MySQL数据库优化总结
对于一个以数据为中心的应用,数据库的好坏直接影响到程序的性能,因此数据库性能至关重要。一般来说,要保证数据库的效率,要做好以下四个方面的工作:数 据库设计、sql语句优化、数据库参数配置、恰当的硬件资源和操作系统,这个顺序也表现了这四个工作对性能影响的大小。下面我们逐个阐明:
一、数据库设计
适度的反范式,注意是适度的
我们都知道三范式,基于三范式建立的模型是最有效保存数
据的方式,也是最容易扩展的模式。我们在开发应用程序时,设计的数据库要最大程度的遵守三范式,特别是对于OLTP型的系统,三范式是必须遵守的规则。当
然,三范式最大的问题在于查询时通常需要join很多表,导致查询效率很低。所以有时候基于性能考虑,我们需要有意的违反三范式,适度的做冗余,以达到提
高查询效率的目的。注意这里的反范式是适度的,必须为这种做法提供充分的理由。下面就是一个糟糕的实例:
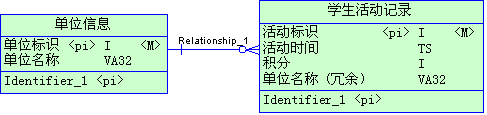
在这里,为了提高学生活动记录的检索效率,把单位名称冗余到学生活动记录表里。单位信息有500条记录,而学生活动记录在一年内大概有200万数据量。
如果学生活动记录表不冗余这个单位名称字段,只包含三个int字段和一个timestamp字段,只占用了16字节,是一个很小的表。而冗余了一个
varchar(32)的字段后则是原来的3倍,检索起来相应也多了这么多的I/O。而且记录数相差悬殊,500 VS 2000000
,导致更新一个单位名称还要更新4000条冗余记录。由此可见,这个冗余根本就是适得其反。
下面这个冗余就很好
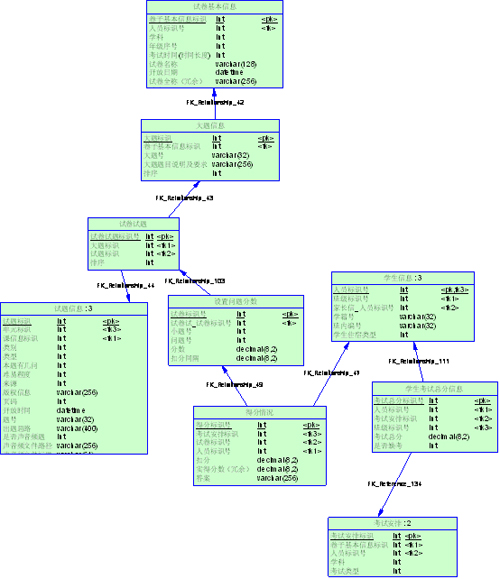
可以看到,[学生考试总分]是冗余的,这个分数完全可以通过[得分情况]汇总得到。在【学生考试总分】里,一次考试一个学生只有一条记录,而在【得分情
况】里,一个学生针对试卷里一个小题的一个小问一条记录,粗略的算一下比例大概是1:100。而且判卷子得分是不会轻易变的,更新的频率不高,所以说这个
冗余是比较好的。
适当建立索引
说起提高数据库性能,索引是最物美价廉的东西了。不用加内存,不用改程序,不用调sql,只要执行个正确的’create index’,查询速度就可能提高百倍千倍,这可真有诱惑力。可是天下没有免费的午餐,查询速度的提高是以插入、更新、删除的速度为代价的,这些写操作,增加了大量的I/O。由于索引的存储结构不同于表的存储,一个表的索引所占空间比数据所占空间还大的情况经常发生。这意味着我们在写数据库的时候做了很多额外的工作,而这个工作只是为了提高读的效率。因此,我们建立一个索引,必须保证这个索引不会“亏本”。一般需要遵守这样的规则:
索引的字段必须是经常作为查询条件的字段;
如果索引多个字段,第一个字段要是经常作为查询条件的。如果只有第二个字段作为查询条件,这个索引不会起到作用;
索引的字段必须有足够的区分度;
Mysql 对于长字段支持前缀索引;
对表进行水平划分
如果一个表的记录数太多了,比如上千万条,而且需要经常检索,那么我们就有必要化整为零了。如果我拆成100个表,那么每个表只有10万条记录。当然这
需要数据在逻辑上可以划分。一个好的划分依据,有利于程序的简单实现,也可以充分利用水平分表的优势。比如系统界面上只提供按月查询的功能,那么把表按月
拆分成12个,每个查询只查询一个表就够了。如果非要按照地域来分,即使把表拆的再小,查询还是要联合所有表来查,还不如不拆了。所以一个好的拆分依据是
最重要的。
这里有个比较好的实例

每个学生做过的题都记录在这个表里,包括对题和错题。每个题会对应一个或多个知识点,我们需要根据错题来分析学生在哪个知识点上掌握的不足。这个表很容
易达到千万级,迫切需要拆分,那么根据什么来拆呢?从需求上看,无论是老师还是学生,最终会把焦点落在一个学生的身上。学生会关心自己,老师会关心自己班
的学生。而且每个学科的知识点是不同的。所以我们很容易想到,联合学科和知识点两个字段来拆分这个表。这样拆下来,每个表大概2万条数据,检索效率非常
高。
对表进行垂直划分
有些表记录数并不多,可能也就2、3万条,但是字段却很长,表占用空间很大,检索表时需要执行大量I/O,严重降低了性能。这个时候需要把大的字段拆分到另一个表,并且该表与原表是一对一的关系。
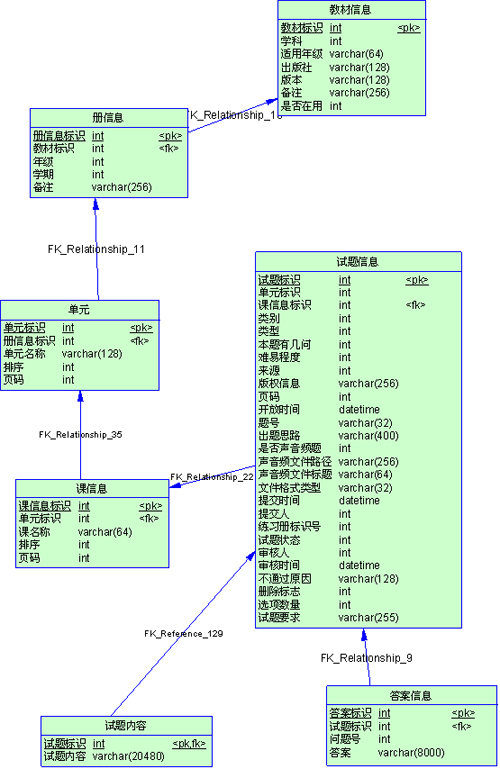
【试题内容】、【答案信息】两个表,最初是作为几个字段添加到【试题信息】里的,可以看到试题内容和答案这两个字段很长,在表里有3万记录时,表已经占
了1G的空间,在列试题列表时非常慢。经过分析,发现系统很多时候是根据【册】、【单元】、类型、类别、难易程度等查询条件,分页显示试题详细内容。而每
次检索都是这几个表做join,每次要扫描一遍1G的表,很郁闷啊。我们完全可以把内容和答案拆分成另一个表,只有显示详细内容的时候才读这个大表,由此
就产生了【试题内容】、【答案信息】两个表。
选择适当的字段类型,特别是主键
选择字段的一般原则是保小不保大,能用占用字节小的字段就不用大字段。比如主键,
我们强烈建议用自增类型,不用guid,为什么?省空间啊?空间是什么?空间就是效率!按4个字节和按32个字节定位一条记录,谁快谁慢太明显了。涉及到
几个表做join时,效果就更明显了。值得一提的是,datetime和timestamp,datetime占用8个字节,而timestamp占用4
个字节,只用了一半,而timestamp表示的范围是1970—2037,对于大多数应用,尤其是记录什么考试时间,登录时间这类信息,绰绰有余啊。
文件、图片等大文件用文件系统存储,不用数据库
不用多说,铁律!!!数据库只存储路径。
外键表示清楚,方便建立索引
我们都知道,在powerdesigner里为两个实体建立关系,生成物理模型时会自动给外键建立索引。所以我们不要怕建立关系把线拉乱,建立个ShortCut就好了。
掌握表的写入时机
在库模式相同的情况下,如何使用数据库也对性能有着重要作用。同样是写入一个表,先写和后写对后续的操作会产生很大影响。例如在上面提到的适度冗余里的例子,
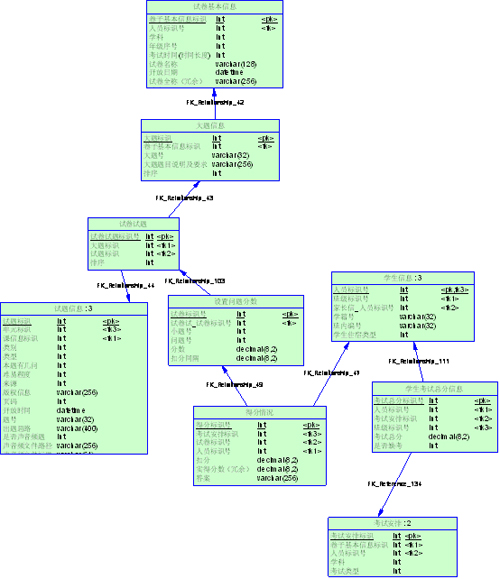
我们最初的目的是记录考生的总分,以达到提高检索效率的目的,也就是在录入成绩时写入这个表。在需求里有这样的要求:列出本次考试的所有学生成绩,没有
录入成绩的也显示该学生名称,只是总分显示为空。这个查询就需要用【学生信息】left outer join
【学生考试总分信息】,大家都知道outer join
的效率比join是要低的,为了避免这个问题,我们就在布置考试的时候写入这个表,把所有学生都插入进去,分数都是null,这样一来我们就可以用
join达到这个效果了。而且还有这样的好处:在某次考试中,安排了一个班所有学生考试,所有学生都录入了成绩。现在班里转来一个新生,那么在此时如果查
询学生成绩,就会列出这个新生,结果是未录入成绩,这显然是不对的。如果在安排的时候就写入,就可以记录下该次考试中实际的考生了,这个表的作用,也就不
知是冗余了。
宁可集中批量操作,避免频繁读写
系统里包含了积分部分,学生和老师通过系统做了操作都可以获得积分,而且积分规
则很复杂,限制每类操作获得积分不同,每人每天每类积分都有上限。比如登录,一次登录就可以获得1分,但是不管你登录多少次,一天只能累积一个登录积分。
这个还是简单的,有的积分很变态,比如老师积分中有一类是看老师判作业的情况,规则是:老师判了作业,发现学生有错的,学生改过了,老师再判,如果这时候
学生都对了,就给老师加分,如果学生还是错的,那就接着改,知道学生都改对了,老师都判完了,才能给老师加分。如果用程序来处理,很可能每个功能都会额外
的写一堆代码来处理这个鸡肋似的积分。不仅编程的同事干活找不到重点,还平白给数据库带来了很大的压力。经过和需求人员的讨论,确定积分没有必要实时累
积,于是我们采取后台脚本批量处理的方式。夜深人静的时候,让机器自己玩去吧。
这个变态的积分规则用批处理读出来是这样的:
1 select person_id, @semester_id, 301003, 0, @one_marks, assign_date, @one_marks2 from hom_assignmentinfo ha, hom_assign_class hac3 where ha.assignment_id = hac.assignment_id4 and ha.assign_date between @time_begin and @time_end5 and ha.assignment_id not in6 (7 select haa.assignment_id from hom_assignment_appraise haa, hom_check_assignment hca8 where haa.appraise_id = hca.appraise_id and haa.if_submit=19 and (10 (hca.recheck_state = 3004001 and hca.check_result in (3003002, 3003003) )11 or12 (hca.recheck_state = 3004002 and hca.recheck_result in (3003002, 3003003))13 )14 )15 and ha.assignment_id not in16 (17 select assignment_id from hom_assignment_appraise where if_submit=0 and result_type = 018 )19 and ha.assignment_id in 20 (21 select haa.assignment_id from hom_assignment_appraise haa, hom_check_assignment hca22 where haa.appraise_id = hca.appraise_id and haa.if_submit=123 and hca.check_result in (3003002, 3003003)24 ); |
这还只是个中间过程,这要是用程序实时处理,即使编程人员不罢工,数据库也会歇了。
选择合适的引擎
Mysql提供了很多种引擎,我们用的最多的是myisam,innodb,memory这三类。官方手册上说道myisqm比innodb的读速度要
快,大概是3倍。不过书不能尽信啊,《OreIlly.High.Performance.Mysql》这本书里提到了myisam和innodb的比
较,在测试中myisam的表现还不及innodb。至于memory,哈哈,还是比较好用的。在批处理种作临时表是个不错的选择(如果内存够大)。在我的一个批处理中,速度比近乎1:10。
二、SQL语句优化
Sql语句优化工具
·慢日志
如果发现系统慢了,又说不清楚是哪里慢,那么就该用这个工具了。只需要为mysql配置参数,mysql会自己记录下来慢的sql语句。配置很简单,参数文件里配置:
slow_query_log=d:/slow.txt
long_query_time = 2
就可以在d:/slow.txt里找到执行时间超过2秒的语句了,根据这个文件定位问题吧。
·mysqldumpslow.pl
慢日志文件可能会很大,让人去看是很难受的事。这时候我们可以通过mysql自带的工具来分析。这个工具可以格式化慢日志文件,对于只是参数不同的语句
会归类类并,比如有两个语句select * from a where id=1 和select * from a where
id=2,经过这个工具整理后就只剩下select * from a where
id=N,这样读起来就舒服多了。而且这个工具可以实现简单的排序,让我们有的放矢。
Explain
现在我们已经知道是哪个语句慢了,那么它为什么慢呢?看看mysql是怎么执行的吧,用explain可以看到mysql执行计划,下面的用法来源于手册
EXPLAIN语法(获取SELECT相关信息)
EXPLAIN [EXTENDED] SELECT select_options
EXPLAIN语句可以用作DESCRIBE的一个同义词,或获得关于MySQL如何执行SELECT语句的信息:
· EXPLAIN tbl_name是DESCRIBE tbl_name或SHOW COLUMNS FROM tbl_name的一个同义词。
· 如果在SELECT语句前放上关键词EXPLAIN,MySQL将解释它如何处理SELECT,提供有关表如何联接和联接的次序。
该节解释EXPLAIN的第2个用法。
借助于EXPLAIN,可以知道什么时候必须为表加入索引以得到一个使用索引来寻找记录的更快的SELECT。
如果由于使用不正确的索引出现了问题,应运行ANALYZE TABLE更新表的统计(例如关键字集的势),这样会影响优化器进行的选择。
还可以知道优化器是否以一个最佳次序联接表。为了强制优化器让一个SELECT语句按照表命名顺序的联接次序,语句应以STRAIGHT_JOIN而不只是SELECT开头。
EXPLAIN为用于SELECT语句中的每个表返回一行信息。表以它们在处理查询过程中将被MySQL读入的顺序被列出。MySQL用一遍扫描多次联
接(single-sweep
multi-join)的方式解决所有联接。这意味着MySQL从第一个表中读一行,然后找到在第二个表中的一个匹配行,然后在第3个表中等等。当所有的
表处理完后,它输出选中的列并且返回表清单直到找到一个有更多的匹配行的表。从该表读入下一行并继续处理下一个表。
当使用EXTENDED关键字时,EXPLAIN产生附加信息,可以用SHOW WARNINGS浏览。该信息显示优化器限定SELECT语句中的表和列名,重写并且执行优化规则后SELECT语句是什么样子,并且还可能包括优化过程的其它注解。
如果什么都做不了,试试全索引扫描
如果一个语句实在不能优化了,那么还有一个方法可以试试:索引覆盖。
如果一个语句可以从索引上获取全部数据,就不需要通过索引再去读表,省了很多I/O。比如这样一个表
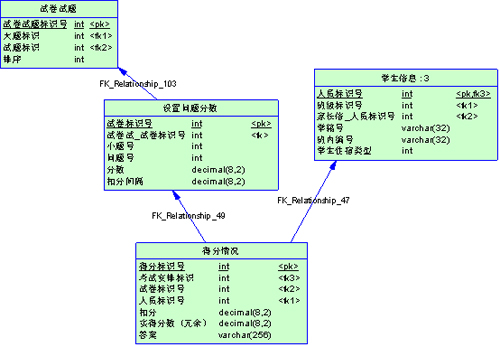
如果我要统计每个学生每道题的得分情况,我们除了要给每个表的主键外键建立索引,还要对【得分情况】的实际得分字段索引,这样,整个查询就可以从索引得到数据了。
三、数据库参数配置
最重要的参数就是内存,我们主要用的innodb引擎,所以下面两个参数调的很大
# Additional memory pool that is used by InnoDB to store metadata
# information. If InnoDB requires more memory for this purpose it will
# start to allocate it from the OS. As this is fast enough on most
# recent operating systems, you normally do not need to change this
# value. SHOW INNODB STATUS will display the current amount used.
innodb_additional_mem_pool_size = 64M
# InnoDB, unlike MyISAM, uses a buffer pool to cache both indexes and
# row data. The bigger you set this the less disk I/O is needed to
# access data in tables. On a dedicated database server you may set this
# parameter up to 80% of the machine physical memory size. Do not set it
# too large, though, because competition of the physical memory may
# cause paging in the operating system. Note that on 32bit systems you
# might be limited to 2-3.5G of user level memory per process, so do not
# set it too high.
innodb_buffer_pool_size = 5G
对于myisam,需要调整key_buffer_size
当然调整参数还是要看状态,用show status语句可以看到当前状态,以决定改调整哪些参数
Cretated_tmp_disk_tables 增加tmp_table_size
Handler_read_key 高表示索引正确 Handler_read_rnd高表示索引不正确
Key_reads/Key_read_requests 应小于0.01 计算缓存损失率,增加Key_buffer_size
Opentables/Open_tables 增加table_cache
select_full_join 没有实用索引的链接的数量。如果不为0,应该检查索引。
select_range_check 如果不为0,该检查表索引。
sort_merge_passes 排序算法已经执行的合并的数量。如果该值较大,应增加sort_buffer_size
table_locks_waited 不能立即获得的表的锁的次数,如果该值较高,应优化查询
Threads_created 创建用来处理连接的线程数。如果Threads_created较大,要增加 thread_cache_size值。
缓存访问率的计算方法Threads_created/Connections。
四、合理的硬件资源和操作系统
如果你的机器内存超过4G,那么毋庸置疑应当采用64位操作系统和64位mysql
读写分离
如果数据库压力很大,一台机器支撑不了,那么可以用mysql复制实现多台机器同步,将数据库的压力分散。
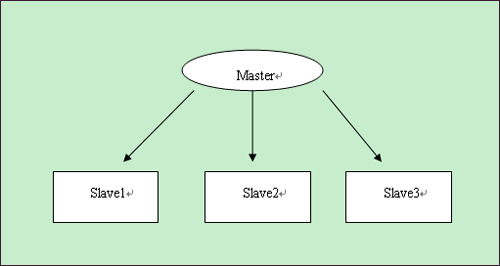
Master
Slave1
Slave2
Slave3
主库master用来写入,slave1—slave3都用来做select,每个数据库分担的压力小了很多。
要实现这种方式,需要程序特别设计,写都操作master,读都操作slave,给程序开发带来了额外负担。当然目前已经有中间件来实现这个代理,对程
序来读写哪些数据库是透明的。官方有个mysql-proxy,但是还是alpha版本的。新浪有个amobe for
mysql,也可达到这个目的,结构如下
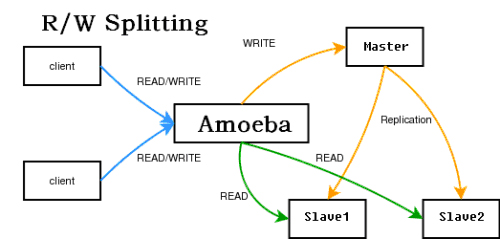
使用方法可以看amobe的手册。
转载自:http://www.cnblogs.com/villion/archive/2009/07/23/1893765.html#3020915
MySQL数据库优化总结的更多相关文章
- 关于MySQL数据库优化的部分整理
在之前我写过一篇关于这个方面的文章 <[原创]为什么使用数据索引能提高效率?(本文针对mysql进行概述)(更新)> 这次,主要侧重点讲下两种常用存储引擎. 我们一般从两个方面进行MySQ ...
- 【MySQL】花10分钟阅读下MySQL数据库优化总结
1.花10分钟阅读下MySQL数据库优化总结http://www.kuqin.com2.扩展阅读:数据库三范式http://www.cnblogs.com3.my.ini--->C:\Progr ...
- 30多条mysql数据库优化方法,千万级数据库记录查询轻松解决(转载)
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引. 2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索 ...
- 50多条mysql数据库优化建议
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引. 缺省情况下建立的索引是非群集索引,但有时它并不是最佳的.在非群集索引下,数据在物理上随机存 ...
- 解开发者之痛:中国移动MySQL数据库优化最佳实践(转)
开源数据库MySQL比较容易碰到性能瓶颈,为此经常需要对MySQL数据库进行优化,而MySQL数据库优化需要运维DBA与相关开发共同参与,其中MySQL参数及服务器配置优化主要由运维DBA完成,开发则 ...
- 30多条mysql数据库优化方法【转】
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引. 2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索 ...
- 百万行mysql数据库优化和10G大文件上传方案
百万行mysql数据库优化和10G大文件上传方案 最近这几天正在忙这个优化的方案,一直没时间耍,忙碌了一段时间终于还是拿下了这个项目?项目中不要每次都把程序上的问题,让mysql数据库来承担,它只是个 ...
- 从运维角度来分析mysql数据库优化的一些关键点【转】
概述 一个成熟的数据库架构并不是一开始设计就具备高可用.高伸缩等特性的,它是随着用户量的增加,基础架构才逐渐完善. 1.数据库表设计 项目立项后,开发部根据产品部需求开发项目,开发工程师工作其中一部分 ...
- 关于mysql数据库优化
关于mysql数据库优化 以我之愚见,数据库的优化在于优化存储和查询速度 目前主要的优化我认为是优化查询速度,查询速度快了,提高了用户的体验 我认为优化主要从两方面进行考虑, 优化数据库对象, 优化s ...
- mysql数据库优化 pt-query-digest使用
mysql数据库优化 pt-query-digest使用 一.pt-query-digest工具简介 pt-query-digest是用于分析 mysql慢查询的一个工具,它可以分析binlog.Ge ...
随机推荐
- DrawerLayout带有侧滑功能的布局类(2)
ActionBarDrawerToggle: 在前一张中我们并没有使用drawLayout.setDrawerListener(); 对应的参数对象就是DrawerLayout.DrawerListe ...
- Intent Android 详解
Intents and Intent Filters 三种应用程序基本组件 activity, service和broadcast receiver——是使用称为intent的消息来激活的. Inte ...
- vhdl基础---分频
偶数分频 ibrary IEEE; use IEEE.STD_LOGIC_1164.ALL; use ieee.std_logic_arith; use ieee.std_logic_unsigned ...
- 阅读verilog程序总结
1.写程序先直接写出时钟信号 //-----------------产生串行时钟scl,为输入时钟的二分频--------- always@(negedge clk)//二分频表示频率小了,周期大了 ...
- < java.util >-- List接口
List本身是Collection接口的子接口,具备了Collection的所有方法.现在学习List体系特有的共性方法,查阅方法发现List的特有方法都有索引,这是该集合最大的特点. List:有序 ...
- P3384: [Usaco2004 Nov]Apple Catching 接苹果
一道DP题, f[i,j,k] 表示 第 k 时刻 由 1 位置 变换 j 次 到达 当前 i 棵树 注意也要维护 变换 0 次的情况. var i,j,k,t,w,now:longint; tree ...
- 【桌面程序搞界面再也不怕了】:迅雷BOLT入门(一)开篇 附程序和源码
本来想多蛤一下前因后果,突然意兴阑珊不想多说啦,直接帖效果吧. 这个是用迅雷BOLT把原来写的一个IE拦截器的界面重写了一下.界面效果是直接从单位的大屏系统改过来的,其中文本框部分,还请设计大屏的小姑 ...
- Netsharp快速入门(之6) 基础档案(创建导航菜单)
作者:秋时 杨昶 时间:2014-02-15 转载须说明出处 1.1 创建导航菜单 1.在Demo节点下,录入路径名称,并在下方录入两个导航页签名 2.建立分类,只要填路径名 3.双击基 ...
- HTML5 编码规范
在编写HTML时,可能有一些方面不够规范,在通过对<HTML5编码规范>的学习后,采用代码注解的方式,做相关的整理,方便今后回顾. <!DOCTYPE html> <!- ...
- Invalid object name ‘sys.configurations’. (Microsoft SQL Server, Error: 208)
http://blogs.msdn.com/b/ramaprasanna/archive/2009/09/16/invalid-object-name-sys-configurations-micro ...