Spark standalone运行模式

Spark Standalone 部署配置
Standalone架构
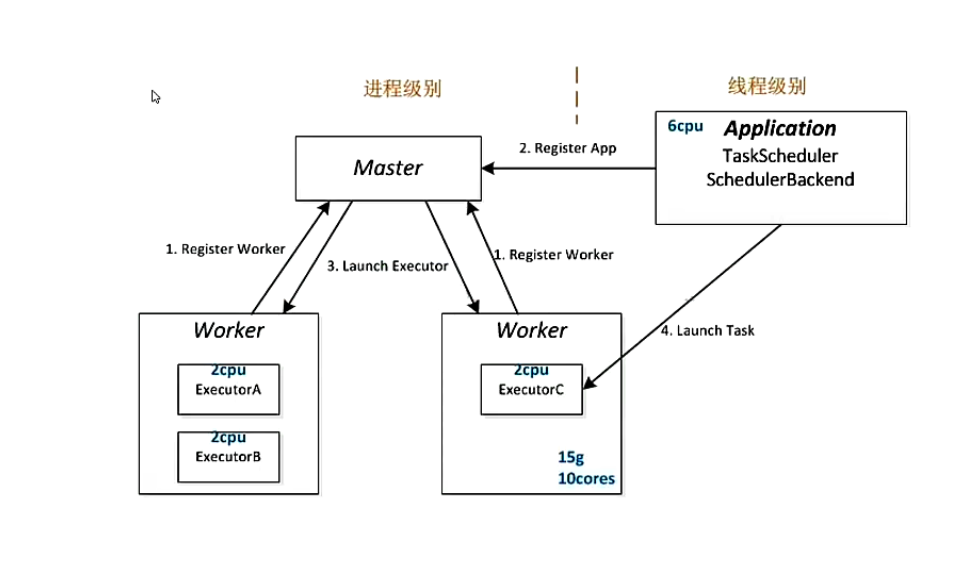
手工启动一个Spark集群
https://spark.apache.org/docs/latest/spark-standalone.html
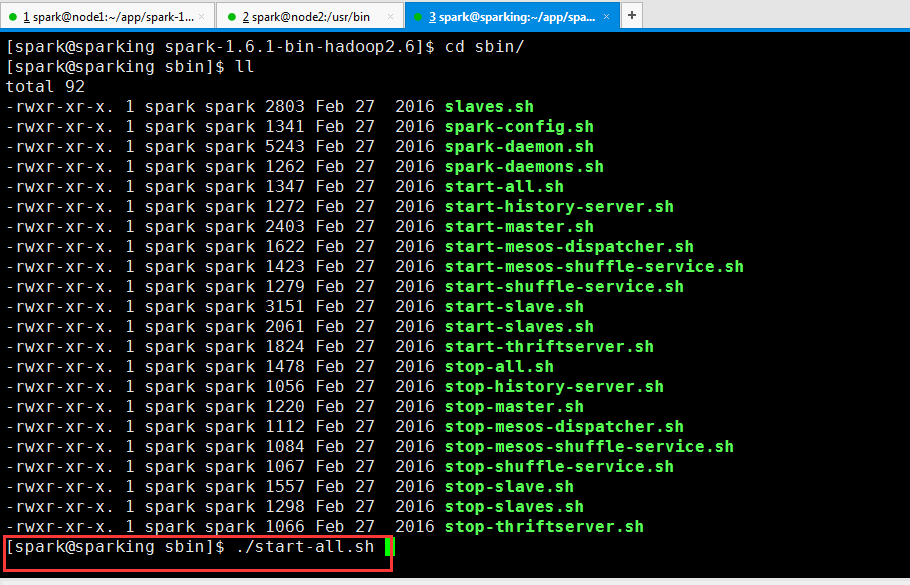
通过脚本启动集群


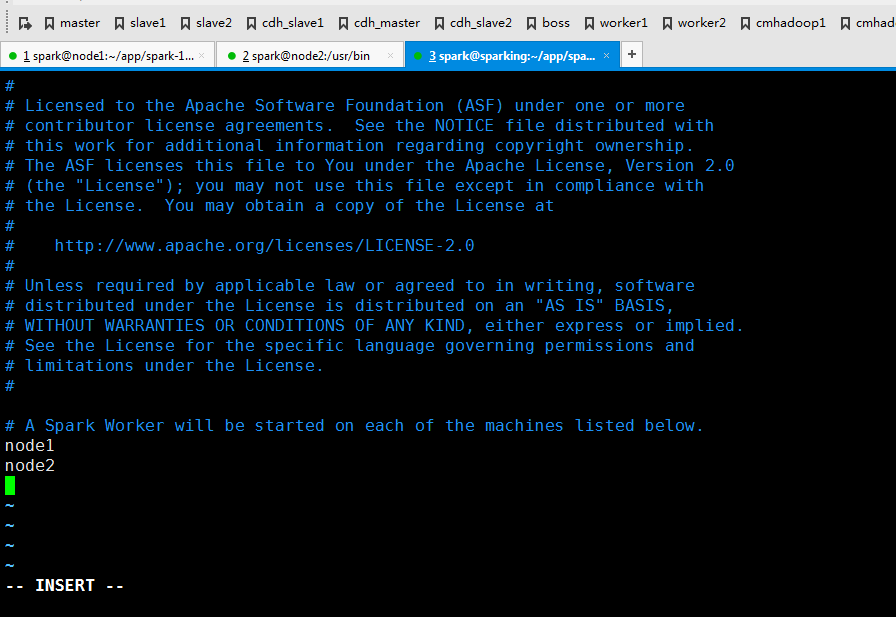
编辑slaves,其实把worker所在节点添加进去

配置spark-defaults.conf


启动集群(我这里是三节点集群)

在浏览器打开页面
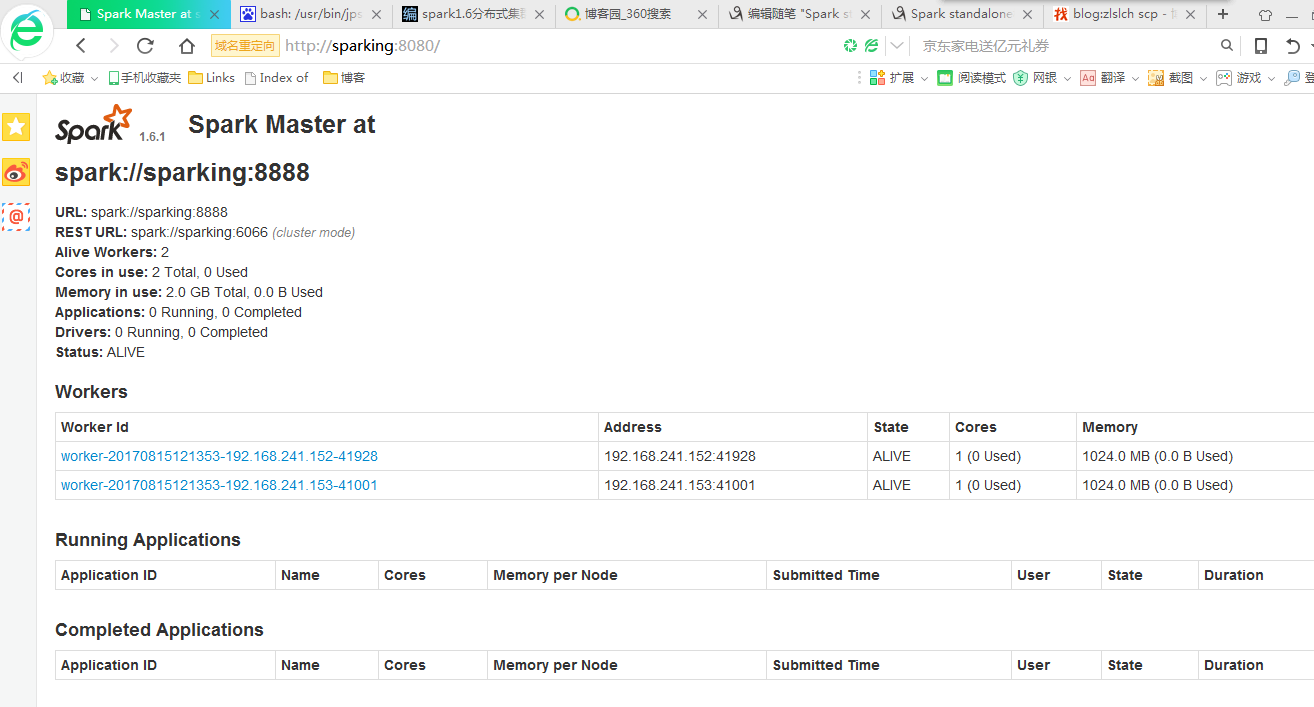
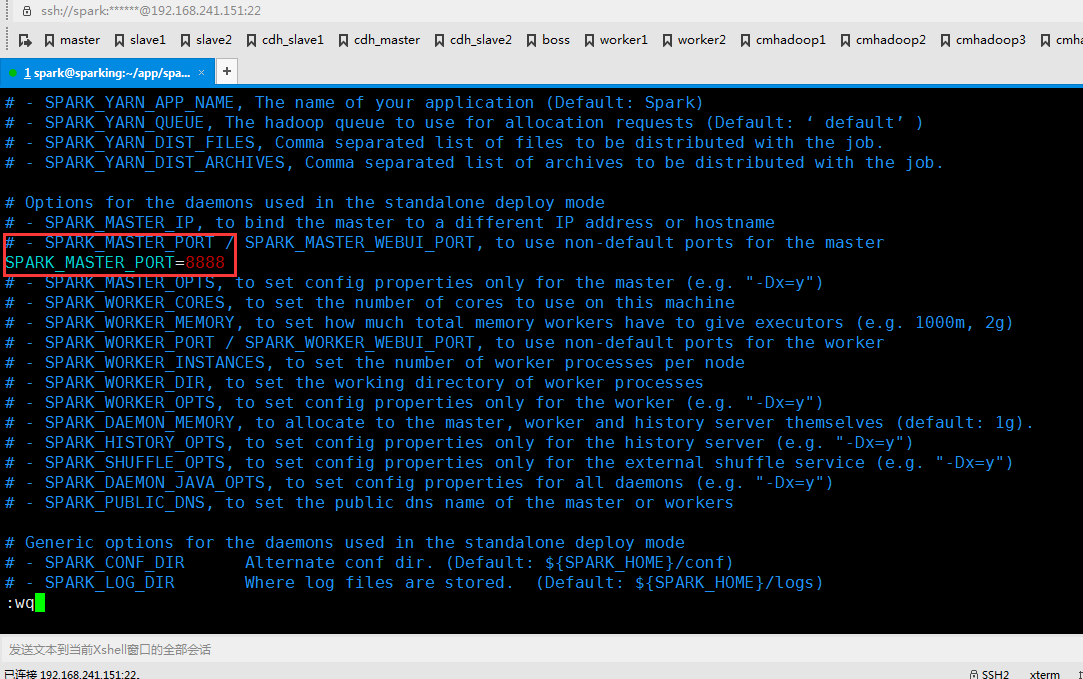
修改 spark-env.sh 文件
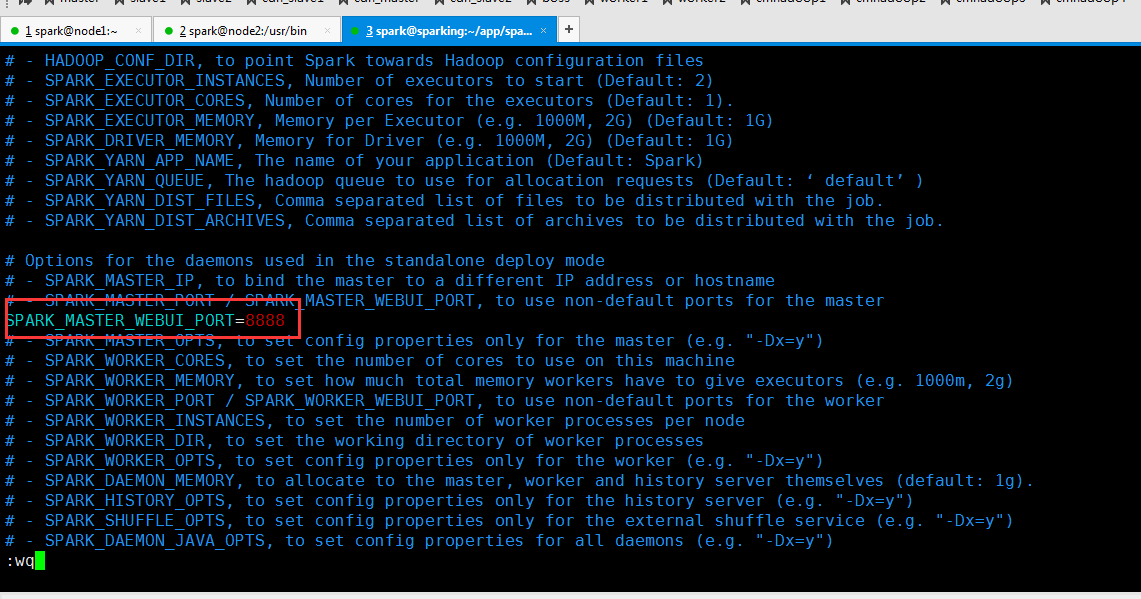
先停止
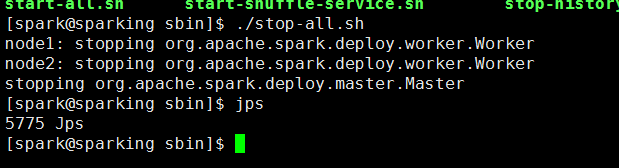
在重新启动一下
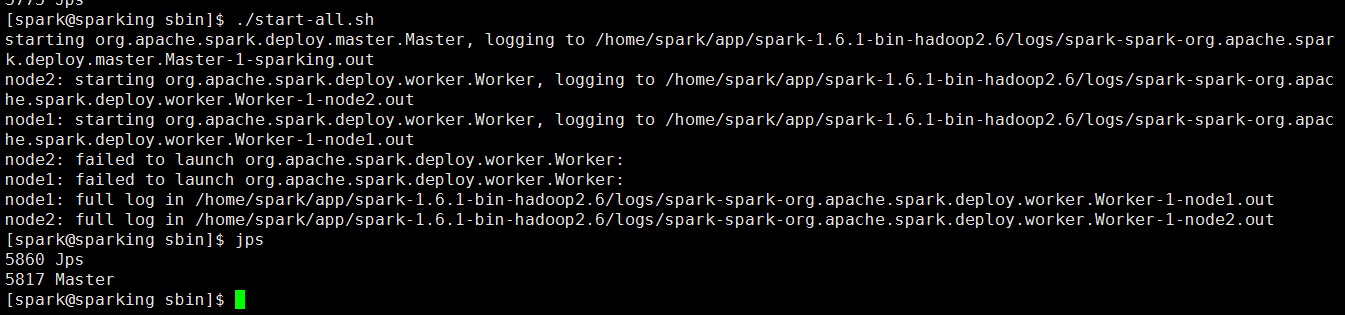
再次访问网页
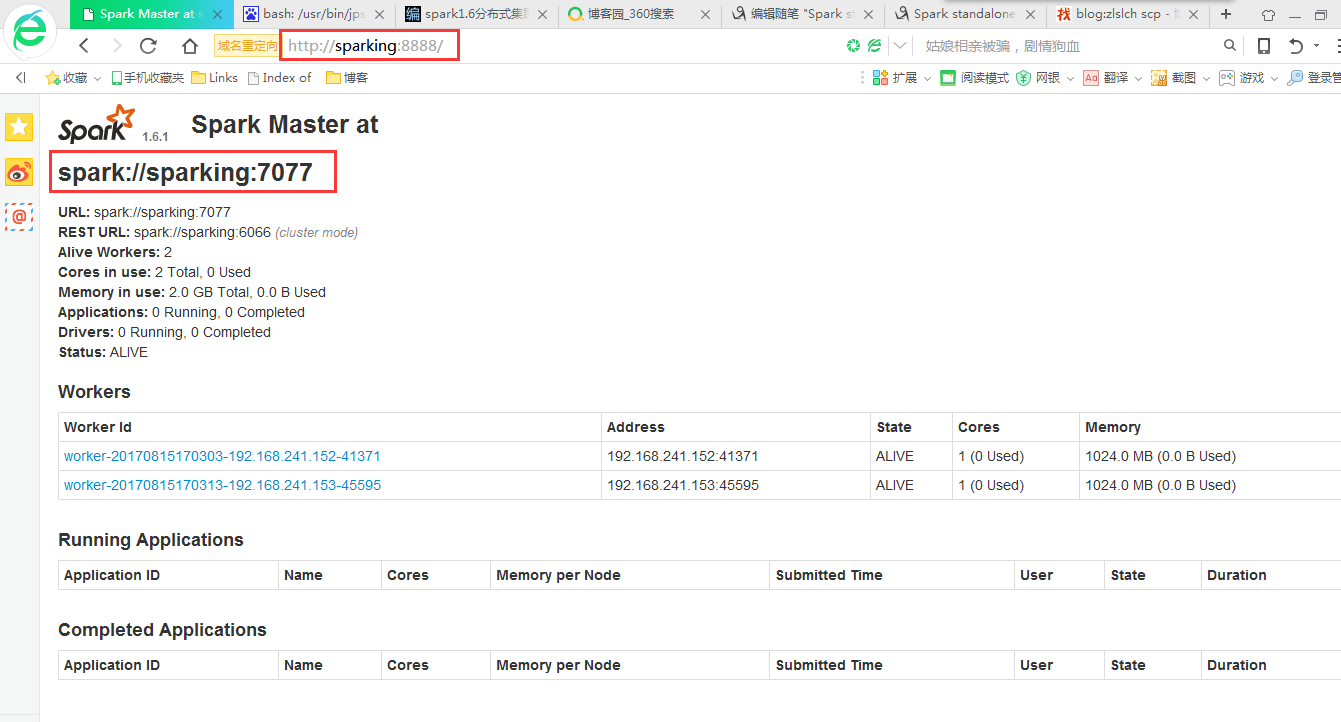
下面跑一个Job实例
./spark-submit --master spark://sparking:7077 --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.1-hadoop2.6.0.jar
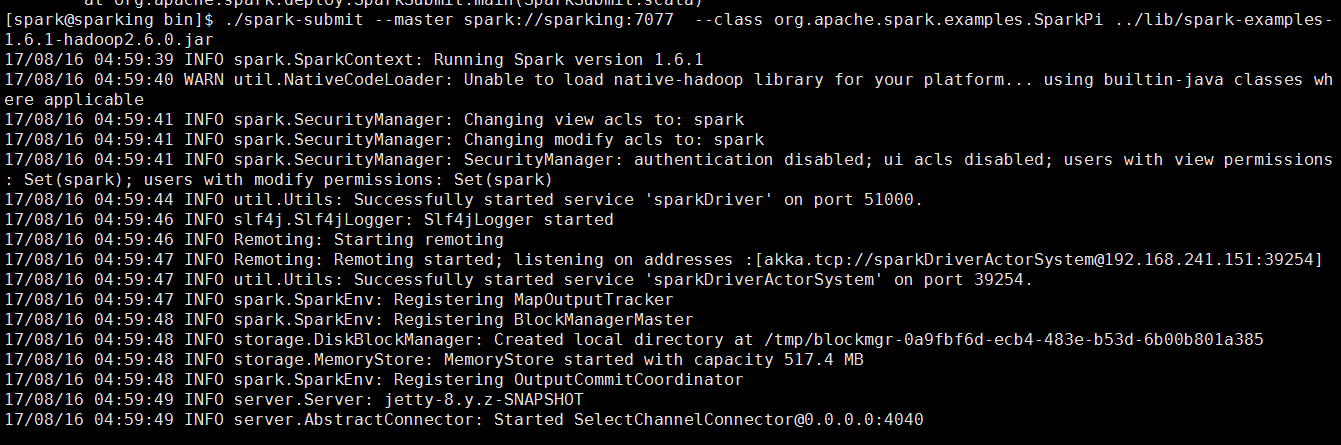
从过程反馈信息可以看出来计算Pi的值
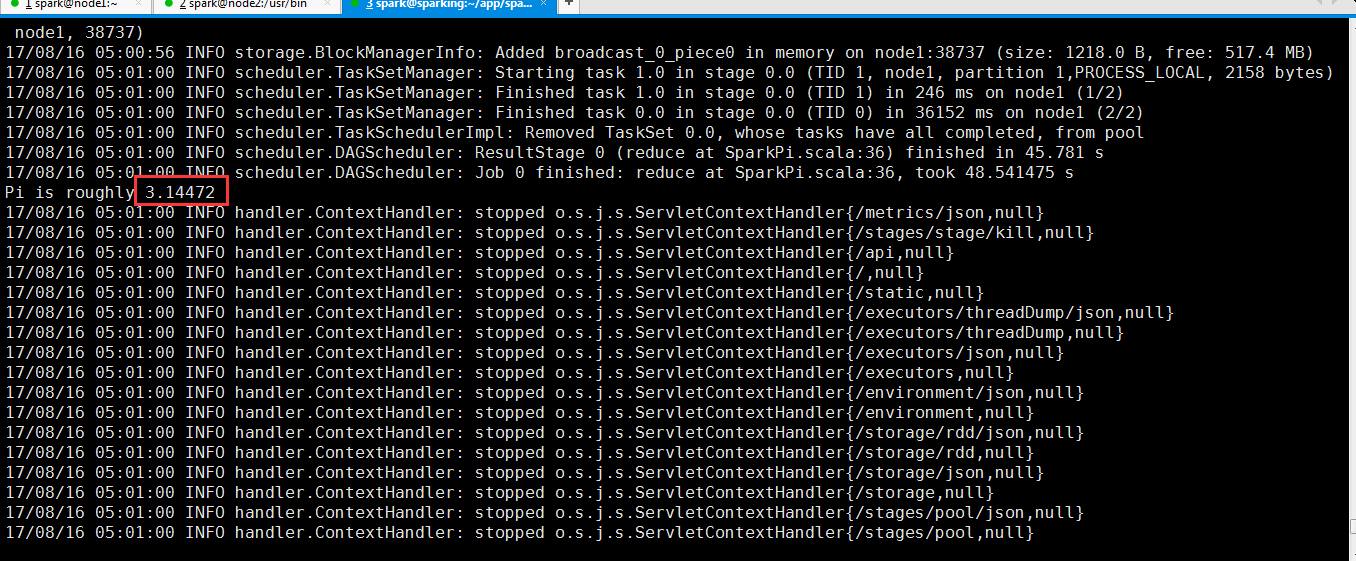
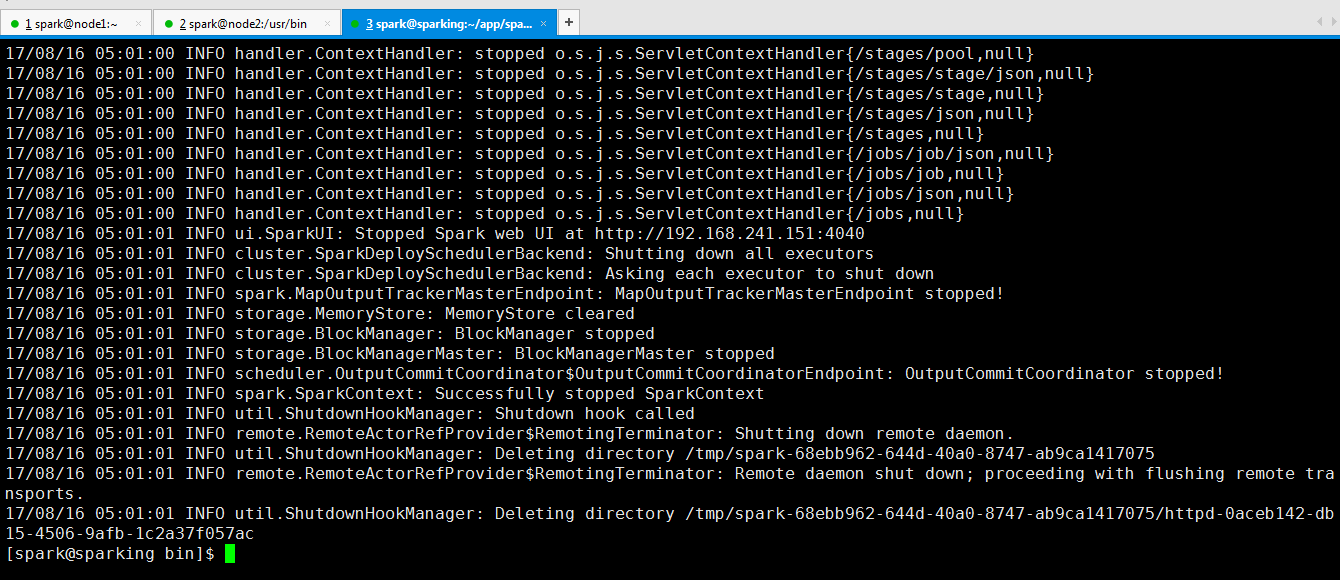
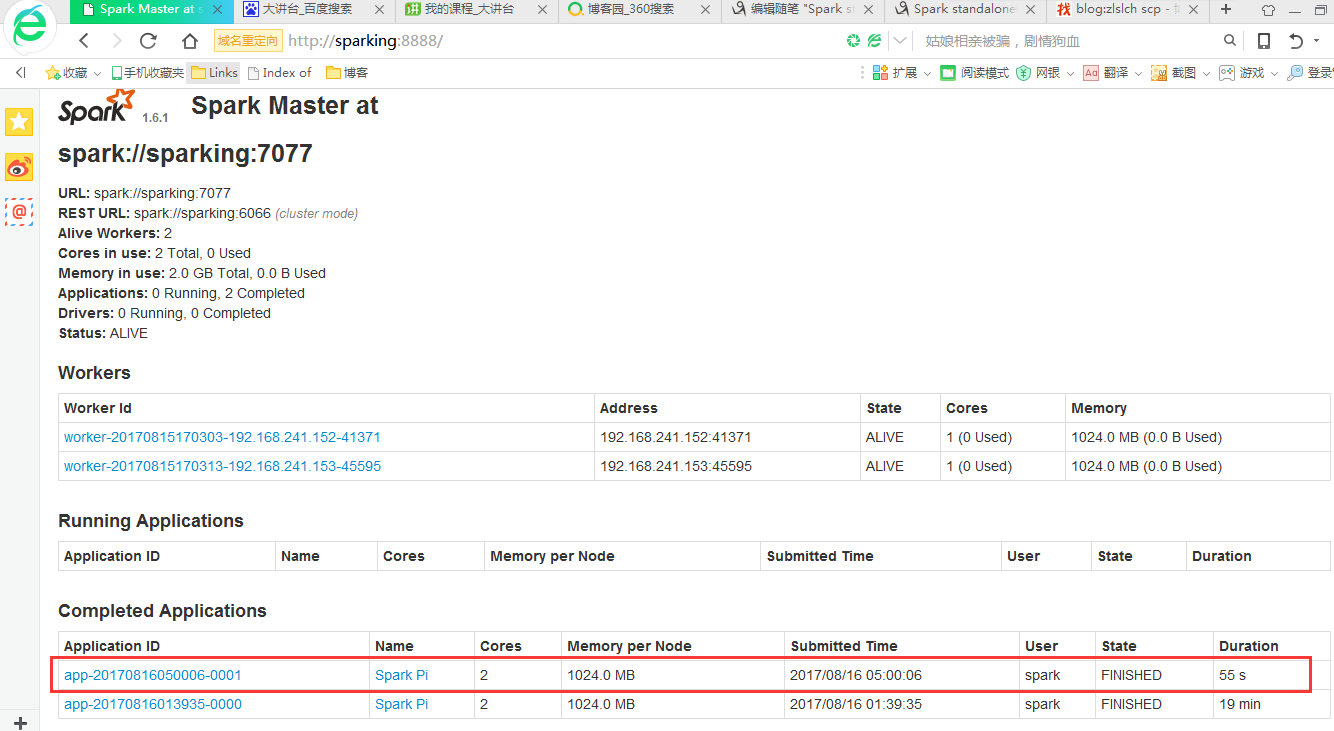
可以看到运行完成了。
从页面也可以看出来
Spark Standalone HA

官方参考地址
https://spark.apache.org/docs/latest/spark-standalone.html#high-availability

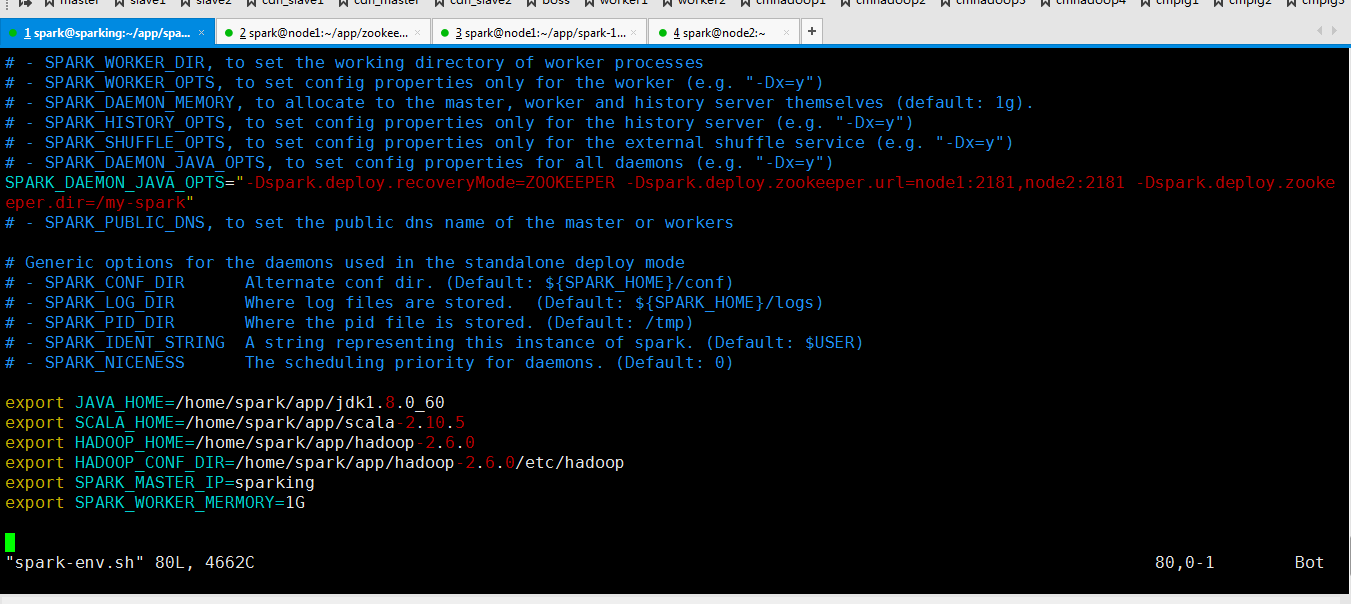
SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node1:2181,node2:2181 -Dspark.deploy.zookeeper.dir=/my-spark"
默认是这样连接的。
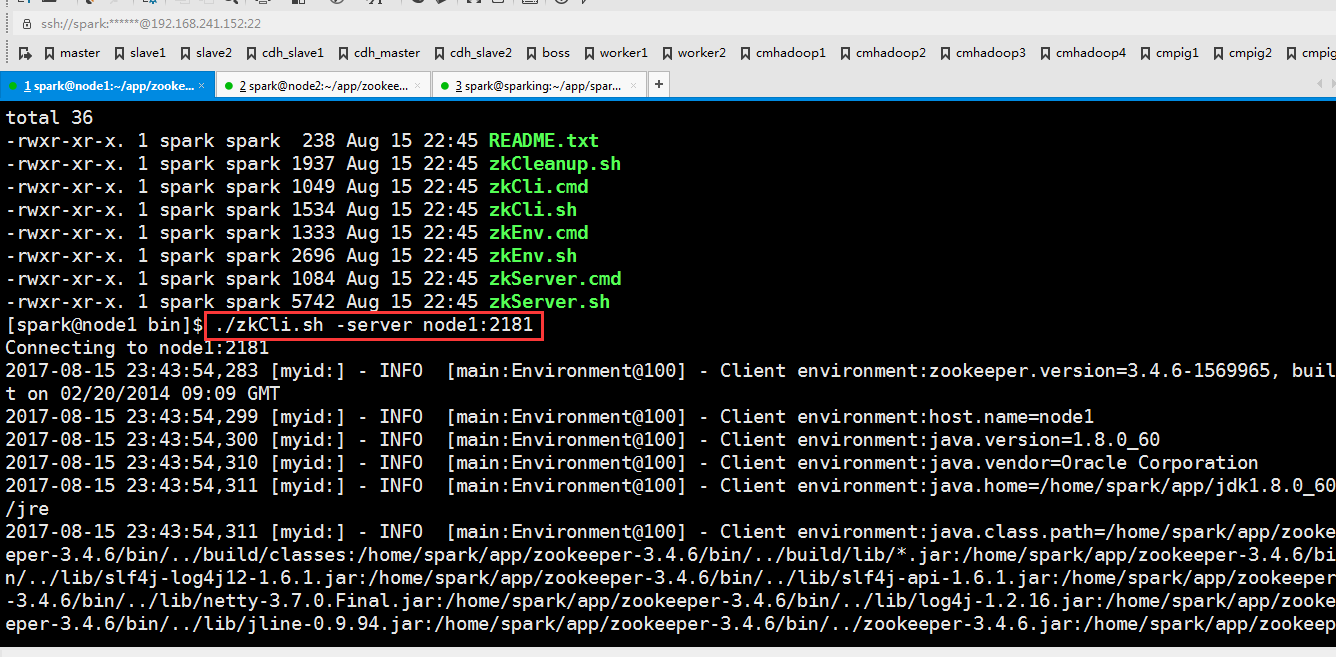
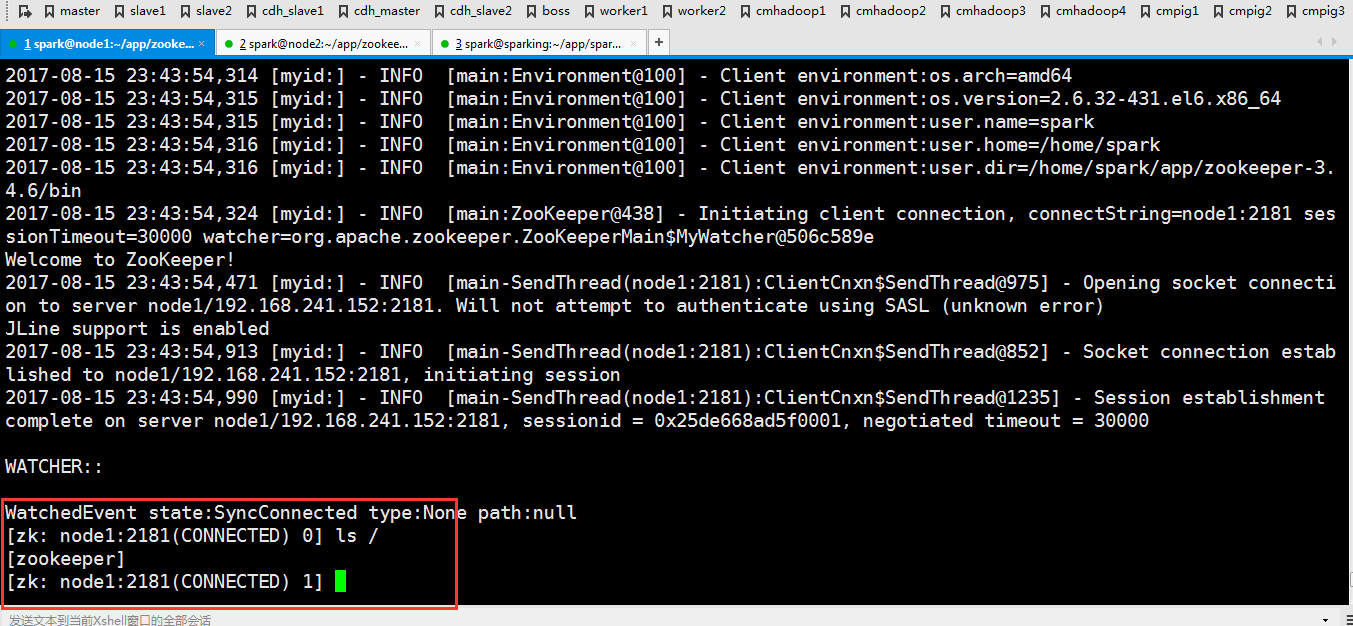
因为刚才修改了文件,现在把修改好的文件分发到另外两个节点去

scp -r spark-env.sh spark@node1:/home/spark/app/spark-1.6.-bin-hadoop2./conf/ scp -r spark-env.sh spark@node2:/home/spark/app/spark-1.6.-bin-hadoop2./conf/
然后重新启动一下
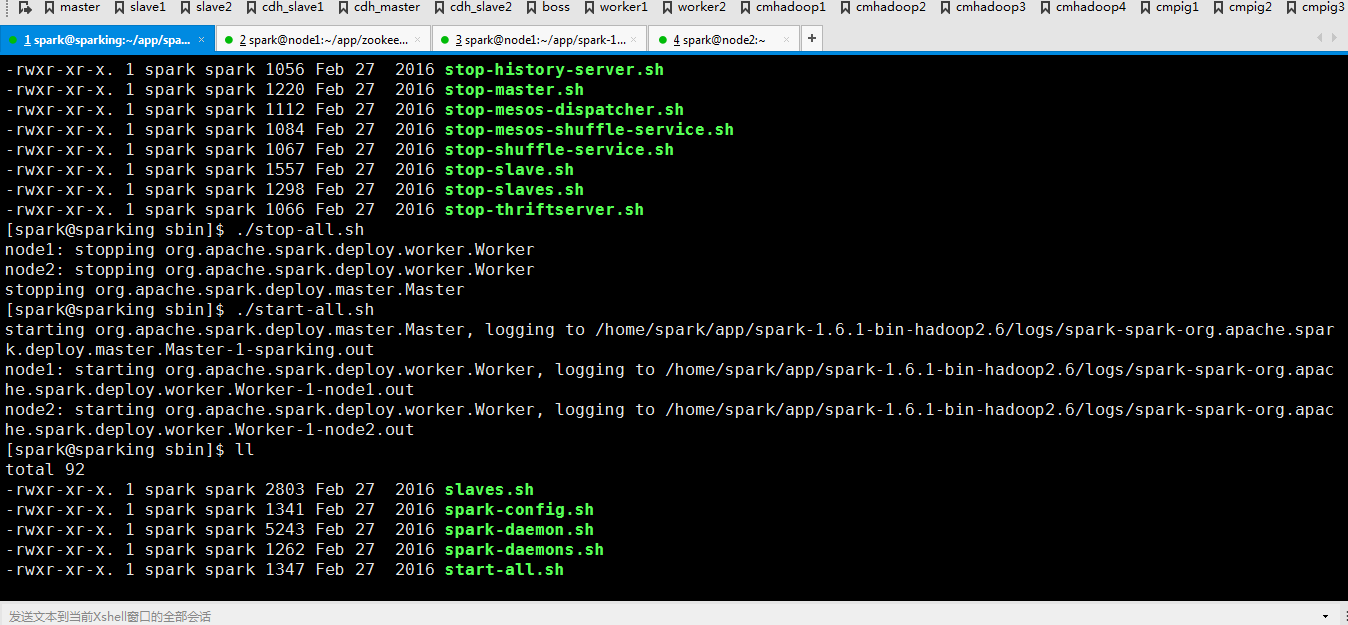
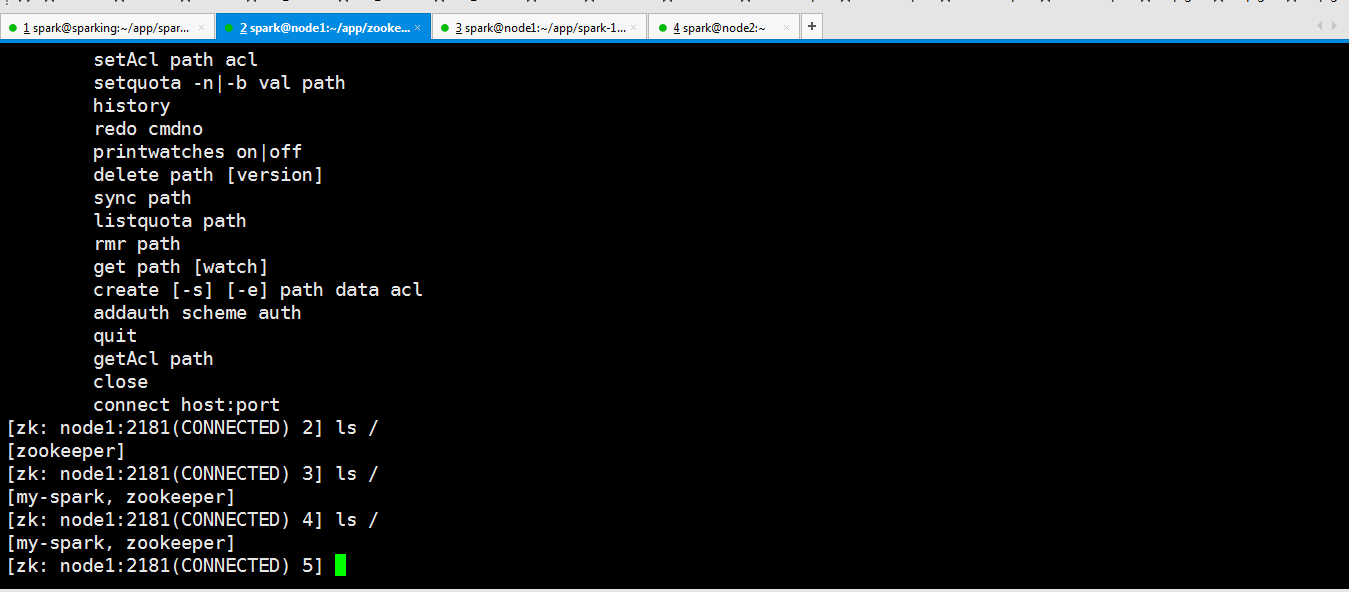
可以看到起来了
Spark Standalone 运行架构解析
Spark基本工作流程
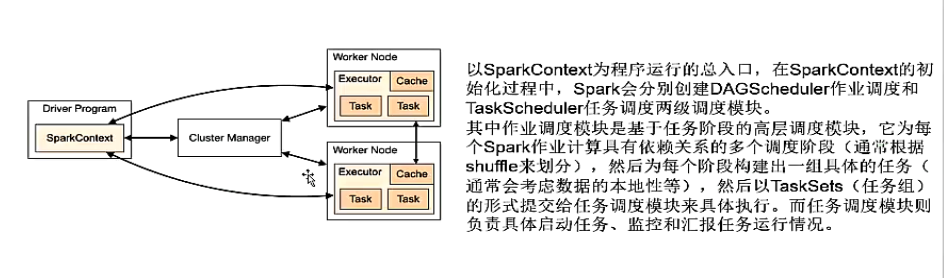
Spark Local模式

Spark Local cluster 模式

Spark standalone 模式

Spark standalone 详细过程解析
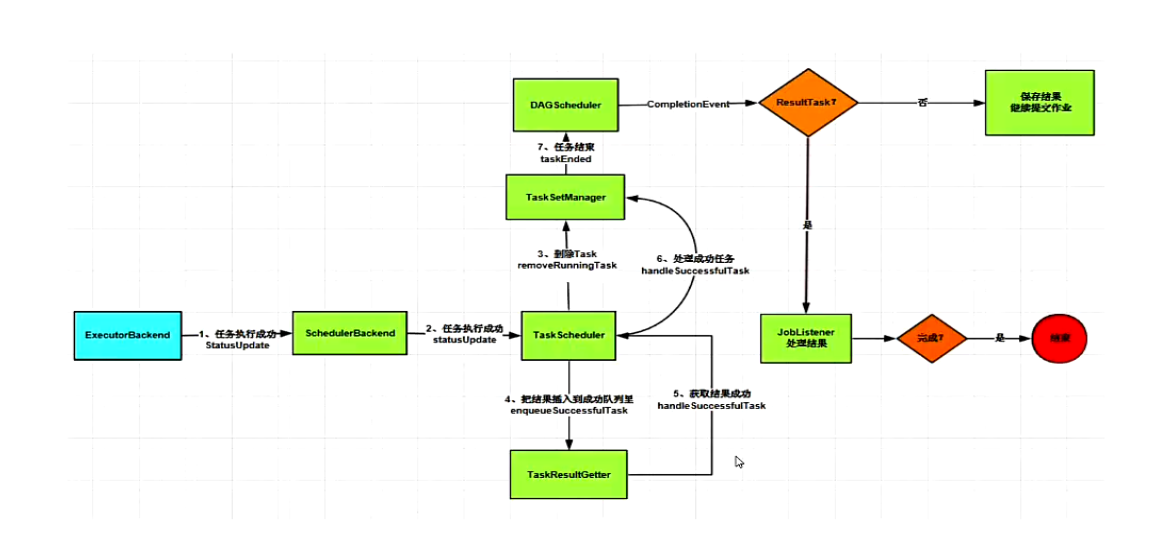
Spark standalone 模式下运行WordCount
在IDEA里把写好的wordcount程序打包(我这里用的是scala版本写的)
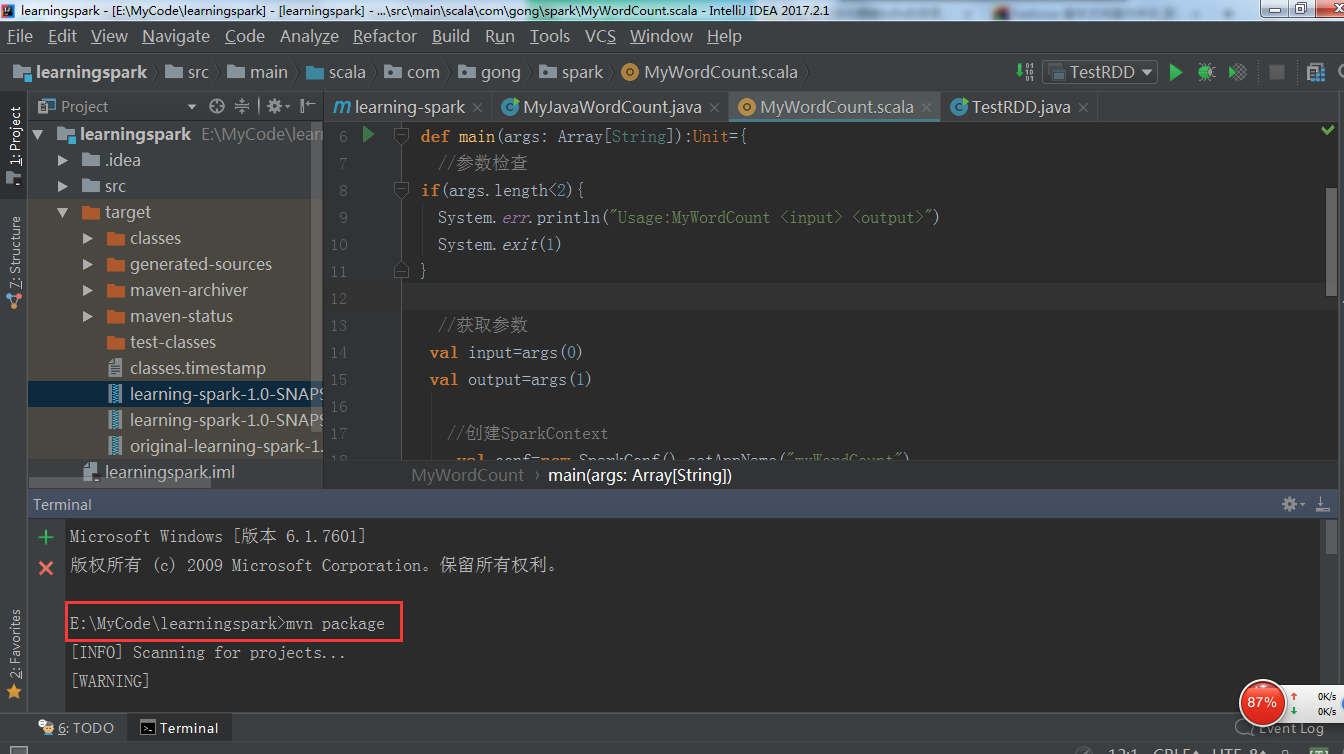
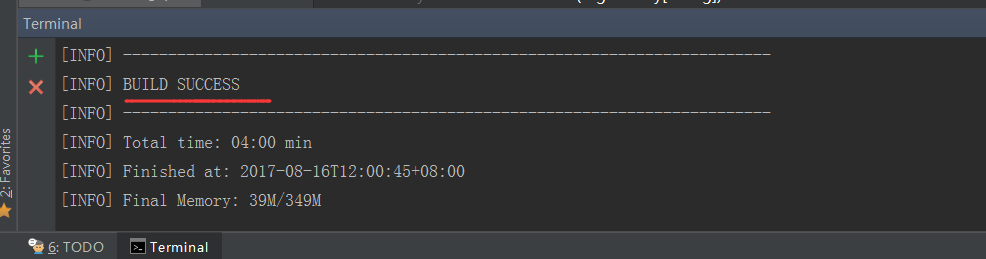
可以看到打包成功!
参考代码
package com.gong.spark
import org.apache.spark.{SparkConf, SparkContext}
object MyWordCount {
def main(args: Array[String]):Unit={
//参数检查
if(args.length<){
System.err.println("Usage:MyWordCount <input> <output>")
System.exit()
}
//获取参数
val input=args()
val output=args()
//创建SparkContext
val conf=new SparkConf().setAppName("myWordCount")
val sc=new SparkContext(conf)
//读取数据
val lines=sc.textFile(input)
//进行相关计算
val resultRdd=lines.flatMap(_.split(" ")).map((_,)).reduceByKey(_+_)
//保存结果
resultRdd.saveAsTextFile(output)
sc.stop()
}
}
把包上传到集群上(用rz命令就可以了)
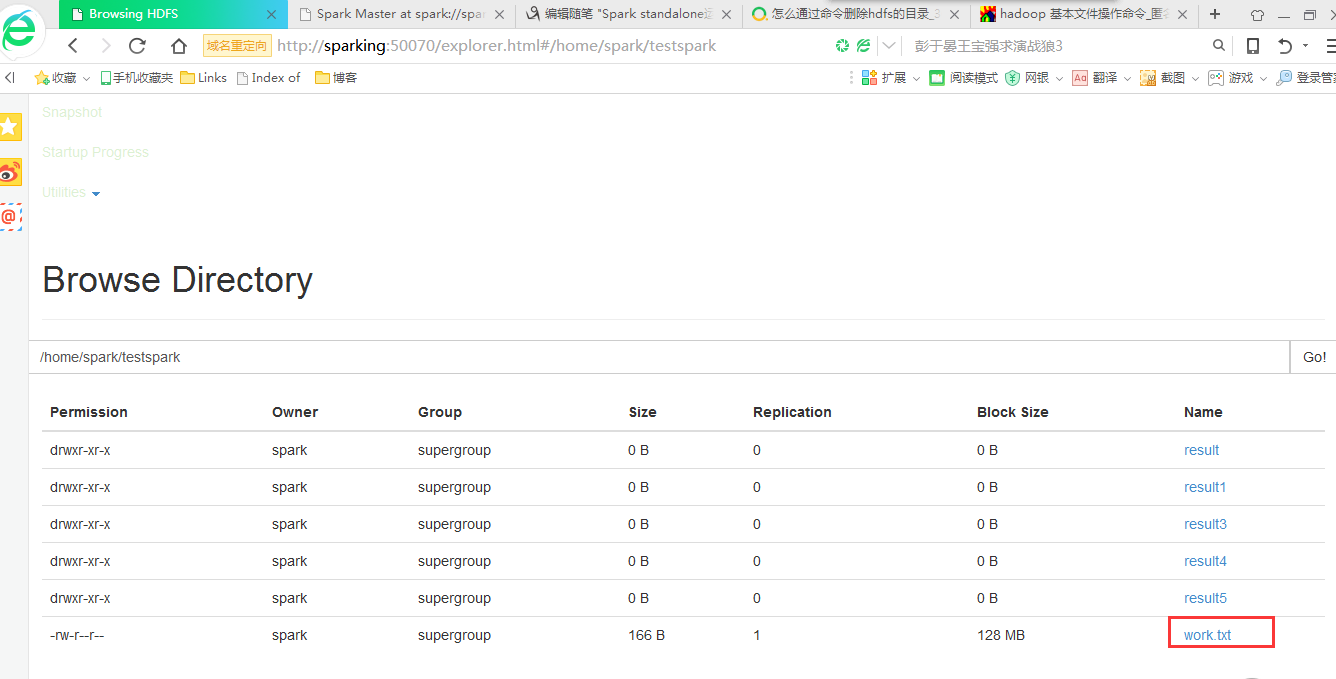
在这之前我已经在我的hdfs上上次了work.txt文件
下面在集群里跑一下程序
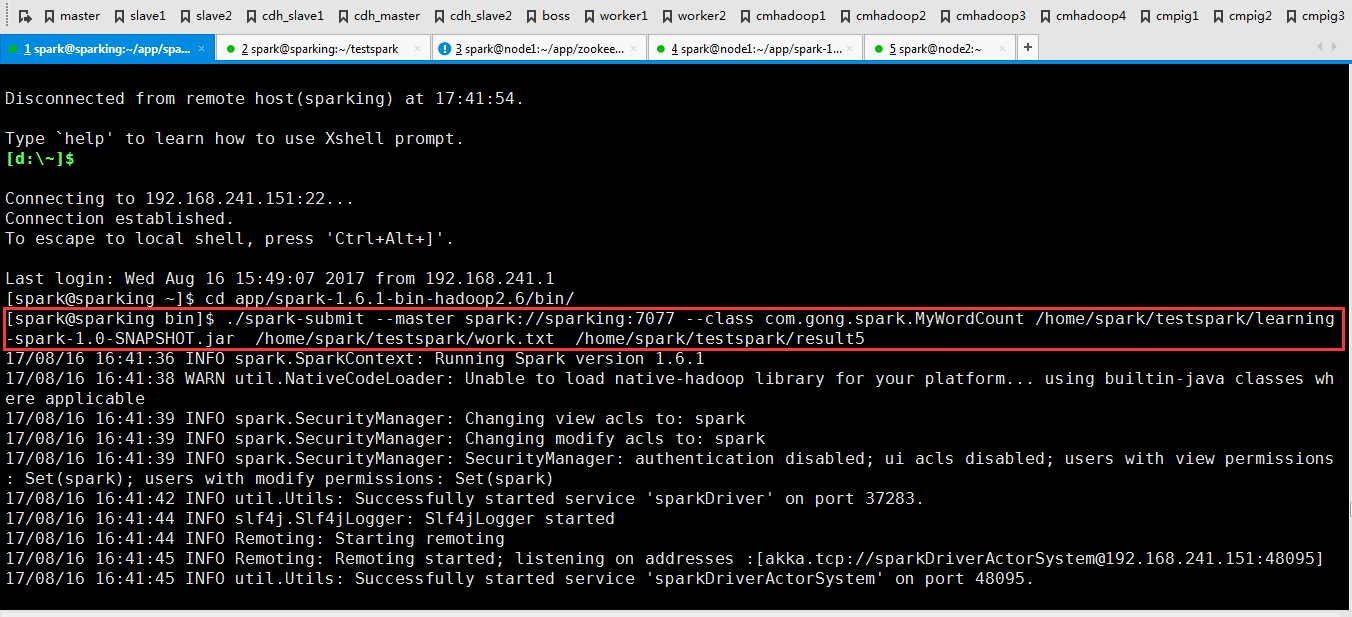
./spark-submit --master spark://sparking:7077 --class com.gong.spark.MyWordCount /home/spark/testspark/learning-spark-1.0-SNAPSHOT.jar /home/spark/testspark/work.txt /home/spark/testspark/result5
可以看到运行完成了(在这里我说下运行这个程序需要网络良好才可以,因为我的实验室的网络非常差,所以我试了好多次)!!!!!
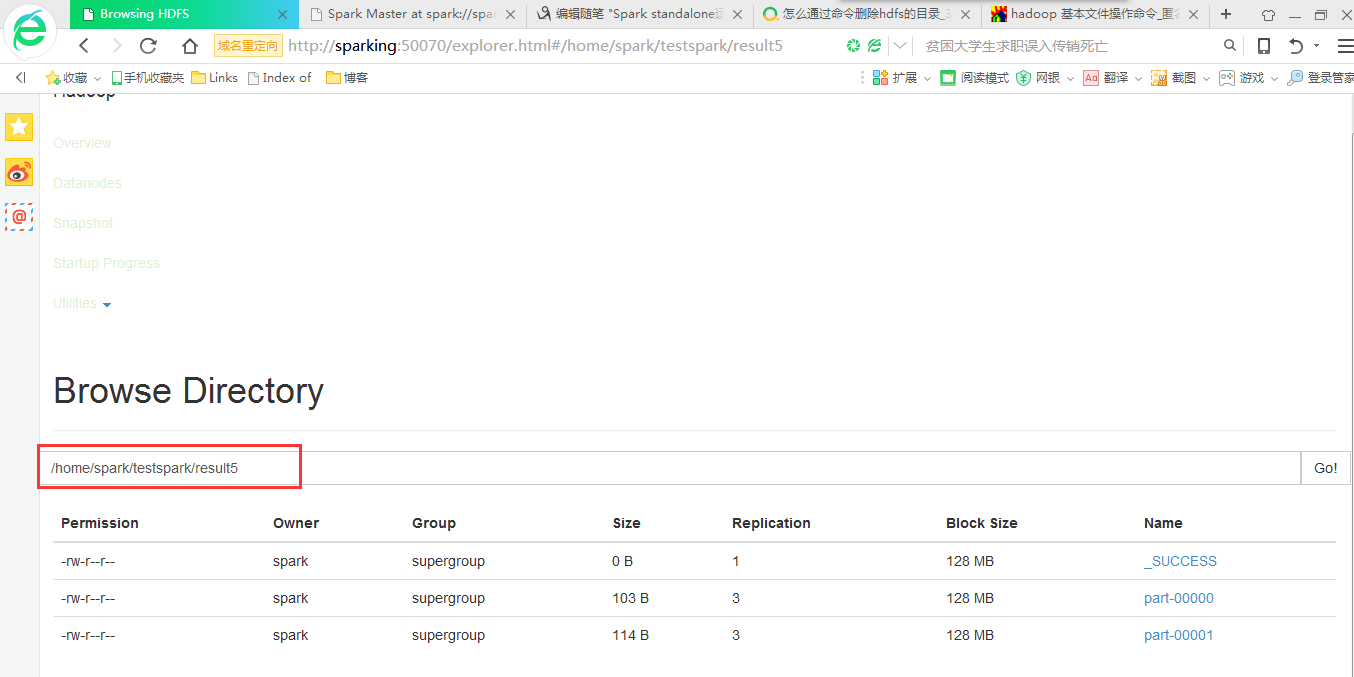
在hdfs上查看运行结果
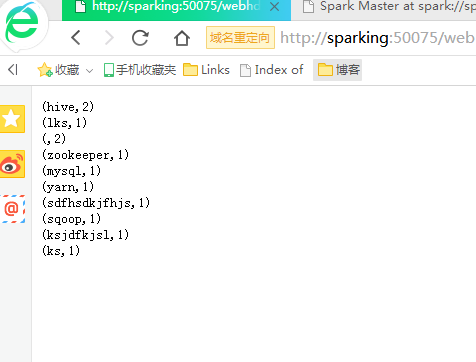
Spark standalone运行模式的更多相关文章
- Spark standalone运行模式(图文详解)
不多说,直接上干货! 请移步 Spark standalone简介与运行wordcount(master.slave1和slave2) Spark standalone模式的安装(spark-1.6. ...
- 【原】Spark不同运行模式下资源分配源码解读
版权声明:本文为原创文章,未经允许不得转载. 复习内容: Spark中Task的提交源码解读 http://www.cnblogs.com/yourarebest/p/5423906.html Sch ...
- Spark的 运行模式详解
Spark的运行模式是多种多样的,那么在这篇博客中谈一下Spark的运行模式 一:Spark On Local 此种模式下,我们只需要在安装Spark时不进行hadoop和Yarn的环境配置,只要将S ...
- 五、standalone运行模式
在上文中我们知道spark的集群主要有三种运行模式standalone.yarn.mesos,其中常被使用的是standalone和yarn,本文了解一下什么是standalone运行模式,它的运行流 ...
- Spark的运行模式(1)--Local和Standalone
Spark一共有5种运行模式:Local,Standalone,Yarn-Cluster,Yarn-Client和Mesos. 1. Local Local模式即单机模式,如果在命令语句中不加任何配置 ...
- Spark多种运行模式
1.测试或实验性质的本地运行模式(单机) 该模式被称为Local[N]模式,是用单机的多个线程来模拟Spark分布式计算,通常用来验证开发出来的应用程序逻辑上是否有问题. 其中N代表可以使用N个线程, ...
- Spark的运行模式(2)--Yarn-Cluster和Yarn-Client
3. Yarn-Cluster Yarn是一种统一资源管理机制,可以在上面运行多种计算框架.Spark on Yarn模式分为两种:Yarn-Cluster和Yarn-Client,前者Driver运 ...
- spark的运行模式
1.local(本地模式) 单机模式,通常用来测试 将spark应用以多线程方式,直接运行在本地 本地模式可以启动多个executor不过上限不能超过cpu数 2.standalone(独立模式) 独 ...
- 017 Spark的运行模式(yarn模式)
1.关于mapreduce on yarn 来提交job的流程 yarn=resourcemanager(RM)+nodemanager(NM) client向RM提交任务 RM向NM分配applic ...
随机推荐
- GET_DDL提取建表语句:ddl
创建对象的语句就是了 提取表 set line 200 pages 50000 wrap on long 999999 serveroutput on SQL> select dbms_meta ...
- java面试题12
1. jsp与servlet的区分? 答:Servlet和JSP都是基于java语言上的动态网页技术,Servlet程序其实就是java程序,只不过它所使用的类库为JAVA Servlet API, ...
- rabbitmq学习(五):springboot整合rabbitmq
一.Springboot对rabbitmq的支持 springboot提供了对rabbitmq的支持,并且大大简化了rabbitmq的相关配置.在springboot中,框架帮我们将不同的交换机划分出 ...
- Ubuntu 18.10 安装PDF阅读器
======================================== 软件开发转移到了 Linux上,使用Ubuntu 18.10作为桌面开发环境 下面介绍 安装PDF阅读器 1.下载 福 ...
- 安装maven和glassfish及配置环境变
首先搜索并下载maven3.6.0和glassfish4.1.1(版本看按需要选择). 点击安装包进行安装 安装完成后开始配置环境变量 打开系统环境变量 (1)新建系统变量MAVEN_HOME 变量值 ...
- ES6必知必会 (二)—— 字符串和函数的拓展
字符串的拓展 1.ES6为字符串添加了遍历器接口,因此可以使用for...of循环遍历字符串 2.字符串新增的 includes().startsWith().endsWidth() 三个方法用于判断 ...
- 自制数据结构(容器)-java开发用的最多的ArrayList和HashMap
public class MyArrayList<E> { private int capacity = 10; private int size = 0; private E[] val ...
- [Python] 中文路径和中文文本文件乱码问题
情景: Python首先读取名为log.txt的文本文件, 其中包含有文件名相对路径信息filename. 随后Python调用shutil.copy2(src, dst)对该filename文件进行 ...
- 【转】每天一个linux命令(45):free 命令
原文网址:http://www.cnblogs.com/peida/archive/2012/12/25/2831814.html free命令可以显示Linux系统中空闲的.已用的物理内存及swap ...
- 顶级域名和子级域名之间的cookie共享和相互修改、删除
举例: js 设置 cookie: domain=cag.com 和 domain=.cag.com 是一样的,在浏览器cookie中,Domain都显示为 .cag.com. 就是说:以下2个语句是 ...