97.5%准确率的深度学习中文分词(字嵌入+Bi-LSTM+CRF)
摘要
深度学习当前在NLP领域发展也相当快,翻译,问答,摘要等基本都被深度学习占领了。 本文给出基于深度学习的中文分词实现,借助大规模语料,不需要构造额外手工特征,在2014年人民日报语料上取得97.5%的准确率。模型基本是参考论文:http://www.aclweb.org/anthology/N16-1030
相关方法
中文分词是个比较经典的问题,各大互联网公司都会有自己的分词实现。 考虑到性能,可维护性,词库更新,多粒度,以及其他的业务需求,一般工业界中文分词方案都是基于规则。
1) 基于规则的常见的就是最大正/反向匹配,以及双向匹配。
2) 规则里糅合一定的统计规则,会采用动态规划计算最大的概率路径的分词
以上说起来很简单,其中还有很多细节,比如词法规则的高效匹配编译,词库的索引结构等。
3) 基于传统机器学习的方法 ,以CRF为主,也有用svm,nn的实现,这类都是基于模型的,跟本文一样,都有个缺陷,不方便增加用户词典(但可以结合,比如解码的时候force-decode)。 速度上会有损耗。 另外都需要提取特征。传统CRF一般是定义特征模板,方便性上有所提高。另外传统CRF训练算法(LBFGS)较慢,也有使用sgd的,但多线程都支持的不好。代表有crf++, crfsuite, crfsgd, wapiti等。
深度学习方法
深度学习主要是特征学习,端到端训练, 适合有大量语料的场景。另外各种工具越来越完善,利用GPU可大幅提高训练速度。
前文提过,深度学习主要是特征学习,在NLP里各种词嵌入是一种有效的特征学习。 本文实现的第一步也是对语料进行处理,使用word2vec对语料的字进行嵌入,每个字特征为50维。
得到字嵌入后,用字嵌入特征喂给双向LSTM, 对输出的隐层加一个线性层,然后加一个CRF就得到本文实现的模型。
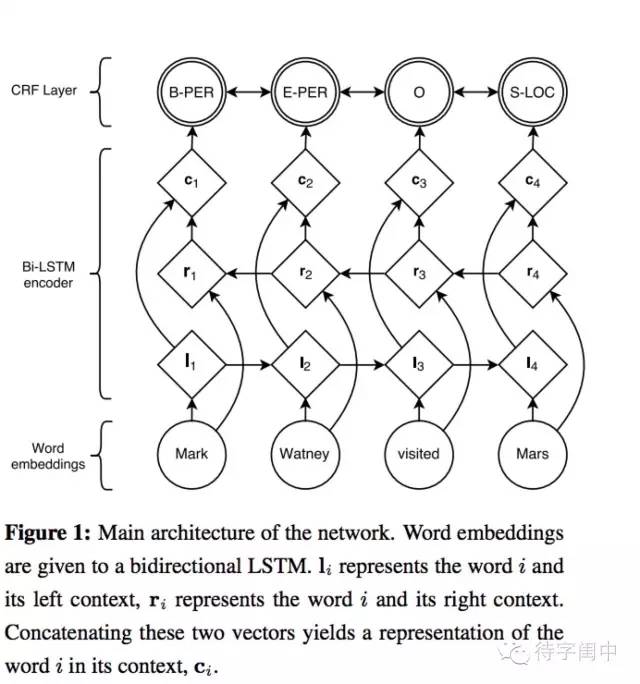
另外,字符嵌入的表示可以是纯预训练的,但也可以在训练模型的时候再fine-tune,一般而言后者效果更好。
对于fine-tune的情形,可以在字符嵌入后,输入双向LSTM之前加入dropout进一步提升模型效果。
最后,对于最优化方法,文本语言模型类的貌似Adam效果更好, 对于分类之类的,貌似AdaDelta效果更好。
语料
本文使用2014人民日报语料,一共50w+ 句子,1千多万的字符次数 (句子长度超过50的不考虑)
标注示例:
法新社/j 报道/v 说/v ,/w [泰国/nsf 政府/nis]/nt 已经/d 作/v 好/a 签发/v 紧急状态/n 令/v的/ude1 准备/vn 。/w (/w 老/a 任/v )/w
预处理
我们首先使用word2vec对字进行嵌入,具体就是把每一句按字符切割,空格隔开,喂给word2vec,指定维度50
然后我们把每一句处理成 :
字索引1 字索引2 … 字索引N 标注1 标注2 … 标注N
对于标注,我们按字分词的典型套路,
- 对于单独字符,不跟前后构成词的,我们标注为S (0)
- 跟后面字符构成词且自身是第一个字符的,我们标注为B (1)
- 在成词的中间的字符,标注为M (2)
- 在词尾的字符,标注为E (3)
这样处理后使用前面描述模型训练。
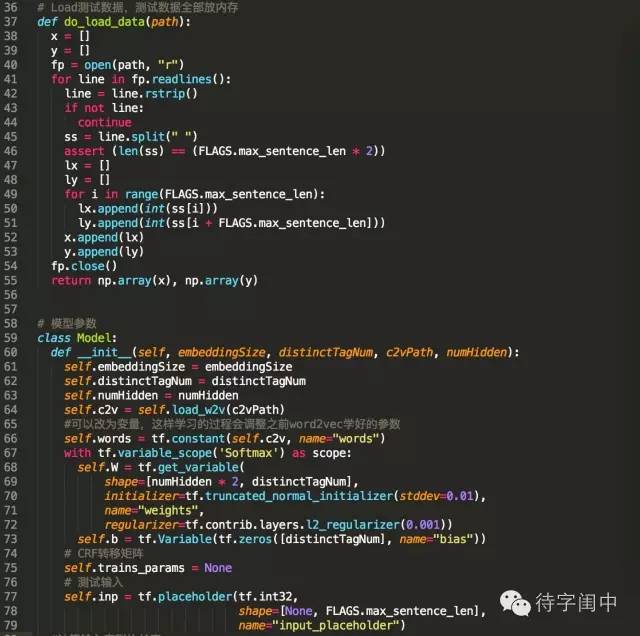
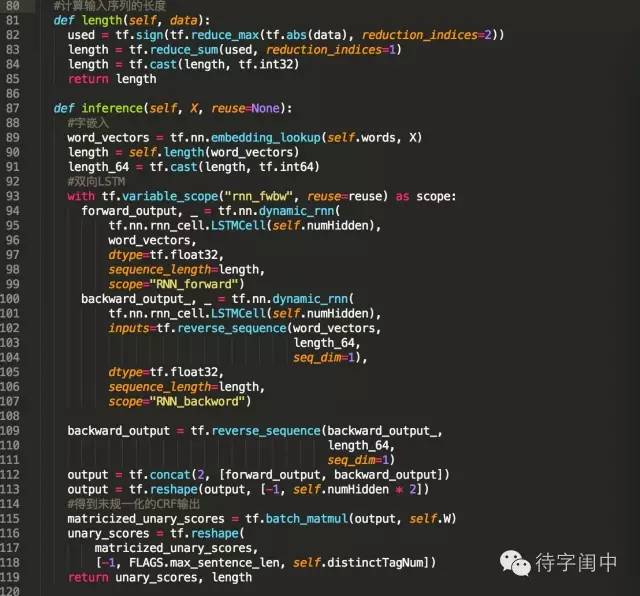
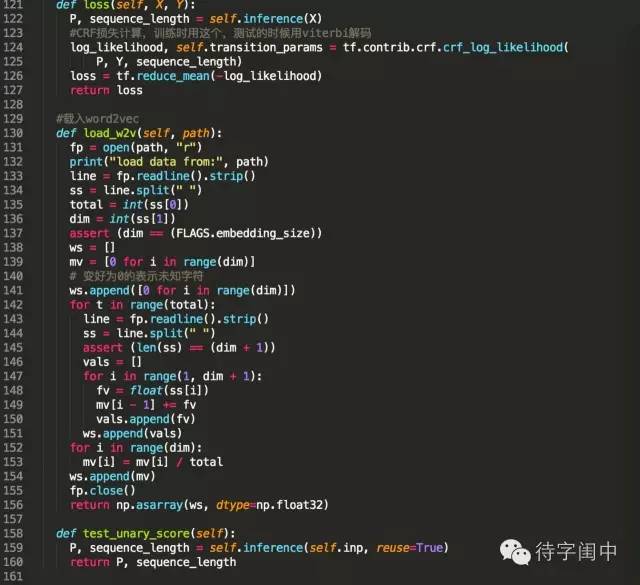
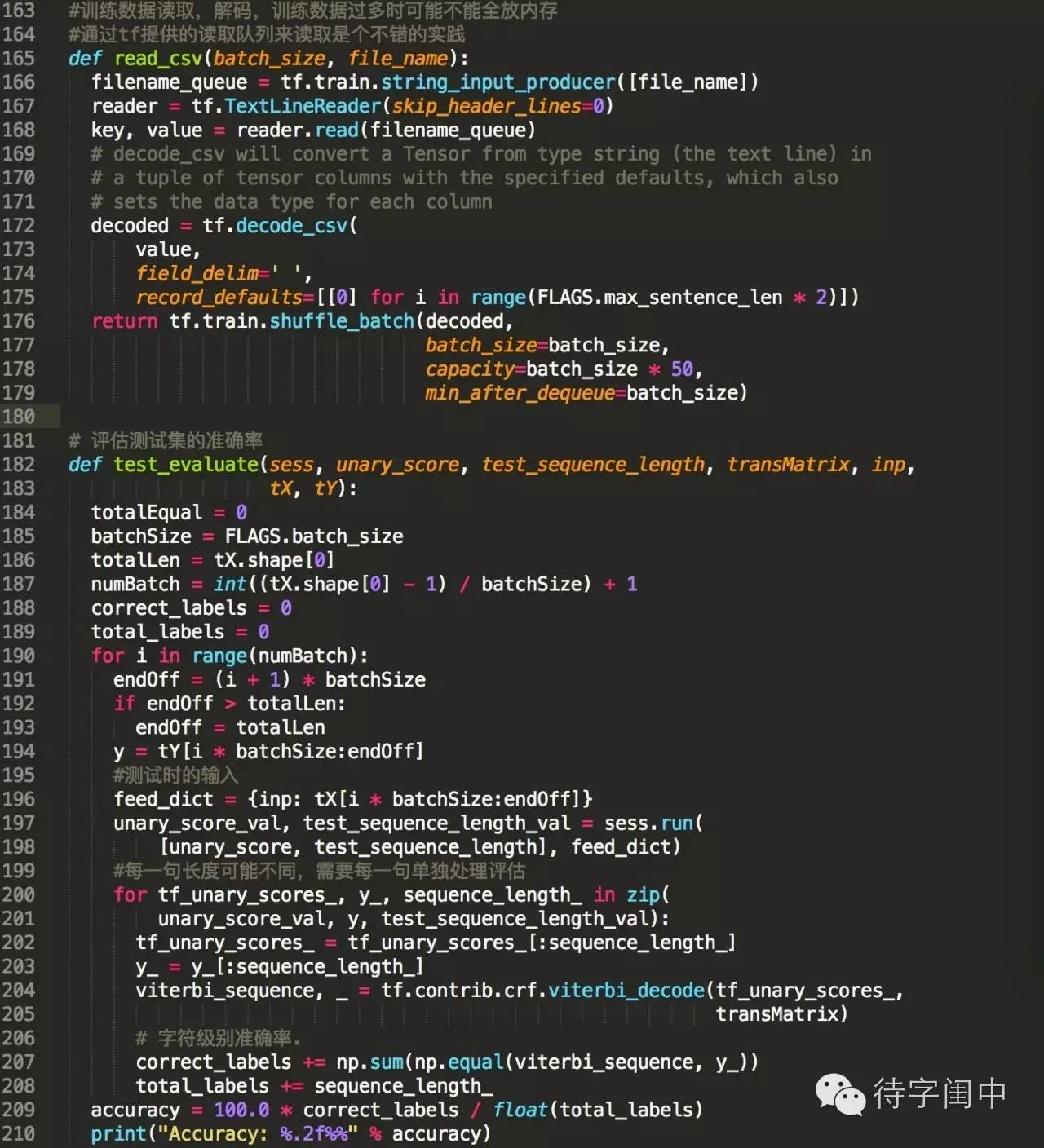
训练代码


在线测试服务
C++提供的在线服务demo:http://45.32.100.248:9090/ ?,或是点击“原文链接” 测试。
97.5%准确率的深度学习中文分词(字嵌入+Bi-LSTM+CRF)的更多相关文章
- 开源项目kcws代码分析--基于深度学习的分词技术
http://blog.csdn.net/pirage/article/details/53424544 分词原理 本小节内容参考待字闺中的两篇博文: 97.5%准确率的深度学习中文分词(字嵌入+Bi ...
- 万字总结Keras深度学习中文文本分类
摘要:文章将详细讲解Keras实现经典的深度学习文本分类算法,包括LSTM.BiLSTM.BiLSTM+Attention和CNN.TextCNN. 本文分享自华为云社区<Keras深度学习中文 ...
- TensorFlow 深度学习中文第二版·翻译完成
原文:Deep Learning with TensorFlow Second Edition 协议:CC BY-NC-SA 4.0 不要担心自己的形象,只关心如何实现目标.--<原则>, ...
- crf++实现中文分词简单例子 (Windows crf++0.58 python3)
学习自然语言处理的同学都知道,条件随机场(crf)是个好东西.虽然它的原理确实理解起来有点困难,但是对于我们今天用到的这个crf工具crf++,用起来却是挺简单方便的. 今天只是简单试个水,参考别人的 ...
- 深度学习:浅谈RNN、LSTM+Kreas实现与应用
主要针对RNN与LSTM的结构及其原理进行详细的介绍,了解什么是RNN,RNN的1对N.N对1的结构,什么是LSTM,以及LSTM中的三门(input.ouput.forget),后续将利用深度学习框 ...
- 深度学习的seq2seq模型——本质是LSTM,训练过程是使得所有样本的p(y1,...,yT‘|x1,...,xT)概率之和最大
from:https://baijiahao.baidu.com/s?id=1584177164196579663&wfr=spider&for=pc seq2seq模型是以编码(En ...
- 自己动手实现深度学习框架-7 RNN层--GRU, LSTM
目标 这个阶段会给cute-dl添加循环层,使之能够支持RNN--循环神经网络. 具体目标包括: 添加激活函数sigmoid, tanh. 添加GRU(Gate Recurrent U ...
- 吴裕雄--天生自然神经网络与深度学习实战Python+Keras+TensorFlow:LSTM网络层详解及其应用
from keras.layers import LSTM model = Sequential() model.add(embedding_layer) model.add(LSTM(32)) #当 ...
- NLP+词法系列(二)︱中文分词技术简述、深度学习分词实践(CIPS2016、超多案例)
摘录自:CIPS2016 中文信息处理报告<第一章 词法和句法分析研究进展.现状及趋势>P4 CIPS2016 中文信息处理报告下载链接:http://cips-upload.bj.bce ...
随机推荐
- [java] 虚拟机(JVM)底层结构详解[转]
本文来自:曹胜欢博客专栏.转载请注明出处:http://blog.csdn.net/csh624366188 在以前的博客里面,我们介绍了在java领域中大部分的知识点,从最基础的java最基本语法到 ...
- HDU 5839 Special Tetrahedron 计算几何
Special Tetrahedron 题目连接: http://acm.hdu.edu.cn/showproblem.php?pid=5839 Description Given n points ...
- CocoaPods第三方库管理工具
http://code4app.com/article/cocoapods-install-usage
- java判断集合是否重复的一种便捷方法
内容来自其它网站,感谢原作者! import java.util.ArrayList; import java.util.HashSet; import java.util.List; /** * 通 ...
- OpenVPN的ipp.txt为空不生效的问题
1.ipp.txt是分配固定IP使用的,但在tun模式下里面的ip地址不是写使用着的IP,而是30位子网中没有列举出来的启动一位,比如我要给客户机分配为10.8.0.6的IP,那么它这个文件填写的是1 ...
- jquery json 格式教程
介绍 我们知道AJAX技术能够使得每一次请求更加迅捷,对于每一次请求返回的不是整个页面,也仅仅是所需要返回的数据.通常AJAX通过返回XML格式的数据,然后再通过客户端复杂的JavaScript脚本解 ...
- Revit API单位转换类
用法:txt.Text=UnitConvertC.CovertFromAPI(param.AsDouble());param.Set(UnitConvertC.CovertToAPI(txt.Text ...
- MySQL客户端输出窗口显示中文乱码问题解决办法
最近发现,在MySQL的dos客户端输出窗口中查询表中的数据时,表中的中文数据都显示成乱码,如下图所示:
- ListBox使用
一.什么是ListBox? ListBox 是一个显示项集合的控件.一次可以显示 ListBox 中的多个项. ListBox继承自ItemsControl,可以使用Items或者ItemsSourc ...
- eclipse中设置自定义文档签名(工具)
今天第一次认真学习eclipse的使用,看到自定义文档签名,步骤如下: 1.点击window->preferences->java->Code Style->Code Tem ...