【Python笔记】十分钟搞定pandas
本文是对pandas官方网站上《10 Minutes to pandas》的一个简单的翻译,原文在这里。这篇文章是对pandas的一个简单的介绍,详细的介绍请参考:Cookbook 。习惯上,我们会按下面格式引入所需要的包:

一、 创建对象
可以通过 Data Structure Intro Setion 来查看有关该节内容的详细信息。
1、可以通过传递一个list对象来创建一个Series,pandas会默认创建整型索引:

2、通过传递一个numpy array,时间索引以及列标签来创建一个DataFrame:

3、通过传递一个能够被转换成类似序列结构的字典对象来创建一个DataFrame:

4、查看不同列的数据类型:

5、如果你使用的是IPython,使用Tab自动补全功能会自动识别所有的属性以及自定义的列,下图中是所有能够被自动识别的属性的一个子集:

二、 查看数据
详情请参阅:Basics Section
1、 查看frame中头部和尾部的行:

2、 显示索引、列和底层的numpy数据:

3、 describe()函数对于数据的快速统计汇总:

4、 对数据的转置:

5、 按轴进行排序

6、 按值进行排序

三、 选择
虽然标准的Python/Numpy的选择和设置表达式都能够直接派上用场,但是作为工程使用的代码,我们推荐使用经过优化的pandas数据访问方式: .at, .iat, .loc, .iloc 和 .ix详情请参阅Indexing and Selecing Data 和MultiIndex / Advanced Indexing。
l 获取
1、 选择一个单独的列,这将会返回一个Series,等同于df.A:

2、 通过[]进行选择,这将会对行进行切片

l 通过标签选择
1、 使用标签来获取一个交叉的区域

2、 通过标签来在多个轴上进行选择

3、 标签切片

4、 对于返回的对象进行维度缩减

5、 获取一个标量

6、 快速访问一个标量(与上一个方法等价)

l 通过位置选择
1、 通过传递数值进行位置选择(选择的是行)

2、 通过数值进行切片,与numpy/python中的情况类似

3、 通过指定一个位置的列表,与numpy/python中的情况类似

4、 对行进行切片

5、 对列进行切片

6、 获取特定的值

l 布尔索引
1、 使用一个单独列的值来选择数据:

2、 使用where操作来选择数据:

3、 使用isin()方法来过滤:

l 设置
1、 设置一个新的列:

2、 通过标签设置新的值:

3、 通过位置设置新的值:

4、 通过一个numpy数组设置一组新值:

上述操作结果如下:

5、 通过where操作来设置新的值:(必须数值型,存在字符串列会出错!)

四、 缺失值处理
在pandas中,使用np.nan来代替缺失值,这些值将默认不会包含在计算中,详情请参阅:Missing Data Section。
1、 reindex()方法可以对指定轴上的索引进行改变/增加/删除操作,这将返回原始数据的一个拷贝:、

2、 去掉包含缺失值的行:

3、 对缺失值进行填充:

4、 对数据进行布尔填充:

五、 相关操作
详情请参与 Basic Section On Binary Ops
l 统计(相关操作通常情况下不包括缺失值)
1、 执行描述性统计:

2、 在其他轴上进行相同的操作:

3、 对于拥有不同维度,需要对齐的对象进行操作。Pandas会自动的沿着指定的维度进行广播:

l Apply
1、 对数据应用函数:

l 直方图
具体请参照:Histogramming and Discretization

l 字符串方法
Series对象在其str属性中配备了一组字符串处理方法,可以很容易的应用到数组中的每个元素,如下段代码所示。更多详情请参考:Vectorized String Methods.

六、 合并
Pandas提供了大量的方法能够轻松的对Series,DataFrame和Panel对象进行各种符合各种逻辑关系的合并操作。具体请参阅:Merging section
l Concat
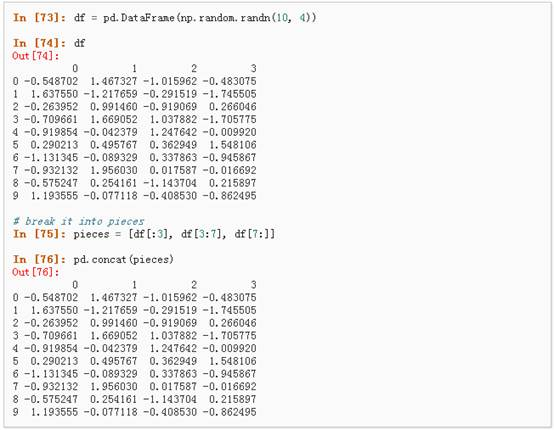
l Join 类似于SQL类型的合并,具体请参阅:Database style joining

l Append 将一行连接到一个DataFrame上,具体请参阅Appending:

七、 分组
对于”group by”操作,我们通常是指以下一个或多个操作步骤:
l (Splitting)按照一些规则将数据分为不同的组;
l (Applying)对于每组数据分别执行一个函数;
l (Combining)将结果组合到一个数据结构中;
详情请参阅:Grouping section

1、 分组并对每个分组执行sum函数:

2、 通过多个列进行分组形成一个层次索引,然后执行函数:

八、 Reshaping
详情请参阅 Hierarchical Indexing 和 Reshaping。
l Stack



l 数据透视表,详情请参阅:Pivot Tables.

可以从这个数据中轻松的生成数据透视表:

九、 时间序列
Pandas在对频率转换进行重新采样时拥有简单、强大且高效的功能(如将按秒采样的数据转换为按5分钟为单位进行采样的数据)。这种操作在金融领域非常常见。具体参考:Time Series section。

1、 时区表示:
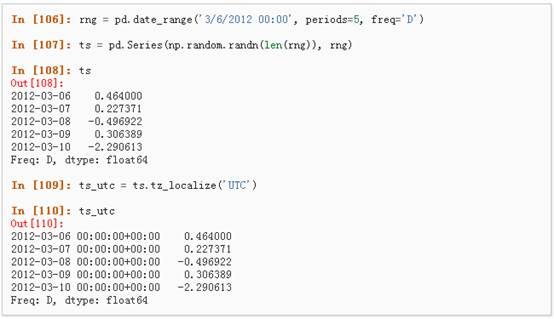
2、 时区转换:
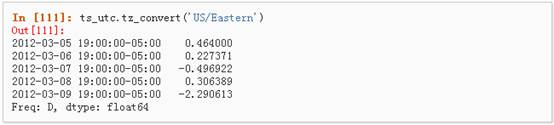
3、 时间跨度转换:
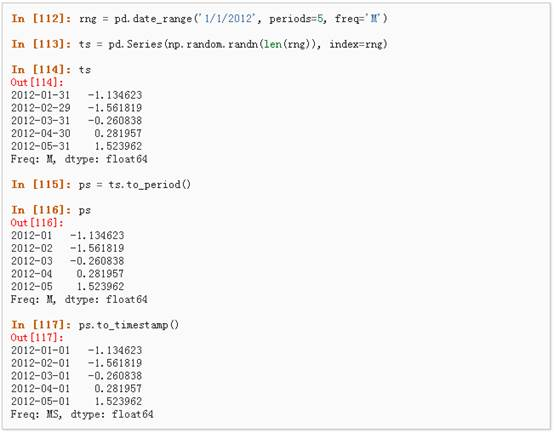
4、 时期和时间戳之间的转换使得可以使用一些方便的算术函数。

十、 Categorical
从0.15版本开始,pandas可以在DataFrame中支持Categorical类型的数据,详细 介绍参看:categorical introduction和API documentation。

1、 将原始的grade转换为Categorical数据类型:

2、 将Categorical类型数据重命名为更有意义的名称:

3、 对类别进行重新排序,增加缺失的类别:

4、 排序是按照Categorical的顺序进行的而不是按照字典顺序进行:

5、 对Categorical列进行排序时存在空的类别:

十一、 画图
具体文档参看:Plotting docs
对于DataFrame来说,plot是一种将所有列及其标签进行绘制的简便方法:

十二、 导入和保存数据
l CSV,参考:Writing to a csv file
1、 写入csv文件:

2、 从csv文件中读取:

l HDF5,参考:HDFStores
1、 写入HDF5存储:

2、 从HDF5存储中读取:

l Excel,参考:MS Excel
1、 写入excel文件:

2、 从excel文件中读取:

import pandas as pd;import numpy as np;import matplotlib.pyplot as plt;dates= pd.date_range('20130101',periods=6)df=pd.DataFrame({'A':1,'B':pd.Timestamp('20130102'),'C':pd.Series(1,index=list(range(4)),dtype='float32'),'D':np.array([3]*4,dtype='int32'),'E':pd.Categorical(["test","train","test","train"]),'F':'foo'})df=pd.DataFrame(np.random.randn(6,4),index=dates,columns=list('ABCD'))#6行4列""" A B C D2013-01-01 -1.107551 0.195271 -1.230686 -0.4846302013-01-02 0.865845 -1.511340 -1.534180 2.0543692013-01-03 0.904075 -0.336863 -0.718355 0.1242692013-01-04 0.508006 -0.375838 -1.626099 0.8341802013-01-05 0.577990 1.005768 -1.883421 -0.4608582013-01-06 -0.750353 -1.296683 -0.627696 -1.204832"""df.head(6);df.indexdf.columnsdf.valuesdf.describe()df.Thelp(pd.DataFrame.sort_index)df.sort_index(axis=1,ascending=False)#axis=0是按行序号排序,1位按列序号排序df.sort(columns='B')df[0:3]#单独按行或者按列,返回数据框,[0:3]是第0行到第2行,不包括第3行!df.loc[dates[0],:]#多轴选择,按字段名df.iloc[0,:]#多轴选择,按索引序号df.at[dates[0],'A']#单独选择一个值,按字段名df.iat[0,0]#单独选择一个值,按索引序号df[df.A>0]df[df>0]df2=df.copy()#深拷贝df2['E']=['one','one','two','three','four','three']df2.loc[dates[0],'E']='124'df2[df2['E'].isin(['124','three'])]s1=pd.Series([1,2,3,4,5,6],index=pd.date_range('20130102',periods=6))df['F']=s1df.loc[:,'D']=np.array([5]*len(df))df2=df2.loc[:,['A','B','C','D']]df2[df2>0]=-df2df1=df.reindex(index=dates[0:4],columns=list(df.columns)+['E'])df1.loc[dates[0]:dates[1],'E']=1df1.dropna(how='any')#去掉包含缺失值的行df1.fillna(value=5)pd.isnull(df1)df.mean(1)#代表按行平均s=pd.Series([1,3,5,np.nan,6,8],index=dates).shift(2)#向下偏倚2个单位df.apply(np.cumsum)#列累加df.apply(lambda x: x.max()-x.min())#列最大最小相减s=pd.Series(np.random.randint(0,7,size=10))#取值范围[最小值,最大值]的整型个数s.value_counts()#统计词频,和R中的table一样s=pd.Series(['A','B','C','Aaba','Baca',np.nan,'caba','dog','cat'])s.str.lower()#小写输出,原s未变pieces=[df[:2],df[2:4],df[4:]]pd.concat(pieces)#连接left=pd.DataFrame({'key':['foo','foo'],'lval':[1,2]})right=pd.DataFrame({'key':['foo','foo'],'rval':[4,5]})pd.merge(left,right,on='key')#全连接df=pd.DataFrame(np.random.randn(8,4),columns=['A','B','C','D'])s=df.iloc[3]df.append(s,ignore_index=True)#尾部添加一行df.groupby(['D','F']).sum()#SQL里的分组聚合#R语言的reshapetuples=list(zip(*[['bar','bar','baz','baz','foo','foo','qux','qux'],['one','two','one','two','one','two','one','two']]))#返回一系列元组,每个对应组的第i个index=pd.MultiIndex.from_tuples(tuples,names=['first','second'])df2=pd.DataFrame(np.random.randn(8,2),index=index,columns=['A','B'])stacked=df2.stack()#宽变长stacked.unstack(0)#长变宽,把第0列变宽df['A1']=['one','one','one','two','two','two']df['A2']=['first','first','second','first','third','first']df['A3']=['hee','hee','sec','sec','sec','hee']pd.pivot_table(df,values='A',index=['A2','A3'],columns=['A1'])#透视表,#时间rng=pd.date_range('1/1/2012',periods=100,freq='S')#精确到秒ts=pd.Series(np.random.randint(0,500,len(rng)),index=rng)ts.resample('5Min',how='sum')#重采样rng=pd.date_range('3/6/2012',periods=5,freq='D')ts=pd.Series(np.random.randn(len(rng)),rng)ts_utc=ts.tz_localize('UTC')#时区ts_utc.tz_convert('US/Eastern')#时区转换rng=pd.date_range('3/6/2012',periods=5,freq='M')ts=pd.Series(np.random.randn(len(rng)),rng)ps=ts.to_period()#?时间跨度转换ps.to_timestamp()#?全部转换为1号的prng=pd.period_range('1990Q1','2000Q4',freq='Q-NOV')ts=pd.Series(np.random.randn(len(prng)),prng)ts.index=(prng.asfreq('M','e')+1).asfreq('H','s')+9#!!!!df=pd.DataFrame({"id":[1,2,3,4,5,6],"raw_grade":['a','b','b','a','a','e']})df["grade"]=df["raw_grade"].astype("category")#类似R里面的factor因子df.dtypesdf["grade"].cat.categories=["very good","good","very bad"]#因子等级名称换了,cat是Categorical的缩写?或者是返回?df["grade"]=df["grade"].cat.set_categories(["very bad","bad","medium","good","very good"])#因子等级排序,pd.Categorical.set_categoriesdf.groupby("grade").size()ts=pd.Series(np.random.randn(1000),index=pd.date_range('1/1/2000',periods=1000))ts=ts.cumsum()ts.plot(grid=True)#grid添加网格参数df=pd.DataFrame(np.random.randn(1000,4),index=ts.index,columns=['A','B','C','D'])df=df.cumsum()plt.figure();#?啥作用df.plot();plt.legend(loc='best')#没图?df.to_csv('test.csv')#写入dfpd.read_csv('test.csv')#读文件"test.csv"
【Python笔记】十分钟搞定pandas的更多相关文章
- 十分钟搞定pandas内容
目录 十分钟搞定pandas 一.创建对象 二.查看数据 三.选择器 十二.导入和保存数据 参考:http://pandas.pydata.org/pandas-docs/stable/whatsne ...
- 【原】十分钟搞定pandas
http://www.cnblogs.com/chaosimple/p/4153083.html 本文是对pandas官方网站上<10 Minutes to pandas>的一个简单的翻译 ...
- 十分钟搞定 pandas
原文:http://pandas.pydata.org/pandas-docs/stable/10min.html 译者:ChaoSimple 校对:飞龙 官方网站上<10 Minutes to ...
- 十分钟搞定pandas
转至:http://www.cnblogs.com/chaosimple/p/4153083.html 本文是对pandas官方网站上<10 Minutes to pandas>的一个简单 ...
- 【转】十分钟搞定pandas
原文链接:http://www.cnblogs.com/chaosimple/p/4153083.html 关于pandas的入门介绍,比较全,也比较实在,特此记录~ 还有关于某同学的pandas学习 ...
- 十分钟搞定CSS选择器
在最近的web开发中是不是就会用到一些选择器,发现很多尤其是CSS3新增的不太熟悉,在此总结一下. 优先级 不同级别 1. 在属性后面使用 !important 会覆盖页面内任何位置定义的元素样式. ...
- (转)十分钟搞定CSS选择器
原文地址:http://www.cnblogs.com/dolphinX/p/3347713.html 在最近的web开发中是不是就会用到一些选择器,发现很多尤其是CSS3新增的不太熟悉,在此总结一下 ...
- 十分钟搞定微信企业帐号“echostr校验失败,请您检查是否正确解密并输出明文echostr”
问题域:在这里我们只解决密文可以正确解密,但微信验证提示“echostr校验失败,请您检查是否正确解密并输出明文echostr”的问题. 干货:没有正确验证的原因是:你给微信返回的是字符串,而微信需要 ...
- 十分钟搞定mongodb副本集
mongodb副本集配置 最近项目中用到了mongodb,由于是用mongodb来记录一些程序的日志信息和日常的统计,为了增加应用的可靠性,一直在找mongodb集群的一些资料,下面是对最近做的一个小 ...
随机推荐
- 使用npm安装包失败的解决办法(使用npm国内镜像介绍)
镜像使用方法(三种办法任意一种都能解决问题,建议使用第三种,将配置写死,下次用的时候配置还在): 1.通过config命令 npm config set registry https://regist ...
- Dijkstra算法(转)
基本思想 通过Dijkstra计算图G中的最短路径时,需要指定起点s(即从顶点s开始计算). 此外,引进两个集合S和U.S的作用是记录已求出最短路径的顶点(以及相应的最短路径长度),而U则是记录还未求 ...
- python设计模式之迭代器与生成器详解(五)
前言 迭代器是设计模式中的一种行为模式,它提供一种方法顺序访问一个聚合对象中各个元素, 而又不需暴露该对象的内部表示.python提倡使用生成器,生成器也是迭代器的一种. 系列文章 python设计模 ...
- python操作adb代码
adb命令的练习 #!/usr/bin/env python # encoding: utf-8 import os import re nameplt=re.compile("packag ...
- mac 上 sublime text2 快捷键
打开/前往: ⌘T 前往文件 ⌘⌃P 前往项目⌘R 前往 method⌘⇧P 命令提示⌃G 前往行⌃ ` python 控制台 编辑:⌘L 选择行 (重复按下将下一行加入选择)⌘D 选择词 (重复按下 ...
- UFT12.续期的操作方法
安装完毕UFT后,页面中报install错误,此时报此错误的原因是因为UFT的许可证过期了,解决方法如下: 方法是找到C:\ProgramData目录下的SafeNet Sentinel文件夹将其删除 ...
- (二) Mysql 数据类型简介
第一节:整数类型.浮点数类型和定点数类型 1,整数类型 2,浮点数类型和定点数类型 M 表示:数据的总长度(不包括小数点): D 表示:小数位: 例如 decimal(5,2) 123.45 ...
- hdu 5912(迭代+gcd)
Fraction Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Others)Total Su ...
- 如何让EasyUI弹出层跳出框架
这个的解决方法其实挺简单的. 只要在最外面的框架页面加个div,然后用parent.div的id就可以的.但是必须得弹出框得是一个页面. <div id="div_info" ...
- 浅谈ES5和ES6继承和区别
最近想在重新学下ES6,所以就把自己学到的,记录下加强下自己的理解 首先先简单的聊下ES5和ES6中的继承 1.在es5中的继承: function parent(a,b){ this a = a; ...