Hive 体系结构介绍
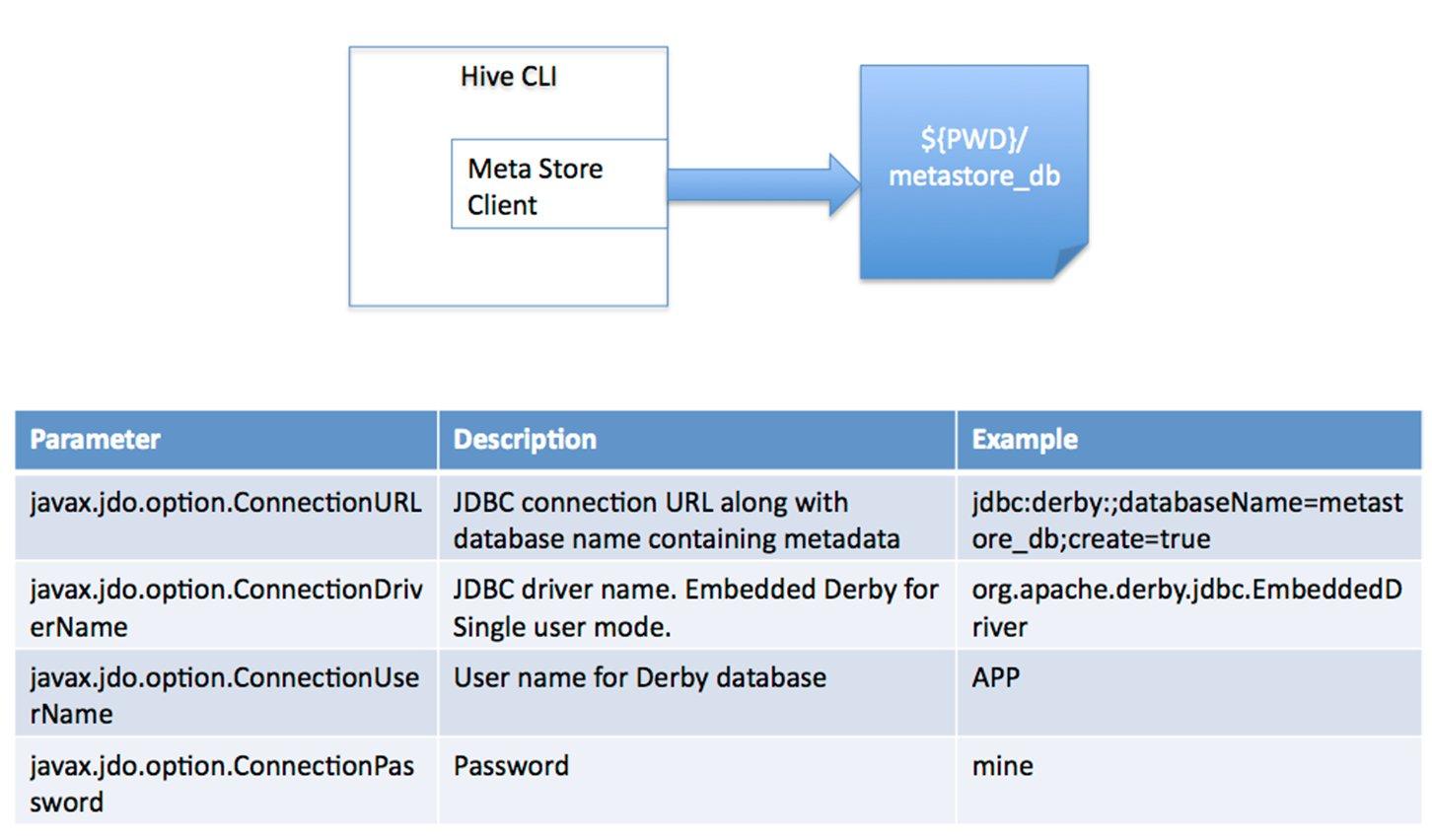
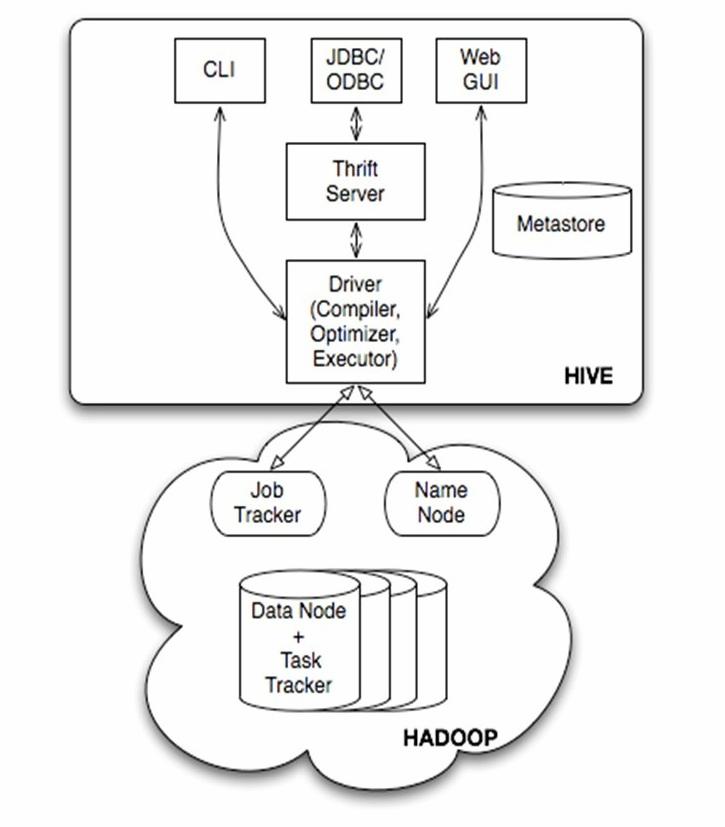

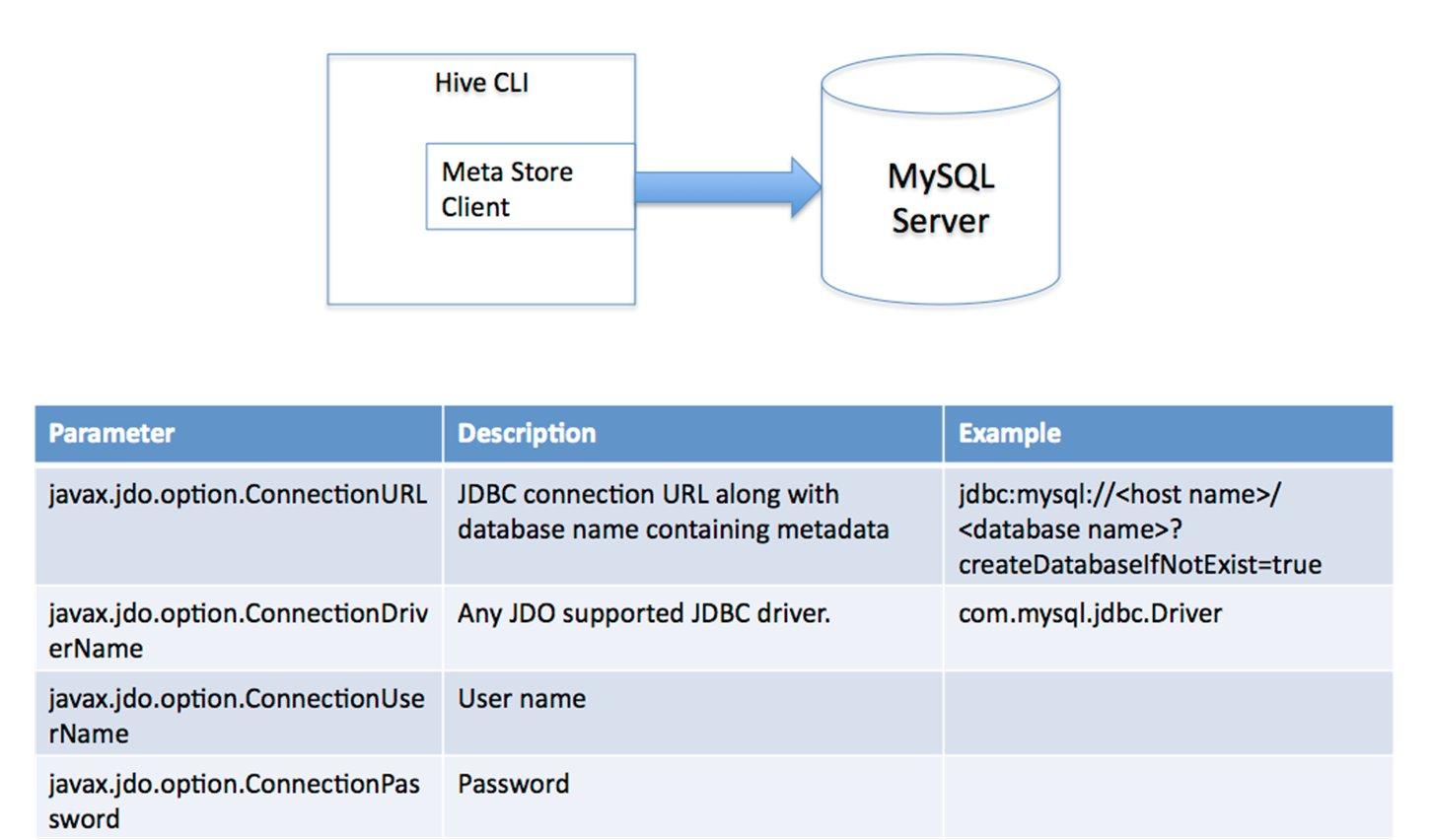
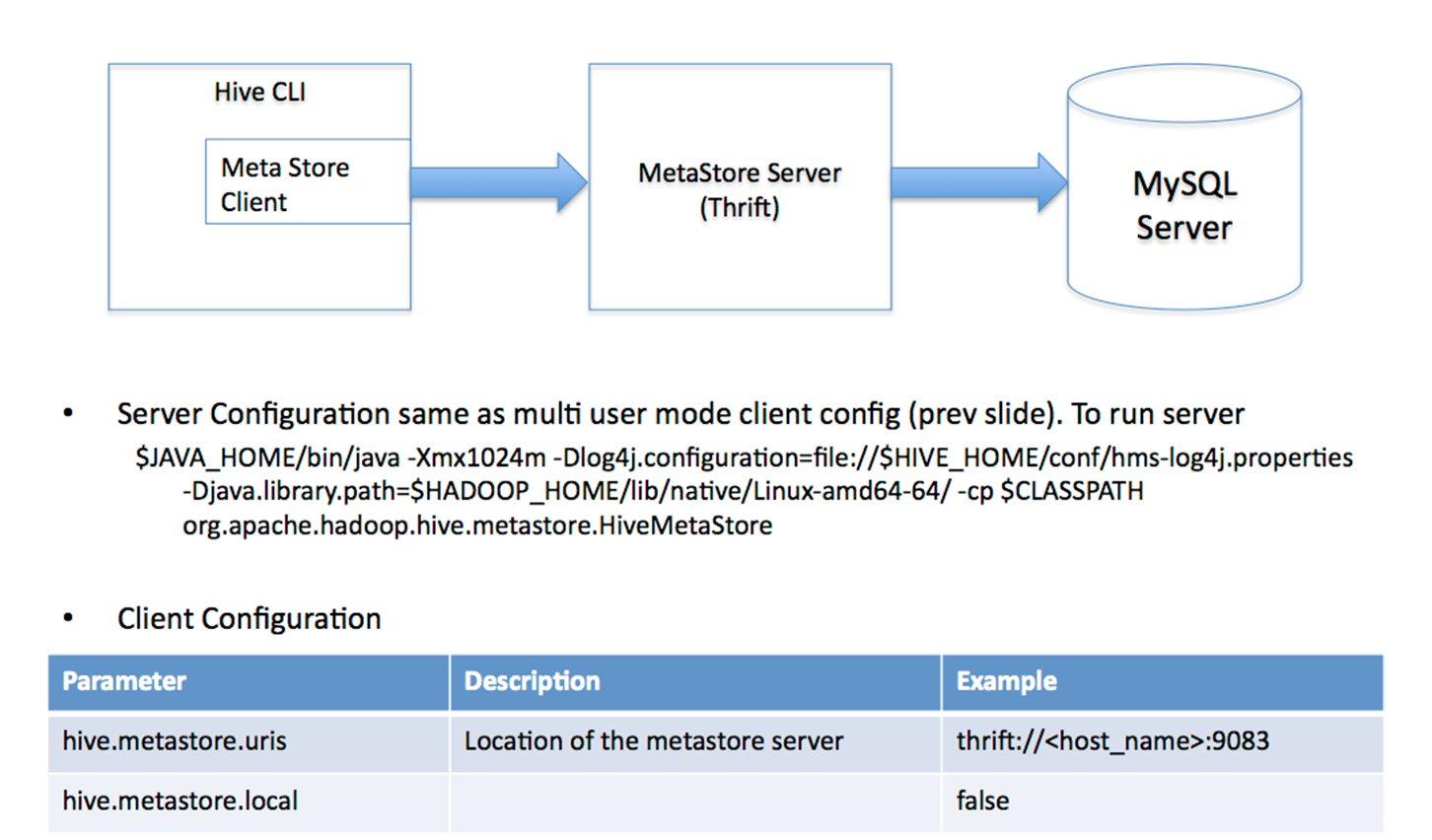
对于数据存储,Hive没有专门的数据存储格式,也没有为数据建立索引,用户可以非常自由的组织Hive中的表,只需要在创建表的时候告诉Hive数据中
的列分隔符和行分隔符,Hive就可以解析数据。Hive中所有的数据都存储在HDFS中,存储结构主要包括数据库、文件、表和视图。Hive中包含以下
数据模型:Table内部表,External
Table外部表,Partition分区,Bucket桶。Hive默认可以直接加载文本文件,还支持sequence file 、RCFile。
Hive的内部表与数据库中的Table在概念上是类似。每一个Table在Hive中都有一个相应的目录存储数据。例如一个表pvs,它在HDFS中的
路径为/wh/pvs,其中wh是在hive-site.xml中由${hive.metastore.warehouse.dir}
指定的数据仓库的目录,所有的Table数据(不包括External Table)都保存在这个目录中。删除表时,元数据与数据都会被删除。
创建数据文件:test_inner_table.txt
加载数据:LOAD DATA LOCAL INPATH ‘filepath’ INTO TABLE test_inner_table
查看数据:select * from test_inner_table; select count(*) from test_inner_table
删除表:drop table test_inner_table
外部表指向已经在HDFS中存在的数据,可以创建Partition。它和内部表在元数据的组织上是相同的,而实际数据的存储则有较大的差异。内部表的创
建过程和数据加载过程这两个过程可以分别独立完成,也可以在同一个语句中完成,在加载数据的过程中,实际数据会被移动到数据仓库目录中;之后对数据对访问
将会直接在数据仓库目录中完成。删除表时,表中的数据和元数据将会被同时删除。而外部表只有一个过程,加载数据和创建表同时完成(CREATE
EXTERNAL TABLE ……LOCATION),实际数据是存储在LOCATION后面指定的 HDFS
路径中,并不会移动到数据仓库目录中。当删除一个External Table时,仅删除该链接。
外部表简单示例:
创建数据文件:test_external_table.txt
创建表:create external table test_external_table (key string)
加载数据:LOAD DATA INPATH ‘filepath’ INTO TABLE test_inner_table
查看数据:select * from test_external_table; •select count(*) from test_external_table
删除表:drop table test_external_table
Partition对应于数据库中的Partition列的密集索引,但是Hive中Partition的组织方式和数据库中的很不相同。在Hive中,
表中的一个Partition对应于表下的一个目录,所有的Partition的数据都存储在对应的目录中。例如pvs表中包含ds和city两个
Partition,则对应于ds = 20090801, ctry = US
的HDFS子目录为/wh/pvs/ds=20090801/ctry=US;对应于 ds = 20090801, ctry = CA
的HDFS子目录为/wh/pvs/ds=20090801/ctry=CA。
创建数据文件:test_partition_table.txt
创建表:create table test_partition_table (key string) partitioned by (dt string)
加载数据:LOAD DATA INPATH ‘filepath’ INTO TABLE test_partition_table partition (dt=‘2006’)
查看数据:select * from test_partition_table; select count(*) from test_partition_table
删除表:drop table test_partition_table
Buckets是将表的列通过Hash算法进一步分解成不同的文件存储。它对指定列计算hash,根据hash值切分数据,目的是为了并行,每一个
Bucket对应一个文件。例如将user列分散至32个bucket,首先对user列的值计算hash,对应hash值为0的HDFS目录为/wh
/pvs/ds=20090801/ctry=US/part-00000;hash值为20的HDFS目录为/wh/pvs/ds=20090801
/ctry=US/part-00020。如果想应用很多的Map任务这样是不错的选择。
创建数据文件:test_bucket_table.txt
创建表:create table test_bucket_table (key string) clustered by (key) into 20 buckets
加载数据:LOAD DATA INPATH ‘filepath’ INTO TABLE test_bucket_table
查看数据:select * from test_bucket_table; set hive.enforce.bucketing = true;
示例:create view test_view as select * from test
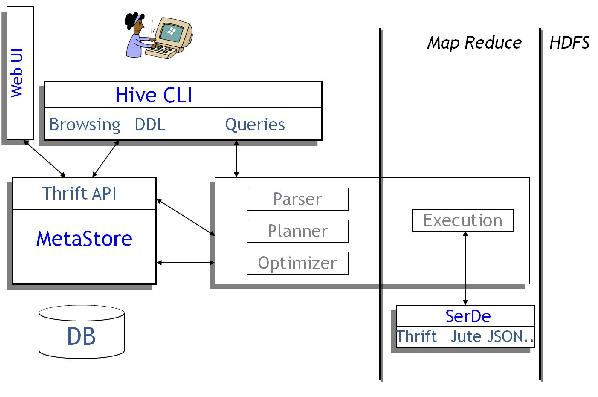
(1)HQL中对查询语句的解释、优化、生成查询计划是由Hive完成的
(2)所有的数据都是存储在Hadoop中
(3)查询计划被转化为MapReduce任务,在Hadoop中执行(有些查询没有MR任务,如:select * from table)
(4)Hadoop和Hive都是用UTF-8编码的
protected List <Operator<? extends Serializable >> childOperators;
protected List <Operator<? extends Serializable >> parentOperators;
protected boolean done; // 初始化值为false

TableScanOperator:扫描hive表数据
ReduceSinkOperator:创建将发送到Reducer端的<Key,Value>对
JoinOperator:Join两份数据
SelectOperator:选择输出列
FileSinkOperator:建立结果数据,输出至文件
FilterOperator:过滤输入数据
GroupByOperator:GroupBy语句
MapJoinOperator:/*+mapjoin(t) */
LimitOperator:Limit语句
UnionOperator:Union语句
Hive通过ExecMapper和ExecReducer执行MapReduce任务。在执行MapReduce时有两种模式,即本地模式和分布式模式 。


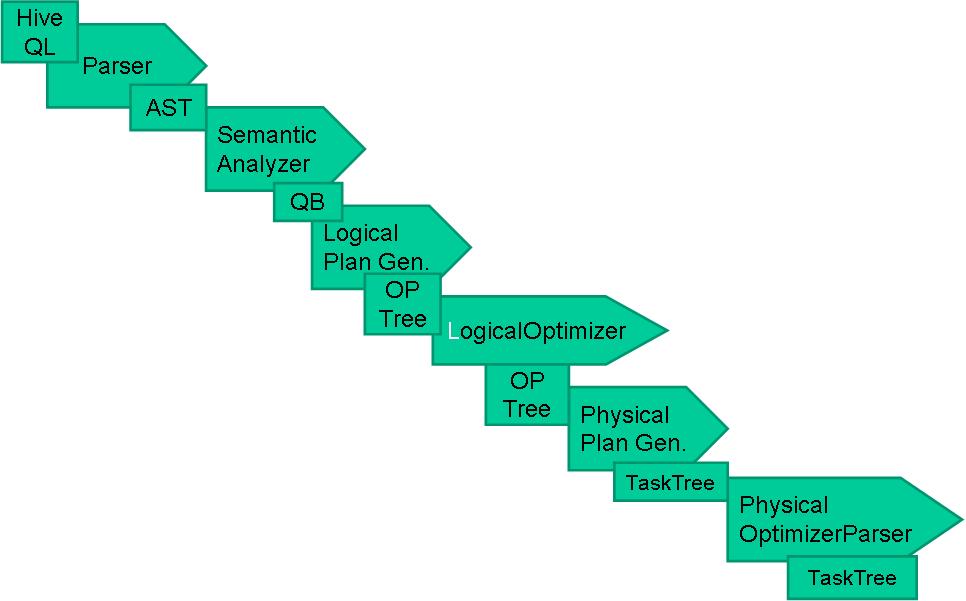
由于Hive采用了SQL的查询语言HQL,因此很容易将Hive理解为数据库。其实从结构上来看,Hive和数据库除了拥有类似的查询语言,再无类似之
处。数据库可以用在Online的应用中,但是Hive是为数据仓库而设计的,清楚这一点,有助于从应用角度理解Hive的特性。
|
Hive
|
RDBMS
|
|
|
查询语言
|
HQL
|
SQL
|
|
数据存储
|
HDFS
|
Raw Device or Local FS
|
|
数据格式
|
用户定义
|
系统决定
|
|
数据更新
|
不支持
|
支持
|
|
索引
|
无
|
有
|
|
执行
|
MapReduce
|
Executor
|
|
执行延迟
|
高
|
低
|
|
处理数据规模
|
大
|
小
|
|
可扩展性
|
高
|
低
|
(3)数据格式。Hive中没有定义专门的数据格式,数据格式可以由用户指定,用户定义数据格式需要指定三个属性:列分隔符(通常为空
格、”\t”、”\x001″)、行分隔符(”\n”)以及读取文件数据的方法(Hive中默认有三个文件格式
TextFile,SequenceFile以及RCFile)。由于在加载数据的过程中,不需要从用户数据格式到Hive定义的数据格式的转换,因此,
(4)数据更新。由于Hive是针对数据仓库应用设计的,而数据仓库的内容是读多写少的。因此,Hive中不支持对数据的改写和添加,所有的数据都
是在加载的时候中确定好的。而数据库中的数据通常是需要经常进行修改的,因此可以使用INSERT INTO ...
VALUES添加数据,使用UPDATE ... SET修改数据。
(5)索引。之前已经说过,Hive在加载数据的过程中不会对数据进行任何处理,甚至不会对数据进行扫描,因此也没有对数据中的某些Key建立索
引。Hive要访问数据中满足条件的特定值时,需要暴力扫描整个数据,因此访问延迟较高。由于MapReduce的引入,
Hive可以并行访问数据,因此即使没有索引,对于大数据量的访问,Hive仍然可以体现出优势。数据库中,通常会针对一个或者几个列建立索引,因此对于
少量的特定条件的数据的访问,数据库可以有很高的效率,较低的延迟。由于数据的访问延迟较高,决定了Hive不适合在线数据查询。
(7)执行延迟。之前提到,Hive在查询数据的时候,由于没有索引,需要扫描整个表,因此延迟较高。另外一个导致Hive执行延迟高的因素是
MapReduce框架。由于MapReduce本身具有较高的延迟,因此在利用MapReduce执行Hive查询时,也会有较高的延迟。相对的,数据
库的执行延迟较低。当然,这个低是有条件的,即数据规模较小,当数据规模大到超过数据库的处理能力的时候,Hive的并行计算显然能体现出优势。
(8)可扩展性。由于Hive是建立在Hadoop之上的,因此Hive的可扩展性是和Hadoop的可扩展性是一致的(世界上最大的Hadoop
集群在Yahoo!,2009年的规模在4000台节点左右)。而数据库由于ACID语义的严格限制,扩展行非常有限。目前最先进的并行数据库
Oracle在理论上的扩展能力也只有100台左右。
4、Hive元数据库
启动derby数据库:/home/admin/caona/hive/build/dist/,运行startNetworkServer -h 0.0.0.0。
- <P style="TEXT-ALIGN: left; PADDING-BOTTOM: 0px; WIDOWS: 2;
TEXT-TRANSFORM: none; BACKGROUND-COLOR: rgb(255,255,255); TEXT-INDENT:
0px; MARGIN: 0px; PADDING-LEFT: 0px; PADDING-RIGHT: 0px; FONT: 14px/26px
Arial; WHITE-SPACE: normal; ORPHANS: 2; LETTER-SPACING: normal; COLOR:
rgb(0,0,0); WORD-SPACING: 0px; PADDING-TOP: 0px;
-webkit-text-size-adjust: auto; -webkit-text-stroke-width: 0px">
</P>
输入:./ij Connect 'jdbc:derby://hadoop1:1527/metastore_db;create=true';
| 表名 | 说明 | 关联键 |
| TBLS | 所有hive表的基本信息 | TBL_ID,SD_ID |
| TABLE_PARAM | 表级属性,如是否外部表,表注释等 | TBL_ID |
| COLUMNS | Hive表字段信息(字段注释,字段名,字段类型,字段序号) | SD_ID |
| SDS | 所有hive表、表分区所对应的hdfs数据目录和数据格式 | SD_ID,SERDE_ID |
| SERDE_PARAM | 序列化反序列化信息,如行分隔符、列分隔符、NULL的表示字符等 | SERDE_ID |
| PARTITIONS | Hive表分区信息 | PART_ID,SD_ID,TBL_ID |
| PARTITION_KEYS | Hive分区表分区键 | TBL_ID |
| PARTITION_KEY_VALS | Hive表分区名(键值) | PART_ID |
从上面表的内容来看,hive整个创建表的过程已经比较清楚了。
(1)解析用户提交hive语句,对其进行解析,分解为表、字段、分区等hive对象
(2)根据解析到的信息构建对应的表、字段、分区等对象,从 SEQUENCE_TABLE中获取构建对象的最新ID,与构建对象信息(名称,类型等)一同通过DAO方法写入到元数据表中去,成功后将SEQUENCE_TABLE中对应的最新ID+5。
实际上我们常见的RDBMS都是通过这种方法进行组织的,典型的如postgresql,其系统表中和hive元数据一样裸露了这些id信息
(oid,cid等),而Oracle等商业化的系统则隐藏了这些具体的ID。通过这些元数据我们可以很容易的读到数据诸如创建一个表的数据字典信息,比
如导出建表语名等。
创建内部表时,会将数据移动到数据仓库指向的路径;若创建外部表,仅记录数据所在的路径,不对数据的位置做任何改变。在删除表的时候,内部表的元数据和数
据会被一起删除,而外部表只删除元数据,不删除数据。
(3)LIKE允许用户复制现有的表结构,但是不复制数据。
(4)用户在建表的时候可以自定义SerDe或者使用自带的 SerDe ( Serialize/Deserilize
的简称,目的是用于序列化和反序列化 )。如果没有指定 ROW FORMAT 或者 ROW FORMAT
DELIMITED,将会使用自带的SerDe。在建表的时候,用户还需要为表指定列,用户在指定表的列的同时也会指定自定义的SerDe,Hive通过
SerDe确定表的具体的列的数据。
(5)如果文件数据是纯文本,可以使用STORED AS TEXTFILE。如果数据需要压缩,使用STORED AS SEQUENCE。
(6)有分区的表可以在创建的时候使用 PARTITIONED BY语句。一个表可以拥有一个或者多个分区,每一个分区单独存在一个目录下。而且,表和分区都可以对某个列进行CLUSTERED
BY操作,将若干个列放入一个桶(bucket)中。也可以利用SORT BY对数据进行排序。这样可以为特定应用提高性能。
(7)表名和列名不区分大小写,SerDe和属性名区分大小写。表和列的注释是字符串。
layer是有关系的,因为它的存储层是HDFS,插入一个数据要全表扫描,还不如用整个表的替换来的快些。Hive也不支持update的操作。数据是
以load的方式,加载到建立好的表中。数据一旦导入,则不可修改。要么drop掉整个表,要么建立新的表,导入新的数据。
SELECT `(ds|hr)?+.+` FROM sales
SELECT语句:查询数据。
join 序列中除了最后一个表的所有表的记录,
再通过最后一个表将结果序列化到文件系统。这一实现有助于在reduce端减少内存的使用量。实践中,应该把最大的那个表写在最后(否则会因为缓存浪费大
量内存)。
(5)LEFT SEMI JOIN 是 IN/EXISTS 子查询的一种更高效的实现。Hive 当前没有实现 IN/EXISTS
子查询,所以你可以用 LEFT SEMI JOIN 重写你的子查询语句。LEFT SEMI JOIN的限制是,
JOIN子句中右边的表只能在ON子句中设置过滤条件,在WHERE子句、SELECT子句或其他地方过滤都不行。
(1)字符集
Hadoop和Hive都是用UTF-8编码的,所以, 所有中文必须是UTF-8编码, 才能正常使用。
备注:中文数据load到表里面,,如果字符集不同,很有可能全是乱码需要做转码的,但是hive本身没有函数来做这个。
(2)压缩
hive.exec.compress.output 这个参数,默认是false,但是很多时候貌似要单独显式设置一遍,否则会对结果做压缩的,如果你的这个文件后面还要在hadoop下直接操作,那么就不能压缩了。
(3)count(distinct)
当前的Hive不支持在一条查询语句中有多Distinct。如果要在Hive查询语句中实现多Distinct,需要使用至少n+1条查询语句(n为
distinct的数目),前n条查询分别对n个列去重,最后一条查询语句对n个去重之后的列做Join操作,得到最终结果。
(4)JOIN
只支持等值连接
(5)DML操作
只支持INSERT/LOAD操作,无UPDATE和DELTE
(6)HAVING
不支持HAVING操作。如果需要这个功能要嵌套一个子查询用where限制
(7)子查询
Hive不支持where子句中的子查询
(8)Join中处理null值的语义区别
SQL标准中,任何对null的操作(数值比较,字符串操作等)结果都为null。Hive对null值处理的逻辑和标准基本一致,除了Join时的特殊
逻辑。这里的特殊逻辑指的是,Hive的Join中,作为Join key的字段比较,null=null是有意义的,且返回值为true。
; FAILED: Parse Error: line : cannot recognize input '<EOF>' in function specification
可以推断,Hive解析语句的时候,只要遇到分号就认为语句结束,而无论是否用引号包含起来。
解决的办法是,使用分号的八进制的ASCII码进行转义,那么上述语句应写成:
;
为什么是八进制ASCII码?我尝试用十六进制的ASCII码,但Hive会将其视为字符串处理并未转义,好像仅支持八进制,原因不详。这个规则也适用于 其他非SELECT语句,如CREATE TABLE中需要定义分隔符,那么对不可见字符做分隔符就需要用八进制的ASCII码来转义。
* 内存中的数据格式: Java Integer/String, Hadoop IntWritable/Text
* 用户提供的map/reduce脚本:不管什么语言,利用stdin/stdout传输数据
* 用户自定义函数:Substr, Trim, 1 – 1
* 用户自定义聚合函数:Sum, Average…… n – 1
| TextFile | SequenceFIle | RCFFile | |
| Data type | Text Only | Text/Binary | Text/Binary |
| Internal Storage Order | Row-based | Row-based | Column-based |
| Compression | File Based | Block Based | Block Based |
| Splitable | YES | YES | YES |
| Splitable After Compression | No | YES | YES |
CREATE TABLE mylog ( user_id BIGINT, page_url STRING, unix_time INT)
STORED AS TEXTFILE;
CREATE TABLE base64_test(col1 STRING, col2 STRING)
STORED AS
INPUTFORMAT 'org.apache.hadoop.hive.contrib.
fileformat.base64.Base64TextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.contrib.
fileformat.base64.Base64TextOutputFormat';
SerDe是Serialize/Deserilize的简称,目的是用于序列化和反序列化。序列化的格式包括:分隔符(tab、逗号、CTRL-A)、Thrift 协议
反序列化(内存内):Java Integer/String/ArrayList/HashMap、Hadoop Writable类、用户自定义类
其中,LazyObject只有在访问到列的时候才进行反序列化。 BinarySortable保留了排序的二进制格式。
当存在以下情况时,可以考虑增加新的SerDe:
* 用户有更有效的序列化磁盘数据的方法。
用户如果想为Text数据增加自定义Serde,可以参照contrib/src/java/org/apache/hadoop/hive
/contrib/serde2/RegexSerDe.java中的例子。RegexSerDe利用用户提供的正则表倒是来反序列化数据,例如:
CREATE TABLE apache_log(
host STRING,
identity STRING,
user STRING,
time STRING,
request STRING,
status STRING,
size STRING,
referer STRING,
agent STRING)
ROW FORMAT
SERDE 'org.apache.hadoop.hive.contrib.serde2.RegexSerDe'
WITH SERDEPROPERTIES
( "input.regex" = "([^ ]*) ([^ ]*) ([^ ]*) (-|\\[[^\\]]*\\])
([^ \"]*|\"[^\"]*\") (-|[0-9]*) (-|[0-9]*)(?: ([^ \"]*|\"[^\"]*\")
([^ \"]*|\"[^\"]*\"))?",
"output.format.string" $s $s $s $s $s $s $s $s $s";)
STORED AS TEXTFILE;
CREATE TABLE mythrift_table
ROW FORMAT SERDE
'org.apache.hadoop.hive.contrib.serde2.thrift.ThriftSerDe'
WITH SERDEPROPERTIES (
"serialization.class" = "com.facebook.serde.tprofiles.full",
"serialization.format" = "com.facebook.thrift.protocol.TBinaryProtocol";);
用户可以自定义Hive使用的Map/Reduce脚本,比如:
FROM (
SELECT TRANSFORM(user_id, page_url, unix_time)
USING 'page_url_to_id.py'
AS (user_id, page_id, unix_time)
FROM mylog
DISTRIBUTE BY user_id
SORT BY user_id, unix_time)
mylog2
SELECT TRANSFORM(user_id, page_id, unix_time)
USING 'my_python_session_cutter.py' AS (user_id, session_info);
Map/Reduce脚本通过stdin/stdout进行数据的读写,调试信息输出到stderr。
用户可以自定义函数对数据进行处理,例如:
<P>[sql]</P> <P>add jar build/ql/test/test-udfs.jar; CREATE TEMPORARY FUNCTION testlength AS 'org.apache.hadoop.hive.ql.udf.UDFTestLength'; SELECT testlength(src.value) FROM src; DROP TEMPORARY FUNCTION testlength;</P>
package org.apache.hadoop.hive.ql.udf;
public class UDFTestLength extends UDF {
public Integer evaluate(String s) {
if (s == null) {
return null;
}
return s.length();
}
}
* Hadoop的Writables/Text 具有较高性能。
* UDF可以被重载。
* Hive支持隐式类型转换。
* UDF支持变长的参数。
* genericUDF 提供了较好的性能(避免了反射)。
例子:
<P>[sql]</P>
), count(DISTINCT user_id) FROM mylog;</P>
UDAFCount.java代码如下:
public class UDAFCount extends UDAF {
public static class Evaluator implements UDAFEvaluator {
private int mCount;
public void init() {
mcount = 0;
}
public boolean iterate(Object o) {
if (o!=null)
mCount++;
return true;
}
public Integer terminatePartial() {
return mCount;
}
public boolean merge(Integer o) {
mCount += o;
return true;
}
public Integer terminate() {
return mCount;
}
}
Hive 体系结构介绍的更多相关文章
- Hive体系结构介绍
http://www.aboutyun.com/thread-6217-1-1.html 1.Hive架构与基本组成 下面是Hive的架构图. 图1.1 Hive体系结构 Hive ...
- Hive学习之一 《Hive的介绍和安装》
一.什么是Hive Hive是建立在 Hadoop 上的数据仓库基础构架.它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储.查询和分析存储在 Hadoop 中的大规模数据 ...
- Hive 体系结构
1.Hive架构与基本组成 下面是Hive的架构图. 图1.1 Hive体系结构 Hive的体系结构可以分为以下几部分: (1)用户接口主要有三个:CLI,Client 和 W ...
- _00017 Kafka的体系结构介绍以及Kafka入门案例(0基础案例+Java API的使用)
博文作者:妳那伊抹微笑 itdog8 地址链接 : http://www.itdog8.com(个人链接) 博客地址:http://blog.csdn.net/u012185296 博文标题:_000 ...
- HIve体系结构,hive的安装和mysql的安装,以及hive的一些简单使用
Hive体系结构: 是建立在hadoop之上的数据仓库基础架构. 和数据库相似,只不过数据库侧重于一些事务性的一些操作,比如修改,删除,查询,在数据库这块发生的比较多.数据仓库主要侧重于查询.对于相同 ...
- Hive 接口介绍(Web UI/JDBC)
Hive 接口介绍(Web UI/JDBC) 实验简介 本次实验学习 Hive 的两种接口:Web UI 以及 JDBC. 一.实验环境说明 1. 环境登录 无需密码自动登录,系统用户名shiyanl ...
- 深入Java虚拟机读书笔记第一章Java体系结构介绍
第1章 Java体系结构介绍 Java技术核心:Java虚拟机 Java:安全(先天防bug的设计.内存).健壮.平台无关.网络无关(底层结构上,对象序列化和RMI为分布式系统中各个部分共享对象提供了 ...
- 【转贴】SMP、NUMA、MPP体系结构介绍
SMP.NUMA.MPP体系结构介绍 https://www.cnblogs.com/tcicy/p/10185783.html 从系统架构来看,目前的商用服务器大体可以分为三类,即对称多处理器结构 ...
- Hive QL 介绍
小结 本次课程学习了 Hive QL 基本语法和操作. 一.实验环境说明 1. 环境登录 无需密码自动登录,系统用户名shiyanlou,密码shiyanlou 2. 环境介绍 本实验环境采用带桌面的 ...
随机推荐
- 【BZOJ3413】匹配 离线+后缀树+树状数组
[BZOJ3413]匹配 Description Input 第一行包含一个整数n(≤100000). 第二行是长度为n的由0到9组成的字符串. 第三行是一个整数m. 接下来m≤5·10行,第i行是一 ...
- mac下安装启动Mongodb
本人最近才上手mac,在使用mac上面有很多不熟悉的地方,慢慢摸索,记录下来,以供后续翻阅与参考: 在Mac下安装MongoDB方式 第一种.用浏览器或者第三方工具下载当前版本的下载地址: http: ...
- CentOS 6.8下Apache绑定多个域名的方法
如何通过设置Apache的http.conf文件,进行多个域名的绑定(假设我们要绑定的域名是discuz11.com和discuz22.com,独立IP为25.25.25.25). 域名/IP地址 域 ...
- java基础/一个类A继承了类B,那么A就叫做B的派生类或子类,B就叫基类或超类。
类重复,pulic class demo1 和class demo1 重复 无主类, 在cmd中输入命令: SET CLASSPATH=. (等号后为英文点符号),即可设置解释的路径为当前路径. 再次 ...
- FaceBook开源的词向量计算框架
fasttext是个好东西,是由facebook在2016年推出的一个训练词向量的模型.相比于之前Google的word2vec,fasttext可以解决out of vocabulary的问题.fa ...
- python字典获取最大值的键的值
有时我们需要字典中数值最大的那个键的名字,使用max(dict, key=dict.get)函数非常的方便 key_name = max(my_dict, key=my_dict.get) 获取之后你 ...
- HDU - 5961 传递 想法,bfs
题意:给你一个有向图,满足去掉方向是完全图,将其拆成PQ两个图(没有公共边),问你两图是否分别满足对于任意3个点a,b,c 若有一条边从a到b且有一条边从b到c ,则同样有一条边从a到c. 题解:观察 ...
- angularJS module里的'服务'
首先,为了举栗子,先写好如下的模型,控制器,html: html: <!DOCTYPE html> <html ng-app="serviceApp"> & ...
- 20144306《网络对抗》Web基础
1 实验内容 Web前端HTML:能正常安装.启停Apache.理解HTML,理解表单,理解GET与POST方法,编写一个含有表单的HTML. Web前端javascipt:理解JavaScript ...
- AT2043 AND Grid 构造
正解:构造 解题报告: 传送门传送门! 这题psj讲了俩做法,一个是最常见的解法,还一种还不知道484对的QAQ 然后先把psj讲的不知正确性的做法港下QwQ 大概就是说,第一个图,先把底给染完 然后 ...