[Python] re正则表达式指南以及常用操作
一、语法
1. 使用正则表达式进行匹配的流程

2. Python支持的正则表达式元字符和语法
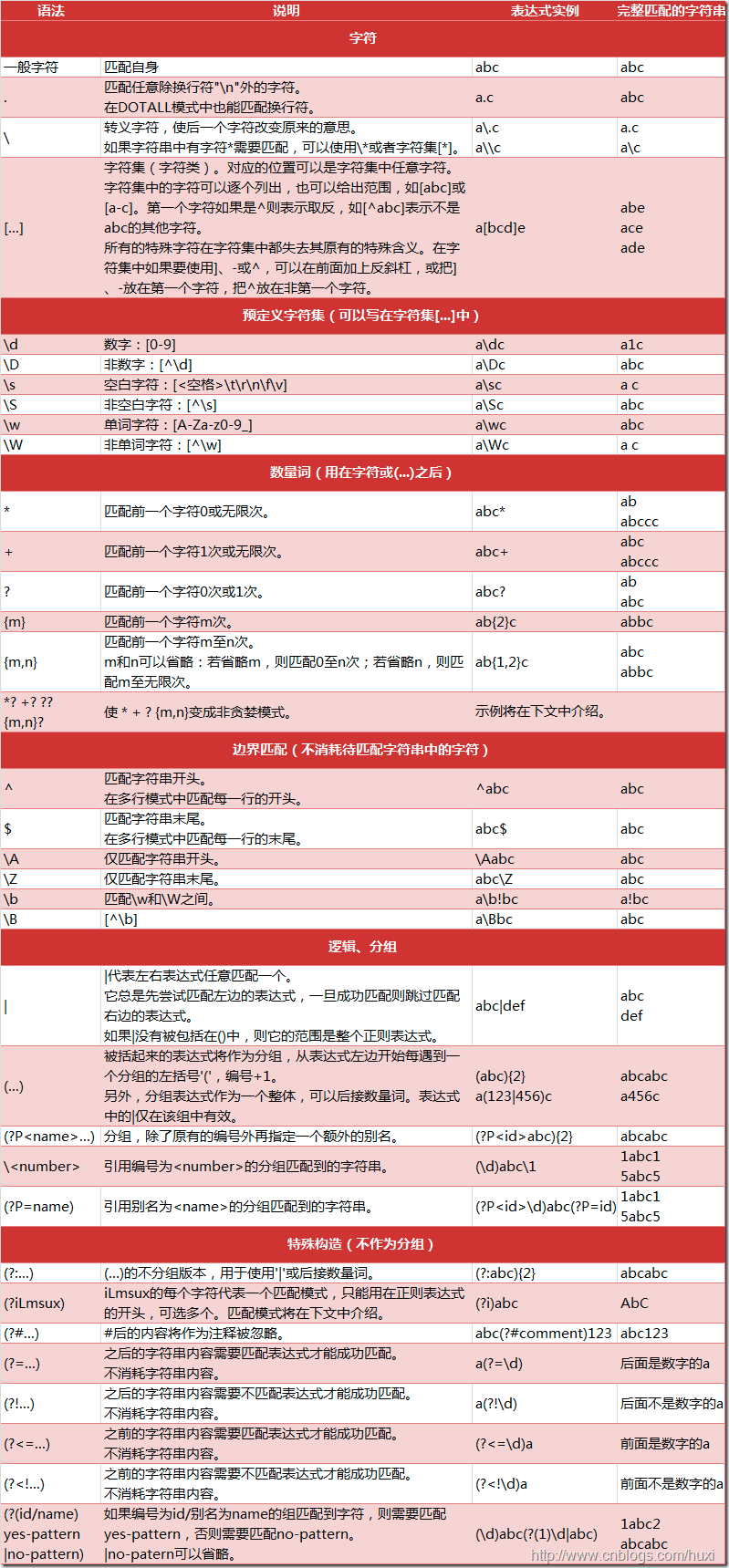
参考:
AstralWind的Python正则表达式指南
官方文档:7.2. re — Regular expression operations
二、常用操作
1. 匹配
>>> import re
>>> re.match(r'^\d{3}\-\d{3,8}$', '010-12345')
<_sre.SRE_Match object; span=(0, 9), match='010-12345'>
>>> re.match(r'^\d{3}\-\d{3,8}$', '010 12345')
>>>
match()方法判断是否匹配,如果匹配成功,返回一个Match对象,否则返回None。常见的判断方法就是:
test = '用户输入的字符串'
if re.match(r'正则表达式', test):
print('ok')
else:
print('failed')
2. 切分字符串
用正则表达式切分字符串比用固定的字符更灵活,请看正常的切分代码:
>>> 'a b c'.split(' ')
['a', 'b', '', '', 'c']
嗯,无法识别连续的空格,用正则表达式试试:
>>> re.split(r'\s+', 'a b c')
['a', 'b', 'c']
无论多少个空格都可以正常分割。加入,试试:
>>> re.split(r'[\s\,]+', 'a,b, c d')
['a', 'b', 'c', 'd']
再加入;试试:
>>> re.split(r'[\s\,\;]+', 'a,b;; c d')
['a', 'b', 'c', 'd']
如果用户输入了一组标签,下次记得用正则表达式来把不规范的输入转化成正确的数组。
3. 分组
除了简单地判断是否匹配之外,正则表达式还有提取子串的强大功能。用()表示的就是要提取的分组(Group)。比如:
^(\d{3})-(\d{3,8})$分别定义了两个组,可以直接从匹配的字符串中提取出区号和本地号码:
>>> m = re.match(r'^(\d{3})-(\d{3,8})$', '010-12345')
>>> m
<_sre.SRE_Match object; span=(0, 9), match='010-12345'>
>>> m.group(0)
'010-12345'
>>> m.group(1)
''
>>> m.group(2)
''
如果正则表达式中定义了组,就可以在Match对象上用group()方法提取出子串来。
注意到group(0)永远是原始字符串,group(1)、group(2)……表示第1、2、……个子串。
提取子串非常有用。来看一个更凶残的例子:
>>> t = '19:05:30'
>>> m = re.match(r'^(0[0-9]|1[0-9]|2[0-3]|[0-9])\:(0[0-9]|1[0-9]|2[0-9]|3[0-9]|4[0-9]|5[0-9]|[0-9])\:(0[0-9]|1[0-9]|2[0-9]|3[0-9]|4[0-9]|5[0-9]|[0-9])$', t)
>>> m.groups()
('', '', '')
这个正则表达式可以直接识别合法的时间。但是有些时候,用正则表达式也无法做到完全验证,比如识别日期:
'^(0[1-9]|1[0-2]|[0-9])-(0[1-9]|1[0-9]|2[0-9]|3[0-1]|[0-9])$'
对于'2-30','4-31'这样的非法日期,用正则还是识别不了,或者说写出来非常困难,这时就需要程序配合识别了。
4. 贪婪匹配
最后需要特别指出的是,正则匹配默认是贪婪匹配,也就是匹配尽可能多的字符。举例如下,匹配出数字后面的0:
>>> re.match(r'^(\d+)(0*)$', '').groups()
('', '')
由于\d+采用贪婪匹配,直接把后面的0全部匹配了,结果0*只能匹配空字符串了。
必须让\d+采用非贪婪匹配(也就是尽可能少匹配),才能把后面的0匹配出来,加个?就可以让\d+采用非贪婪匹配:
>>> re.match(r'^(\d+?)(0*)$', '').groups()
('', '')
5. 编译
当我们在Python中使用正则表达式时,re模块内部会干两件事情:
编译正则表达式,如果正则表达式的字符串本身不合法,会报错;
用编译后的正则表达式去匹配字符串。
如果一个正则表达式要重复使用几千次,出于效率的考虑,我们可以预编译该正则表达式,接下来重复使用时就不需要编译这个步骤了,直接匹配:
>>> import re
# 编译:
>>> re_telephone = re.compile(r'^(\d{3})-(\d{3,8})$')
# 使用:
>>> re_telephone.match('010-12345').groups()
('', '')
>>> re_telephone.match('010-8086').groups()
('', '')
编译后生成Regular Expression对象,由于该对象自己包含了正则表达式,所以调用对应的方法时不用给出正则字符串。
详细参考:
三、其它样例
1. 根据指定字符进行字符串切割
下面的语句先是将中文标点符号替换为指定的标记符号('\3'),然后根据该标记符号切割字符串;其它类型字符的处理方式类似
dialog = re.sub(u',|。|?|!', '\3', dialog).split('\3')
因为是中文字符,这里的u表示unicode编码
2. 只保留单词和数字字符
res = re.sub(r"_|\W", "", s).lower()
3. 验证Email地址
import re def is_valid_email(addr):
""" 验证Email地址 """
return True if re.match(r"^[0-9a-zA-Z.]+@[0-9a-zA-Z]+.com", addr) else False assert is_valid_email('someone@gmail.com')
assert is_valid_email('bill.gates@microsoft.com')
assert not is_valid_email('bob#example.com')
assert not is_valid_email('mr-bob@example.com')
print('ok')
4. 提取出带名字的Email地址
import re def name_of_email(addr):
""" 提取出带名字的Email地址 """
return re.match(r"^<?(\w+\s?\w+)>?.*@\w+.\w{3}", addr).group(1) assert name_of_email('<Tom Paris> tom@voyager.org') == 'Tom Paris'
assert name_of_email('tom@voyager.org') == 'tom'
print('ok')
[Python] re正则表达式指南以及常用操作的更多相关文章
- python学习二,字符串常用操作
字符串可以说是在日常开发中应用最广泛的了,现在来总结下有关python中有关字符串一些常用操作 首先我们声明一个字符串变量 str = "hello world" 下面我们来依次介 ...
- Python脚本控制的WebDriver 常用操作 <二> 关闭浏览器
下面将模拟一个WebDriver关闭浏览器的操作 测试用例场景 在一个自动化测试脚本运行完毕后,我们很可能会采取关闭浏览器的操作,而关闭浏览器的常用操作有如下两种: close quit close ...
- Python脚本控制的WebDriver 常用操作 <一> 启动浏览器
由于本人的学习定位是基于Selenium+WebDriver+Python+FireFox+Eclipse+Pydev, 所以我的笔记也只和这方面相关. 我打算先学习基于Python脚本WebDriv ...
- python的字典数据类型及常用操作
字典的定义与特性 字典是Python语言中唯一的映射类型. 定义:{key1: value1, key2: value2} 1.键与值用冒号“:”分开: 2.项与项用逗号“,”分开: 特性: 1.ke ...
- python的列表数据类型及常用操作
列表是最常用的Python数据类型,它可以作为一个方括号内的逗号分隔值出现. 列表中的每个元素都分配一个数字 - 它的位置,或索引,第一个索引是0,第二个索引是1,依此类推. 列表可以进行的操作包括索 ...
- Python中字符串有哪些常用操作?纯干货超详细
- Python脚本控制的WebDriver 常用操作 <十一> 操作测试对象
下面将使用WebDriver来模拟键盘的输入操作,以及复习上节的层对象操作 测试用例场景 定位到具体的对象后,我们就可以对这个对象进行具体的操作,比如先前已经看到过的点击操作(click).一般来说, ...
- Python脚本控制的WebDriver 常用操作 <八> 简单的对象定位
这一部分的内容,将是在WebDriver中,定位元素方法的演示,是将Selenium中Selenese元素定位命令的WebDriver中使用方法的结合 Selenium中元素定位方法复习可以参考: & ...
- Python脚本控制的WebDriver 常用操作 <十二> send_keys模拟按键输入
下面将使用WebDriver中的send_keys来模拟键盘按键输入 测试用例场景 send_keys方法可以模拟一些组合键操作: ctrl+a ctrl+c ctrl+v 等. 另外有时候我们需要在 ...
随机推荐
- 梅森素数应用 nefu 120
梅森素数 定义: if m是一个正整数 and 2^m-1是一个素数 then m是素数 if m是一个正整数 and m是一个素数 then M(m)=2^m-1被称为第m个梅森数 if p是一个素 ...
- 2017 ACM-ICPC 南宁区比赛 Minimum Distance in a Star Graph
2017-09-25 19:58:04 writer:pprp 题意看上去很难很难,但是耐心看看还是能看懂的,给你n位数字 你可以交换第一位和之后的某一位,问你采用最少的步数可以交换成目标 有五组数据 ...
- 自学Jav测试代码三 Math类 & Date & GregorianCalendar类
2017-08-23 20:30:08 writer: pprp package test; import java.util.Date; import java.util.*; public cla ...
- raid1磁盘更换---测试
安装centos6.71. CentOS安装过程配raid.参考:http://www.360doc.com/content/13/1209/21/14661619_335823338.shtml. ...
- Hibernate与 MyBatis的比较(转,留作以后细细钻研)
最近做了一个Hibernate与MyBatis的对比总结,希望大家指出不对之处. 第一章 Hibernate与MyBatis Hibernate 是当前最流行的O/R mapping框架,它出 ...
- jqueryUI之datepicker日历插件的介绍和使用
jQuery UI很强大,其中的日期选择插件Datepicker是一个配置灵活的插件.我们可以自定义其展示方式,包括日期格式.语言.限制选择日期范围.添加相关按钮以及其它导航等.
- 完美解决 No toolchains found in the NDK toolchains folder for ABI with prefix: mips64el-linux-android
问题描述 好久之前的一个Android项目,最近需要重构一下 因为Android Studio的开发环境以及Gradle的版本等等都进行了一定的更新,于是导入Project以后,出现了报错: No t ...
- jquery 表格自动拆分(方便打印)插件-printTable
/** * jquery 表格打印插件 * * 作者: LiuJunGuang * 日期:2013年6月4日 * 分页样式(需要自定义): * @media print { * .pageBreak ...
- mysql数据库优化课程---15、mysql优化步骤
mysql数据库优化课程---15.mysql优化步骤 一.总结 一句话总结:索引优化最立竿见影 1.mysql中最常用最立竿见影的优化是什么? 索引优化 索引优化,不然有多少行要扫描多少次,1亿行大 ...
- Python面向过程和面向对象基础
总结一下: 面向过程编程:根据业务逻辑从上到下的写代码-----就是一个project写到底,重复利用性比较差 函数式:将某些特定功能代码封装到函数中------方便日后调用 面向对象:对函数进行分类 ...