Sklearn环境搭建与常用包
开发环境搭建
直接安装Anaconda
IPython
IPython是公认的现代科学计算中最重要的Python工具之一。它是一个加强版的Python交互命令行工具,有以下几个明显的特点:
1. 可以在IPython环境下直接执行Shell指令
2. 可以直接绘图操作的Web GUI环境
3. 更强大的交互功能,包括内省、Tab键自动完成、魔术命令
基础
命令行输入ipython,即可启动交互环境
按Tab键,会自动显示命名空间下的所有开头函数,自动完成
Ctrl + A:移动光标到开头
Ctrl + E:移动光标到结尾
Ctrl + U:删除光标之前的所有字符
Ctrl + K:删除光标之后的所有字符,包含当前字符
Ctrl + L:清屏
Ctrl + P:向后搜索匹配的指令
Ctrl + N:向前搜索匹配的指令
Ctrl + C:终端当前脚本的执行
可以直接在函数或变量后面加上问号?来查询文档
在类或变量、函数后面添加两个问号??,可以查看源码,结合星号 * 和问号 ?,还可以查询命名空间里的所有函数和对象。
魔术命令
%run hello.py 可以直接运行hello.py文件。
%timeit np.dot(a,a) 可以快速评估代码执行效率。
%who 或 %whos命令查看当前环境下的变量列表
%quickref 显示IPython的快速参考文档
%magic 显示所有的魔术命令及其详细文档
%reset 删除当前环境下的所有变量和导入的模块
%logstart 开始记录IPython里的所有输入的命令,默认保存在当前工作目录的ipython_log.py中
%logstop 停止记录,并关闭log文件
需要说明的是,魔术命令后面加上问号 ? 可以直接显示魔术命令的文档。来查看%reset魔术命令的文档
IPython与shell交互的能力,可以让我们不离开IPython环境即可完成很多与操作系统相关的功能。最简单的方法就是在命令前加上叹号!既可以直接运行shell命令。
例如:!ifconfig | grep "inet "
当使用 %automagic on 启用自动魔术命令功能后,可以省略百分号%的输入即可直接运行魔术命令
IPython图形界面
除了控制台环境外,IPython另外一个强大的功能就是图形环境。与控制台环境相比,它有两个显著的特点:
1. 方便编写多行代码
2. 可以直接把数据可视化,显示在当前页面下
安装Jupyter
pip install jupyter
jupyter notebook
安装完Jupyter后,直接在命令行输入ipython notebook,启动网页版的图形编程界面。会在命令行启动一个轻量级的Web服务器,同时用默认浏览器打开当前目录所在的页面,在这个页面下可以直接打开某个notebook或者创建一个新的notebook。一个notebook是以.ipynb作为后缀名的、基于json格式的文本文件。
我们可以创建一个notebook,并且画一个正弦曲线 jupyter notebook inline.ipynb
- # 设置 inline 方式,直接把图片画在页面上
- %matplotlib inline
- # 导入必要的库
- import numpy as np
- import matplotlib.pyplot as plt
- # 在[0,2*PI] 之间取100个点
- x = np.linspace(0,2*np.pi,num=100)
- # 计算这100个点的正弦值,并保存到变量y中
- y = np.sin(x)
- plt.plot(x,y)
几乎所有的IPython控制台的技巧都可以在IPython notebook里使用。一个比较大的区别是,IPython notebook使用cell作为一个代码单元。控制台里,写完代码直接按Enter键即可运行,而在IPython notebook里需要单击“运行”按钮或用快捷键Ctrl+ Enter才能运行。
notebook有两种模式,一个是编辑模式,可以修改代码。一个是命令模式,输入的按键作为命令。使用Ctrl + M快捷键在模式之间切换。
Numpy简介
Numpy是Python科学计算的基础库,主要提供了高性能的N维数组实现及计算能力,还提供了和其他语言如C/C++集成的能力,此外还实现了一些基础的数学算法,如线性代数相关、傅里叶变换及随机数生成等。
API:https://docs.scipy.org/doc/numpy/genindex.html
参考:https://docs.scipy.org/doc/numpy/reference/index.html
指南:https://docs.scipy.org/doc/numpy/user/index.html
Numpy数组
可以直接用Python列表来创建数组
Numpy核心是ndarry对象,封装了数据类型的操作。所以使用np.array创建的数组可以直接相乘。
- import numpy as np
- a = np.array([1, 2, 3, 4])
- print(a) # [1 2 3 4]
- b = np.array([[1, 2], [3, 4], [5, 6]])
- print(b) # [[1 2] [3 4]]
- print(b.ndim) # 查看维度:2
- print(b.shape) # 查看行、列 (3,2)
- print(b.dtype) # 查看类型 int32
- c = np.arange(10) # 创建连续数组
- print(c) # [0 1 2 3 4 5 6 7 8 9]
- d = np.linspace(0, 2, 11) # 将[0,2]切分成11等分之后的数组
- print(d) # [0. 0.2 0.4 0.6 0.8 1. 1.2 1.4 1.6 1.8 2. ]
- print(np.ones((3, 3))) # 创建3行3列的1数组
- np.zeros((3, 6)) # 创建3行3列的0数组
- np.eye(4) # 创建4行4列的对角线数组
- np.random.randn(6, 3) # 创建6行3列的随机数组
np.random.rand(10) # 创建一个给定维度的数组,并用统一分布的随机样本[0,1]填充它
np.random_integers(1,5,(6,3)) # 创建6行3列的随机整数数组
np.random.normal(0,1,100) # 从正态分布中抽取随机样本
- c[3] # 可以通过索引查找
- c[:3] # 切片也可以
- c[2:8:2] # 表示起始、结束、步长
- c[2:: 2] # 可以省略结束为止
- c[:: 3] # 开始结束都省略
- a = np.arange(0, 51, 10).reshape(6, 1) + np.arange(6) # 创建0-51且步长为10的连续数组,6行6列的二维数组
- a[0, 0] # 访问0行0列
- a[:3, 3:] # 访问前三行的后三列
- a[2, :] # 访问第2行
- a[:, 3] # 访问第三列向量
- a[:, ::2] # 访问所有行的步长为2的列
- a[::2, ::3] # 访问步长为2的行的步长为3的列
- a % 2 == 0 # 判断每一个数组与2取余是否等于0,返回True/False
- a[a % 2 == 0] # 每个数与2取余等于0,并输出
正态分布:也称常态分布、高斯分布。是一个非常重要的概率分布。观测数据非常大的时候,具有独立分布的独立随机变量的观测样本平均值是收敛于正态分布的。概率密度函数为
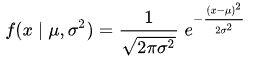
μ是分布的均值,或者叫期望值;σ是标准差。σ的平方是方差
Numpy总是试图自动把结果转换为行向量,
Numpy数组是共享内存的,如果需要独立保存,要显示备份。可以使用np.may_share_memory()函数来判断两个数组是否共享内存
如果需要显示备份:a[2:6].copy()
使用埃拉托斯特尼筛法来打印[0,100]之间的所有质数(除了1和它自身外,不能被其他自然数整除的数)。从第一个质数2开始,数据里所有能被2整除的数字都不是质数,即从2开始,以2为步长,每经过的数字能被2整除,标识为非质数。接着,从下一个质数3开始,重复上述过程
- import numpy as np
- a = np.arange(1, 101)
- n_max = int(np.sqrt(len(a))) # 返回平方根
- is_prime = np.ones(len(a), dtype=bool)
- is_prime[0] = False
- for i in range(2, n_max):
- if i in a[is_prime]:
- is_prime[(i * 2 - 1):: i] = False # 省略截止,步长为2
- print(a[is_prime])
Numpy运算
最简单的数值计算是数组和标量进行计算,计算过程是直接把数组里的元素和标量逐个进行计算
- a = np.arange(6)
print(a * 3)
使用Numpy的优点是运行速度会比较快。
另一种是数组和数组的运算,如果数组的维度相同,那么在组里对应位置进行逐个元素的数学运算
- a = np.random.random_integers(1, 5, (5, 4))
b = np.random.randn(5, 4)
print(a + b, a * b)
矩阵乘积应该使用np.dot()函数
- a = np.random.random_integers(1, 5, (5, 4))
b = np.random.randn(4, 1)
print(np.dot(a, b))
如果数组的维度不同,Numpy会视图使用广播机制来匹配,如果能匹配上,就进行运算。如果不满足广播条件,则报错
符合广播的条件是两个数组必须有一个维度可以扩展,然后在这个维度上进行复制,最终复制出两个相同维度的数组,再进行运算。
- import numpy as np
- a = np.random.random_integers(1, 9, (5, 4))
b = np.arange(4)
print(a + b) # 符合广播条件
# 会将b转换为5行4列的向量,其中每一行的内容一致,则相当于同维度相加
数组还可以直接比较,返回一个同维度的布尔数组。针对布尔数组,可以使用all()/any()函数来返回布尔数组的标量值
- a = np.array([1, 2, 3, 4])
b = np.array([4, 2, 3, 1])
print(a == b) # [False True True False]
print(a > b) # [False False False True]
print((a == b).all()) # False
print((a == b).any()) # True
Numpy还提供了一些数组运算的内置函数:
np.cos(a) 计算余弦
np.exp(a) 计算所有元素的指数
np.sqrt(a) 计算平方根
还提供了一些基本的统计功能
a.sum() 汇总
a.mean() 平均值
a.std() 标准偏差
a.min()
a.max()
a.argmin() 返回轴上最小值
a.argmax() 返回轴上最大值
针对二维数组或者更高维度的数组,可以根据行或列来计算
b.sum()
b.sum(axis=0)
b.sum(axis=1)
b.sum(axis=1).sum()
b.min(axis=1)
其中axis参数表示坐标轴,0表示按行计算,1表示按列计算。
注意:按列计算后,计算结果Numpy会默认转换为行向量。
随机漫步算法
两个人用一个均匀的硬币来赌博,硬币抛出正面和反面的概率各占一半。硬币抛出正面时甲方输给乙方一块钱,反面时乙方输给甲方一块钱。这种赌博规则下,随着抛硬币次数的增加,输赢的总金额呈现怎么样的分布。
首先让足够多的人两两组成一组参与这个游戏,然后抛出足够多的硬币,就可以统计算出输赢的平均金额。
当使用Numpy实现时,生成多个由-1和1构成的足够长的随机数组,用来代表每次硬币抛出正面和反面的事件。这个二维数组中,每行表示一组参与赌博的人抛出正面和反面的事件序列,然后按行计算这个数组的累加和就是这每组输赢的金额
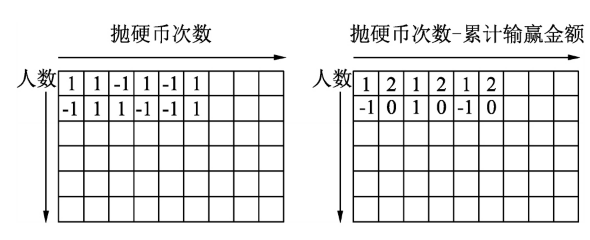
实际计算时,先求出每组输赢金额的平方,再求平均值。最后把平方根的值用绿色的点画在二维坐标上,同时画出 的红色曲线来对比两组曲线的重合情况
的红色曲线来对比两组曲线的重合情况
- %matplotlib inline
- import matplotlib.pyplot as plt
- import numpy as np
- n_person = 2000
- n_times = 500
- t = np.arange(n_times)
- steps = 2 * np.random.random_integers(0, 1, (n_person, n_times)) - 1
- amount = np.cumsum(steps, axis=1)
- sd_amount = amount ** 2
- mean_sd_amount = sd_amount.mean(axis=0)
- plt.figure(figsize=(20, 12), dpi=144)
- plt.xlabel(r"$t$", fontsize=24)
- plt.tick_params(labelsize=20)
- plt.ylabel(r"$\sqrt{\langle (\delta x)^2 \rangle}$", fontsize=24)
- plt.plot(t, np.sqrt(mean_sd_amount), 'g.', t, np.sqrt(t), 'r-');
使用np.reshape() 进行数组维度变换,而np.ravel() 则正好相反,会把多维数组变成一维向量
- a= np.arange(12)
- b = a.reshape(4,3)
- # [[ 0 1 2]
- # [ 3 4 5]
- # [ 6 7 8]
- # [ 9 10 11]]
- b.ravel()
添加维度使用np.newaxis
- a = np.arange(4)
- print(a.shape) # (4,)
- b = a[:, np.newaxis]
- print(b.shape) # (4, 1)
- c = a[np.newaxis, :]
- print(c.shape) # (1, 4)
np.sort(a,axis=1) 按行独立排序
a.sort(axis=0) 按列独立排序,并直接把结果给a
Numpy高级功能包括多项式求解以及多项式拟合的功能。np.polyfit() 函数可以用多项式对数据进行拟合。我们生成20个在平方根曲线周围引入随机噪声点,用3阶多项式来拟合这些点。
- import matplotlib.pyplot as plt
- import numpy as np
- n_dots = 20
- n_order = 3
- x = np.linspace(0, 1, n_dots) # [0,1]之间创建20个点
- y = np.sqrt(x) + 0.2 * np.random.rand(n_dots)
- p = np.poly1d(np.polyfit(x, y, n_order)) # 用3阶多项式拟合
- print(p.coeffs)
- # 画出拟合出来的多项式所表达的曲线以及原始的点
- t = np.linspace(0, 1, 200)
- plt.plot(x, y, 'ro', t, p(t), '-');
使用Numpy求圆周率π的值。使用的算法是蒙特卡罗方法(Monte Carlo method)其主要思想是,在一个正方形内,用正方形的边长画出一个1/4圆的扇形,假设圆的半径为r,则正方形的面积为r2,圆的面积为1/4π r2,它们的面积之比是π/4
我们在正方形内随机产生足够多的点,计算落在扇形区域内的点的个数与总的点个数的比值。当产生的随机点足够多时,这个比值和面积比值应该是一致的。这样就可以算出π的值。判断一个点是否落在扇形区域的方法是计算这个点到圆心的距离。当距离小于半径时,说明这个点落在扇形内。
- import numpy as np
- # 假设圆的半径为1,圆心在原点
- n_dots = 10000000
- x = np.random.random(n_dots)
- y = np.random.random(n_dots)
- # 随机产生一百万个点
- distance = np.sqrt(x ** 2 + y ** 2)
- # 计算每个点到圆心的距离
- in_circle = distance[distance < 1]
- # 所有落在扇形内的点
- pi = 4 * float(len(in_circle)) / n_dots
- # 计算出PI的值
- print(pi)
Numpy数组作为文本文件,可以直接保存到文件系统里,也可以从文件系统里读取出数据
- a = np.arange(15).reshape(3, 5)
np.savetxt('a.txt', a) # 序列化为文本
b = np.loadtxt('a.txt') # 文本反序列化
print(b)
也可以直接保存为Numpy特有的二进制格式
- np.save('a.npy', a) # 序列化为文本
b = np.load('a.npy') # 文本反序列化
Pandas简介
Pandas是一个强大的时间序列数据处理工具包,为了分析财经数据,现在已经广泛应用在Python数据分析领域中。
文档:http://pandas.pydata.org/pandas-docs/stable/
Pandas最基础的数据结构是Series,用它来表达一行数据,可以理解为一维的数组。比如创建一个包含6个数据的一维数组
- s = pd.Series([4, 2, 5])
# 0 4
# 1 2
# 2 5
# dtype: int64
另一个关键的数据结构为DataFrame,表示是二维数组。下面的代码创建一个DataFrame对象
- df = pd.DataFrame(np.random.rand(6, 4), columns=list('ABCD'))
# A B C D
# 0 0.584111 0.186057 0.204064 0.519430
# 1 0.645679 0.405943 0.032989 0.897339
# 2 0.898421 0.757804 0.948457 0.145658
# 3 0.502044 0.925613 0.599234 0.220672
# 4 0.432294 0.039789 0.577377 0.954598
# 5 0.274313 0.443114 0.416644 0.604243
DataFrame里的数据实际是Numpy的array对象来保存的,读者可以输入df.values来查看原始数据。DataFrame对象的每一行和列都是一个Series对象。可以使用行索引来访问一个行数,可以用列名称来索引一列数据
df.iloc[0] 行索引
df.A 列索引
df.shape 查看维度
df.head(3) 访问前三行
df.tail(3) 访问后三行
df.index 访问数据的行索引
df.columns 访问数据的列索引
df.describe() 计算简单的数据统计信息(可以计算出个数、平均值、标准差、最小值、最大值)
df.sort_index(axis=1,ascending=False) 可以进行列名称倒序
df.sort_values(by='B') 对B列数值进行排序
df[3:5] 索引范围访问
df[['A','B','C']] 选择3列数据
df.loc[3,'A'] 选择3行的A列
df.iloc[3,0] 通过数组索引来访问
df.iloc[2:5,0:2] 通过索引
df[df.c > 0] 插入布尔值
df["D"] = ["A","B"] 添加一列
df.groupby("D").sum() 分组
Pandas提供了时间序列处理能力,可以创建以时间序列为索引的数据集
- import numpy as np
- import pandas as pd
- n_items = 366
- ts = pd.Series(np.random.rand(n_items), index=pd.date_range('20000101', periods=n_items))
- print(ts.shape) # (366,)
- print(ts.head(5))
- # 2000-01-01 0.523365
- # 2000-01-02 0.127577
- # 2000-01-03 0.914436
- # 2000-01-04 0.474645
- # 2000-01-05 0.098926
- # Freq: D, dtype: float64
- # 按照月份聚合
- print(ts.resample("1m").sum())
- # 2000-01-31 14.488162
- # 2000-02-29 16.219371
- # 2000-03-31 14.601253
数据可视化
- % matplotlib inline
- # 导入必要的库
- import numpy as np
- import pandas as pd
- import matplotlib.pyplot as plt
- n_items = 366
- ts = pd.Series(np.random.rand(n_items), index=pd.date_range('20000101', periods=n_items))
- plt.figure(figsize=(10,6),dpi=144)
- cs = ts.cumsum()
- cs.plot()
文件读写
- import numpy as np
- import pandas as pd
- n_items = 366
- ts = pd.Series(np.random.rand(n_items), index=pd.date_range('20000101', periods=n_items))
- ts.to_csv('data.csv') # 写入
- df = pd.read_csv('data.csv', index_col=0) # 读取
- print(df.shape)
- print(df.head(5))
Matplotlib
Matplotlib是Python数据可视化工具包,
示例:https://matplotlib.org/tutorials/index.html
API:https://matplotlib.org/contents.html
如果要在IPython控制台使用,可以使用ipython--matplotlib来启动
如果要在IPython notebook使用,需要开始位置插入
- % matplotlib inline
并且进入包
from matplotlitb import pyplot as plt
在机器学习领域中,经常需要把数据可视化,以便观察数据的模式。对算法性能评估时,也需要把模型相关的数据可视化,才能观察出需要改进的地方。
图形样式
默认样式的坐标轴上画出正弦和余弦
- % matplotlib inline
- from matplotlib import pyplot as plt
- import numpy as np
- x = np.linspace(-np.pi, np.pi, 200)
- C, S = np.cos(x), np.sin(x)
- plt.plot(x, C) # 余弦
- plt.plot(x, S) # 正弦
- plt.show()
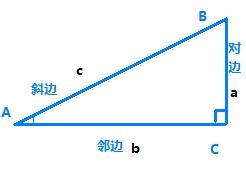
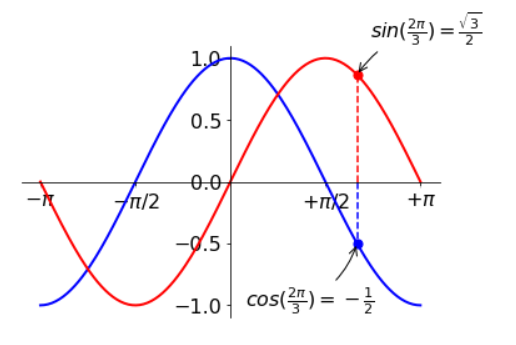
正弦值是在直角三角形中,对边的长比上斜边的长的值。sinA=∠A的对边/斜边=a/c
余弦值是在直角三角形中,邻边比三角形的斜边的值,cosA=b/c,也可写为cosa=AC/AB
画出来的图形如下

接着可以通过修改默认样式,来变成右边的正余弦曲线
- % matplotlib inline
- from matplotlib import pyplot as plt
- import numpy as np
- X = np.linspace(-np.pi, np.pi, 200, endpoint=True)
- C, S = np.cos(X), np.sin(X)
- # 画出余弦/正弦
- plt.plot(X, C, color="blue", linewidth=2.0, linestyle="-")
- plt.plot(X, S, color="red", linewidth=2.0, linestyle="-")
- # 设置坐标轴的长度
- plt.xlim(X.min() * 1.1, X.max() * 1.1)
- plt.ylim(C.min() * 1.1, C.max() * 1.1)
- # 重新设置坐标轴的刻度、X轴自定义标签
- plt.xticks((-np.pi, -np.pi/2, np.pi/2, np.pi),
- (r'$-\pi$', r'$-\pi/2$', r'$+\pi/2$', r'$+\pi$'))
- plt.yticks([-1, -0.5, 0, 0.5, 1])
- # 左侧图片的4个方向坐标改为两个方向的交叉坐标
- # 方法通过设置颜色为透明色,把上方和右侧的坐标线隐藏
- # 移动左侧和下方的坐标边线到原点(0,0)的位置
- ax = plt.gca() # 获取当前坐标轴
- ax.spines['right'].set_color('none') # 隐藏右侧坐标轴
- ax.spines['top'].set_color('none')
- ax.xaxis.set_ticks_position('bottom') # 设置刻度显示到下方
- ax.spines['bottom'].set_position(('data', 0)) # 设置下方坐标轴的位置
- ax.yaxis.set_ticks_position('left')
- ax.spines['left'].set_position(('data', 0)) # 设置左侧坐标轴位置
- # 在余弦去线上标识出这个点,同时用虚线画出对应的X轴坐标
- # 在坐标轴上标示相应的点
- t = 2 * np.pi / 3
- # 画出 cos(t) 所在的点在 X 轴上的位置,即画出 (t, 0) -> (t, cos(t)) 线段,使用虚线
- plt.plot([t, t], [0, np.cos(t)], color='blue', linewidth=1.5, linestyle="--")
- # 画出标示的坐标点,即在 (t, cos(t)) 处画一个大小为 50 的蓝色点
- plt.scatter([t, ], [np.cos(t), ], 50, color='blue')
- # 画出标示点的值,即 cos(t) 的值
- plt.annotate(r'$cos(\frac{2\pi}{3})=-\frac{1}{2}$',
- xy=(t, np.cos(t)), xycoords='data',
- xytext=(-90, -50), textcoords='offset points', fontsize=16,
- arrowprops=dict(arrowstyle="->", connectionstyle="arc3,rad=.2"))
- # 画出 sin(t) 所在的点在 X 轴上的位置,即画出 (t, 0) -> (t, sin(t)) 线段,使用虚线
- plt.plot([t, t], [0, np.sin(t)], color='red', linewidth=1.5, linestyle="--")
- # 画出标示的坐标点,即在 (t, sin(t)) 处画一个大小为 50 的红色点
- plt.scatter([t, ], [np.sin(t), ], 50, color='red')
- # 画出标示点的值,即 sin(t) 的值
- plt.annotate(r'$sin(\frac{2\pi}{3})=\frac{\sqrt{3}}{2}$',
- xy=(t, np.sin(t)), xycoords='data',
- xytext=(+10, +30), textcoords='offset points', fontsize=16,
- arrowprops=dict(arrowstyle="->", connectionstyle="arc3,rad=.2"))
- # plt.annotate函数的功能时在图片上画出标示文本
- # 定制坐标轴上的刻度标签字体,在刻度标签上添加一个半透明的背景
- for label in ax.get_xticklabels() + ax.get_yticklabels():
- label.set_fontsize(16)
- label.set_bbox(dict(facecolor='white', edgecolor='None', alpha=0.65))
- plt.show()
图形对象
在Matplotlib里,一个图形是指图片的全部可视区域,可以使用plt.figure来创建。在一个图形里,可以包含多个子图,可以使用plt.subplot() 来创建子图。子图按照网络形状排列显示在图形里,可以在每个子图上单独作画。。坐标轴和子图类似,唯一不同的是,坐标轴可以在图形上任意摆放,而不需要按照网络排列,这样显示起来更灵活,可以使用plt.axes()来创建坐标轴
当使用默认配置作画时,Matplotlib调用plt.gac()函数来获取当前的坐标轴,并在当前坐标轴上作画。plt.gac()函数调用plt.gcf函数来获取当前图形对象,如果当前不存在图形对象会调用plt.figure()函数创建要一个图形对象
plt.figure函数有几个常用的参数
num:图形对象的标识符,可以是数字或字符串。
figsize:以英寸为单位的图形大小,是一个元组
dpi:指定图形的质量,每英寸多少个点
下面的代码创建了两个图形,一个是sin,并且把正弦曲线画在这个图形上。然后创建了一个名称是cos的图形,并且把余弦曲线画在这个图形上。接着切换到之前创建的sin图形上,把余弦图片画在这个图形上
- from matplotlib import pyplot as plt
- import numpy as np
- X = np.linspace(-np.pi, np.pi, 200, endpoint=True)
- C, S = np.cos(X), np.sin(X)
- plt.figure(num='sin', figsize=(16, 4))
- plt.plot(X, S)
- plt.figure(num='cos', figsize=(16, 4))
- plt.plot(X, C)
- plt.figure(num='sin')
- plt.plot(X, C)
- print(plt.figure(num='sin').number)
- print(plt.figure(num='cos').number)
不同的图形可以单独保存为一个图片文件,但子图是指一个图形里分成几个区域,在不同的区域里单独作画,所有的子图最终都保存在一个文件里。plt.subplot()函数的关键参数是一个包含三个元素的元组,分别代表子图的行、列以及当前激活的子图序号。比如plt.subplot(2,2,1)表示把图标对象分成两行两列,激活的一个子图来作画
- from matplotlib import pyplot as plt
- plt.figure(figsize=(18, 4))
- plt.subplot(2, 2, 1)
- plt.xticks(())
- plt.yticks(())
- plt.text(0.5, 0.5, 'subplot(2,2,1)', ha='center', va='center', size=20, alpha=.5)
- plt.subplot(2, 2, 2)
- plt.xticks(())
- plt.yticks(())
- plt.text(0.5, 0.5, 'subplot(2,2,2)', ha='center', va='center', size=20, alpha=.5)
- plt.tight_layout()
- plt.show()
更复杂的子图布局,可以使用gridspec来实现,优点是可以指定某个子图横跨多个列或多个行
- from matplotlib import pyplot as plt
- import matplotlib.gridspec as gridspec
- plt.figure(figsize=(18, 4))
- G = gridspec.GridSpec(3, 3)
- axes_1 = plt.subplot(G[0, :]) # 占用第一行
- plt.xticks(())
- plt.yticks(())
- plt.text(.5, .5, 'Axes 1', ha='center', va='center', size=24, alpha=.5)
- axes_2 = plt.subplot(G[1:, 0]) # 占用第二行开始之后的所有行,第一列
- plt.xticks(())
- plt.yticks(())
- plt.text(0.5, 0.5, 'Axes 2', ha='center', va='center', size=24, alpha=.5)
- axes_3 = plt.subplot(G[1:, -1]) # 占用第二行开始之后的所有行,最后一列
- plt.xticks(())
- plt.yticks(())
- plt.text(0.5, 0.5, 'Axes 3', ha='center', va='center', size=24, alpha=.5)
- axes_4 = plt.subplot(G[1, -2]) # 占用第二行,倒数第二列
- plt.xticks(())
- plt.yticks(())
- plt.text(0.5, 0.5, 'Axes 4', ha='center', va='center', size=24, alpha=.5)
- axes_5 = plt.subplot(G[-1, -2]) # 占用倒数第一行,倒数第二列
- plt.xticks(())
- plt.yticks(())
- plt.text(0.5, 0.5, 'Axes 5', ha='center', va='center', size=24, alpha=.5)
- plt.tight_layout()
- plt.show()

使用坐标轴plt.axes()来创建,可以给矩形进行定位 plt.axes([.1,.1,.8,.8])
画图操作
绘制一个点分布图,需要使用plt.scatter()函数。np.arctan2(Y,X) 计算随机点的反正切,这个值作为随机点的颜色。
- import numpy as np
- from matplotlib import pyplot as plt
- n = 1024 # 定义点数量
- X = np.random.normal(0, 1, n)
- Y = np.random.normal(0, 1, n)
- T = np.arctan2(Y, X)
- plt.figure(figsize=(18, 4))
- plt.subplot(1, 2, 1)
- plt.scatter(X, Y, s=75, c=T, alpha=.5)
- plt.xlim(-1.5, 1.5)
- plt.xticks(())
- plt.ylim(-1.5, 1.5)
- plt.yticks(())

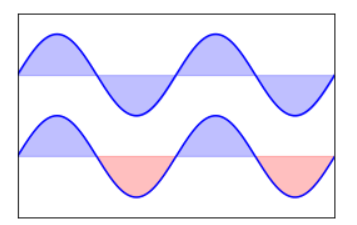
使用plt.fill_between()函数,可以画出正弦曲线。并在直线和曲线之间填充指定的颜色
- import numpy as np
- from matplotlib import pyplot as plt
- n = 256
- X = np.linspace(-np.pi, np.pi, n, endpoint=True)
- Y = np.sin(2*X)
- plt.figure(figsize=(10, 3))
- plt.subplot(1, 2, 2)
- plt.plot(X, Y+1, color="blue", alpha=1.00)
- plt.fill_between(X, 1, Y+1, color="blue", alpha=.25)
- plt.plot(X, Y-1, color="blue", alpha=1.00)
- plt.fill_between(X, -1, Y-1, (Y-1) > -1, color="blue", alpha=.25)
- plt.fill_between(X, -1, Y-1, (Y-1) < -1, color="red", alpha=.25)
- plt.xlim(-np.pi, np.pi)
- plt.xticks(())
- plt.ylim(-2.5, 2.5)
- plt.yticks(())
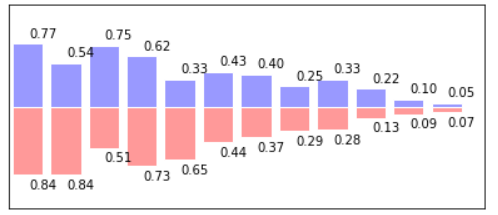
使用plt.bar()函数可以画出柱状图。生成24个随机值,调用两次plt.bar() 分别画在上下两侧。在调用plt.text()函数把数值画在对应的柱状图上。
- import numpy as np
- from matplotlib import pyplot as plt
- n = 12
- X = np.arange(n)
- Y1 = (1-X/float(n)) * np.random.uniform(0.5, 1.0, n)
- Y2 = (1-X/float(n)) * np.random.uniform(0.5, 1.0, n)
- plt.figure(figsize=(15, 3))
- plt.subplot(1, 2, 1)
- plt.bar(X, +Y1, facecolor="#9999ff", edgecolor="white")
- plt.bar(X, -Y2, facecolor="#ff9999", edgecolor="white")
- for x, y in zip(X, Y1):
- plt.text(x+0.4, y+0.05, '%.2f' % y, ha='center', va='bottom')
- for x, y in zip(X, Y2):
- plt.text(x+0.4, -y-0.05, '%.2f' % y, ha='center', va='top')
- plt.xlim(-.5, n)
- plt.xticks(())
- plt.ylim(-1.25, 1.25)
- plt.yticks(())
使用plt.contourf() 函数填充等高线,命名参数cmap表示颜色映射风格。plt.contour()函数画出等高线。plt.clable()画出等高线上的数字
- import numpy as np
- from matplotlib import pyplot as plt
- def f(x, y):
- return (1 - x / 2 + x ** 5 + y ** 3) * np.exp(-x ** 2, -y ** 2)
- n = 256
- x = np.linspace(-3, 3, n)
- y = np.linspace(-3, 3, n)
- X, Y = np.meshgrid(x, y)
- plt.figure(figsize=(30, 10))
- plt.subplot(1, 2, 2)
- plt.contourf(X, Y, f(X, Y), 8, alpha=.75, cmap=plt.cm.hot)
- c = plt.contour(X, Y, f(X, Y), 8, colors="black", linewidth=.5)
- plt.clabel(c, inline=1, fontsize=10)
- plt.xticks(())
- plt.yticks(())

使用plt.imshow()函数把数组当成图片画出来
- import numpy as np
- from matplotlib import pyplot as plt
- def f(x, y):
- return (1 - x / 2 + x ** 5 + y ** 3) * np.exp(-x ** 2, -y ** 2)
- plt.subplot(1, 2, 1)
- n = 10
- x = np.linspace(-3, 3, 4 * n)
- y = np.linspace(-3, 3, 3 * n)
- X, Y = np.meshgrid(x, y)
- plt.imshow(f(X, Y), cmap="hot", origin="low")
- plt.colorbar(shrink=.83)
- plt.xticks(())
- plt.yticks(())

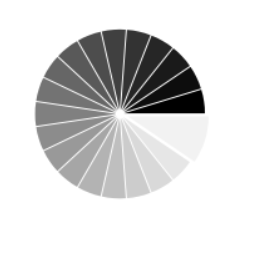
使用plt.pie()函数画出饼图
- import numpy as np
- from matplotlib import pyplot as plt
- plt.subplot(1, 2, 2)
- n = 20
- Z = np.ones(n)
- Z[-1] *= 2
- plt.pie(Z, explode=Z*.05, colors=['%f' % (i/float(n)) for i in range(n)])
- plt.axis('equal')
- plt.xticks(())
- plt.yticks()
使用坐标轴set_major_locator()和set_minor_locator()把坐标刻度设置成MultipleLocator央视。然后使用grid()函数在刻度刻画线段。这样就生成了网格
- from matplotlib import pyplot as plt
- ax = plt.subplot(1,2,1)
- ax.set_xlim(0,4)
- ax.set_ylim(0,3)
- ax.xaxis.set_major_locator(plt.MultipleLocator(1.0))
- ax.xaxis.set_major_locator(plt.MultipleLocator(0.1))
- ax.yaxis.set_major_locator(plt.MultipleLocator(1.0))
- ax.yaxis.set_major_locator(plt.MultipleLocator(0.1))
- ax.grid(which="major",axis="x",linewidth=0.75,linestyle="-",color="0.75")
- ax.grid(which="minor",axis="x",linewidth=0.25,linestyle="-",color="0.75")
- ax.grid(which="major",axis="y",linewidth=0.75,linestyle="-",color="0.75")
- ax.grid(which="minor",axis="y",linewidth=0.25,linestyle="-",color="0.75")
- ax.set_xticklabels([])
- ax.set_yticklabels([])

使用plt.bar()和bar.set_facecolor()来填充不同的颜色,可以做出极坐标图
- import numpy as np
- from matplotlib import pyplot as plt
- ax = plt.subplot(1, 2, 2, polar=True)
- N = 20
- theta = np.arange(0.0, 2*np.pi, 2*np.pi/N)
- radii = 10 * np.random.rand(N)
- width = np.pi / 4 * np.random.rand(N)
- bars = plt.bar(theta, radii, width=width, bottom=0.0)
- for r, bar in zip(radii, bars):
- bar.set_facecolor(plt.cm.jet(r/10.))
- bar.set_alpha(0.5)
- ax.set_xticklabels([])
- ax.set_yticklabels([])

Sklearn环境搭建与常用包的更多相关文章
- 04-SSH综合案例:环境搭建之jar包引入
刚才已经把表关系的分析已经分析完了,现在呢就先不去创建这个表,写到哪儿的时候再去创建这个表. 1.4 SSH环境搭建: 1.4.1 第一步:创建一个web项目. 1.4.2 第二步:导入相应jar包. ...
- Maven环境搭建及常用命令、生命周期
一.下载maven包,解压 二.配置环境变量,MAVEN_PATH=解压路径 添加到path中 三.测试 mvn -v 查看maven版本 四.设置本地仓库的路径 在conf文件夹下的setting ...
- Jenkins+PowerShell持续集成环境搭建(四)常用PowerShell命令
0. 修改执行策略 Jenkins执行PowerShell脚本,需要修改其执行策略.以管理员身份运行PowerShell,执行以下脚本: Set-ExecutionPolicy Unrestricte ...
- 【ZooKeeper系列】3.ZooKeeper源码环境搭建
前文阅读: [ZooKeeper系列]1.ZooKeeper单机版.伪集群和集群环境搭建 [ZooKeeper系列]2.用Java实现ZooKeeper API的调用 在系列的前两篇文章中,介绍了Zo ...
- go语言之行--简介与环境搭建
一.Go简介 Go 是一个开源的编程语言,它能让构造简单.可靠且高效的软件变得容易. Go是从2007年末由Robert Griesemer, Rob Pike, Ken Thompson主持开发,后 ...
- 我的vim开发环境搭建:C/C++/Go,持续更新中
懒得在github博客上折腾评论功能,先借用博客园推广下,虽然好像也没什么用. 我的vim开发环境搭建(1): 准备工作 我的vim开发环境搭建(2): 常用的vim插件 我的vim开发环境搭建(3) ...
- u-boot 移植(一)编译环境搭建
u-boot 移植(一)编译环境搭建 soc:s3c2440 board:jz2440 uboot:u-boot-2016.11 toolchain:gcc-linaro-7.4.1-2019.02- ...
- java:Hibernate框架1(环境搭建,Hibernate.cfg.xml中属性含义,Hibernate常用API对象,HibernteUitl,对象生命周期图,数据对象的三种状态,增删查改)
1.环境搭建: 三个准备+7个步骤 准备1:新建项目并添加hibernate依赖的jar文件 准备2:在classpath下(src目录下)新建hibernate的配置文件:hibernate.cf ...
- 【java开发】ubuntu常用命令及环境搭建
学习第一天,今天内容相对简单,主要就是ubuntu一些常用命令及常规操作,后续涉及到环境的搭建,也会在本文再更. ubuntu环境搭建 第一种 也是最简单最方便的 通过vm虚拟机软件,下载iso镜像进 ...
随机推荐
- sudo实例--企业生产环境用户权限集中管理方案实例
根据角色的不同,给不同的用户分配不同的角色1.创建初级工程师3个,网络工程师1个,中级工程师1个,经理1个 # 批量创建用户 for user in chuji{01..03} net01 ...
- CSS学习摘要-定位实例
CSS学习摘要-定位实例 注:全文摘自MDN-CSS定位实例 列表消息盒子 我们研究的第一个例子是一个经典的选项卡消息框,你想用一块小区域包括大量信息时,一个非常常用的特征.这包括含有大信息量的应用, ...
- Asp.net Core 2.0+EntityFrameWorkCore 2.0添加数据迁移
Asp.net Core 由于依赖注入的广泛使用,配置数据迁移,与Asp.net大不相同,本篇介绍一下Asp.net Core添加数据迁移的过程 添加Nuget包 Install-Package Mi ...
- ZT C语言链表操作(新增单向链表的逆序建立)
这个不好懂,不如看 转贴:C语言链表基本操作http://www.cnblogs.com/jeanschen/p/3542668.html ZT 链表逆序http://www.cnblogs.com/ ...
- selenium安装浏览器驱动
3.0以上版本恩的selenium需要安装驱动 pip show selenium 安装驱动 1.下载驱动地址: 火狐:https://github.com/mozilla/geckodriver/r ...
- Ubuntu18.04 使用过程遇到的问题记录
索引: 1.Ubuntu 18.04 安装搜狗输入法 2.在 Ubuntu 18.04 中将第三方软件添加至 favorite 菜单栏 3.在 VMware workstation 中为虚拟机安装 V ...
- 翻新并行程序设计的认知整理版(state of the art parallel)
近几年,业内对并行和并发积累了丰富的经验.有了较深刻的理解.但之前积累的大量教材,在当今的软硬件体系下.反而都成了负面教材.所以,有必要加强宣传,翻新大家的认知. 首先.天地倒悬,结论先行:当你须要并 ...
- P2278 [HNOI2003]操作系统
题目描述 写一个程序来模拟操作系统的进程调度.假设该系统只有一个CPU,每一个进程的到达时间,执行时间和运行优先级都是已知的.其中运行优先级用自然数表示,数字越大,则优先级越高. 如果一个进程到达的时 ...
- repulsion-loss
行人检测中的mr,fppi这些指标??? 3种距离:欧式距离.SmoothL1距离.IoU距离 总的loss公式:3个部分组成Lattr是预测框和匹配的gt尽可能接近,Lrepgt是预测框和周围没匹配 ...
- 【转】np.linspace()、np.logspace()、np.arange()
转自:https://blog.csdn.net/ui_shero/article/details/78881067 1.np.linspace() 生成(start,stop)区间指定元素个数num ...