eclipse运行WordCount
1)
可以完全参考http://www.cnblogs.com/archimedes/p/4539751.html在eclipse下创建MapReduce工程,创建了MR工程,并完成WordCount.java的编写之后,运行WordCount.java,结果可能如图所示 ,原因是未设置MR读取文件的路径以及输出结果的路径,修改方法如下图所示
,原因是未设置MR读取文件的路径以及输出结果的路径,修改方法如下图所示
需要注意的就是,这里的in和out就是hdfs中的路径,in就是输入数据所在的路径,ou就是最后结果的输出路径。使用完全分布式运行MR程序,设置如下:
 ,其实Master:9000/user/input中只是存储了数据集的元数据(9000是hdfs-site.xml中配置的),并没有存储真正的数据集。另外,第二次运行WordCounts时会提示output文件已存在,需要删除output才能正常运行。
,其实Master:9000/user/input中只是存储了数据集的元数据(9000是hdfs-site.xml中配置的),并没有存储真正的数据集。另外,第二次运行WordCounts时会提示output文件已存在,需要删除output才能正常运行。
以上在eclipse中点击run直接运行的方式只是在本地机器上运行mapreduce(单机模式),可以在http://master:50030/jobtracker.jsp中看到Running Jobs是none,在Eclipse的控制台就是这种形式:
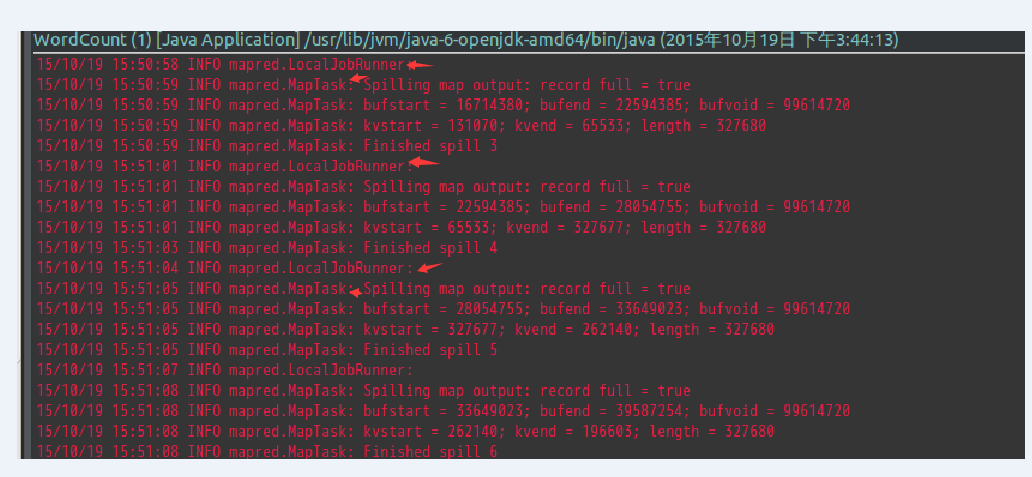
可以看到LocalJobRunner,就是使用本地主机运行MR,一直都是mapred.MapTask,即一直进行map操作,这就是因为没有把MR程序部署到集群上去。程序运行时间是54分钟。
2)
下图就是将MR部署到集群上之后,运行MR时候的情况:
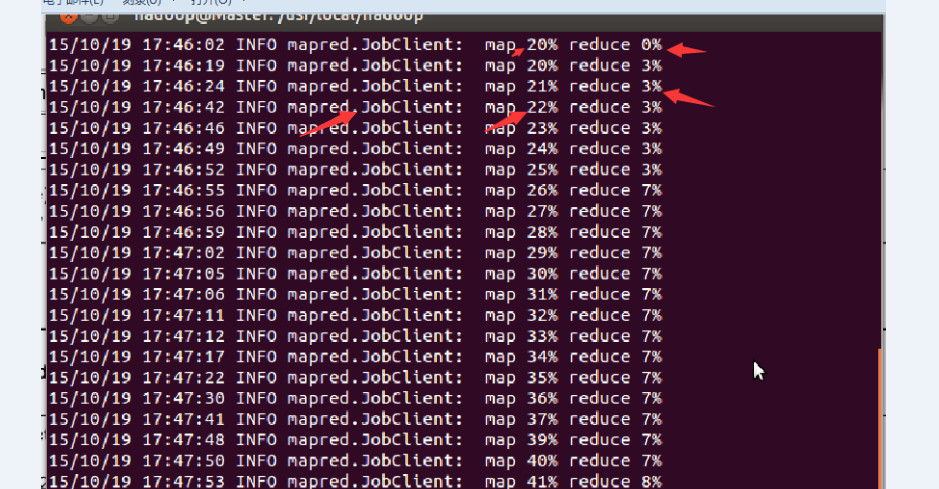
可以看到,当map达到一定的比例时,map和reduce操作是并行运行的。

map运行完毕,reduce继续运行。

在http://master:50030/jobtracker.jsp中看到Running Jobs。
程序运行时间是17分9秒。集群中1个master,3个slave。
3)
如何是MR程序在集群上运行呢?
需要将eclipse中的MR程序打包,利用eclipse打包过程如下:
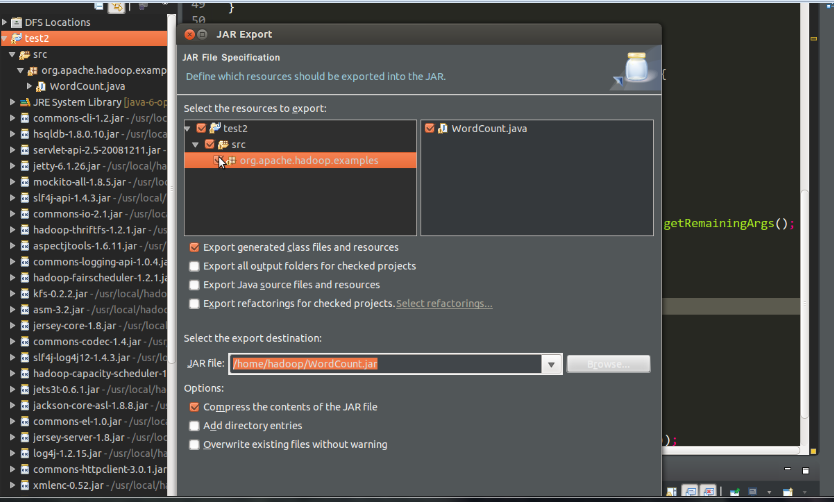
生成jar包之后,使用
bin/hadoop jar /home/hadoop/WordCount.jar org.apache.hadoop.examples.WordCount /user/input /user/output
其中: 1)/home/hadoop/WordCount.jar 指示jar包的位置
2)org.apache.hadoop.examples.WordCount表示package org.apache.hadoop.examples(源程序中第一行生命了包)中的主类WordCount。

3)/user/input /user/output分别是hdfs中数据集的输入目录和运算结果的输出目录。
4)WordCount原码如下:
/**
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/ package org.apache.hadoop.examples; import java.io.IOException;
import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser; public class WordCount { public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{ private final static IntWritable one = new IntWritable(1);
private Text word = new Text(); public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
} public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
} public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
//JobConf conf=new JobConf();
//
//conf.setJar("org.apache.hadoop.examples.WordCount.jar");
// conf.set("fs.default.name", "hdfs://Master:9000/");
//conf.set("hadoop.job.user","hadoop");
//指定jobtracker的ip和端口号,master在/etc/hosts中可以配置
// conf.set("mapred.job.tracker","Master:9001");
/*
FileSystem hdfs =FileSystem.get(conf);
Path findf=new Path("/user/output");
boolean isExists=hdfs.exists(findf);
System.out.println("/user/output exit?"+isExists);
if(isExists)
{
hdfs.delete(findf, true);
System.out.println("delete /user/output"); }
*/
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "word count"); job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
这种代码可以直接在elipse中以单机模式运行,但是再次运行之前需要手动删除output目录,所以就想在程序中加入代码,检测output是否已经存在,是的话就删除,代码如下:
/**
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/ package org.apache.hadoop.examples; import java.io.IOException;
import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser; public class WordCount { public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{ private final static IntWritable one = new IntWritable(1);
private Text word = new Text(); public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
} public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
} public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
//JobConf conf=new JobConf();
//
//conf.setJar("org.apache.hadoop.examples.WordCount.jar");
// conf.set("fs.default.name", "hdfs://Master:9000/");
//conf.set("hadoop.job.user","hadoop");
//指定jobtracker的ip和端口号,master在/etc/hosts中可以配置
// conf.set("mapred.job.tracker","Master:9001"); FileSystem hdfs =FileSystem.get(conf);
Path findf=new Path("/eclipse-test5/output");
boolean isExists=hdfs.exists(findf);
System.out.println("/eclipse-test5/output exit?"+isExists);
if(isExists)
{
hdfs.delete(findf, true);
System.out.println("delete /eclipse-test5/output"); } String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "word count"); job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
78-88行代码实现检测output目录是否存在,存在的话就删除的功能。但是78-88行使用的hdfs的API却检测到output不存在,但是运行程序的时候却提示output已经存在,如图所示:
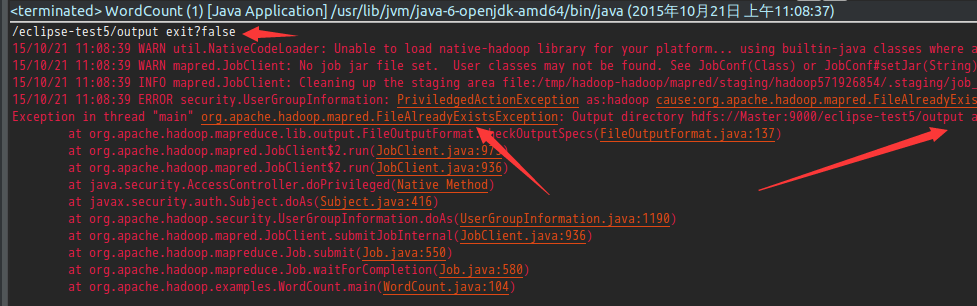
但是,如果将上述程序打成jar包再运行就不会出错。
5)
如果是单单使用HDFS提供的API对文件进行操作,又想直接在eclipse中直接运行,不想打jar包使用hadoop命令运行的话,可以在代码中加入以下三行代码:
conf.set("fs.default.name", "hdfs://Master:9000/");
conf.set("hadoop.job.user","hadoop");
//指定jobtracker的ip和端口号,master在/etc/hosts中可以配置
conf.set("mapred.job.tracker","Master:9001");
这样可以实现不打jar包直接对hdfs进行操作的目的。
但是,将这三行代码加入WordCount中的话却会报错。
6)最后,需要搞清楚这三行代码到底做了什么?
conf.set("fs.default.name", "hdfs://Master:9000/");
conf.set("hadoop.job.user","hadoop");
//指定jobtracker的ip和端口号,master在/etc/hosts中可以配置
conf.set("mapred.job.tracker","Master:9001");
eclipse运行WordCount的更多相关文章
- Eclipse运行wordcount步骤
Eclipse运行wordcount步骤 第一步:建立工程,导入代码. 第二步:建立文件写入数据(以空格分开),并上传到hdfs上. 1.创建文件并写入数据: 2.上传hdfs 在hadoop权限下就 ...
- Hadoop3 在eclipse中访问hadoop并运行WordCount实例
前言: 毕业两年了,之前的工作一直没有接触过大数据的东西,对hadoop等比较陌生,所以最近开始学习了.对于我这样第一次学的人,过程还是充满了很多疑惑和不解的,不过我采取的策略是还是先让环 ...
- eclipse连hadoop2.x运行wordcount 转载
转载地址:http://my.oschina.net/cjun/blog/475576 一.新建java工程,并且导入hadoop相关jar包 此处可以直接创建mapreduce项目就可以,不用下面折 ...
- 解决在windows的eclipse上面运行WordCount程序出现的一系列问题详解
一.简介 要在Windows下的 Eclipse上调试Hadoop2代码,所以我们在windows下的Eclipse配置hadoop-eclipse-plugin- 2.6.0.jar插件,并在运行H ...
- (三)配置Hadoop1.2.1+eclipse(Juno版)开发环境,并运行WordCount程序
配置Hadoop1.2.1+eclipse(Juno版)开发环境,并运行WordCount程序 一. 需求部分 在ubuntu上用Eclipse IDE进行hadoop相关的开发,需要在Eclip ...
- win10+eclipse+hadoop2.7.2+maven+local模式直接通过Run as Java Application运行wordcount
一.准备工作 (1)Hadoop2.7.2 在linux部署完毕,成功启动dfs和yarn,通过jps查看,进程都存在 (2)安装maven 二.最终效果 在windows系统中,直接通过Run as ...
- 021_在Eclipse Indigo中安装插件hadoop-eclipse-plugin-1.2.1.jar,直接运行wordcount程序
1.工具介绍 Eclipse Idigo.JDK1.7-32bit.hadoop1.2.1.hadoop-eclipse-plugin-1.2.1.jar(自己网上下载) 2.插件安装步骤 1)将ha ...
- Window7中Eclipse运行MapReduce程序报错的问题
按照文档:http://www.micmiu.com/bigdata/hadoop/hadoop2x-eclipse-mapreduce-demo/安装配置好Eclipse后,运行WordCount程 ...
- eclipse运行没问题,tomcat以脚本启动后插入数据库的中文会乱码
记一次部署工程的时候遇到的问题 部署war包到win7的时候发现,布上去后插入数据库的中文会乱码,然后发现用eclipse运行源码没问题,一开始以为是war打出来的时候编码错误,然后将eclipse的 ...
随机推荐
- 配置《算法 第四版》的Eclipse开发环境
1. 安装JAVA JAVA网址:http://www.oracle.com/technetwork/java/javase/downloads/index.html 配置环境变量(我把JAVA安装在 ...
- 第六章 类型(class)和成员基础
1. 概述 本章讲述如何在一个类型中定义不同种类的成员. 2. 名词解释 3. 主要内容 3.1 类型的各种成员 在一个类型中,可以定义0个或多个以下种类的成员: ① 常量:常量就是指出数据值恒定不变 ...
- .NET开源工作流RoadFlow-系统布署中常见错误及处理方法
1.未开启asp.net状态服务时会出现以下错误: 解决办法:开启ASP.NET STATE SERVICE服务 2.未开启应用程序池32位: 解决办法:启用32位
- AsyncTask和Handler两种异步方式的实现和区别比较
1 AsyncTask实现的原理,和适用的优缺点 AsyncTask,是android提供的轻量级的异步类,可以直接继承AsyncTask,在类中实现异步操作,并提供接口反馈当前异步执行的程度(可以 ...
- hdu 5199 Gunner
原题链接:http://acm.hdu.edu.cn/showproblem.php?pid=5199 简单题,stl水之... #include<algorithm> #include& ...
- golang反射初试
golang反射来自Go AST(Abstract Syntax Tree). reflect操作更多像traverse AST. t := reflect.TypeOf(obj) 使用TypeOf( ...
- golang的哪些坑爷事: package实践
在golang中package是个困惑的概念, 特别是package还可以与folder不同名, 委实让我恶心了一把. 关于golang的package的最佳实践: package is folder ...
- 初始twisted(一)
1.与同步模型的优势: 1.有大量的任务,一个时刻内至少有一个任务要运行 2.任务执行大量的I/O,同步模型会因为任务阻塞而浪费大量时间 3.任务之间相互独立,任务内部交互少. 2.与同步模式客户端的 ...
- [转]ubuntu server上网配置
[转]ubuntu server上网配置 http://blog.sina.com.cn/s/blog_6c9d65a101011pyt.html 今天我的ubuntu server上不去网了,所以重 ...
- Entity Framework 学习第一天
文章是作为初学者记录之用,没有学习过的同学可以借鉴一下,至于用过和高手嘛,就算了吧.仅是入门.废话不多说了,马上新建个项目,添加Entity Framework,这个词以下将用EF代替. 本文使用的I ...