Mahout之深入navie Bayesian classifier理论
转自:http://www.cnblogs.com/leoo2sk/archive/2010/09/17/naive-bayesian-classifier.html
1.1、摘要
贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。本文作为分类算法的第一篇,将首先介绍分类问题,对分类问题进行一个正式的定义。然后,介绍贝叶斯分类算法的基础——贝叶斯定理。最后,通过实例讨论贝叶斯分类中最简单的一种:朴素贝叶斯分类。
1.2、分类问题综述
对于分类问题,其实谁都不会陌生,说我们每个人每天都在执行分类操作一点都不夸张,只是我们没有意识到罢了。例如,当你看到一个陌生人,你的脑子下意识判断TA是男是女;你可能经常会走在路上对身旁的朋友说“这个人一看就很有钱、那边有个非主流”之类的话,其实这就是一种分类操作。
从数学角度来说,分类问题可做如下定义:
已知集合:和
,确定映射规则
,使得任意
有且仅有一个
使得
成立。(不考虑模糊数学里的模糊集情况)
其中C叫做类别集合,其中每一个元素是一个类别,而I叫做项集合,其中每一个元素是一个待分类项,f叫做分类器。分类算法的任务就是构造分类器f。
这里要着重强调,分类问题往往采用经验性方法构造映射规则,即一般情况下的分类问题缺少足够的信息来构造100%正确的映射规则,而是通过对经验数据的学习从而实现一定概率意义上正确的分类,因此所训练出的分类器并不是一定能将每个待分类项准确映射到其分类,分类器的质量与分类器构造方法、待分类数据的特性以及训练样本数量等诸多因素有关。
例如,医生对病人进行诊断就是一个典型的分类过程,任何一个医生都无法直接看到病人的病情,只能观察病人表现出的症状和各种化验检测数据来推断病情,这时医生就好比一个分类器,而这个医生诊断的准确率,与他当初受到的教育方式(构造方法)、病人的症状是否突出(待分类数据的特性)以及医生的经验多少(训练样本数量)都有密切关系。
1.3、贝叶斯分类的基础——贝叶斯定理
每次提到贝叶斯定理,我心中的崇敬之情都油然而生,倒不是因为这个定理多高深,而是因为它特别有用。这个定理解决了现实生活里经常遇到的问题:已知某条件概率,如何得到两个事件交换后的概率,也就是在已知P(A|B)的情况下如何求得P(B|A)。这里先解释什么是条件概率:
表示事件B已经发生的前提下,事件A发生的概率,叫做事件B发生下事件A的条件概率。其基本求解公式为:
。
贝叶斯定理之所以有用,是因为我们在生活中经常遇到这种情况:我们可以很容易直接得出P(A|B),P(B|A)则很难直接得出,但我们更关心P(B|A),贝叶斯定理就为我们打通从P(A|B)获得P(B|A)的道路。
下面不加证明地直接给出贝叶斯定理:
1.4、朴素贝叶斯分类
1.4.1、朴素贝叶斯分类的原理与流程
朴素贝叶斯分类是一种十分简单的分类算法,叫它朴素贝叶斯分类是因为这种方法的思想真的很朴素,朴素贝叶斯的思想基础是这样的:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。通俗来说,就好比这么个道理,你在街上看到一个黑人,我问你你猜这哥们哪里来的,你十有八九猜非洲。为什么呢?因为黑人中非洲人的比率最高,当然人家也可能是美洲人或亚洲人,但在没有其它可用信息下,我们会选择条件概率最大的类别,这就是朴素贝叶斯的思想基础。
朴素贝叶斯分类的正式定义如下:
1、设为一个待分类项,而每个a为x的一个特征属性。
2、有类别集合。
3、计算。
4、如果,则
。
那么现在的关键就是如何计算第3步中的各个条件概率。我们可以这么做:
1、找到一个已知分类的待分类项集合,这个集合叫做训练样本集。
2、统计得到在各类别下各个特征属性的条件概率估计。即。
3、如果各个特征属性是条件独立的,则根据贝叶斯定理有如下推导:
因为分母对于所有类别为常数,因为我们只要将分子最大化皆可。又因为各特征属性是条件独立的,所以有:
根据上述分析,朴素贝叶斯分类的流程可以由下图表示(暂时不考虑验证):
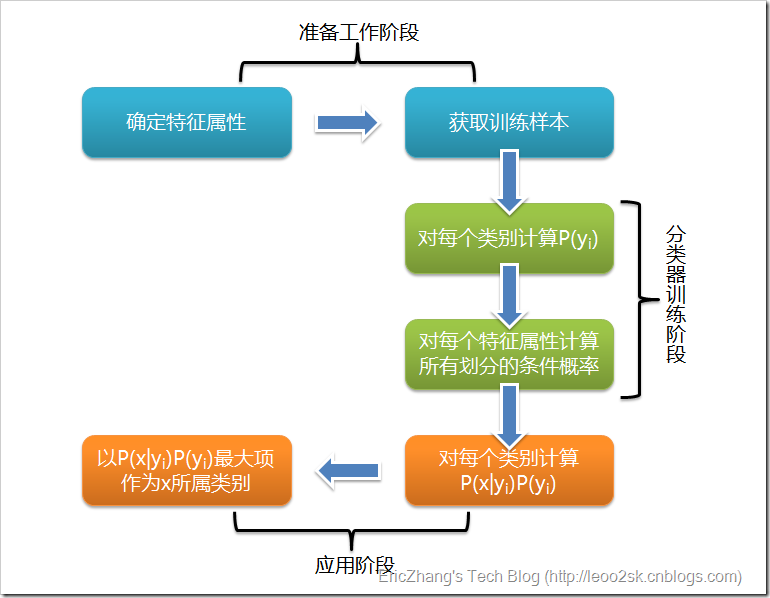
可以看到,整个朴素贝叶斯分类分为三个阶段:
第一阶段——准备工作阶段,这个阶段的任务是为朴素贝叶斯分类做必要的准备,主要工作是根据具体情况确定特征属性,并对每个特征属性进行适当划分,然后由人工对一部分待分类项进行分类,形成训练样本集合。这一阶段的输入是所有待分类数据,输出是特征属性和训练样本。这一阶段是整个朴素贝叶斯分类中唯一需要人工完成的阶段,其质量对整个过程将有重要影响,分类器的质量很大程度上由特征属性、特征属性划分及训练样本质量决定。
第二阶段——分类器训练阶段,这个阶段的任务就是生成分类器,主要工作是计算每个类别在训练样本中的出现频率及每个特征属性划分对每个类别的条件概率估计,并将结果记录。其输入是特征属性和训练样本,输出是分类器。这一阶段是机械性阶段,根据前面讨论的公式可以由程序自动计算完成。
第三阶段——应用阶段。这个阶段的任务是使用分类器对待分类项进行分类,其输入是分类器和待分类项,输出是待分类项与类别的映射关系。这一阶段也是机械性阶段,由程序完成。
1.4.2、估计类别下特征属性划分的条件概率及Laplace校准
这一节讨论P(a|y)的估计。
由上文看出,计算各个划分的条件概率P(a|y)是朴素贝叶斯分类的关键性步骤,当特征属性为离散值时,只要很方便的统计训练样本中各个划分在每个类别中出现的频率即可用来估计P(a|y),下面重点讨论特征属性是连续值的情况。
当特征属性为连续值时,通常假定其值服从高斯分布(也称正态分布)。即:
而
因此只要计算出训练样本中各个类别中此特征项划分的各均值和标准差,代入上述公式即可得到需要的估计值。均值与标准差的计算在此不再赘述。
另一个需要讨论的问题就是当P(a|y)=0怎么办,当某个类别下某个特征项划分没有出现时,就是产生这种现象,这会令分类器质量大大降低。为了解决这个问题,我们引入Laplace校准,它的思想非常简单,就是对没类别下所有划分的计数加1,这样如果训练样本集数量充分大时,并不会对结果产生影响,并且解决了上述频率为0的尴尬局面。
1.4.3、朴素贝叶斯分类实例:检测SNS社区中不真实账号
下面讨论一个使用朴素贝叶斯分类解决实际问题的例子,为了简单起见,对例子中的数据做了适当的简化。
这个问题是这样的,对于SNS社区来说,不真实账号(使用虚假身份或用户的小号)是一个普遍存在的问题,作为SNS社区的运营商,希望可以检测出这些不真实账号,从而在一些运营分析报告中避免这些账号的干扰,亦可以加强对SNS社区的了解与监管。
如果通过纯人工检测,需要耗费大量的人力,效率也十分低下,如能引入自动检测机制,必将大大提升工作效率。这个问题说白了,就是要将社区中所有账号在真实账号和不真实账号两个类别上进行分类,下面我们一步一步实现这个过程。
首先设C=0表示真实账号,C=1表示不真实账号。
1、确定特征属性及划分
这一步要找出可以帮助我们区分真实账号与不真实账号的特征属性,在实际应用中,特征属性的数量是很多的,划分也会比较细致,但这里为了简单起见,我们用少量的特征属性以及较粗的划分,并对数据做了修改。
我们选择三个特征属性:a1:日志数量/注册天数,a2:好友数量/注册天数,a3:是否使用真实头像。在SNS社区中这三项都是可以直接从数据库里得到或计算出来的。
下面给出划分:a1:{a<=0.05, 0.05<a<0.2, a>=0.2},a1:{a<=0.1, 0.1<a<0.8, a>=0.8},a3:{a=0(不是),a=1(是)}。
2、获取训练样本
这里使用运维人员曾经人工检测过的1万个账号作为训练样本。
3、计算训练样本中每个类别的频率
用训练样本中真实账号和不真实账号数量分别除以一万,得到:
4、计算每个类别条件下各个特征属性划分的频率
5、使用分类器进行鉴别
下面我们使用上面训练得到的分类器鉴别一个账号,这个账号使用非真实头像,日志数量与注册天数的比率为0.1,好友数与注册天数的比率为0.2。
可以看到,虽然这个用户没有使用真实头像,但是通过分类器的鉴别,更倾向于将此账号归入真实账号类别。这个例子也展示了当特征属性充分多时,朴素贝叶斯分类对个别属性的抗干扰性。
1.5、分类器的评价
虽然后续还会提到其它分类算法,不过这里我想先提一下如何评价分类器的质量。
首先要定义,分类器的正确率指分类器正确分类的项目占所有被分类项目的比率。
通常使用回归测试来评估分类器的准确率,最简单的方法是用构造完成的分类器对训练数据进行分类,然后根据结果给出正确率评估。但这不是一个好方法,因为使用训练数据作为检测数据有可能因为过分拟合而导致结果过于乐观,所以一种更好的方法是在构造初期将训练数据一分为二,用一部分构造分类器,然后用另一部分检测分类器的准确率。
Mahout之深入navie Bayesian classifier理论的更多相关文章
- Mahout之Navie Bayesian命令端运行
landen@landen-Lenovo:~/文档/20news$ mahout trainclassifier --helpMAHOUT_LOCAL is not set; adding HADOO ...
- [Bayes] *Bayesian Classifier for Face Recognition
Bayesian在识别领域的贡献,着实吸引人 阅读笔记 Gabor特征 (简介,另单独详述) 通过上面的分析,我们知道了,一个Gabor核能获取到图像某个频率邻域的响应情况,这个响应结果可以看做是图像 ...
- 朴素贝叶斯分类器(Naive Bayesian Classifier)
本博客是基于对周志华教授所著的<机器学习>的"第7章 贝叶斯分类器"部分内容的学习笔记. 朴素贝叶斯分类器,顾名思义,是一种分类算法,且借助了贝叶斯定理.另外,它是一种 ...
- [数据挖掘课程笔记]Naïve Bayesian Classifier
朴素贝叶斯模型 1) X:一条未被标记的数据 2) H:一个假设,如H=X属于Ci类 根据贝叶斯公式 把X表示为(x1,x2,....xn) x1,x2,....xn表示X在各个特征上的值. 假设有c ...
- 听同事讲 Bayesian statistics: Part 1 - Bayesian vs. Frequentist
听同事讲 Bayesian statistics: Part 1 - Bayesian vs. Frequentist 摘要:某一天与同事下班一同做地铁,刚到地铁站,同事遇到一熟人正从地铁站出来. ...
- Naive Bayesian文本分类器
贝叶斯学习方法中有用性非常高的一种为朴素贝叶斯学习期,常被称为朴素贝叶斯分类器. 在某些领域中与神经网络和决策树学习相当.尽管朴素贝叶斯分类器忽略单词间的依赖关系.即如果全部单词是条件独立的,但朴素贝 ...
- 从决策树学习谈到贝叶斯分类算法、EM、HMM --别人的,拷来看看
从决策树学习谈到贝叶斯分类算法.EM.HMM 引言 最近在面试中,除了基础 & 算法 & 项目之外,经常被问到或被要求介绍和描述下自己所知道的几种分类或聚类算法(当然,这完全 ...
- 从决策树学习谈到贝叶斯分类算法、EM、HMM
从决策树学习谈到贝叶斯分类算法.EM.HMM (Machine Learning & Recommend Search交流新群:172114338) 引言 log ...
- day39机器学习
2 Numpy快速上手 2.1. 什么是Numpy Numpy是Python的一个科学计算的库 主要提供矩阵运算的功能,而矩阵运算在机器学习领域应用非常广泛 Numpy一般与Scipy.matplot ...
随机推荐
- (六)6.16 Neurons Networks linear decoders and its implements
Sparse AutoEncoder是一个三层结构的网络,分别为输入输出与隐层,前边自编码器的描述可知,神经网络中的神经元都采用相同的激励函数,Linear Decoders 修改了自编码器的定义,对 ...
- 【英语】Bingo口语笔记(60) - 口语中的浊化发音
- SpringMVC注解@initbinder解决类型转换问题
在使用SpringMVC的时候,经常会遇到表单中的日期字符串和JavaBean的Date类型的转换,而SpringMVC默认不支持这个格式的转换,所以需要手动配置,自定义数据的绑定才能解决这个问题.在 ...
- MySQL基础之第18章 性能优化
18.1.优化简介 SHOW STATUS LIKE ‘value’;connections 连接数uptime 启动 ...
- CAT XQX ---- 增删改查架构说明 1
View 层 -- 以国家为例 1. 显示 数据库的 table 页面效果 对应代码: <table id="dg" title="国家信息" cla ...
- 网络编程 --- URLConnection --- 读取服务器的数据 --- java
使用URLConnection类获取服务器的数据 抽象类URLConnection表示一个指向指定URL资源的活动连接,它是java协议处理器机制的一部分. URL对象的openConnection( ...
- Chapter12:动态内存
智能指针——shared_ptr 为了更容易地使用动态内存,新的标准提供了智能指针来管理动态对象.智能指针的行为类似常规指针,重要的区别是它负责自动释放指向的对象. 智能指针的使用方式与普通指针类似. ...
- spring依赖注入方法
依赖注入就是在程序运行时期,由外部容器动态的将依赖对象注入到组件中,通俗的理解是:平常我们new一个实例,这个实例的控制权是我们程序员,而控制反转是指new实例工作不由我们程序员来做而是交给sprin ...
- 记一个社交APP的开发过程——基础架构选型(转自一位大哥)
记一个社交APP的开发过程——基础架构选型 目录[-] 基本产品形态 技术选型 最近两周在忙于开发一个社交App,因为之前做过一点儿社交方面的东西,就被拉去做API后端了,一个人头一次完整的去搭这么一 ...
- Using NuGet without committing packages to source control(在没有把包包提交到代码管理器的情况下使用NuGet进行还原 )
外国老用的语言就是谨慎,连场景都限定好了,其实我们经常下载到有用NuGet引用包包然而却没法编译的情况,上谷歌百度搜又没法使用准确的关键字,最多能用到的就是nuget跟packages.config, ...