吴裕雄 实战PYTHON编程(8)
import pandas as pd
df = pd.DataFrame( {"林大明":[65,92,78,83,70], "陈聪明":[90,72,76,93,56], "黄美丽":[81,85,91,89,77], "熊小娟":[79,53,47,94,80] } )
print(df)
import pandas as pd
datas = [[65,92,78,83,70], [90,72,76,93,56], [81,85,91,89,77], [79,53,47,94,80]]
indexs = ["林大明", "陈聪明", "黄美丽", "熊小娟"]
columns = ["语文", "数学", "英文", "自然", "社会"]
df = pd.DataFrame(datas, columns=columns, index=indexs)
print(df)
import pandas as pd
datas = [[65,92,78,83,70], [90,72,76,93,56], [81,85,91,89,77], [79,53,47,94,80]]
indexs = ["林大明", "陈聪明", "黄美丽", "熊小娟"]
columns = ["语文", "数学", "英文", "自然", "社会"]
df = pd.DataFrame(datas, columns=columns, index=indexs)
indexs[0] = "林晶辉"
df.index = indexs
columns[3] = "理化"
df.columns = columns
print(df)

import pandas as pd
datas = [[65,92,78,83,70], [90,72,76,93,56], [81,85,91,89,77], [79,53,47,94,80]]
indexs = ["林大明", "陈聪明", "黄美丽", "熊小娟"]
columns = ["语文", "数学", "英文", "自然", "社会"]
df = pd.DataFrame(datas, columns=columns, index=indexs)
print('df["自然"] ->')
print(df["自然"])
print()
print('df[["语文", "数学", "自然"] ->')
print(df[["语文", "数学", "自然"]])
print()
print('df[df.数学>=80] ->')
print(df[df.数学 >= 80])

import pandas as pd
datas = [[65,92,78,83,70], [90,72,76,93,56], [81,85,91,89,77], [79,53,47,94,80]]
indexs = ["林大明", "陈聪明", "黄美丽", "熊小娟"]
columns = ["语文", "数学", "英文", "自然", "社会"]
df = pd.DataFrame(datas, columns=columns, index=indexs)
print("df.values:")
print(df.values)
print("陈聪明的成绩(df.values[1]):")
print(df.values[1])
print("陈聪明的英文成绩(df.values[1][2]):")
print(df.values[1][2])

import pandas as pd
datas = [[65,92,78,83,70], [90,72,76,93,56], [81,85,91,89,77], [79,53,47,94,80]]
indexs = ["林大明", "陈聪明", "黄美丽", "熊小娟"]
columns = ["语文", "数学", "英文", "自然", "社会"]
df = pd.DataFrame(datas, columns=columns, index=indexs)
print(df)
print('df.loc["陈聪明", :] ->')
print(df.loc["陈聪明", :])
#print(df.loc["陈聪明"])
print()
print('df.loc["陈聪明"]["数学"] ->')
print(df.loc["陈聪明"]["数学"])
print()
print('df.loc[("陈聪明", "熊小娟") ->')
print(df.loc[("陈聪明", "熊小娟"), :])
print()
print('df.loc[:, "数学"] ->')
print(df.loc[:, "数学"])
print()
print('df.loc[("陈聪明", "熊小娟"), ("数学", "自然")] ->')
print(df.loc[("陈聪明", "熊小娟"), ("数学", "自然")])
print()
print('df.loc["陈聪明":"熊小娟", "数学":"社会"] ->')
print(df.loc["陈聪明":"熊小娟", "数学":"社会"])
print()
print('df.loc[:黄美丽, "数学":"社会"] ->')
print(df.loc[:"黄美丽", "数学":"社会"])
print()
print('df.loc["陈聪明":, "数学":"社会"] ->')
print(df.loc["陈聪明":, "数学":"社会"])

import pandas as pd
datas = [[65,92,78,83,70], [90,72,76,93,56], [81,85,91,89,77], [79,53,47,94,80]]
indexs = ["林大明", "陈聪明", "黄美丽", "熊小娟"]
columns = ["语文", "数学", "英文", "自然", "社会"]
df = pd.DataFrame(datas, columns=columns, index=indexs)
print(df)
print('df.iloc[1, :] ->')
print(df.iloc[1, :])
print()
print('df.iloc[1][1] ->')
print(df.iloc[1][1])

import pandas as pd
datas = [[65,92,78,83,70], [90,72,76,93,56], [81,85,91,89,77], [79,53,47,94,80]]
indexs = ["林大明", "陈聪明", "黄美丽", "熊小娟"]
columns = ["语文", "数学", "英文", "自然", "社会"]
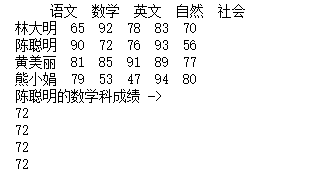
df = pd.DataFrame(datas, columns=columns, index=indexs)
print(df)
print('陈聪明的数学科成绩 ->')
print(df.ix["陈聪明"]["数学"])
print(df.ix["陈聪明"][1])
print(df.ix[1]["数学"])
print(df.ix[1][1])
import pandas as pd
datas = [[65,92,78,83,70], [90,72,76,93,56], [81,85,91,89,77], [79,53,47,94,80]]
indexs = ["林大明", "陈聪明", "黄美丽", "熊小娟"]
columns = ["语文", "数学", "英文", "自然", "社会"]
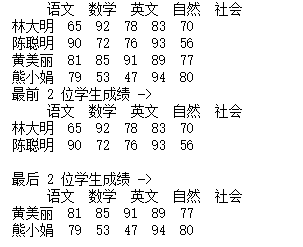
df = pd.DataFrame(datas, columns=columns, index=indexs)
print(df)
print('最前 2 位学生成绩 ->')
print(df.head(2))
print()
print('最后 2 位学生成绩 ->')
print(df.tail(2))
import pandas as pd
datas = [[65,92,78,83,70], [90,72,76,93,56], [81,85,91,89,77], [79,53,47,94,80]]
indexs = ["林大明", "陈聪明", "黄美丽", "熊小娟"]
columns = ["语文", "数学", "英文", "自然", "社会"]
df = pd.DataFrame(datas, columns=columns, index=indexs)
print(df)
print('df.ix["陈聪明"]["数学"] (原始):' + str(df.loc["陈聪明"]["数学"]))
df.ix["陈聪明"]["数学"] = 91
print('df.ix["陈聪明"]["数学"] (修改):' + str(df.loc["陈聪明"]["数学"]))
print()
print('df.ix["陈聪明", :] ->')
df.ix["陈聪明", :] = 80
print(df.ix["陈聪明", :])

import pandas as pd
datas = [[65,92,78,83,70], [90,72,76,93,56], [81,85,91,89,77], [79,53,47,94,80]]
indexs = ["林大明", "陈聪明", "黄美丽", "熊小娟"]
columns = ["语文", "数学", "英文", "自然", "社会"]
df = pd.DataFrame(datas, columns=columns, index=indexs)
print(df)
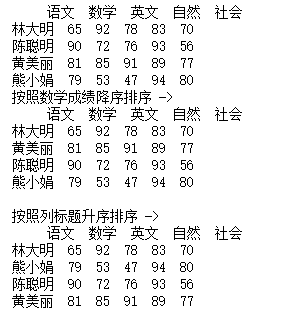
print('按照数学成绩降序排序 ->')
df1 = df.sort_values(by="数学", ascending=False)
print(df1)
print()
print('按照列标题升序排序 ->')
df2 = df.sort_index(axis=0)
print(df2)
print()
import pandas as pd
datas = [[65,92,78,83,70], [90,72,76,93,56], [81,85,91,89,77], [79,53,47,94,80]]
indexs = ["林大明", "陈聪明", "黄美丽", "熊小娟"]
columns = ["语文", "数学", "英文", "自然", "社会"]
df = pd.DataFrame(datas, columns=columns, index=indexs)
print(df)
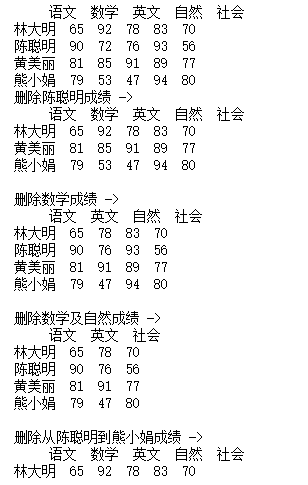
print('删除陈聪明成绩 ->')
df1 = df.drop("陈聪明")
print(df1)
print()
print('删除数学成绩 ->')
df2 = df.drop("数学", axis=1)
print(df2)
print()
print('删除数学及自然成绩 ->')
df3 = df.drop(["数学", "自然"], axis=1)
print(df3)
print()
print('删除从陈聪明到熊小娟成绩 ->')
df4 = df.drop(df.index[1:4])
print(df4)
print()
print('删除从数学到自然的成绩 ->')
df5 = df.drop(df.columns[1:4], axis=1)
print(df5)
print()
import pandas as pd
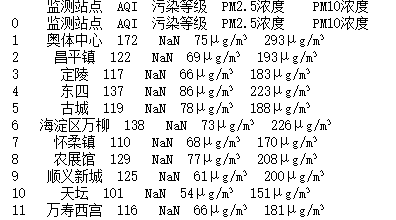
dt = pd.read_html("http://www.86pm25.com/city/beijing.html")
data=dt[0]
print(data)
import pandas as pd
tables = pd.read_html("http://value500.com/M2GDP.html")
n = 1
for table in tables:
print("第 " + str(n) + " 个表格:")
print(table.head())
print()
n += 1
import pandas as pd
tables = pd.read_html("http://value500.com/M2GDP.html")
table = tables[18]
table = table.drop(table.index[0:1])
table.columns = ["年份", "M2指标", "GDP绝对额", "M2/GDP"]
table.index = range(len(table.index))
print(table)
import pandas as pd
from pylab import *
rcParams['font.sans-serif'] = ['SimHei'] #设置中文显示
datas = [[65,92,78,83,70], [90,72,76,93,56], [81,85,91,89,77], [79,53,47,94,80]]
indexs = ["林大明", "陈聪明", "黄美丽", "熊小娟"]
columns = ["语文", "数学", "英文", "自然", "社会"]
df = pd.DataFrame(datas, columns=columns, index=indexs)
df.plot()

def rbCity(): #单击区县按钮的处理函数
global sitelist, listradio
sitelist.clear() #清除原有监测站点列表
for r in listradio: #删除原有监测站点按钮
r.destroy()
n=0
for c1 in data["监测站点"]: #逐一取出所选区县市的监测站点
if(c1 == city.get()):
sitelist.append(data.ix[n, 1])
n += 1
sitemake() #生成测站点按钮
rbSite() #显示PM2.5数值
def rbSite(): #单击监测站按钮后的处理函数
n = 0
for s in data.ix[:,1]: #逐一取得监测站点
if(s == site.get()): #如果某监测站点名称与选中的监测站点相同,则
pm = data.ix[n][ "PM2.5浓度"] #取得该站点的PM2.5数值
print(pm)
pm=pm[:-5] #去除数据后面的5位单位字符
pm=int(pm) #把PM2.5的字符型数据转为整型
if(pd.isnull(pm)): #如果没有数据,则
result1.set(s + "站的 PM2.5 值当前无数据!") #显示无数据
else: #如果有数据,则
if(pm <= 35): #转换为空气质量等级
grade1 = "优秀"
elif(pm <= 53):
grade1 = "良好"
elif(pm <= 70):
grade1 = "中等"
else:
grade1 = "差"
result1.set(s + "站的 PM2.5 值为" + str(pm) + ";" + grade1 )
break #找到选中的监测站点的数据后就跳出循环
n += 1
def clickRefresh(): #重新读取数据
global data
df = pd.read_html("http://www.86pm25.com/city/beijing.html")
data=df[0]
rbSite() #更新监测站点的数据
def sitemake(): #建立监测站点按钮
global sitelist, listradio
for c1 in sitelist: #逐一建立按钮
rbtem = tk.Radiobutton(frame2, text=c1, variable=site, value=c1, command=rbSite) #建立单选按钮
listradio.append(rbtem) #插入至按钮列表
if(c1==sitelist[0]): #默认选取第1个按钮
rbtem.select()
rbtem.pack(side="left") #靠左对齐
import tkinter as tk
import pandas as pd
df = pd.read_html("http://www.86pm25.com/city/beijing.html")
data=df[0]
win=tk.Tk()
win.geometry("640x270")
win.title("PM2.5 实时监测")
city = tk.StringVar() #区县名称变量
site = tk.StringVar() #监测站点名称变量
result1 = tk.StringVar() #显示信息变量
citylist = [] #区县列表
sitelist = [] #监测站点列表
listradio = [] #区县按钮列表
#建立区县列表
for c1 in data["监测站点"]:
if(c1 not in citylist): #如果列表中不存在该县区就将该县区名称插入列表
citylist.append(c1)
#建立第1个区县的监测站点列表
count = 0
for c1 in data["监测站点"]:
if(c1 == citylist[0]): #如果是第1个区县,则
sitelist.append(data.ix[count, 1]) #把该区县的所有监测站点插入到监测站点列表
count += 1
label1 = tk.Label(win, text="区县:", pady=6, fg="blue", font=("新细明体", 12))
label1.pack()
frame1 = tk.Frame(win) #区县容器
frame1.pack()
for i in range(0,2): #按钮分2行
for j in range(0,8): #每行8个
n = i * 8 + j #第n个按钮
if(n < len(citylist)):
city1 = citylist[n] #取得区县名称
rbtem = tk.Radiobutton(frame1, text=city1, variable=city, value=city1, command=rbCity) #建立单选按钮
rbtem.grid(row=i, column=j) #设置按钮的位置
if(n==0): #选取第1个区县
rbtem.select()
label2 = tk.Label(win, text="监测站点:", pady=6, fg="blue", font=("新细明体", 12))
label2.pack()
frame2 = tk.Frame(win) #监测站点容器
frame2.pack()
sitemake()
btnDown = tk.Button(win, text="更新数据", font=("新细明体", 12), command=clickRefresh)
btnDown.pack(pady=6)
lblResult1 = tk.Label(win, textvariable=result1, fg="red", font=("新细明体", 16))
lblResult1.pack(pady=6)
rbSite() #显示测站讯息
win.mainloop()
def rbCity(): #點選縣市選項按鈕後處理函式
global sitelist, listradio
sitelist.clear() #清除原有測站串列
for r in listradio: #移除原有測站選項按鈕
r.destroy()
n=0
for c1 in data["County"] == city.get(): #逐一取出選取縣市的測站
if(c1 == True):
sitelist.append(data.ix[n, 0])
n += 1
sitemake() #建立測站選項按鈕
rbSite() #顯示PM2.5訊息
def rbSite(): #點選測站選項按鈕後處理函式
n = 0
for s in data.ix[:, 0]: #逐一取得測站
if(s == site.get()): #取得點選的測站
pm = data.ix[n, "PM2.5"] #取得PM2.5的值
if(pd.isnull(pm)): #如果沒有資料
result1.set(s + "站的 PM2.5 值目前無資料!")
else: #如果有資料
if(pm <= 35): #轉換為等級
grade1 = "低"
elif(pm <= 53):
grade1 = "中"
elif(pm <= 70):
grade1 = "高"
else:
grade1 = "非常高"
result1.set(s + "站的 PM2.5 值為「" + str(pm) + "」:「" + grade1 + "」等級")
break #找到點選測站就離開迴圈
n += 1
def clickRefresh(): #重新讀取資料
global data
# data = pd.read_csv("http://opendata.epa.gov.tw/ws/Data/REWXQA/?$orderby=SiteName&$skip=0&$top=1000&format=csv")
data = pd.read_csv("F:\\pythonBase\\pythonex\\ch09\\AQX_20160927145712.csv")
rbSite() #更新測站資料
def sitemake(): #建立測站選項按鈕
global sitelist, listradio
for c1 in sitelist: #逐一建立選項按鈕
rbtem = tk.Radiobutton(frame2, text=c1, variable=site, value=c1, command=rbSite) #建立選項按鈕
listradio.append(rbtem) #加入選項按鈕串列
if(c1==sitelist[0]): #預設選取第1個項目
rbtem.select()
rbtem.pack(side="left") #靠左排列
import tkinter as tk
import pandas as pd
# data = pd.read_csv("http://opendata.epa.gov.tw/ws/Data/REWXQA/?$orderby=SiteName&$skip=0&$top=1000&format=csv")
data = pd.read_csv("F:\\pythonBase\\pythonex\\ch09\\AQX_20160927145712.csv")
win=tk.Tk()
win.geometry("640x270")
win.title("PM2.5 實時監測")
city = tk.StringVar() #縣市文字變數
site = tk.StringVar() #測站文字變數
result1 = tk.StringVar() #訊息文字變數
citylist = [] #縣市串列
sitelist = [] #鄉鎮串列
listradio = [] #鄉鎮選項按鈕串列
#建立縣市串列
for c1 in data["County"]:
if(c1 not in citylist): #如果串列中無該縣市就將其加入
citylist.append(c1)
#建立第1個縣市的測站串列
count = 0
for c1 in data["County"]:
if(c1 == citylist[0]): #是第1個縣市的測站
sitelist.append(data.ix[count, 0])
count += 1
label1 = tk.Label(win, text="縣市:", pady=6, fg="blue", font=("新細明體", 12))
label1.pack()
frame1 = tk.Frame(win) #縣市容器
frame1.pack()
for i in range(0,3): #3列選項按鈕
for j in range(0,8): #每列8個選項按鈕
n = i * 8 + j #第n個選項按鈕
if(n < len(citylist)):
city1 = citylist[n] #取得縣市名稱
rbtem = tk.Radiobutton(frame1, text=city1, variable=city, value=city1, command=rbCity) #建立選項按鈕
rbtem.grid(row=i, column=j) #設定選項按鈕位置
if(n==0): #選取第1個縣市
rbtem.select()
label2 = tk.Label(win, text="測站:", pady=6, fg="blue", font=("新細明體", 12))
label2.pack()
frame2 = tk.Frame(win) #測站容器
frame2.pack()
sitemake()
btnDown = tk.Button(win, text="更新資料", font=("新細明體", 12), command=clickRefresh)
btnDown.pack(pady=6)
lblResult1 = tk.Label(win, textvariable=result1, fg="red", font=("新細明體", 16))
lblResult1.pack(pady=6)
rbSite() #顯示測站訊息
win.mainloop()
吴裕雄 实战PYTHON编程(8)的更多相关文章
- 吴裕雄 实战PYTHON编程(10)
import cv2 cv2.namedWindow("frame")cap = cv2.VideoCapture(0)while(cap.isOpened()): ret, im ...
- 吴裕雄 实战PYTHON编程(9)
import cv2 cv2.namedWindow("ShowImage1")cv2.namedWindow("ShowImage2")image1 = cv ...
- 吴裕雄 实战PYTHON编程(7)
import os from win32com import client word = client.gencache.EnsureDispatch('Word.Application')word. ...
- 吴裕雄 实战PYTHON编程(6)
import matplotlib.pyplot as plt plt.rcParams['font.sans-serif']=['Simhei']plt.rcParams['axes.unicode ...
- 吴裕雄 实战PYTHON编程(5)
text = '中华'print(type(text))#<class 'str'>text1 = text.encode('gbk')print(type(text1))#<cla ...
- 吴裕雄 实战PYTHON编程(4)
import hashlib md5 = hashlib.md5()md5.update(b'Test String')print(md5.hexdigest()) import hashlib md ...
- 吴裕雄 实战python编程(3)
import requests from bs4 import BeautifulSoup url = 'http://www.baidu.com'html = requests.get(url)sp ...
- 吴裕雄 实战python编程(2)
from urllib.parse import urlparse url = 'http://www.pm25x.com/city/beijing.htm'o = urlparse(url)prin ...
- 吴裕雄 实战python编程(1)
import sqlite3 conn = sqlite3.connect('E:\\test.sqlite') # 建立数据库联接cursor = conn.cursor() # 建立 cursor ...
随机推荐
- 【转】ORACLE Dataguard安装
ORACLE Dataguard安装 标签: oracledatabasearchivesql数据库list 2011-08-01 09:40 5548人阅读 评论(1) 收藏 举报 分类: ORA ...
- Linux下Oracle中SqlPlus时上下左右键乱码问题的解决办法
window下的sqlplus可以通过箭头键,来回看历史命令,用起来非常的方便. 但是在Linux下,会出现各种乱码,非常不方便,如下图所示,每次打错一个字符就需要重新打一遍. 解决办法:rlwrap ...
- 关于innodb_thread_concurrency参数 并发控制
http://dev.mysql.com/doc/refman/5.5/en/innodb-parameters.html#sysvar_innodb_thread_concurrency Comma ...
- c#中如何获取本机MAC地址、IP地址、硬盘ID、CPU序列号等系统信息
我们在利用C#开发桌面程序(Winform)程序的时候,经常需要获取一些跟系统相关的信息,例如用户名.MAC地址.IP地址.硬盘ID.CPU序列号.系统名称.物理内存等. 首先需要引入命名空间: us ...
- 关于分布式锁Java常用技术方案
前言: 由于在平时的工作中,线上服务器是分布式多台部署的,经常会面临解决分布式场景下数据一致性的问题,那么就要利用分布式锁来解决这些问题. 所以自己结合实际工作中的一些经验和网上 ...
- ALGO-2_蓝桥杯_算法训练_最大最小公倍数
问题描述 已知一个正整数N,问从1~N中任选出三个数,他们的最小公倍数最大可以为多少. 输入格式 输入一个正整数N. 输出格式 输出一个整数,表示你找到的最小公倍数. 样例输入 样例输出 数据规模与约 ...
- Qt中路径问题小结
转载:奋斗Andy 在做Qt项目的时候,我们难免遇到到文件路径问题. 如QFile file("text.txt")加载不成功.QPixmap("../text.png& ...
- 利用spring的ApplicationListener实现springmvc容器的初始化加载--转
1.我们在使用springmvc进行配置的时候一般初始化都是在web.xml里面进行的,但是自己在使用的时候经常会测试一些数据,这样就只有加载spring-mvc.xml的配置文件来实现.为了更方便的 ...
- 实验十一 C的指针
指针编程 11.1 #include<stdio.h> int main() { ]={,,,,,,,,,},i,*p,sum=; ],i=;i<;i++,p++) { ==) su ...
- Python单例模式的4种实现方法
#-*- encoding=utf-8 -*- print '----------------------方法1--------------------------' #方法1,实现__new__方法 ...