Python爬虫(图片)编写过程中遇到的问题
最近我突然对网络爬虫开窍了,真正做起来的时候发现并不算太难,都怪我以前有点懒,不过近两年编写了一些程序,手感积累了一些肯定也是因素,总之,还是惭愧了。好了,说正题,我把这两天做爬虫的过程中遇到的问题总结一下:
需求:做一个爬虫,爬取一个网站上所有的图片(只爬大图,小图标就略过)
思路:1、获取网站入口,这个入口网页上有很多图片集合入口,进入这些图片集合就能看到图片链接了,所以爬取的深度为2,比较简单;2、各个子图片集合内所包含的图片链接有两种形式:一种是绝对图片路径(直接下载即可),另一种的相对图片路径(需要自行拼接当前网页路径)。总之这些子图集合的表现形式简单,没有考虑更复杂的情况。3、在爬取的过程中保存已成功爬取的路径,防止每次爬取都执行重复的任务,当然,当每次启动时要首先加载该历史数据库,剩下的就是细节了。
快速链接:
一、全部代码
直接先来代码,再详细说优化的过程和内容吧:
__author__ = 'KLH'
# -*- coding:utf-8 -*- import urllib
import urllib2
import chardet
import re
import os
import time
from myLogger import * # 网络蜘蛛
class Spider: # 类初始化
def __init__(self):
self.contentFolder = u"抓取内容"
self.dbName = "url.db"
self.createFolder(self.contentFolder)
self.urlDB = set() # 获取URL数据库以获取爬过的网页地址
def loadDatabase(self):
isExists = os.path.exists(self.dbName)
if not isExists:
logging.info(u"创建URL数据库文件:'" + self.dbName + u"'")
f = open(self.dbName, 'w+')
f.write("#Create time: " + time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(time.time())) + '\n')
f.close()
return
db = open(self.dbName, 'r')
for line in db.readlines():
if not line.startswith('#'):
self.urlDB.add(line.strip('\n'))
db.close()
logging.info(u"URL数据库加载完成!") # 追加数据库文件
def writeToDatabase(self, url):
db = open(self.dbName, 'a')
db.write(url + '\n')
db.close() # 处理路径名称中的空格字符
def getPathName(self, pathName):
newName = ""
subName = pathName.split()
i = 0
while i < len(subName) - 1:
newName = newName + subName[i]
i = i + 1
return newName # 获取索引页面的内容
def getPage(self, pageURL, second):
try:
headers = {'User-agent' : 'Mozilla/5.0 (Windows NT 6.2; WOW64; rv:22.0) Gecko/20100101 Firefox/22.0'}
request = urllib2.Request(pageURL, headers = headers)
response = urllib2.urlopen(request, timeout = second)
data = response.read()
response.close()
return data.decode('gbk'), True
except urllib2.HTTPError,e: #HTTPError必须排在URLError的前面
logging.error("HTTPError code:" + str(e.code) + " - Content:" + e.read())
return "", False
except urllib2.URLError, e:
logging.error("URLError reason:" + str(e.reason) + " - " + str(e))
return "", False
except Exception, e:
logging.error(u"获取网页失败:" + str(e))
return "", False # 获取索引界面所有子页面信息,list格式
def getContents(self, pageURL, second):
contents = []
page, succeed = self.getPage(pageURL, second)
if succeed:
# 这里的正则表达式很重要,决定了第一步的抓取内容:
pattern = re.compile('<tr>.*?<a href="(.*?)".*?<b>(.*?)</b>.*?</tr>',re.S)
items = re.findall(pattern,page)
for item in items:
contents.append([item[0],item[1]])
contents.sort()
return contents # 获取页面所有图片
def getAllImgURL(self, infoURL):
images = []
succeed = True
try:
headers = {'User-agent' : 'Mozilla/5.0 (Windows NT 6.2; WOW64; rv:22.0) Gecko/20100101 Firefox/22.0'}
request = urllib2.Request(infoURL, headers = headers)
data = urllib2.urlopen(request).read()
chardet1 = chardet.detect(data) # 自动判断网页编码
page = data.decode(str(chardet1['encoding'])) # 第一种解码格式:
pattern = re.compile('<option value="(.*?)">(.*?)</option>')
items = re.findall(pattern, page)
# item[0]为图片URL尾部,item[1]为图片名称
for item in items:
if item.startswith('http://'):
imageURL = item[0]
if imageURL in self.urlDB:
logging.info(u"获得图片URL(曾被访问,跳过):" + imageURL)
else:
logging.info(u"获得图片URL:" + imageURL)
images.append(imageURL)
else:
imageURL = infoURL + item[0]
if imageURL in self.urlDB:
logging.info(u"获得图片URL(曾被访问,跳过):" + imageURL)
else:
logging.info(u"获得图片URL:" + imageURL)
images.append(imageURL) # 第二种解码格式
pattern = re.compile('<IMG src="(.*?)".*?>')
items = re.findall(pattern, page)
# item为图片URL
for item in items:
if item.startswith('http://'):
if item in self.urlDB:
logging.info(u"获得图片URL(曾被访问,跳过):" + item)
else:
logging.info(u"获得图片URL:" + item)
images.append(item) except Exception, e:
logging.warning(u"在获取子路径图片列表时出现异常:" + str(e))
succeed = False
return images, succeed # 保存所有图片
def saveImgs(self, images, name):
logging.info(u'发现"' + name + u'"共有' + str(len(images)) + u"张照片")
allSucceed = True
for imageURL in images:
splitPath = imageURL.split('/')
fTail = splitPath.pop()
fileName = name + "/" + fTail
logging.info(u"开始准备保存图片(超时设置:120秒):" + imageURL)
startTime = time.time()
succeed = self.saveImg(imageURL, fileName, 120)
spanTime = time.time() - startTime
if succeed:
logging.info(u"保存图片完成(耗时:" + str(spanTime) + u"秒):" + fileName)
# 保存文件存储记录
self.urlDB.add(imageURL)
self.writeToDatabase(imageURL)
else:
logging.warning(u"保存图片失败(耗时:" + str(spanTime) + u"秒):" + imageURL)
allSucceed = False
# 为了防止网站封杀,这里暂停1秒
time.sleep(1)
return allSucceed # 传入图片地址,文件名,超时时间,保存单张图片
def saveImg(self, imageURL, fileName, second):
try:
headers = {'User-agent' : 'Mozilla/5.0 (Windows NT 6.2; WOW64; rv:22.0) Gecko/20100101 Firefox/22.0'}
request = urllib2.Request(imageURL, headers = headers)
u = urllib2.urlopen(request, timeout = second)
data = u.read()
f = open(fileName, 'wb')
f.write(data)
f.close()
u.close()
return True
except urllib2.HTTPError,e: #HTTPError必须排在URLError的前面
logging.error("HTTPError code:" + str(e.code) + " - Content:" + e.read())
return False
except urllib2.URLError, e:
logging.error("URLError reason:" + str(e.reason) + " - " + str(e))
return False
except Exception, e:
logging.error(u"保存图片失败:" + str(e))
return False # 创建新目录
def createFolder(self, path):
path = path.strip()
# 判断路径是否存在
isExists=os.path.exists(path)
# 判断结果
if not isExists:
# 如果不存在则创建目录
logging.info(u"创建文件夹:'" + path + u"'")
# 创建目录操作函数
os.makedirs(path)
return True
else:
# 如果目录存在则不创建,并提示目录已存在
logging.info(u"名为'" + path + u"'的文件夹已经存在,跳过")
return False # 获取的首页地址
def savePageInfo(self, pageURL):
logging.info(u"准备获取网页内容(超时设置:60秒):" + pageURL)
contents = self.getContents(pageURL, 60)
logging.info(u"网页内容获取完成,子路径个数:" + str(len(contents)))
index = 1
for item in contents:
#(1)item[0]子路径URL, item[1]子路径名称
folderURL = item[0]
folderName = self.contentFolder + '\\' + str(index) + "-" + self.getPathName(item[1])
self.createFolder(folderName)
index = index + 1 #(2)判断链接头部合法性和重复性
if not folderURL.startswith('http://'):
folderURL = pageURL + folderURL
if folderURL in self.urlDB:
logging.info(u'"' + folderName + u'"的链接地址(已访问,跳过)为:' + folderURL)
continue
else:
logging.info(u'"' + folderName + u'"的链接地址为:' + folderURL) #(3)获取图片URL列表,成功则保存图片
images, succeed = self.getAllImgURL(folderURL)
if succeed:
succeed = self.saveImgs(images, folderName)
if succeed:
self.urlDB.add(folderURL)
self.writeToDatabase(folderURL) # 初始化系统日志存储
InitLogger()
# 传入初始网页地址,自动启动爬取图片:
spider = Spider()
spider.loadDatabase()
spider.savePageInfo('http://365.tw6000.com/xtu/')
logging.info(u"全部网页内容爬取完成!程序退出。")
查看全部代码
二、问题历史
在上面的代码中有不少的细节是优化解决过的,相关的知识点如下:
2.1 日志系统
Python的日志系统是相当的不错,非常的方便,详细的资料可以参考Python官方文档,或者上一篇博文也是提到过的:《Python中的日志管理Logging模块》,应用到我这个爬虫这里的代码就是myLogger.py模块了,用起来很方便:
__author__ = 'KLH'
# -*- coding:utf-8 -*- import logging
import time def InitLogger():
logFileName = 'log_' + time.strftime("%Y%m%d%H%M%S", time.localtime(time.time())) + '.txt'
logging.basicConfig(level=logging.DEBUG,
format='[%(asctime)s][%(filename)s:%(lineno)d][%(levelname)s] - %(message)s',
filename=logFileName,
filemode='w') # 定义一个StreamHandler将INFO级别以上的信息打印到控制台
console = logging.StreamHandler()
console.setLevel(logging.INFO)
formatter = logging.Formatter('[%(asctime)s][%(filename)s:%(lineno)d][%(levelname)s] - %(message)s')
console.setFormatter(formatter)
logging.getLogger('').addHandler(console)
查看myLogger.py
注意在爬虫的代码执行前调用一下该函数:
from myLogger import *
# 初始化系统日志存储
InitLogger()
日志调用和打印的结果如下:
logging.info(u"准备获取网页内容(超时设置:60秒):" + pageURL) #打印结果如下:
[2015-11-09 22:35:02,976][spider2.py:182][INFO] - 准备获取网页内容(超时设置:60秒):http://365.XXXXX.com/xtu/
2.2 记录访问历史
这里记录URL的访问历史是为了防止执行重复任务,在内存中保持一个Set就能满足需求,在磁盘上可以简单的保存成一个TXT文件,每个URL保存成一行即可。所以这里是逻辑顺序应该是在初始化时创建一个Set用来保存访问历史,任务执行之前从数据库中加载访问历史,如果是首次运行尚未创建数据库还需要进行一次创建操作。然后就好办了,每次完成一个URL的访问就保存一下访问记录。相关代码如下:
# 类初始化
def __init__(self):
self.contentFolder = u"抓取内容"
self.dbName = "url.db" # 1、定义数据库文件名
self.createFolder(self.contentFolder) # 2、创建内容存储目录
self.urlDB = set() # 3、创建内存数据库 # 获取URL数据库以获取爬过的网页地址
def loadDatabase(self):
isExists = os.path.exists(self.dbName) # 4、首先判断是否是首次运行,如果数据库文件不存在则创建一下
if not isExists:
logging.info(u"创建URL数据库文件:'" + self.dbName + u"'")
f = open(self.dbName, 'w+')
f.write("#Create time: " + time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(time.time())) + '\n')
f.close()
return
db = open(self.dbName, 'r') # 5、从磁盘中加载数据库
for line in db.readlines():
if not line.startswith('#'):
self.urlDB.add(line.strip('\n'))
db.close()
logging.info(u"URL数据库加载完成!") # 追加数据库文件
def writeToDatabase(self, url): # 6、在系统运行过程中,如需记录日志,追加日志内容即可
db = open(self.dbName, 'a')
db.write(url + '\n')
db.close()
有了上面的代码,在记录日志过程中就很方便了:
succeed = self.saveImgs(images, folderName)
if succeed:
self.urlDB.add(folderURL)
self.writeToDatabase(folderURL)
2.3 异常处理
访问网络资源不可避免的会有很多异常情况,要处理这些异常情况才能稳定运行,Python的异常处理很简单,请参考如下获取网页的代码段:
# 获取索引页面的内容
def getPage(self, pageURL, second):
try:
request = urllib2.Request(pageURL)
response = urllib2.urlopen(request, timeout = second)
data = response.read()
return data.decode('gbk'), True
except urllib2.HTTPError,e: # HTTPError必须排在URLError的前面
logging.error("HTTPError code:" + str(e.code) + " - Content:" + e.read())
return "", False
except urllib2.URLError, e:
logging.error("URLError reason:" + str(e.reason) + " - " + str(e))
return "", False
except Exception, e: # 其他所有类型的异常
logging.error(u"获取网页失败:" + str(e))
return "", False # 这里返回两个值方便判断
2.4 网页自动编码判断
昨天在爬取网页的过程中突然发现,有的页面居然说编码不能通过utf-8进行解析,我看了看有的网页确实不是utf-8编码的,那怎么办呢?怎么才能自动进行解码?从网上可以搜索到一个Python的开源库很好用,叫做chardet,默认Python2.7是不带的需要下载,比如我下载的是:chardet-2.3.0.tar.gz
有了这个压缩包解压出来cahrdet子文件夹拷贝到:C:\Python27\Lib\site-packages目录下即可。下面看看用法实例:
import chardet # 获取页面所有图片
def getAllImgURL(self, infoURL):
images = []
succeed = True
try:
data = urllib2.urlopen(infoURL).read() # 1、先获取网页内容
chardet1 = chardet.detect(data) # 2、再调用该模块的方法自动判断网页编码
page = data.decode(str(chardet1['encoding'])) # 3、注意,得到的chardet1是一个字典类似于:{'confidence': 0.98999999999999999, 'encoding': 'GB2312'} # 第一种解码格式:
pattern = re.compile('<option value="(.*?)">(.*?)</option>')
items = re.findall(pattern, page)
# item[0]为图片URL尾部,item[1]为图片名称
for item in items:
imageURL = infoURL + item[0]
if imageURL in self.urlDB:
logging.info(u"获得图片URL(曾被访问,跳过):" + imageURL)
else:
logging.info(u"获得图片URL:" + imageURL)
images.append(imageURL) # 第二种解码格式
pattern = re.compile('<IMG src="(.*?)".*?>')
items = re.findall(pattern, page)
# item为图片URL
for item in items:
if item.startswith('http://'): # 4、这里也注意一下,在这种网页中相对路径的图片都是插图之类的小图片不需要下载,所以过滤掉了。
if item in self.urlDB:
logging.info(u"获得图片URL(曾被访问,跳过):" + item)
else:
logging.info(u"获得图片URL:" + item)
images.append(item) except Exception, e:
logging.warning(u"在获取子路径图片列表时出现异常:" + str(e))
succeed = False
return images, succeed
2.5 远程主机重置链接(Errno 10054)
在今天的爬取过程中我发现了一个问题,爬到后面的内容都出错了,错误信息参见如下:
[2015-11-09 23:48:51,082][spider2.py:130][INFO] - 开始准备保存图片(超时设置:300秒):http://xz1.XXXX.com/st/st-06/images/009.jpg
[2015-11-09 23:48:55,095][spider2.py:160][ERROR] - 保存图片失败:[Errno 10054]
[2015-11-09 23:48:55,096][spider2.py:140][WARNING] - 保存图片失败(耗时:4.01399993896秒):http://xz1.XXXX.com/st/st-06/images/009.jpg
[2015-11-09 23:48:55,098][spider2.py:130][INFO] - 开始准备保存图片(超时设置:300秒):http://xz1.XXXX.com/st/st-06/images/010.jpg
[2015-11-09 23:48:56,576][spider2.py:160][ERROR] - 保存图片失败:[Errno 10054]
[2015-11-09 23:48:56,578][spider2.py:140][WARNING] - 保存图片失败(耗时:1.48000001907秒):http://xz1.XXXX.com/st/st-06/images/010.jpg
可以看到都在报这个错误代码,网上一查,发现有很多同学已经遇到过了,请参考知乎上的讨论:http://www.zhihu.com/question/27248551
从网上讨论的结果来看,可以肯定的是直接原因在于“远程主机主动关闭了当前链接”,而根本原因则在于:网站启用了反爬虫的策略,也就是说我的爬虫爬的过快并且被发现不是真正的浏览器浏览了。怎么办了?针对这两个原因逐个处理,一是伪装成浏览器,二是不要访问的过快,三是每次访问完成都关闭链接。相关代码如下:
# 传入图片地址,文件名,超时时间,保存单张图片
def saveImg(self, imageURL, fileName, second):
try:
headers = {'User-agent' : 'Mozilla/5.0 (Windows NT 6.2; WOW64; rv:22.0) Gecko/20100101 Firefox/22.0'} # 1、这里构造一个浏览器的头部
request = urllib2.Request(imageURL, headers = headers)
u = urllib2.urlopen(request, timeout = second) # 2、这里的超时设置timeout不要太长
data = u.read()
f = open(fileName, 'wb')
f.write(data)
f.close()
u.close() # 3、注意这里的链接要主动调用一下关闭
return True
except urllib2.HTTPError,e: #HTTPError必须排在URLError的前面
logging.error("HTTPError code:" + str(e.code) + " - Content:" + e.read())
return False
except urllib2.URLError, e:
logging.error("URLError reason:" + str(e.reason) + " - " + str(e))
return False
except Exception, e:
logging.error(u"保存图片失败:" + str(e))
return False # 4、注意调用完这个函数之后再time.sleep(1)一下,防止过快访问被发现了,呵呵
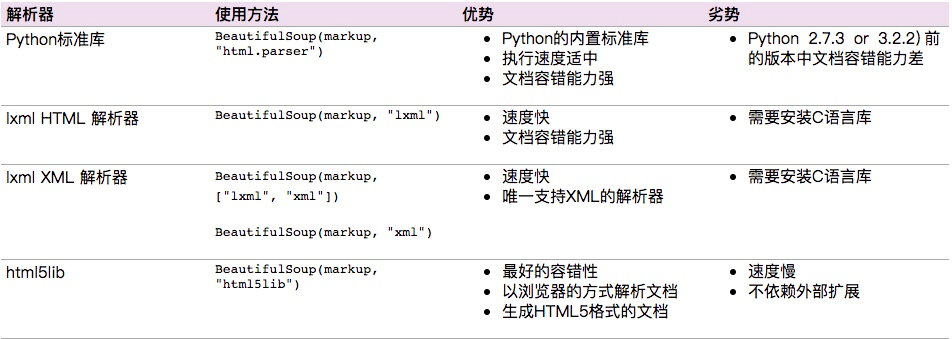
2.6 使用BeautifulSoup来分析网页
使用正则表达式来匹配网页中的字段确实是太费劲了。用BeautifulSoup就省力多了,功能很强大:
soup = BeautifulSoup(page_data, 'lxml')
entries = soup.find_all(src=re.compile('.jpg'), border='') # 找到所有字段为src正则匹配的标签内容,同时增加一个约束条件是border=‘0’
Beautiful Soup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,如果我们不安装它,则 Python 会使用 Python默认的解析器,lxml 解析器更加强大,速度更快,推荐安装。
Python爬虫(图片)编写过程中遇到的问题的更多相关文章
- Selenium2学习-018-WebUI自动化实战实例-016-自动化脚本编写过程中的登录验证码问题
日常的 Web 网站开发的过程中,为提升登录安全或防止用户通过脚本进行黄牛操作(宇宙最贵铁皮天朝魔都的机动车牌照竞拍中),很多网站在登录的时候,添加了验证码验证,而且验证码的实现越来越复杂,对其进行脚 ...
- 利用Gulp实现JSDoc 3的文档编写过程中的实时解析和效果预览
### 利用Gulp实现JSDoc 3的文档编写过程中的实时解析和效果预览 http://segmentfault.com/a/1190000002583569
- 【lombok】使用lombok注解,在代码编写过程中可以调用到get/set方法,但是在编译的时候无法通过,提示找不到get/set方法
错误如题:使用lombok注解,在代码编写过程中可以调用到get/set方法,但是在编译的时候无法通过,提示找不到get/set方法 报错如下: 解决方法: 1.首先查看你的lombok插件是否下载安 ...
- python爬虫爬取内容中,-xa0,-u3000的含义
python爬虫爬取内容中,-xa0,-u3000的含义 - CSDN博客 https://blog.csdn.net/aiwuzhi12/article/details/54866310
- appium+python+android+HTMLTestRunner使用过程中的问题
1:问:appium客户端刚发布了一版新的,我想升级可以吗?答:建议对于刚发布的新版本不要立即升级,因为客户端每升级一版它肯定会去增加和删减一些语句.所以不建议立即升级. 应该先采取调研的态度看 ...
- [持续更新] Python学习、使用过程中遇见的非代码层面知识(想不到更好的标题了 T_T)
写在前面: 这篇博文记录的不是python代码.数据结构.算法相关的内容,而是在学习.使用过程中遇见的一些没有技术含量,但有时很令人抓耳挠腮的小东西.比如:python内置库怎么看.python搜索模 ...
- python 爬虫001-http请求过程
HTTP 请求流程 一次完整的HTTP请求过程从TCP三次握手建立连接成功后开始,客户端按照指定的格式开始向服务端发送HTTP请求,服务端接收请求后,解析HTTP请求,处理完业务逻辑,最后返回一个HT ...
- Python爬虫之编写一个可复用的下载模块
看用python写网络爬虫第一课之编写可复用的下载模块的视频,发现和<用Python写网络爬虫>一书很像,写了点笔记: #-*-coding:utf-8-*- import urllib2 ...
- Python - 装饰器使用过程中的误区
曾灵敏 - APRIL 27, 2015 装饰器基本概念 大家都知道装饰器是一个很著名的设计模式,经常被用于AOP(面向切面编程)的场景,较为经典的有插入日志,性能测试,事务处理,Web权限校验, C ...
随机推荐
- iOS中的多线程及GCD
多线程中的一些概念 //任务:代码段 方法 线程就是执行这些任务 //NSThread类 创建线程 执行线程 [NSThread isMainThread]//判断是否是主线程 #import & ...
- 提示gtk错误,无法打开便器器(sudo gedit filename失败)
解决方法:安装gtksource,命令 sudo apt-get install gir1.2-gtksource-3.0
- 70. Climbing Stairs
You are climbing a stair case. It takes n steps to reach to the top. Each time you can either climb ...
- ZOJ 1056 The Worm Turns
原题链接 题目大意:贪吃蛇的简化版,给出一串操作命令,求蛇的最终状态是死是活. 解法:这条蛇一共20格的长度,所以用一个20个元素的队列表示,队列的每个元素是平面的坐标.每读入一条指令,判断其是否越界 ...
- soapUI 在多个测试套件 testsuite 里,多个testcase里传值如何实现
1.首先 要添加一个全局 自定义变量 Custom Properties 2.用transfer property 将取来的值 放入到变量 getToken 里 3.在另一个testc ...
- java的加减乘除
//编写一个程序,用户输入两个数,求出其加减乘除,并用消息框显示计算结果.//MengYao,2015,10,6 import javax.swing.JOptionPane;public class ...
- timus 1982 Electrification Plan(最小生成树)
Electrification Plan Time limit: 0.5 secondMemory limit: 64 MB Some country has n cities. The govern ...
- 第二章 C语言编程实践
上章回顾 宏定义特点和注意细节 条件编译特点和主要用处 文件包含的路径查询规则 C语言扩展宏定义的用法 第二章 第二章 C语言编程实践 C语言编程实践 预习检查 异或的运算符是什么 宏定义最主要的特点 ...
- Nginx-/etc/sysctl.conf 参数解释
来自<深入理解Nginx模块开发与架构解析> P9 #表示进程(例如一个worker进程)可能同时打开的最大句柄数,直接限制最大并发连接数 fs. #1代表允许将状态为TIME-WAIT状 ...
- Unity3D研究院编辑器之脚本设置ToolBar
Unity版本5.3.2 如下图所示,ToolBar就是Unity顶部的那一横条.这里的所有按钮一般情况下都得我们手动的用鼠标去点击.这篇文章我们说说如果自动操作它们 1.自动点击左边四个按钮 (拖动 ...