Mongos与集群均衡
版权声明:本文由孔德雨原创文章,转载请注明出处:
文章原文链接:https://www.qcloud.com/community/article/190
来源:腾云阁 https://www.qcloud.com/community
mongodb 可以以单复制集的方式运行,client 直连mongod读取数据。
单复制集的方式下,数据的水平扩展的责任推给了业务层解决(分实例,分库分表),mongodb原生提供集群方案,该方案的简要架构如下: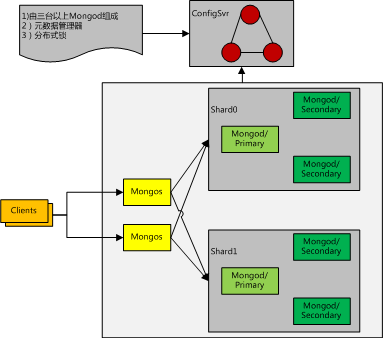
mongodb集群是一个典型的去中心化分布式集群。mongodb集群主要为用户解决了如下问题:
- 元数据的一致性与高可用(Consistency + Partition Torrence)
- 业务数据的多备份容灾(由复制集技术保证)
- 动态自动分片
- 动态自动数据均衡
下文通过介绍mongodb集群中各个组成部分,逐步深入剖析mongodb集群原理。
ConfigServer
mongodb元数据全部存放在configServer中,configServer 是由一组(至少三个)mongod实例组成的集群。
configServer 的唯一功能是提供元数据的增删改查。和大多数元数据管理系统(etcd,zookeeper)类似,也是保证一致性与分区容错性。本身不具备中心化的调度功能。
ConfigServer与复制集
ConfigServer的分区容错性(P)和数据一致性(C)是复制集本身的性质。
MongoDb的读写一致性由WriteConcern和ReadConcern两个参数保证。
writeConcern https://docs.mongodb.com/v3.2/reference/write-concern/
readConcern https://docs.mongodb.com/v3.2/reference/read-concern/
两者组合可以得到不同的一致性等级。
指定 writeConcern:majority 可以保证写入数据不丢失,不会因选举新主节点而被回滚掉。
readConcern:majority + writeConcern:majority 可以保证强一致性的读
readConcern:local + writeConcern:majority 可以保证最终一致性的读
mongodb 对configServer全部指定writeConcern:majority 的写入方式,因此元数据可以保证不丢失。
对configServer的读指定了ReadPreference:PrimaryOnly的方式,在CAP中舍弃了A与P得到了元数据的强一致性读。
Mongos
数据自动分片
对于一个读写操作,mongos需要知道应该将其路由到哪个复制集上,mongos通过将片键空间划分为若干个区间,计算出一个操作的片键的所属区间对应的复制集来实现路由。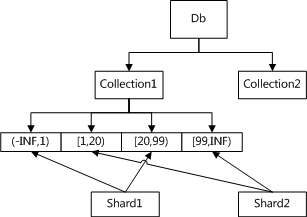
Collection1 被划分为4个chunk,其中
chunk1 包含(-INF,1) , chunk3 包含[20, 99) 的数据,放在shard1上。
chunk2 包含 [1,20), chunk4 包含[99, INF) 的数据,放在shard2上。
chunk 的信息存放在configServer 的mongod实例的 config.chunks 表中,格式如下:
{
"_id" : "mydb.foo-a_\"cat\"",
"lastmod" : Timestamp(1000, 3),
"lastmodEpoch" : ObjectId("5078407bd58b175c5c225fdc"),
"ns" : "mydb.foo",
"min" : { "animal" : "cat" },
"max" : { "animal" : "dog" },
"shard" : "shard0004"
}
值得注意的是:chunk是一个逻辑上的组织结构,并不涉及到底层的文件组织方式。
启发式触发chunk分裂
mongodb 默认配置下,每个chunk大小为16MB。超过该大小就需要执行chunk分裂。chunk分裂是由mongos发起的,而数据放在mongod处,因此mongos无法准确判断每个增删改操作后某个chunk的数据实际大小。因此mongos采用了一种启发式的触发分裂方式:
mongos在内存中记录一份 chunk_id -> incr_delta 的哈希表。
对于insert和update操作,估算出incr_delta的上界(WriteOp::targetWrites), 当incr_delta超过阈值时,执行chunk分裂。
值得注意的是:
1) chunk_id->incr_delta 是维护在mongos内存里的一份数据,重启后丢失
2) 不同mongos之间的这份数据相互独立
3) 不带shardkey的update 无法对 chunk_id->incr_delta 作用
因此这个启发式的分裂方式很不精确,而除了手工以命令的方式分裂之外,这是mongos自带的唯一的chunk分裂方式。
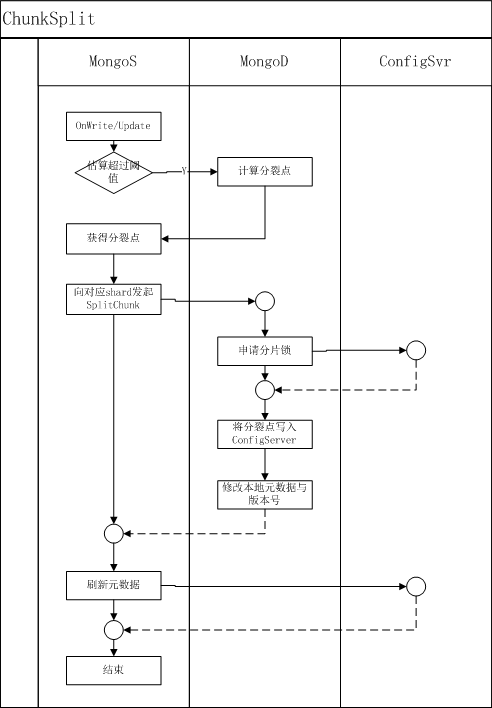
chunk分裂的执行过程
1) 向对应的mongod 发起splitVector 命令,获得一个chunk的可分裂点
2) mongos 拿到这些分裂点后,向mongod发起splitChunk 命令
splitVector执行过程:
1) 计算出collection的文档的 avgRecSize= coll.size/ coll.count
2) 计算出分裂后的chunk中,每个chunk应该有的count数, split_count = maxChunkSize / (2 * avgRecSize)
3) 线性遍历collection 的shardkey 对应的index的 [chunk_min_index, chunk_max_index] 范围,在遍历过程中利用split_count 分割出若干spli
splitChunk执行过程:
1) 获得待执行collection的分布式锁(向configSvr 的mongod中写入一条记录实现)
2) 刷新(向configSvr读取)本shard的版本号,检查是否和命令发起者携带的版本号一致
3) 向configSvr中写入分裂后的chunk信息,成功后修改本地的chunk信息与shard的版本号
4) 向configSvr中写入变更日志
5) 通知mongos操作完成,mongos修改自身元数据
chunk分裂的执行流程图:
问题与思考
问题一:为何mongos在接收到splitVector的返回后,执行splitChunk 要放在mongod执行而不是mongos中呢,为何不是mongos自己执行完了splitChunk再通知mongod 修改元数据?
我们知道chunk元数据在三个地方持有,分别是configServer,mongos,mongod。如果chunk元信息由mongos更改,则其他mongos与mongod都无法第一时间获得最新元数据。可能会发生这样的问题,如下图描述: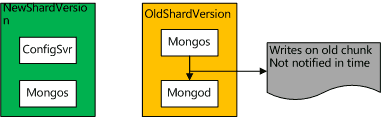
Mongos对元数据的修改还没有被mongod与其他mongos感知,其他mongos与mongod的版本号保持一致,导致其他mongos写入错误的chunk。
如果chunk元信息由mongod更改,mongod 先于所有的mongos感知到本shard的元数据被更改,由于mongos对mongod的写入请求都会带有版本号(以发起者mongos的POV 持有的版本号),mongod发现一个读写带有的版本号低于自身版本号时就会返回 StaleShardingError,从而避免对错误的chunk进行读写。
Mongos对读写的路由
读请求:
mongos将读请求路由到对应的shard上,如果得到StaleShardingError,则刷新本地的元数据(从configServer读取最新元数据)并重试。
写请求:
mongos将写请求路由到对应的shard上,如果得到StaleShardingError,并不会像读请求一样重试,这样做并不合理,截至当前版本,mongos也只是列出了一个TODO(batch_write_exec.cpp:185)
185 // TODO: It may be necessary to refresh the cache if stale, or maybe just
186 // cancel and retarget the batch
chunk迁移
chunk迁移由balancer模块执行,balancer模块并不是一个独立的service,而是mongos的一个线程模块。同一时间只有一个balancer模块在执行,这一点是mongos在configServer中注册分布式锁来保证的。
balancer 对于每一个collection的chunk 分布,计算出这个collection需要进行迁移的chunk,以及每个chunk需要迁移到哪个shard上。计算的过程在BalancerPolicy 类中,比较琐碎。
chunk迁移.Step1
MigrationManager::scheduleMigrations balancer对于每一个collection,尝试获得该collection的分布式锁(向configSvr申请),如果获得失败,表明该collection已有正在执行的搬迁任务。这一点说明对于同一张表统一时刻只能有一个搬迁任务。如果这张表分布在不同的shard上,完全隔离的IO条件可以提高并发,不过mongos并没有利用起来这一点。
如果获得锁成功,则向源shard发起moveChunk 命令
chunk迁移.Step2
mongod 执行moveChunk命令
cloneStage
1) 源mongod 根据需要迁移的chunk 的上下限构造好查询计划,基于分片索引的扫描查询。并向目标mongod发起recvChunkStart 指令,让目标chunk 开始进入数据拉取阶段。
2) 源mongod对此阶段的修改, 将id字段buffer在内存里(MigrationChunkClonerSourceLegacy类),为了防止搬迁时速度过慢buffer无限制增长,buffer大小设置为500MB,在搬迁过程中key的更改量超过buffer大小会导致搬迁失败。
3) 目标mongod 在接收到recvChunkStart命令后
a. 基于chunk的range,将本mongod上的可能脏数据清理掉
b. 向源发起_migrateClone指定,通过1)中构造好的基于分配索引的扫描查询得到该chunk 数据的snapshot
c. 拷贝完snapshot后,向源发起_transferMods命令,将2)中维护在内存buffer中的修改
d. 源在收到_transferMods后,通过记录的objid查询对应的collection,将真实数据返回给目标。
e. 目标在收完_transferMods 阶段的数据后,进入steady状态,等待源接下来的命令。这里有必要说明的是:用户数据源源不断的写入,理论上_transferMods 阶段会一直有新数据,但是必须要找到一个点截断数据流,将源的数据(搬迁对应的chunk的数据)设置为不可写,才能发起路由更改。因此这里所说的“_transferMods阶段的所有数据”只是针对于某个时间点,这个时间点过后依然会有新数据进来。
f. 源心跳检查目标是否已经处于steady状态,如果是,则封禁chunk的写入,向目标发起_recvChunkCommit命令,之后源的chunk上就无修改了。
g. 目标收到_recvChunkCommit命令后,拉取源chunk上的修改并执行,执行成功后源解禁路由并清理源chunk的数据
流程图如下: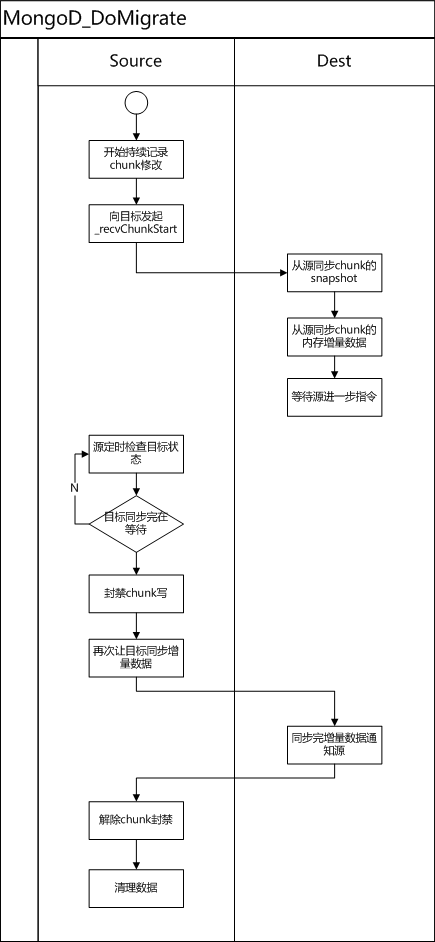
总结
经过分析,我们发现Mongos在迁移方面有很大的待提升空间
1) 一张表同一时间只能有一个chunk在搬迁,没有充分利用不同机器之间的IO隔离来做并发提速。
2) 搬迁时需要扫描源的数据集,一方面会与业务争QPS,一方面会破坏(如果是Mmap引擎)热点读写的working-set
3) Mongos启发式分裂chunk的方式极不靠谱,mongos重启后,启发信息就丢失了,而且部分常见的写入模式也不会记录启发信息
经过CMongo团队的测试,mongos自带的搬迁方案处理100GB的数据需要33小时。CMongo团队分析了mongos自带的搬迁方案的缺陷,自研了一套基于备份的搬迁方案,速度有30倍以上的提升,敬请期待!
Mongos与集群均衡的更多相关文章
- Akka(11): 分布式运算:集群-均衡负载
在上篇讨论里我们主要介绍了Akka-Cluster的基本原理.同时我们也确认了几个使用Akka-Cluster的重点:首先,Akka-Cluster集群构建与Actor编程没有直接的关联.集群构建是A ...
- MongoDB笔记: 分片集群
MongoDB分片集群由三个模块组成 shard: 分片(或者分区)模块, 每个分片分别存储一部分数据, 从MongoDB 3.6开始, 分片必须是replica set(副本集) mongos: m ...
- MongoDB分片集群机制及原理
1. MongoDB常见的部署架构 * 单机版 * 复制集 * 分片集群 2. 为什么要使用分片集群 * 数据容量日益增大,访问性能日渐下降,怎么破? * 新品上线异常火爆,如何支撑更多用户并发? * ...
- mongoDB研究笔记:分片集群部署
前面几篇文章的分析复制集解决了数据库的备份与自动故障转移,但是围绕数据库的业务中当前还有两个方面的问题变得越来越重要.一是海量数据如何存储?二是如何高效的读写海量数据?尽管复制集也可以实现读写分析,如 ...
- 【MongoDB】在windows平台下搭建mongodb的分片集群(二)
在上一片博客中我们讲了Mongodb数据库中分片集群的主要原理. 在本篇博客中我们主要讲描写叙述分片集群的搭建过程.配置分片集群主要有两个步骤.第一启动全部须要的mongod和mongos进程. 第二 ...
- Mongodb集群搭建之 Sharding+ Replica Sets集群架构(2)
参考http://blog.51cto.com/kaliarch/2047358 一.概述 1.1 背景 为解决mongodb在replica set每个从节点上面的数据库均是对数据库的全量拷贝,从节 ...
- mongodb sharding集群搭建
创建虚拟机,如果是使用copy的方式安装系统,记得修改机器名,否则所有的机器名称都一样,会造成安装失败 同时关闭掉防火墙,将所有的机器的时间调成一致,master和slave的heartbeat间隔不 ...
- MongoDB 高可用集群架构简介
在大数据的时代,传统的关系型数据库要能更高的服务必须要解决高并发读写.海量数据高效存储.高可扩展性和高可用性这些难题.不过就是因为这些问题Nosql诞生了. 转载自严澜的博文——<如何搭建高效的 ...
- MongoDB集群——分片
1. 分片的结构及原理分片集群结构分布: 分片集群主要由三种组件组成:mongos,config server,shard1) MONGOS数据库集群请求的入口,所有的请求都通过mongos进行协调, ...
随机推荐
- centos 3d特效
说下我怎么实现的吧 1.现在新力得里搜“XGL”和“Compiz”,把相关软件安装好. 2.安装ndivid的glx驱动: sudo apt-get install nvidia-kernel-com ...
- JS结构图
- VC++ 监控指定目录改变
转载:http://www.cnblogs.com/doublesnke/archive/2011/08/16/2141374.html VC++实施文件监控:实例和详解 相关帮助: http://h ...
- 【leetcode❤python】409. Longest Palindrome
#-*- coding: UTF-8 -*- from collections import Counterclass Solution(object): def longestPalindro ...
- XShell 安装与虚拟机连接
XShell:是liunx的远程管理工具 为啥要用这个工具呢?因为在古老的liunx字符命令下,是看不到中文的,要么使用liunx的图形化界面(支持中文),要么使用远程管理工具,是在windows中的 ...
- [C程序设计语言]第一部分
声明:原创作品,转载时请注明文章来自SAP师太技术博客( 博/客/园www.cnblogs.com):www.cnblogs.com/jiangzhengjun,并以超链接形式标明文章原始出处,否则将 ...
- CUBRID学习笔记 21 查看主键外键索引
命令 show create table game; game是表名 在web管理中,请在sql标签中查,不要在query中执行. show create table game; === <Re ...
- python_way ,自定义session
python_way ,自定义session container = {} #可以是数据库,可以是缓存也可以是文件 class Session: def __init__(self, handler) ...
- 2013/7/16 HNU_训练赛4
CF328B Sheldon and Ice Pieces 题意:给定一个数字序列,问后面的数字元素能够组成最多的组数. 分析:把2和5,6和9看作是一个元素,然后求出一个最小的组数就可以了. #in ...
- c++操作io常见命令
用c++练习下 系统常见io命令. 1)显示文档的文本 2)统计文本单词数字 3)列出目录所有文件 ,递归思路 4)查找第一个匹配的字符. 5)文本单词排序, 快速排序,其实还是递归思路 6)文本单词 ...