2.keras实现-->深度学习用于文本和序列
1.将文本数据预处理为有用的数据表示
- 将文本分割成单词(token),并将每一个单词转换为一个向量
- 将文本分割成单字符(token),并将每一个字符转换为一个向量
- 提取单词或字符的n-gram(token),并将每个n-gram转换为一个向量。n-gram是多个连续单词或字符的集合
将向量与标记相关联的方法有:one-hot编码与标记嵌入(token embedding)
具体见https://www.cnblogs.com/nxf-rabbit75/p/9970320.html
2.使用循环神经网络
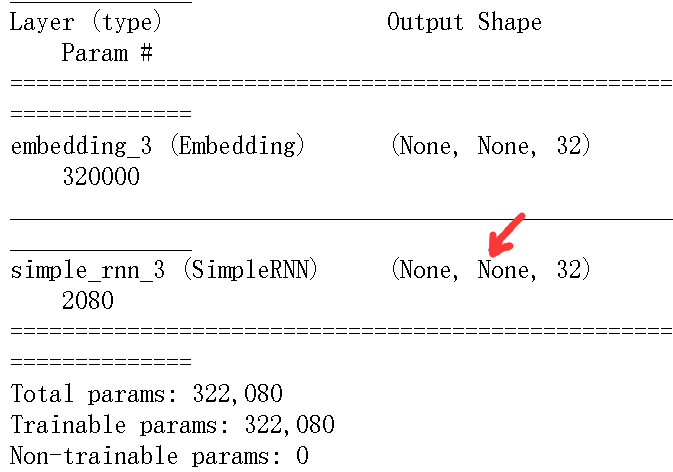
(1)simpleRNNsimpleRNN可以在两种不同的模式下运行,这两种模式由return_sequences这个构造函数参数来控制 |
|
| 一种是返回每个时间步连续输出的完整序列, 其形状为(batch_size,timesteps,output_features); |
另一种是只返回每个输入序列的最终输出,其形状为(batch_size,output_features) |
# 例子1 |
#例子2:RNN返回完整的状态序列
|

|
|
我们将这个模型应用IMDB电影评论分类问题
#准备imdb数据 |
首先对数据进行预处理 25000 train sequences |
#定义模型 |

|
import matplotlib.pyplot as plt acc = history.history['acc'] |
|
|
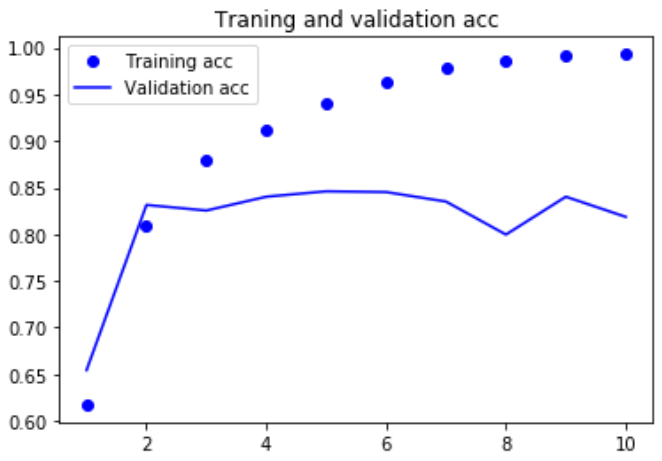
总结: 这个小型循环网络的表现并不好,问题的部分原因在于: 输入只考虑了前500个单词,而不是整个序列,因此RNN获得的信息比前面的基准模型更少。 另一部分原因在于,simpleRNN不擅长处理长序列,比如文本。 其他类型的循环层的表现要好得多,比如说LSTM层和GRU层 理论上来说,SimpleRNN应该能够记住许多时间步之前见过的信息,但实际上他是不可能学到这种长期以来的,原因在于梯度消失问题, 这一效应类似于在层数较多的非循环网络(即前馈网络),随着层数的增加,网络最终变得无法训练。 LSTM和GRU都是为了解决这个问题而设计的 |
|
(2)LSTM# keras实现LSTM的一个例子 |
|
|
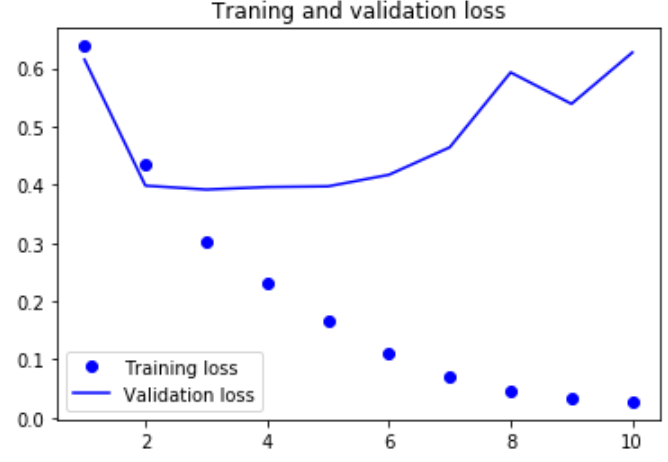
这次,验证精度达到了,比simpleRNN好多了,主要是因为LSTM受梯度消失问题的影响要小得多,这个结果也比第三章的全连接网络略好, 虽然使用的数据量比第三章少。此处在500个时间步之后将序列截断,而在第三章是读取整个序列 |
|
- 循环dropout (降低过拟合)
- 堆叠循环层 (提高网络的表示能力(代价是更高的计算负荷))
- 双向循环层 (将相同的信息以不同的方式呈现给循环网络,可以提高精度并缓解遗忘问题)
我们将使用一个天气时间序列数据集-->德国耶拿的马克思-普朗克生物地球化学研究所的气象站记录
温度预测问题数据集:每十分钟记录14个不同的量(比如气温、气压、湿度、风向等),原始数据可追溯到2003年。本例仅适用2009-2016年的数据, 这个数据集非常适合用来学习处理数值型时间序列我们将会用这个数据集来构建模型, 输入最近的一些数据(几天的数据点),可以预测24小时之后的气温。
|
|
import os |
日期+14个特征名称
一行的数据为:
|
import numpy as np float_data = np.zeros((len(lines),len(header)-1)) |

|
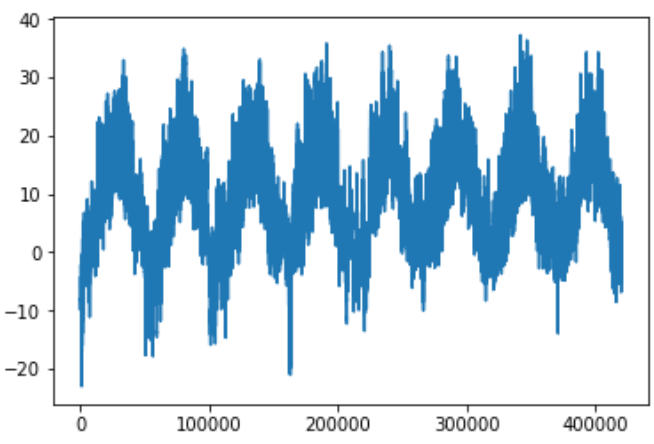
#绘制所有天的温度变化
|
|
#绘制前十天的温度时间序列
|
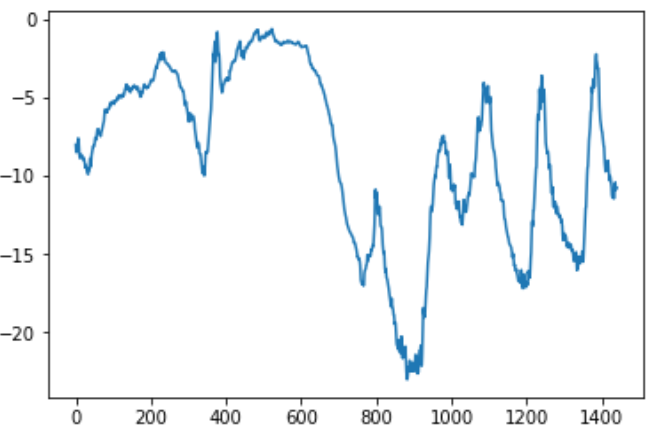
|
|
上面这张图,可以看到每天的周期性变化,尤其是最后4天特别明显。 如果想根据过去几个月的数据来预测下个月的平均温度,那么问题很简单, 因为数据具有可靠的年度周期性。 从这几天的数据来看,温度看起来更混乱一些。以天作为观察尺度,这个时间序列是可以预测的吗? |
|
|
准备数据
lookback = 720:给定过去5天内的观测数据 steps = 6:每6个时间步采样一次数据 delay = 144:目标是未来24小时之后的数据 |
float_data
|
#数据标准化 |
|
#生成时间序列样本及其目标的生成器 |
|
#准备训练生成器,验证生成器,测试生成器 |
|
#为了查看整个训练集,需要从train_gen中抽取多少次 |
1551 769 930 |



# 一种基于常识的、非机器学习的基准方法-->始终预测24小时后的温度等于现在的温度 |
|
from keras.models import Sequential |
|
|
总结 第一个全连接方法的效果并不好,但这并不意味机器学习不适用于这个问题,该方法首先将时间序列展平, 这从输入数据中删除了时间的概念。 数据本身是个序列,其中因果关系和顺序都很重要。 |
|
#对比2.循环网络GRU |

|
#使用dropout来降低过拟合
|

|
模型不再过拟合,但似乎遇到了性能瓶颈,所以我们应该考虑增加网络容量。增加网络容量直到过拟合变成主要的障碍。 只要过拟合不是太严重,那么很可能是容量不足的问题 |
|
#对比3.循环层堆叠 |
|

|
结果如上图所示,可以看出,添加一层的确对结果有所改进,但并不显著,我们可以得到两个结论:1.因为过拟合仍然不是很严重,所以可以放心的增大每层的大小, 以进一步改进验证损失,但这么做的计算成本很高 2.添加一层厚模型并没有显著改进,所以你可能发现,提高网络能力 的回报在逐渐减小 |
#对比4:逆序序列评估LSTM |

|
|
总结:模型性能与正序LSTM几乎相同,这证实了一个假设,虽然单词顺序对理解语言很重要,但使用哪种顺序不重要。 双向RNN正是利用这个想法来提高正序RNN的性能,他从两个方向查看数据,从而得到更加丰富的表示,并捕捉到仅使用正序RNN时可能忽略的一些模式 |
|
(3)Bidirectional RNN#训练并评估一个双向LSTM |
|
#训练一个双向GRU |
|
|
更多尝试
|
|
3.使用一维卷积神经网络处理序列
## 用卷积神经网络处理序列 ## 实现一维卷积神经网络 |
x_train序列长度 25000 |
#在imdb数据上训练并评估一个简单的一维卷积神经网络 |
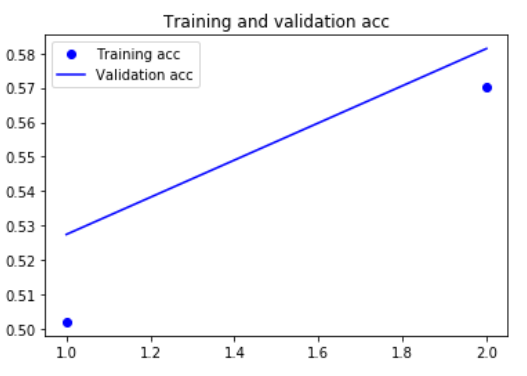
|
|
总结: 用一维卷积神经网络验证精度略低于LSTM,但在CPU和GPU上的运行速度都要更快 在单词级的情感分类任务上,一维卷积神经网络可以替代循环网络,并且速度更快、计算代价更低。 |
|
#在耶拿数据上训练并评估一个简单的一维卷积神经网络 |
验证MAE停留在0.4-0.5,使用小型卷积神经网络甚至无法击败基于尝试的基准方法。同样,这是因为卷积神经网络在输入时间序列的所有位置寻找模式,它并不知道所看到某个模式的时间位置(距开始多长时间,距结束多长时间等)。对于这个具体的预测问题,对最新数据点的解释与对较早数据点的解释应该并不相同,所以卷积神经网络无法得到有意义的结果。 卷积神经网络对IMDB数据来说并不是问题,因为对于正面情绪或负面情绪相关联的关键词模式,无论出现在输入句子中的什么位置,它所包含的信息量是一样的 |
|
要想结合卷积神经网络的速度与轻量 与 RNN的顺序敏感性,一种方法是在RNN前面使用一维神经网络作为预处理步骤。 对于那些非常长,以至于RNN无法处理的序列,这种方法尤其有用。卷积神经网络可以将长的输入序列转换为高级特征组成的更短序列(下采样) 然后,提取的特征组成的这些序列成为网络中RNN的输入。 |
|
|
在RNN前面使用一维卷积神经网络作为预处理步骤 长序列-->通过一维CNN-->更短的序列(CNN特征)->通过RNN-->输出 这里将step减半,得到时间序列的长度变为之前的两倍,温度数据的采样频率为每30分钟一个数据点 |
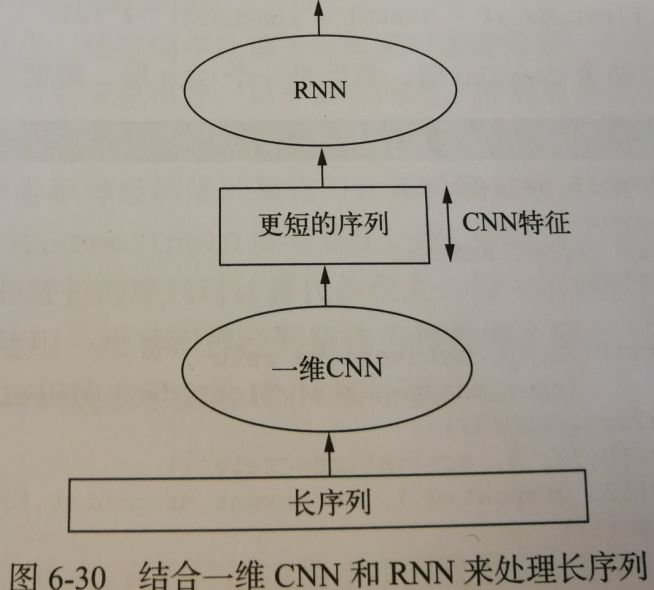
|
#准备训练生成器,验证生成器,测试生成器 |
1556 775 936 |
#结合一维CNN和GRU来处理长序列 |

从验证损失来看,这种架构的效果不如只用正则化GPU,但速度要快很多,它查看了两倍的数据量,在本例中可能不是非常有用,但对于其他数据集可能非常重要 |

2.keras实现-->深度学习用于文本和序列的更多相关文章
- AI:深度学习用于文本处理
同本文一起发布的另外一篇文章中,提到了 BlueDot 公司,这个公司致力于利用人工智能保护全球人民免受传染病的侵害,在本次疫情还没有引起强烈关注时,就提前一周发出预警,一周的时间,多么宝贵! 他们的 ...
- TensorFlow深度学习笔记 文本与序列的深度模型
Deep Models for Text and Sequence 转载请注明作者:梦里风林 Github工程地址:https://github.com/ahangchen/GDLnotes 欢迎st ...
- 万字总结Keras深度学习中文文本分类
摘要:文章将详细讲解Keras实现经典的深度学习文本分类算法,包括LSTM.BiLSTM.BiLSTM+Attention和CNN.TextCNN. 本文分享自华为云社区<Keras深度学习中文 ...
- 基于 Keras 用深度学习预测时间序列
目录 基于 Keras 用深度学习预测时间序列 问题描述 多层感知机回归 多层感知机回归结合"窗口法" 改进方向 扩展阅读 本文主要参考了 Jason Brownlee 的博文 T ...
- 【AI in 美团】深度学习在文本领域的应用
背景 近几年以深度学习技术为核心的人工智能得到广泛的关注,无论是学术界还是工业界,它们都把深度学习作为研究应用的焦点.而深度学习技术突飞猛进的发展离不开海量数据的积累.计算能力的提升和算法模型的改进. ...
- 将迁移学习用于文本分类 《 Universal Language Model Fine-tuning for Text Classification》
将迁移学习用于文本分类 < Universal Language Model Fine-tuning for Text Classification> 2018-07-27 20:07:4 ...
- 使用Keras进行深度学习:(七)GRU讲解及实践
####欢迎大家关注我们的网站和系列教程:http://www.tensorflownews.com/,学习更多的机器学习.深度学习的知识! 介绍 GRU(Gated Recurrent Unit) ...
- 使用Keras进行深度学习:(一)Keras 入门
欢迎大家关注我们的网站和系列教程:http://www.tensorflownews.com/,学习更多的机器学习.深度学习的知识! Keras是Python中以CNTK.Tensorflow或者Th ...
- [AI开发]centOS7.5上基于keras/tensorflow深度学习环境搭建
这篇文章详细介绍在centOS7.5上搭建基于keras/tensorflow的深度学习环境,该环境可用于实际生产.本人现在非常熟练linux(Ubuntu/centOS/openSUSE).wind ...
随机推荐
- webapck html-loader实现资源复用
1.安装 npm i html-loader --save-dev 2.项目目录 layout文件夹下的footer.html文件为: <script type="text/javas ...
- MySQL数据库执行sql语句创建数据库和表提示The 'InnoDB' feature is disabled; you need MySQL built with 'InnoDB' to have it working
MySQL创建数据库 只想sql文件创建表时候提示 The 'InnoDB' feature is disabled; you need MySQL built with 'InnoDB' to ha ...
- Openstack的网卡设置
本博客已经添加"打赏"功能,"打赏"位置位于右边栏红色框中,感谢您赞助的咖啡. 最开始接触Openstack,这块是比较头疼的,不同的文档,设置都会有所差异,并 ...
- Linux操作系统定时任务系统 Cron 入门
cron是一个linux下的定时执行工具,可以在无需人工干预的情况下运行作业.由于Cron 是Linux的内置服务,但它不自动起来,可以用以下的方法启动.关闭这个服务: /sbin/service c ...
- [Html5] HTML5 开发手机应用
上次周例会我给大家做了题目为:<漫游移动平台前端开发>的汇报,现在推荐一些额外的学习资料. 依照目前iPhone/Android 迅速提升市占率的情势来看,未来如果想要在 ...
- Android 模糊效果 FastBlur
import android.graphics.Bitmap; import android.graphics.Canvas; import android.graphics.Paint; impor ...
- Unity3D笔记 英保通三 脚本编写 、物体间通信
一.脚本编写 1.1.同一类型的方法JS和C#的书写方式却不一样主要还是语法,在工程中创建一个Cube 分别把JSTest.js和CSharp.cs 添加到Cube中 JSTest.js #pragm ...
- yii---对数组进行分页
很多时候,我们会对多个数据进行分页处理,例如我最近开发的一个功能,系统消息,系统消息的来源是多个表,而且多个表之间的数据没有任何关联,这个时候,需要对多个表进行查询,查询返回的数据进行分页,而且采用的 ...
- Python中常用包——sklearn主要模块和基本使用方法
在从事数据科学的人中,最常用的工具就是R和Python了,每个工具都有其利弊,但是Python在各方面都相对胜出一些,这是因为scikit-learn库实现了很多机器学习算法. 加载数据(Data L ...
- scrapy-redis的使用与解析
scrapy-redis是一个基于redis的scrapy组件,通过它可以快速实现简单分布式爬虫程序,该组件本质上提供了三大功能: scheduler - 调度器 dupefilter - URL ...