLongField" precisionStep="0" positionIncrementGap="0"/>
<fieldType name="double" class="solr.TrieDoubleField" precisionStep="0" positionIncrementGap="0"/>
<!--ik分词器配置-->
<fieldType name="text_ik" class="solr.TextField">
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType> </schema>
solr配置相关:约束文件及引入ik分词器的更多相关文章
- [Linux]Linux下安装和配置solr/tomcat/IK分词器 详细实例二.
为了更好的排版, 所以将IK分词器的安装重启了一篇博文, 大家可以接上solr的安装一同查看.[Linux]Linux下安装和配置solr/tomcat/IK分词器 详细实例一: http://ww ...
- Lucene介绍及简单入门案例(集成ik分词器)
介绍 Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和 ...
- IK分词器 整合solr4.7 含同义词、切分词、停止词
转载请注明出处! IK分词器如果配置成 <fieldType name="text_ik" class="solr.TextField"> < ...
- Solr 06 - Solr中配置使用IK分词器 (配置schema.xml)
目录 1 配置中文分词器 1.1 准备IK中文分词器 1.2 配置schema.xml文件 1.3 重启Tomcat并测试 2 配置业务域 2.1 准备商品数据 2.2 配置商品业务域 2.3 配置s ...
- solr添加中文IK分词器,以及配置自定义词库
Solr是一个基于Lucene的Java搜索引擎服务器.Solr 提供了层面搜索.命中醒目显示并且支持多种输出格式(包括 XML/XSLT 和 JSON 格式).它易于安装和配置,而且附带了一个基于H ...
- [Linux]Linux下安装和配置solr/tomcat/IK分词器 详细实例一.
在这里一下讲解着三个的安装和配置, 是因为solr需要使用tomcat和IK分词器, 这里会通过图文教程的形式来详解它们的安装和使用.注: 本文属于原创文章, 如若转载,请注明出处, 谢谢.关于设置I ...
- Solr(四)Solr实现简单的类似百度搜索高亮功能-1.配置Ik分词器
配置Ik分词器 一 效果图 二 实现此功能需要添加分词器,在这里使用比较主流的IK分词器. 1 没有配置IK分词器,用solr自带的text分词它会把一句话分成单个的字. 2 配置IK分词器,的话它会 ...
- Solr4.4入门,介绍Solr的安装、IK分词器的配置及高亮查询结果(转)
一.Windows下安装solr-4.4.0 1. 下载solr.4.4 2. 下载绿色版tomcat6.0.18 3. 解压下载的solr到d:\study\solr,将dist目录下的sol ...
- solr配置同义词,停止词,和扩展词库(IK分词器为例)
定义 同义词:搜索结果里出现的同义词.如我们输入”还行”,得到的结果包括同义词”还可以”. 停止词:在搜索时不用出现在结果里的词.比如is .a .are .”的”,“得”,“我” 等,这些词会在句子 ...
随机推荐
- fpga pll重配置实验总结
今天做了pll重配置的实验,输入时钟50m初始配置输出75m经重配置后输出100m,带宽为low,使用的ip:rom,altpll_reconfig ,altpll,将altpll配置为可重配置模式, ...
- Visual studio环境中的一些快捷键
VS的快键键 F12(转到定义),那怎么转回定义呢? 转回应该是Ctrl+Shift+8 自动排版:ctrl+E+D
- div,css常用技术
1,<div></div>一张图作为背景的用法: 必须指定width,height,background属性 .smallCircle{ margin-top: 25px; ...
- [LeetCode系列]翻转链表问题II
给定一个链表和两个整数m, n, 翻转链表第m个节点到第n个节点(从1开始计数). 如, 给定链表: 1->2->3->4->5->NULL, 以及 m = 2, n = ...
- Debian初识(选择最佳镜像发布站点加入source.list文件)
选择最佳镜像发布站点加入source.list文件:netselect,netselect-apt “该将哪个Debian镜像发布站点加入source.list文件?”.有很多方法来选择镜像发布站点, ...
- WebApi全局异常处理方式
自定义错误消息 public class ErrorMessage:DelegatingHandler { protected override Task<HttpResponseMessage ...
- 使用GDI+保存带Alpha通道的图像
带Alpha通道的图像(ARBG)在通过GDIPlus::Bitmap::FromHBITMAP等转为GDI+位图,再存储时,透明区域会变成纯黑(也有可能是纯白?). 网上找了两段保持透明的实现代 ...
- Java运算符,算术运算符
算术运算符介绍 算术运算符用在数学表达式中,它们的作用和在数学中的作用一样. 下表列出了所有的算术运算符. 表格中的实例假设整数变量A的值为10,变量B的值为20: 操作符 描述 例子 + 加法 - ...
- ThreadPoolExecutor之三:自定义线程池-扩展示例
ThreadPoolExecutor是可扩展的,下面一个示例: package com.dxz.threadpool.demo1; import java.util.concurrent.Blocki ...
- Java Web不能不懂的知识
1.传说中java的class文件可以一次编译到处运行,那么源代码采用GBK还是UTF-8会有影响么? 不会有影响. 因为Java源代码通过编译后,生成的class文件为字节码.它可以被看作是包含一个 ...