机器学习笔记—K-均值聚类
在聚类问题中,给定训练集 {x(1),...,x(m)},要把数据分成内聚的“簇”。这里 x(i)∈R,没有 y(i)。所以,这是一个无监督学习问题。
k-均值聚类算法如下:
1、随机初始化簇中心 μ1,μ2,...,μk∈Rn;
2、重复直至收敛:{
对每个 i:
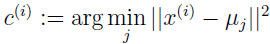
对每个 j:

}
其中 k 是簇个数,簇中心 μj 表示猜测的簇中心位置,初始化簇中心时,随机选择 k 个训练例子作为簇中心。
算法在内循环中不停执行两步:(i) 把每个 x(i) 绑定到最近的簇中心 μj,(ii) 移动每个簇中心到相应簇的均值 μj。下图显示了 k均值的运行过程

k-均值算法保证收敛吗?在某种意义上,是的。特别的,我们定义畸变函数为:
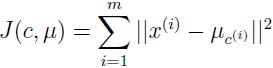
J 表示每一个训练例和簇中心的距离平方。可以看出,k 均值就是 J 的坐标下降。特别的,k-均值的内循环不停地最小化 J,最小化 J 时, μ 固定时以 c 为参数,c 固定时以 μ 为参数,所以 J 一定是单调下降的,J 一定会收敛。通常,这意味着 c 和 μ 也会收敛。理论上,k-均值会在一些不同的聚类震荡,有相同的 J,但在实践中几乎不会发生。
畸变函数 J 是个非凸函数,所以 J 的坐标下降法不能保证收敛到全局最优,换句话说,k-均值可能会到局部最优。尽管如此,k-均值经常运行很好,可以得到很好的聚类结果。如果你还是担心陷入局部最优,一个常做的事情是多运行几次 k-均值算法(使用不同的随机初始值 μj),然后在找到的所有聚类结果中,选择 J 最小的一个结果。
参考资料:
1、http://cs229.stanford.edu/notes/cs229-notes7a.pdf
机器学习笔记—K-均值聚类的更多相关文章
- 机器学习之K均值聚类
聚类的核心概念是相似度或距离,有很多相似度或距离的方法,比如欧式距离.马氏距离.相关系数.余弦定理.层次聚类和K均值聚类等 1. K均值聚类思想 K均值聚类的基本思想是,通过迭代的方法寻找K个 ...
- 100天搞定机器学习|day44 k均值聚类数学推导与python实现
[如何正确使用「K均值聚类」? 1.k均值聚类模型 给定样本,每个样本都是m为特征向量,模型目标是将n个样本分到k个不停的类或簇中,每个样本到其所属类的中心的距离最小,每个样本只能属于一个类.用C表示 ...
- 机器学习实战---K均值聚类算法
一:一般K均值聚类算法实现 (一)导入数据 import numpy as np import matplotlib.pyplot as plt def loadDataSet(filename): ...
- 机器学习算法与Python实践之(六)二分k均值聚类
http://blog.csdn.net/zouxy09/article/details/17590137 机器学习算法与Python实践之(六)二分k均值聚类 zouxy09@qq.com http ...
- 机器学习实战5:k-means聚类:二分k均值聚类+地理位置聚簇实例
k-均值聚类是非监督学习的一种,输入必须指定聚簇中心个数k.k均值是基于相似度的聚类,为没有标签的一簇实例分为一类. 一 经典的k-均值聚类 思路: 1 随机创建k个质心(k必须指定,二维的很容易确定 ...
- 机器学习之路:python k均值聚类 KMeans 手写数字
python3 学习使用api 使用了网上的数据集,我把他下载到了本地 可以到我的git中下载数据集: https://github.com/linyi0604/MachineLearning 代码: ...
- 机器学习理论与实战(十)K均值聚类和二分K均值聚类
接下来就要说下无监督机器学习方法,所谓无监督机器学习前面也说过,就是没有标签的情况,对样本数据进行聚类分析.关联性分析等.主要包括K均值聚类(K-means clustering)和关联分析,这两大类 ...
- K均值聚类的失效性分析
K均值聚类是一种应用广泛的聚类技术,特别是它不依赖于任何对数据所做的假设,比如说,给定一个数据集合及对应的类数目,就可以运用K均值方法,通过最小化均方误差,来进行聚类分析. 因此,K均值实际上是一个最 ...
- 探索sklearn | K均值聚类
1 K均值聚类 K均值聚类是一种非监督机器学习算法,只需要输入样本的特征 ,而无需标记. K均值聚类首先需要随机初始化K个聚类中心,然后遍历每一个样本,将样本归类到最近的一个聚类中,一个聚类中样本特征 ...
- k均值聚类算法原理和(TensorFlow)实现
顾名思义,k均值聚类是一种对数据进行聚类的技术,即将数据分割成指定数量的几个类,揭示数据的内在性质及规律. 我们知道,在机器学习中,有三种不同的学习模式:监督学习.无监督学习和强化学习: 监督学习,也 ...
随机推荐
- How many---hdu2609(最小表示)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=2609 给你n个01串,然后求这n个串中有几个不同的: 例如:1100 ,1001 ,0011 ,011 ...
- PHP error_log 新认知
//error_log 简介及使用方法 // error_log("消息","类型","路径"); //message //type ...
- LInux下桥接模式详解二
上篇文章导入博客园的比较早,而这篇自己在写的时候才发现内部复杂的很,以至于没能按时完成,造成两篇文章的间隔时间有点长! 话不多说,言归正传! 前面的文章介绍了桥接模式下的基础理论知识,其实本节想结合L ...
- int文档
文档 class int(object): """ int(x=0) -> integer int(x, base=10) -> integer ------ ...
- Django logging模块
一.Django logging配置 1.在setting.py中配置 # 日志文件存放路径 BASE_LOG_DIR = os.path.join(BASE_DIR, "log" ...
- ObjectDetection中的一些名词中英文对照
mAP:mean Average Precision,平均精确度 recall rate:召回率 Loss Function Anchro
- 前端 html border-right: 1px solid red;
后边框 加粗 实体线 红色 border-right: 1px solid red;
- ambari rest api (三)
1.获取指定主机指定组件的信息列表 http://ip:8080/api/v1/clusters/hdp_dev/hosts/hadoop003.edcs.org/host_components/DA ...
- Uboot mmc命令解析&NAND flash uboot命令详解
转载:http://blog.csdn.net/simonjay2007/article/details/43198353 一:mmc的命令如下: 1:对mmc读操作 mmc read addr bl ...
- javaScript动画2 scroll家族
offsetWidth和offsetHight (检测盒子自身宽高+padding+border) 这两个属性,他们绑定在了所有的节点元素上.获取之后,只要调用这两个属性,我们就能够获取元素节点的宽和 ...